功能概述
模型实验是 WeData 实现模型生产中过程可管理、实验可复现的关键模块之一,支持如下核心功能:
支持实验/运行过程中的关键信息上报、存储、管理、查看,包括:实验/运行名称、模型文件、代码包、超参数、环境、数据集/特征、模型训练指标、创建时间等等。
支持进行实验/运行之间对比关键信息。
支持版本管理和关联关系记录,方便信息回溯和问题定位。
WeData 的模型实验模块基于业界主流的MLFlow工具包实现,其实现的过程可管理、实验可复现大致流程及各模块功能如下。
必要说明
类型 | 说明 |
引擎支持 | DLC 标准引擎 可用于模型训练、模型实验上报、特征管理、模型注册等操作 注意,只有 DLC 引擎建资源组时选择“wedata-data-science”镜像,才可以用于 AutoML 实验 EMR on CVM、EMR on TKE(注意需包含 EG 组件,否则无法在 WeData 使用) 可用于模型训练、模型实验上报、特征管理、模型注册等操作 注意,不可用于 AutoML 实验 EMR:Ray on TKE(注意需包含 EG 组件,否则无法在 WeData 使用) 可用于模型训练、模型实验上报、模型注册等操作 注意:不可用于 AutoML 实验、特征处理 |
MLflow 版本 | WeData 的实验管理默认兼容 MLflow 的2.17.2版本,相关镜像已经预装,连接 Studio 运行环境后可执行命令进行检查:
|
表操作权限 | DLC: 如果开通了 Catalog: 需在 DLC 中“DLC > 系统管理 > 用户与权限管理”对用户授权对应库表权限 并在 WeData 的“数据资产 > Catalog 目录 > 对应的 Catalog > 权限”中对用户进行授权 如果没有开通 Catalog: 只需要在 DLC 中“DLC > 系统管理 > 用户与权限管理”对用户授权对应库表权限 EMR: 在 WeData 的“项目管理 > 存算引擎设置”中设置引擎访问账号和账号映射,来确定访问库表的权限 |
模型操作权限 | DLC: 如果开通了 Catalog: 需要在 WeData 的“数据资产 > Catalog 目录 > 对应的模型 Catalog > 权限”中对用户进行授权 如果没有开通 Catalog: 无需授权 EMR: 无需授权 |
特征工程包 | 连接引擎后执行如下命令,即可安装最新的特征工程包:
如果使用 DLC 引擎,构建资源组时选择“wedata-data-science”镜像,已经预安装特征工程包。可执行命令检查版本:
|
环境变量设置 | DLC: 如果开通了 Catalog,无需额外设置。 如果没有开通 Catalog,需要设置环境变量,否则实验和模型上报可能报错:
EMR: 需要设置环境变量,否则实验和模型上报可能报错:
|
操作步骤
实验列表
1. 单击进入“模型实验”功能菜单。
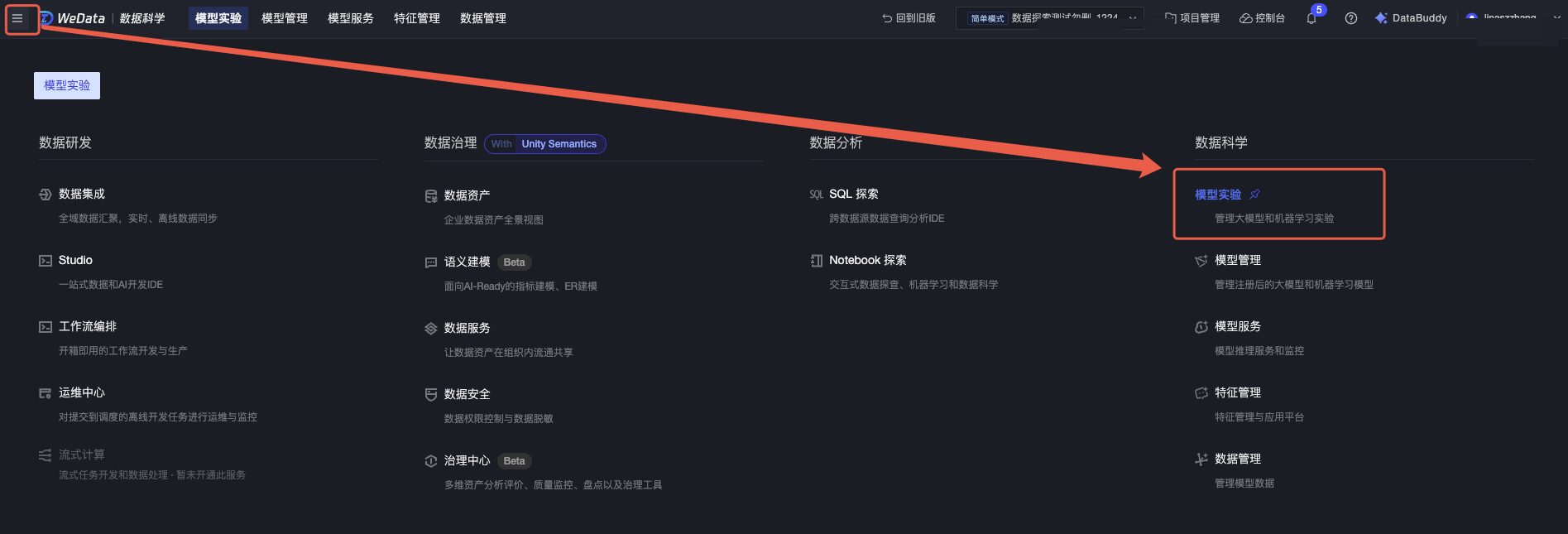
2. 首页显示新建实验及实验列表。
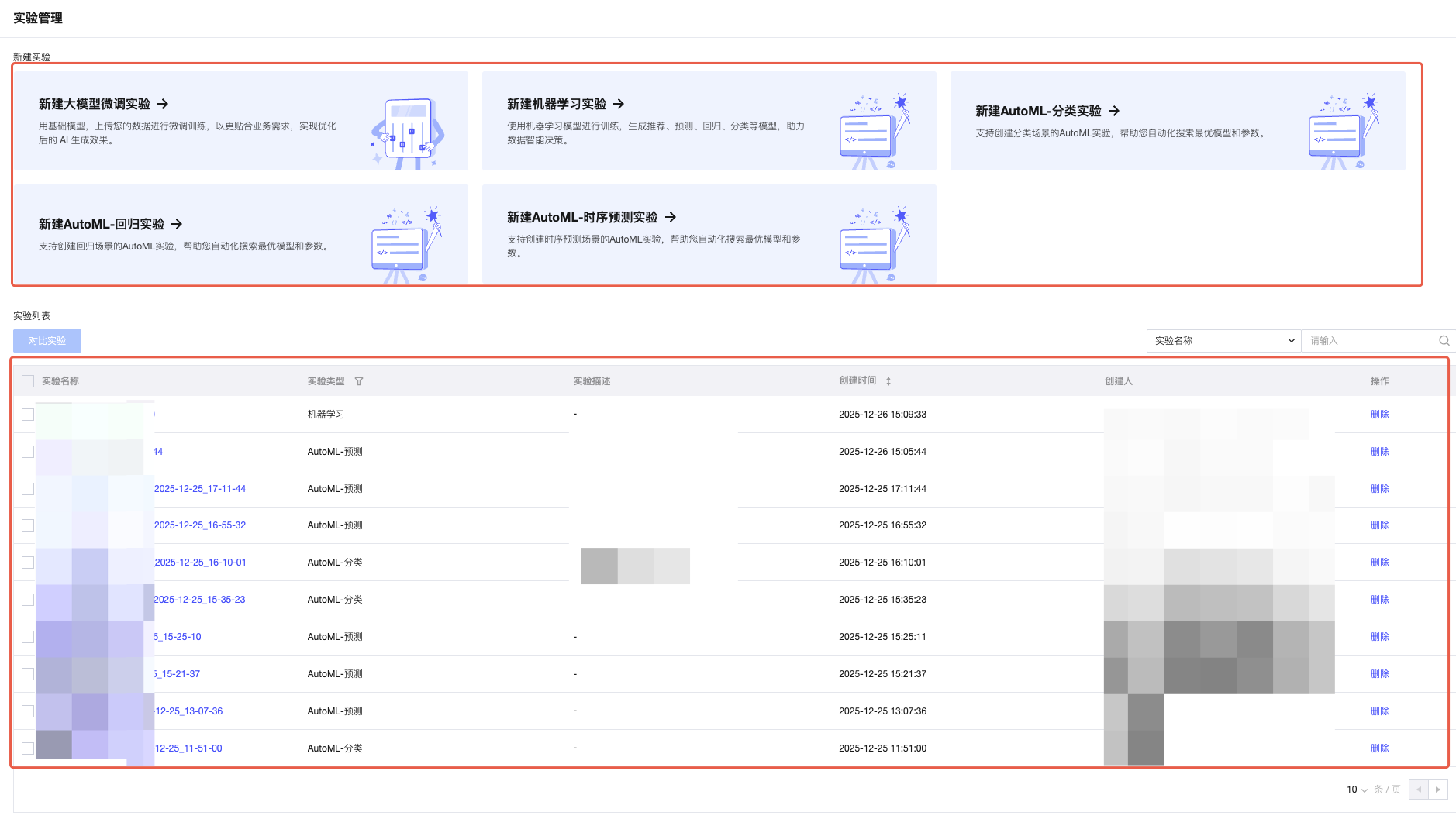
新建实验
1. 您可以在当前页面通过新建机器学习实验的按钮进行新建。

2. 单击新建机器学习实验,弹窗内填入实验名称即可创建成功。
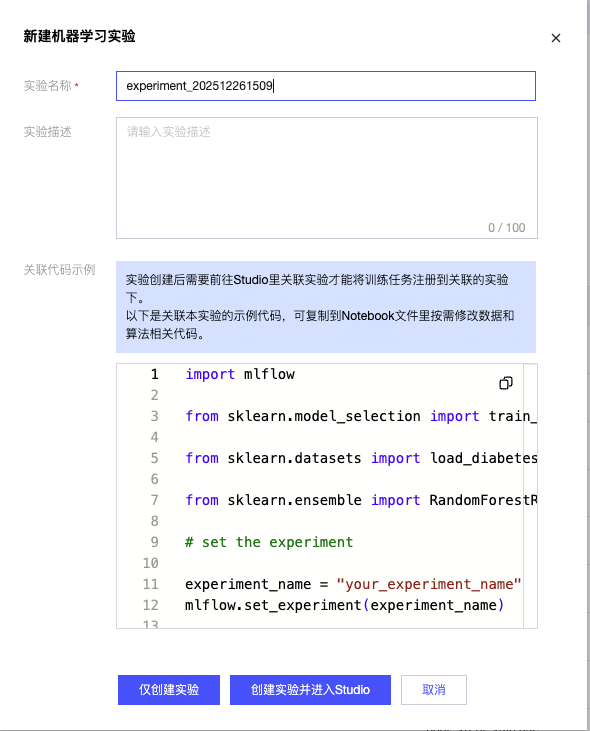
说明:
实验创建后需要前往 Studio 里关联实验才能将训练任务注册到关联的实验下。
3. 您可以在训练脚本中使用 mlflow.create_experiment()函数创建实验,例如定义实验名称为“experiment_202512261509”,运行代码后,该实验则会出现在实验列表中。

实验详情
1. 单击“实验名称”,右侧显示该实验的运行列表,并显示运行的相关信息,包括:运行名称、运行状态、实验名称、创建时间、运行时长、数据集、代码源文件、注册模型等等。
2. 在当前列表可以单击代码源文件和注册模型跳转到 Studio 和模型详情页进行查看。

3. 也可在操作列删除运行任务通过删除。
4. 运行任务图表视图。
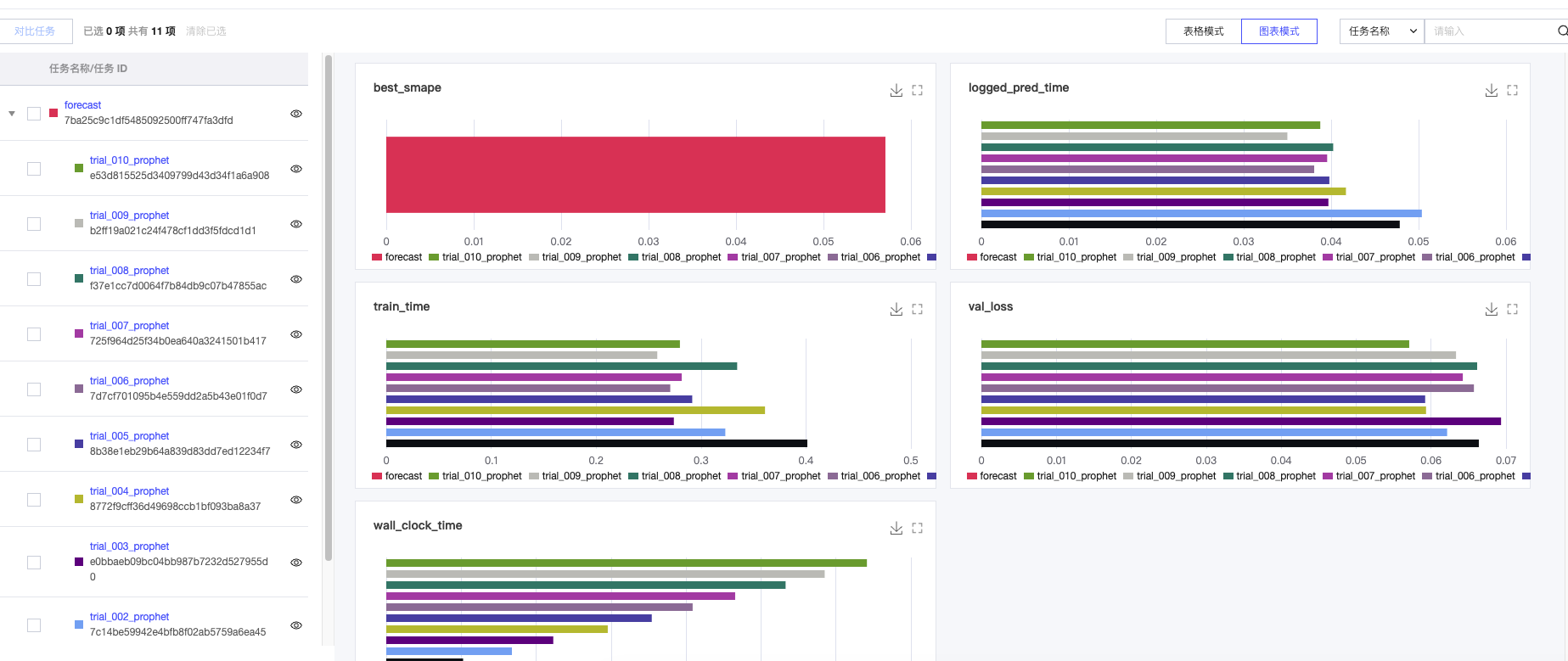
显示运行任务的模型指标信息,支持单击,显示或隐藏该运行任务的柱状图,顶部支持全局搜索图表名称和参数。
右上角支持下载(默认 PNG 文件)和全屏显示。
说明:
当运行任务数量大于10,为确保阅读体验,默认按顺序依次展示前10个运行任务,超过数量的运行任务自动隐藏。
5. 运行任务对比。
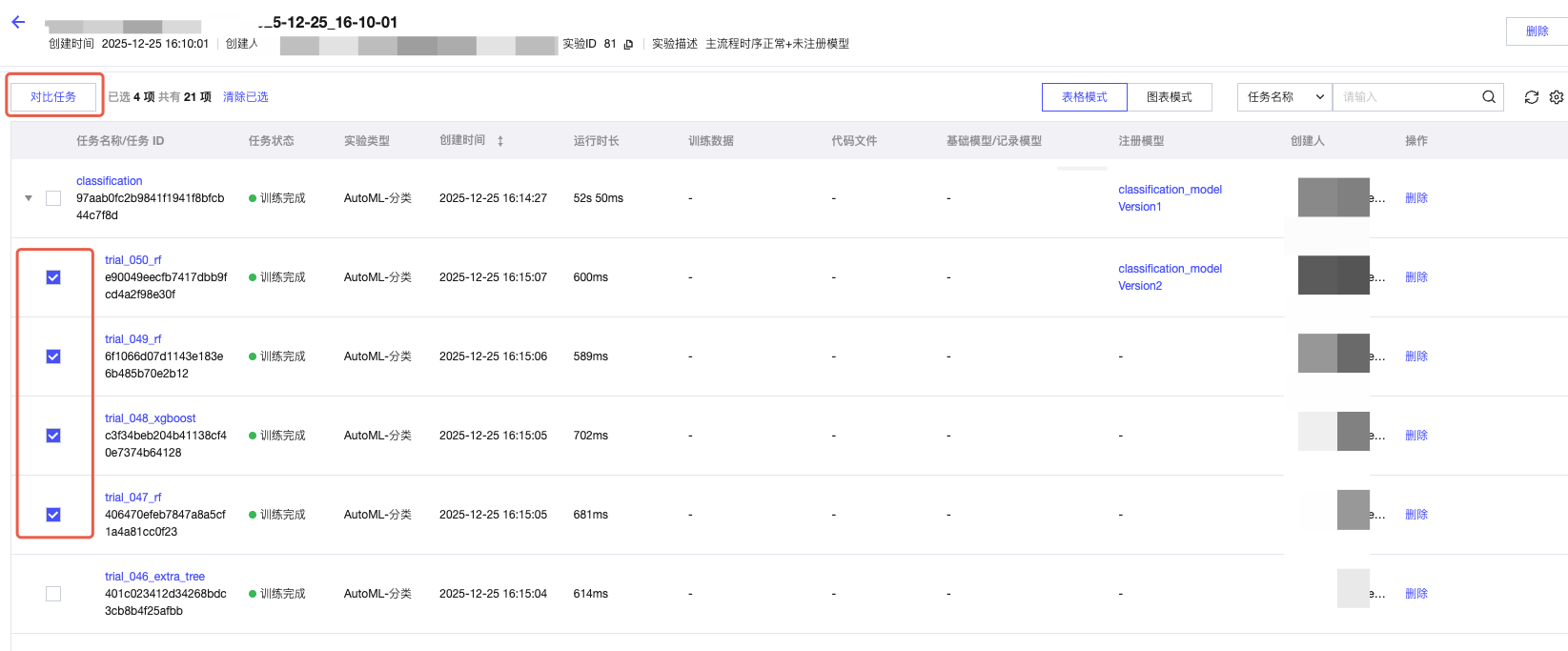
6. 通过多选框勾选任务,单击运行任务比较按钮,可以对运行任务进行参数及指标的对比。方便对实验的运行任务进行详细的对比,最终择优进行应用。
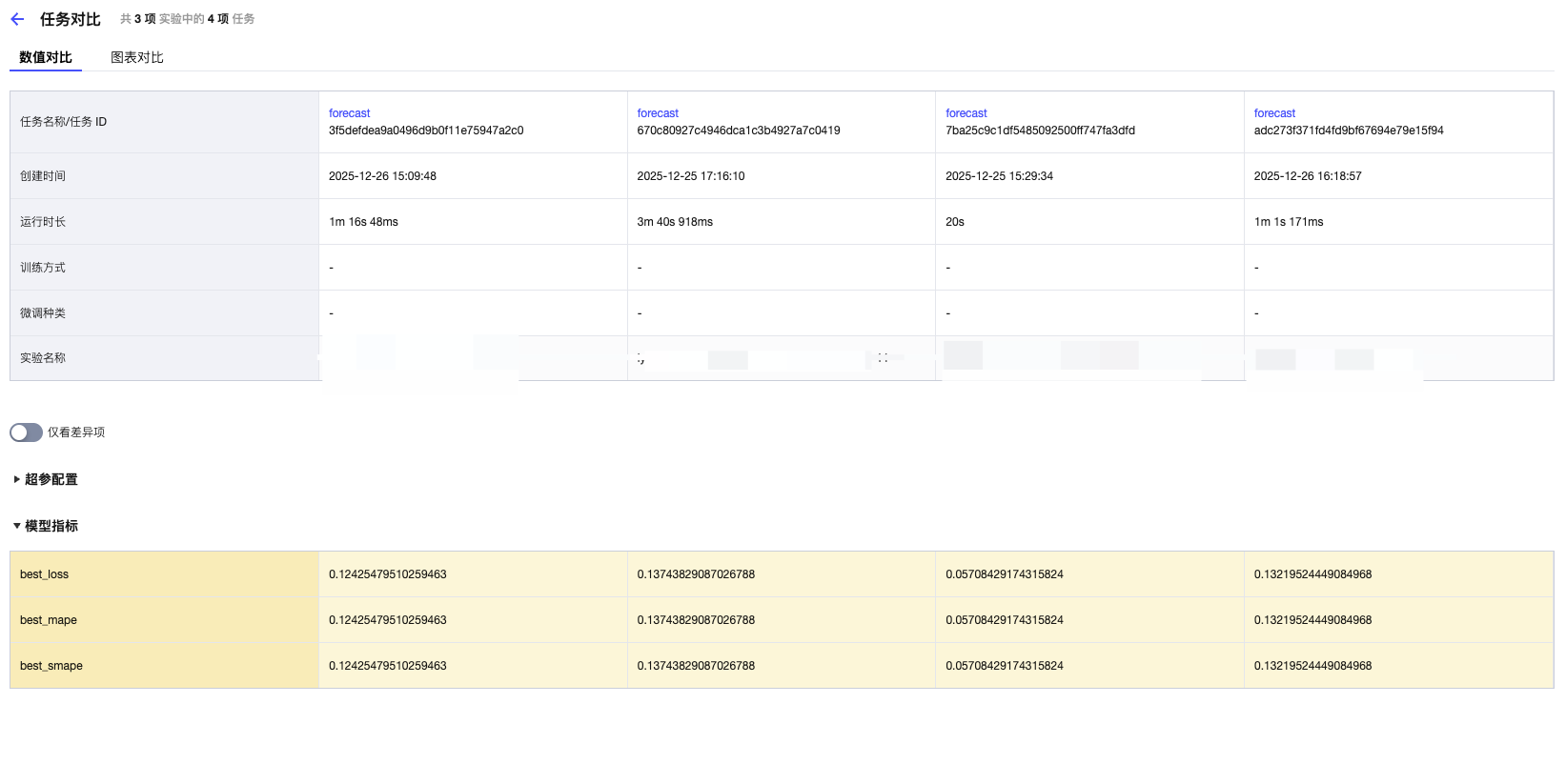
数值对比展示所选运行任务的详情、参数、指标的数据对比视图。
平行坐标系:
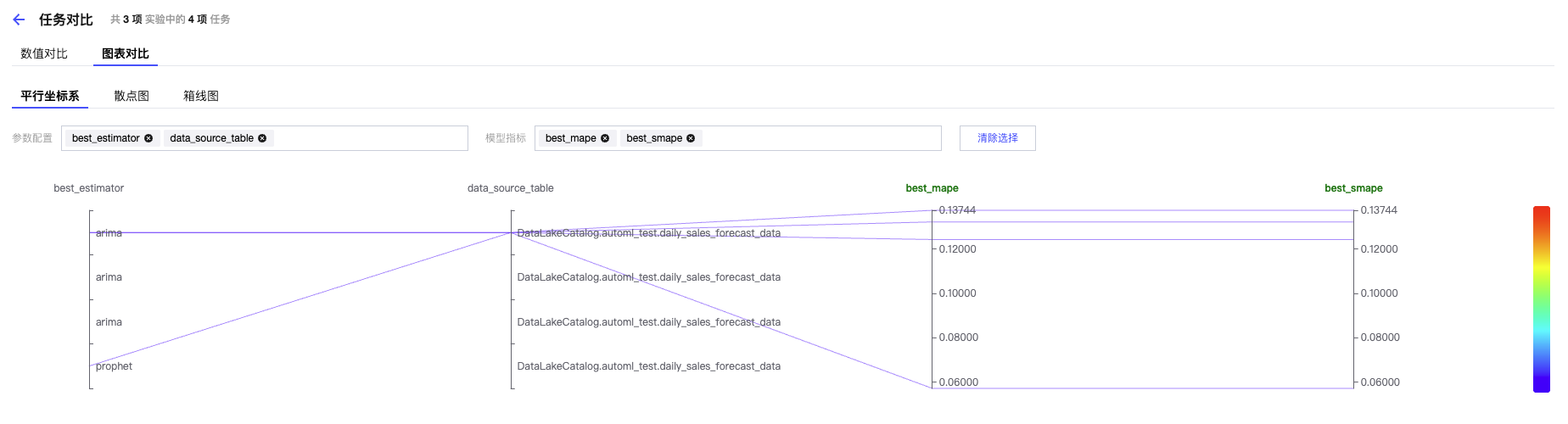
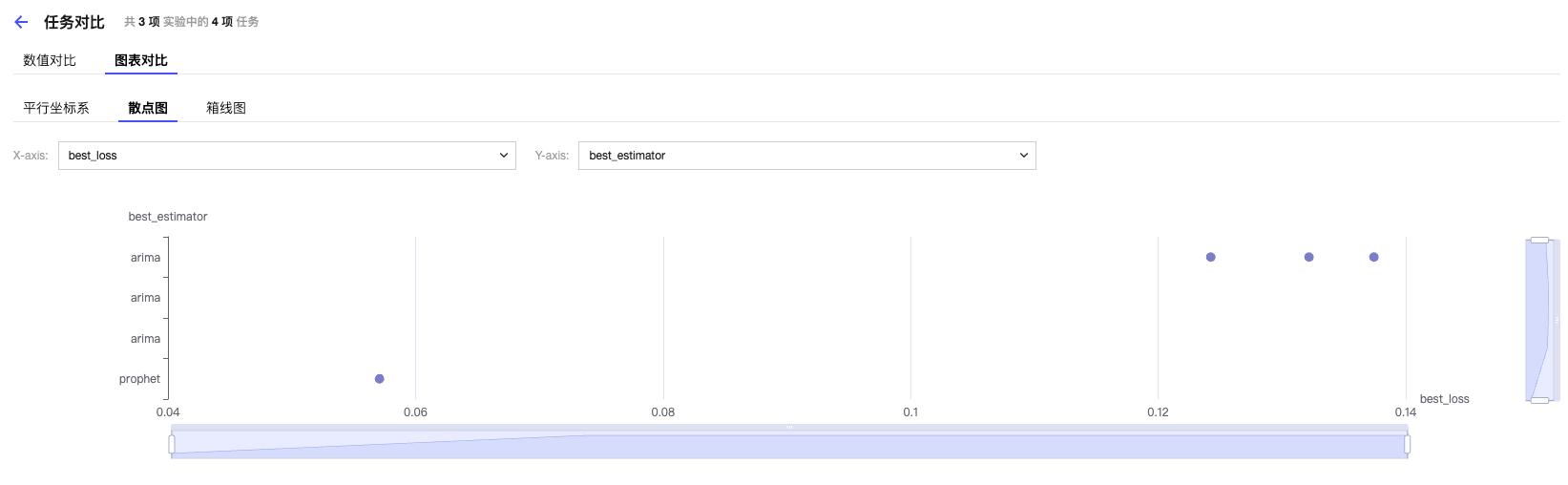
散点图:
箱线图:
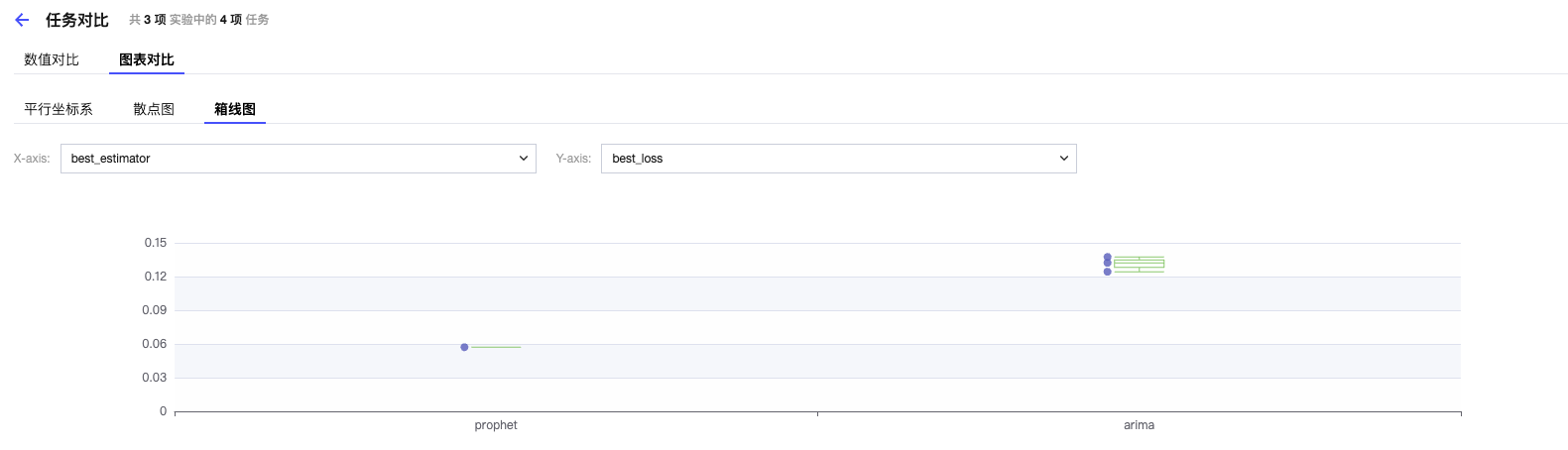
图表对比可自行选择平行坐标系、散点图、箱线图三个类型的可视化图表,其中 X 轴和 Y 轴可根据您场景的需要进行自定义。
运行详情
1. 查看运行详情。
单击“运行名称”,进入运行详情界面,默认进入概览页面,显示内容如下:
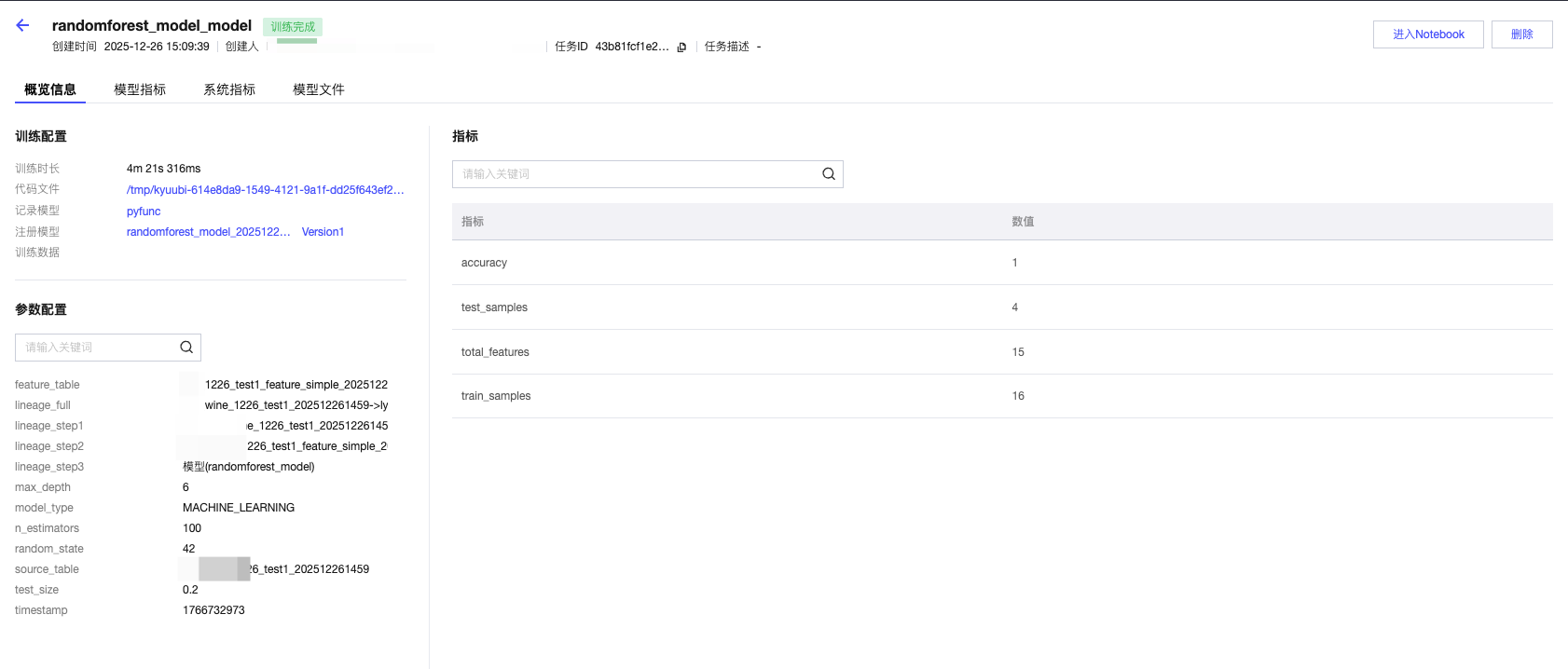
包括:
运行的关键信息:创建时间、创建人、实验 ID、运行状态、运行 ID、运行时长、数据集、标签、代码、基础模型、已注册模型。
超参数:模型训练过程中的超参数,在此例子中为权重等。
模型指标:模型训练过程中,上报的指标(基于训练测试集或者是训练验证集)。
2. 查看模型指标。
单击 Model Metrics 可以查看模型指标,此功能支持记录和评估模型的性能指标,如准确率、精确率、召回率等。这些指标可以帮助你了解模型的表现并进行比较。
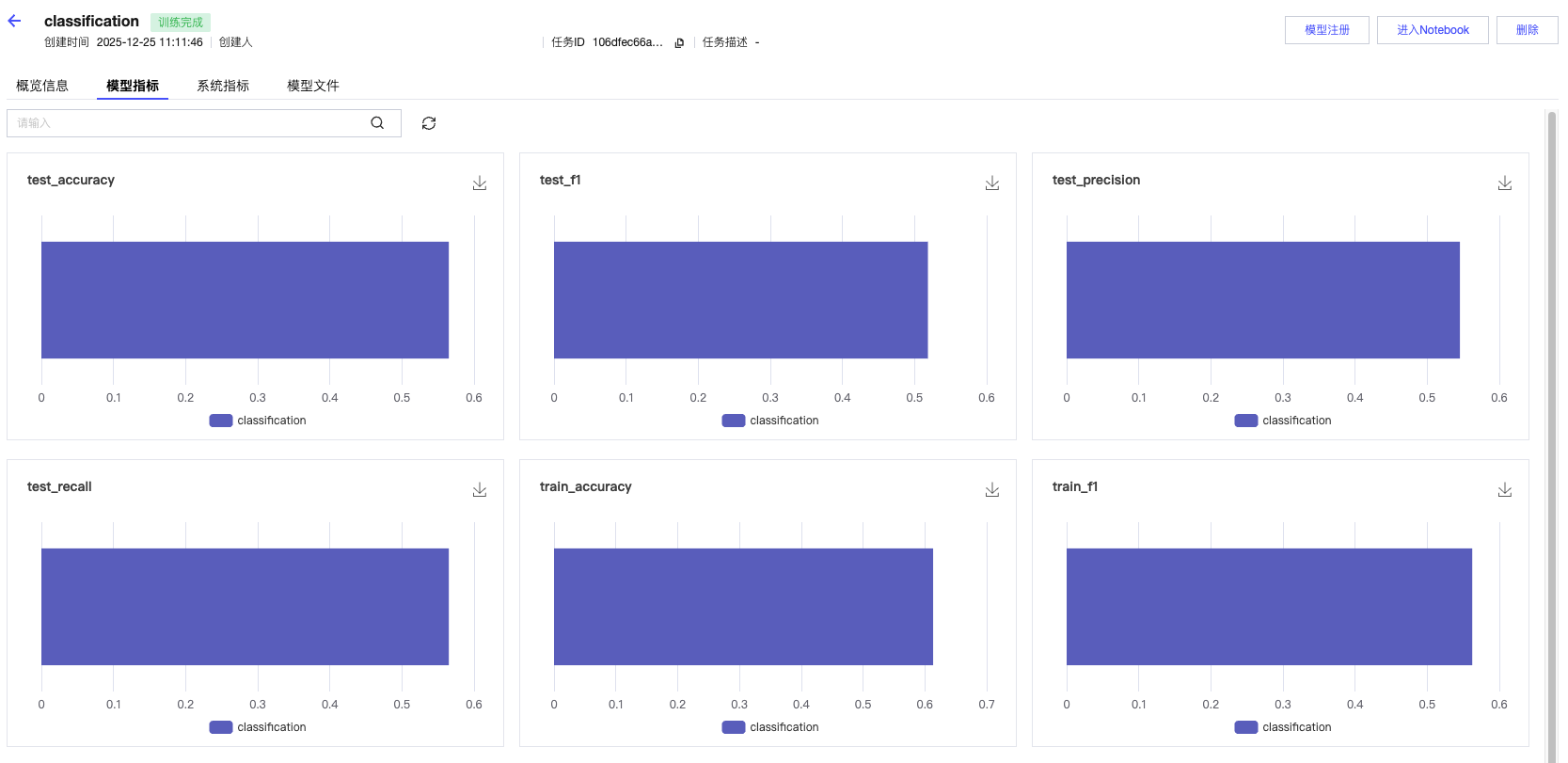
您可以在训练脚本中使用 mlflow.log_metric() 函数记录模型性能指标,示例:
import mlflowfrom sklearn.metrics import accuracy_score, precision_score, recall_score# 假设你有训练好的模型和测试数据y_true = [...] # 实际标签y_pred = [...] # 预测标签# 开始 MLflow 运行with mlflow.start_run():# 计算模型性能指标accuracy = accuracy_score(y_true, y_pred)precision = precision_score(y_true, y_pred)recall = recall_score(y_true, y_pred)# 记录模型性能指标mlflow.log_metric("accuracy", accuracy)mlflow.log_metric("precision", precision)mlflow.log_metric("recall", recall)...
3. 查看系统指标。
System Metrics 用于监控和记录模型训练过程中的系统性能指标,如 CPU 使用率、内存使用情况等,这些指标可以帮助你了解模型训练的资源消耗情况。MLFlow 默认记录的系统指标如下:
cpu_utilization_percentage
system_memory_usage_megabytes
system_memory_usage_percentage
network_receive_megabytes
network_transmit_megabytes
disk_usage_megabytes
disk_available_megabytes
您可以在训练脚本中使用三种方式记录系统性能指标,示例:
import mlflowimport psutil # 用于获取系统性能指标#开启方式1:使用环境变量的形式import osos.environ["MLFLOW_ENABLE_SYSTEM_METRICS_LOGGING"] = "true"#开启方式2:使用 mlflow.enable_system_metrics_logging() 记录mlflow.enable_system_metrics_logging()#开启方式3:针对指定的run启动with mlflow.start_run(log_system_metrics=True):...
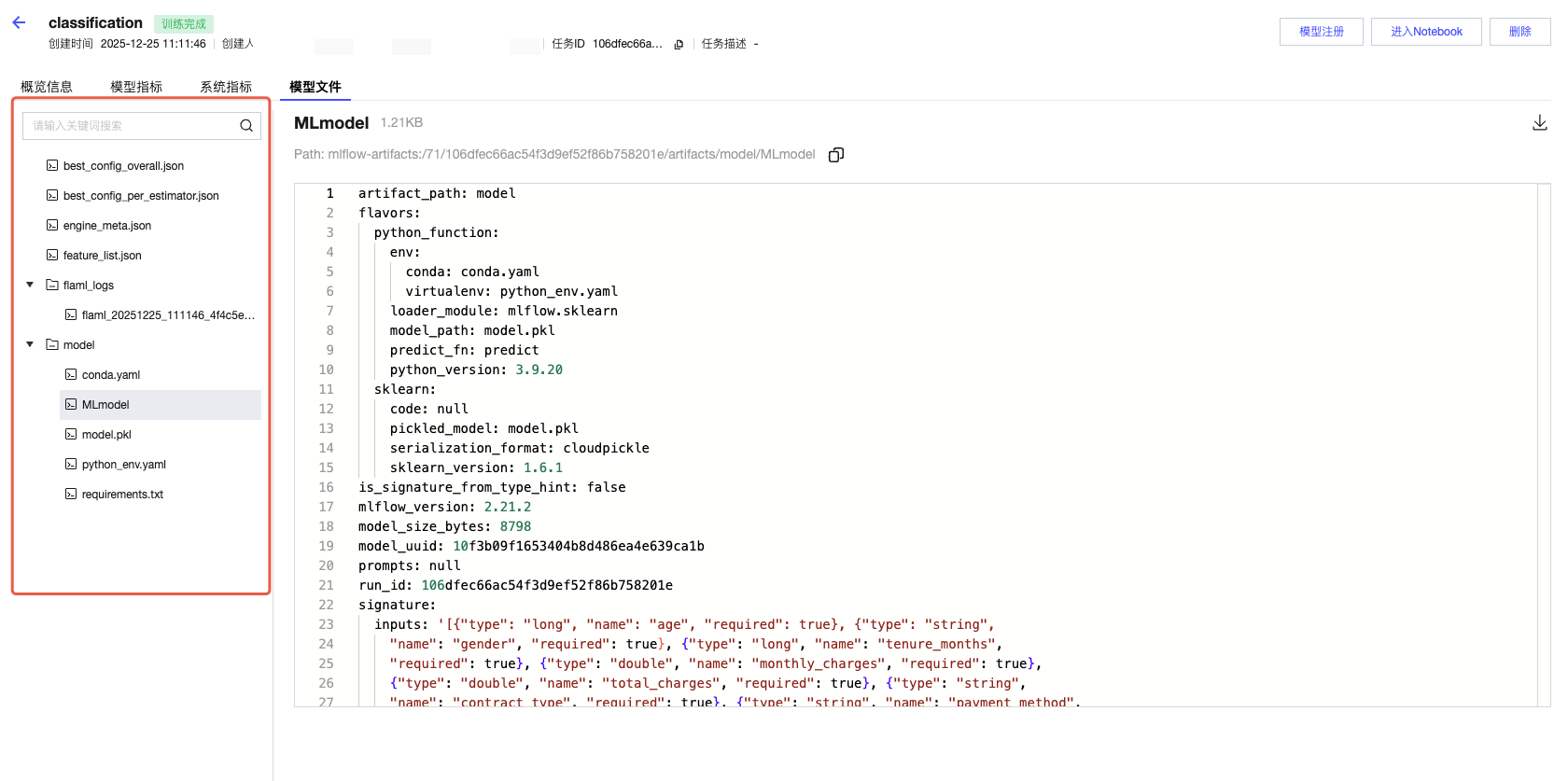
4. 查看模型文件。
Artifacts 是指与模型相关的文件,例如模型文件、图表、数据集、日志文件等。
如下图示例,是本次运行所产生的模型文件,包括模型的路径、输入和输出元数据以及调试运行的代码示例。并且支持单击跳转到模型管理中,查看所发布的模型。