功能概述
WeData 的特征管理模块通过提供特征离线存储和在线存储的服务,从而实现特征的统一管理,助力数据科学家和数据工程师在模型开发过程中,可以集约化的存储、读取、分析和复用特征,避免烟囱式的开发协作模式。
能力说明
WeData 的特征管理主要提供如下能力:
类型 | 说明 |
界面操作功能 | 1. 支持查看特征表的基础信息、特征字段信息等。 2. 支持批量导入特征表。 3. 支持创建特征同步等。 |
特征工程 API | 支持在 Studio 中调用进行离在线特征表的增删改查、同步、消费等操作。 |
必要说明
类型 | 说明 |
离线特征存储 | WeData 所管理的离线特征表,目前仅支持 DLC 的 Iceberg 表和 EMR 的 Hive 表,且注册特征表时必须指定表的主键及时间戳键,后续操作时将以所指定的主键和时间戳键进行特征索引。 |
表操作权限 | DLC: 如果开通了 Catalog: 需在 DLC 中“DLC > 系统管理 > 用户与权限管理”对用户授权对应库表权限 并在 WeData 的“数据资产 > Catalog 目录 > 对应的 Catalog > 权限”中对用户进行授权 如果没有开通 Catalog: 只需要在 DLC 中“DLC > 系统管理 > 用户与权限管理”对用户授权对应库表权限 EMR: 在 WeData 的“项目管理 > 存算引擎设置”中设置引擎访问账号和账号映射,来确定访问库表的权限 |
在线特征存储 | WeData 支持 Redis 作为在线特征存储。准备如下: 地域、网络需要注意和调度资源组、所使用的引擎(DLC 或者 EMR)保持一致。 第二步:在 WeData 的“项目管理 > 数据源管理”添加 Redis 数据源,测试可连通调度资源组。 第三步:在 WeData 的“离线开发 > Studio”中连接远程内核后,验证 Redis 是否连通,如下:
|
特征工程包 | 连接引擎后执行如下命令,即可安装最新的特征工程包:
如果使用 DLC 引擎,构建资源组时选择“wedata-data-science”镜像,已经预安装特征工程包。可执行命令检查版本:
|
密钥管理说明 | |
环境变量设置 | DLC: 如果开通了 Catalog,无需额外设置。 如果没有开通 Catalog,需要设置环境变量,否则实验和模型上报可能报错:
EMR: 需要设置环境变量,需要设置环境变量,否则实验和模型上报可能报错:
|
界面操作
特征导入和默认库设置
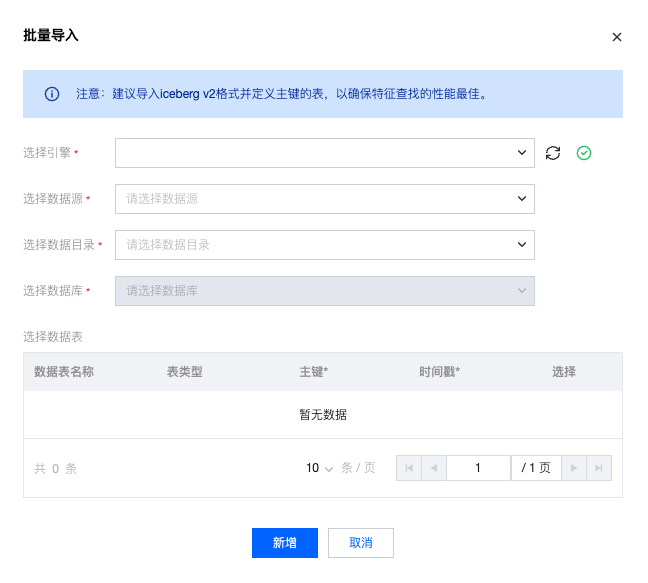
离线特征表批量导入/注册
WeData 支持批量地导入/注册已有的特征表,进入特征管理页面,点击批量导入按钮,支持按照提示选择引擎、数据源和数据库,并勾选主键及对应的表后即可进行批量导入。
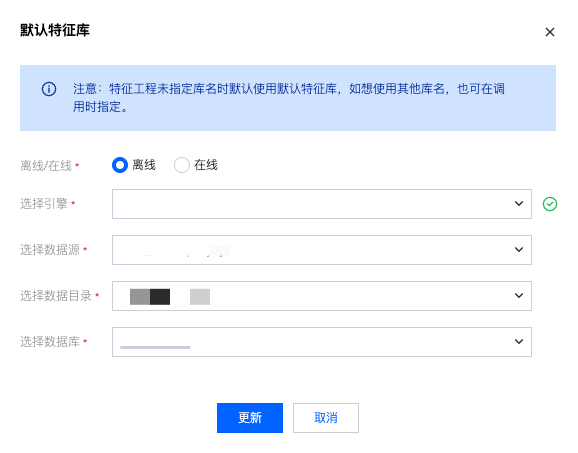
默认库设置
WeData 支持设置默认的离线特征库和在线特征库,将会在您调用 API 未指定特征库信息时,使用默认特征库信息。
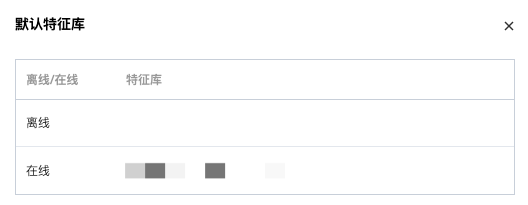
并且支持在模块名右侧查看所设置的默认库信息。
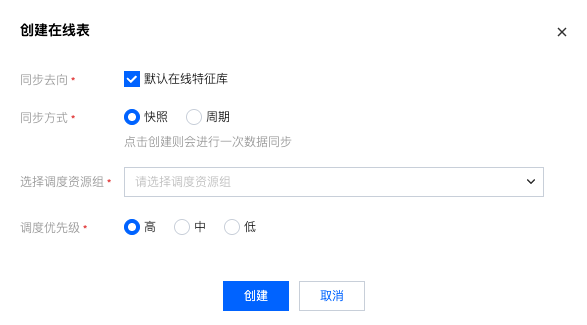
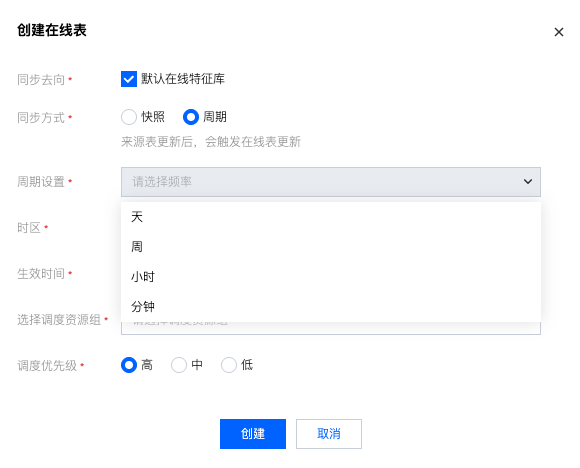
创建在线表/特征同步
支持点击离线特征表的创建在线表的操作项,从而创建离线表到在线表的同步任务。支持选择快照、周期两种同步方式。
快照方式支持一次性的特征同步,设置计算资源、任务优先级等。
周期方式支持设置同步周期,支持按天、周、小时、分钟的同步周期,并且支持设置时间区间、计算资源、任务优先级等。
特征表详情查看
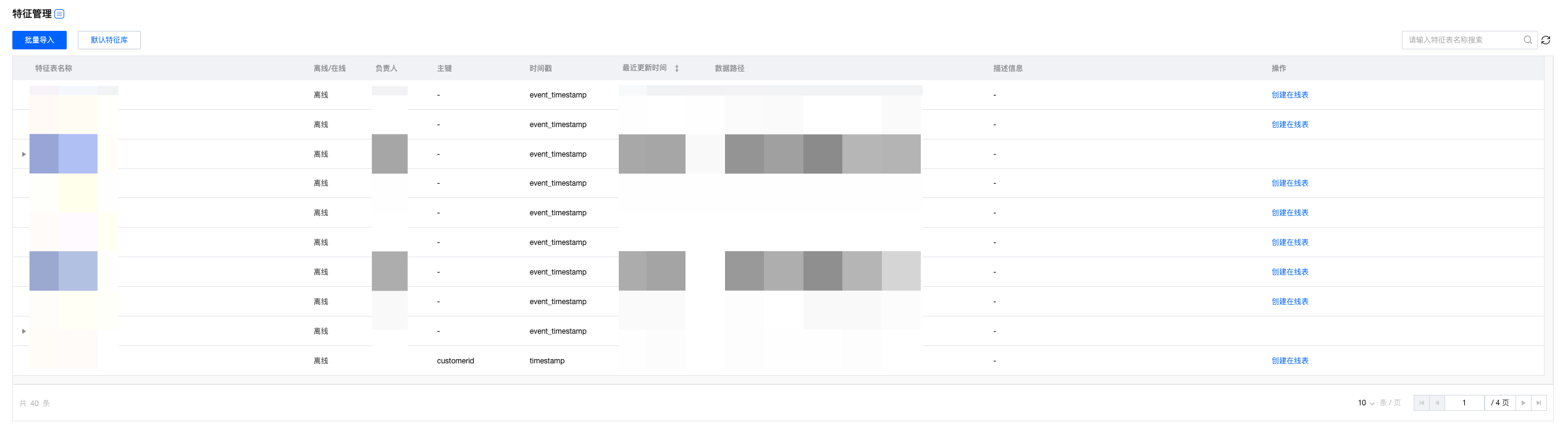
特征管理页面支持索引查看离线特征表和在线特征表的元信息:
列表页支持查看特征表名、离/在线情况、责任人、主键、时间戳、上次修改时间、数据地址、描述、操作项。
列表中在线特征表信息默认收起
支持在未创建在线特征表的情况下,提供创建在线特征表的操作项
已经创建在线特征表的情况下,不提供在线特征表的操作项,且支持通过表名左侧的三角形展开对应在线特征表的信息
一个离线特征表,仅能创建一个在线特征表
删除离线特征表之前,必须先将对应的在线特征表删除,否则不提供删除按钮
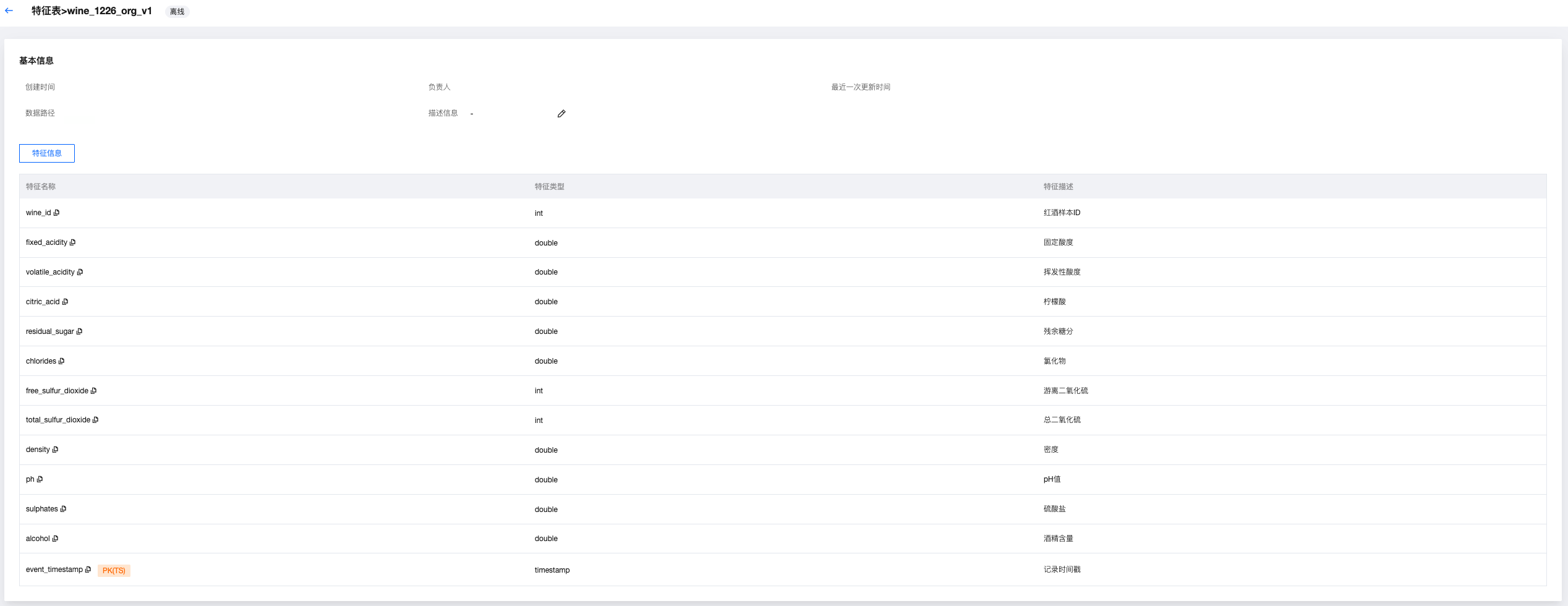
离线特征表详情
点击进入离线特征表详情后,可以查看创建时间、责任人、上次修改时间、数据地址、描述,且顶部会显示离线标签。
并支持查看特征信息,包括特征名、字段类型、特征描述,并且会标记出主键和时间戳。
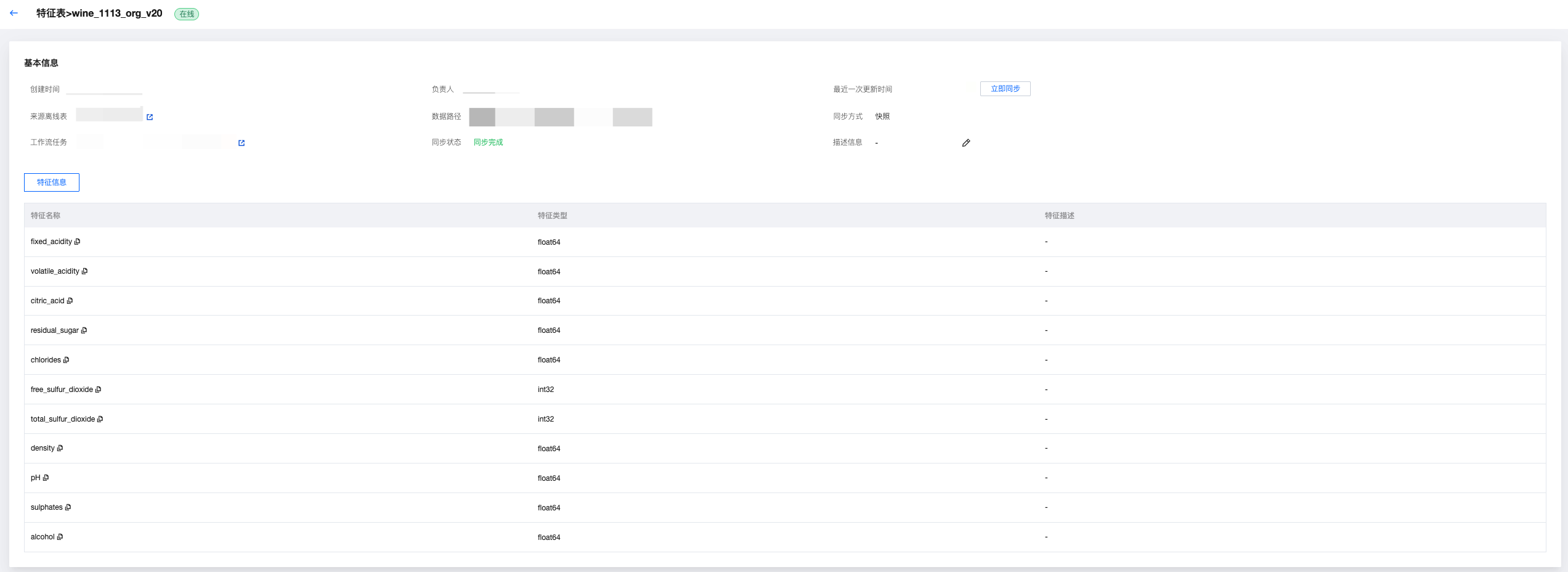
在线特征表详情
点击进入在线特征表详情后,可以查看创建时间、责任人、同步时间(支持立即同步)、来源离线表(支持点击跳转至相应的离线表页面)、数据地址、同步方式、工作流任务(支持点击跳转至相应的特征同步工作流的页面)、同步状态、描述。
并支持查看特征信息,包括特征名、字段类型、特征描述,并且会标记出主键和时间戳。
特征工程 API
FeatureStoreClient 是 WeData 特征存储的统一客户端,提供特征全生命周期管理能力,包括特征表创建、注册、读写、训练集创建、模型记录等功能。
说明:
当开启 Catalog 功能后,部分 API 需要传入 Catalog_name,请注意查看 API 文档。
使用前,需要在 Studio 的运行环境中安装最新的特征工程 API 包。
%pip install tencent-wedata-feature-engineering
如果使用 DLC 引擎,构建资源组时选择“wedata-data-science”镜像,已经预安装特征工程包,无需额外安装。可执行命令检查版本:
%pip list | grep tencent-wedata-feature-engineering
初始化特征工程客户端
init
init API 可用于初始化 FeatureStoreClient 实例。
输入参数
参数名 | 是否必填 | 字段类型 | 字段说明 | 入参示例 |
spark | 是 | Optional[SparkSession] | 已初始化的 SparkSession 对象,如未提供则自动创建 | SparkSession.builder.getOrCreate() |
cloud_secret_id | 是 | str | 云服务密钥 ID | "your_secret_id" |
cloud_secret_key | 是 | str | 云服务密钥 | "your_secret_key" |
输出参数
结果名 | 字段类型 | 字段说明 |
client | FeatureStoreClient | 返回 FeatureStoreClient 实例 |
调用示例
from wedata.feature_store.client import FeatureStoreClient# 构建特征工程客户端实例# create FeatureStoreClientclient = FeatureStoreClient(spark, cloud_secret_id=cloud_secret_id, cloud_secret_key=cloud_secret_key)
错误码
无特定错误码,SparkSession 创建失败会抛出相关异常。
离线特征表操作
create_table
创建特征表(支持批流数据写入)。
输入参数
参数名 | 是否必填 | 字段类型 | 字段说明 | 入参示例 |
name | 是 | str | 特征表全称(格式:<table>) | "user_features" |
primary_keys | 是 | Union[str, List[str]] | 主键列名(支持复合主键) | "user_id" 或 ["user_id", "session_id"] |
timestamp_key | 是 | str | 时间戳键(用于时态特征) | "timestamp" |
engine_type | 是 | wedata.feature_store.constants.engine_types.EngineTypes | 引擎类型 EngineTypes.HIVE_ENGINE -- HIVE 引擎 EngineTypes. ICEBERG_ENGINE -- ICEBERG 引擎 | EngineTypes.HIVE_ENGINE |
data_source_name | 是 | str | 数据源名称 | "hive_datasource" |
database_name | 否 | Optional[str] | 数据库名 | "feature_db" |
df | 否 | Optional[DataFrame] | 初始数据(用于推断 schema) | spark.createDataFrame([...]) |
partition_columns | 否 | Union[str, List[str], None] | 分区列(优化存储查询) | "date" 或 ["date", "region"] |
schema | 否 | Optional[StructType] | 表结构定义(当不提供 df 时必需) | StructType([...]) |
description | 否 | Optional[str] | 业务描述 | "用户特征表" |
tags | 否 | Optional[Dict[str, str]] | 业务标签 | {"domain": "user", "version": "v1"} |
catalog_name | 如果未开启 catalog,则无需填入 如果开启 catalog,则必填 | str | 特征表所在的 catalog 名 | "DataLakeCatalog" |
输出参数
结果名 | 字段类型 | 字段说明 |
feature_table | FeatureTable | 包含特征表元数据的 FeatureTable 对象 |
调用示例
from wedata.feature_store.constants.engine_types import EngineTypes# 创建用户特征表--EMR on hive# create user's feature table--EMR on hivefeature_table = client.create_table(name=table_name, # 表名primary_keys=["wine_id"], # 主键df=wine_features_df, # 数据engine_type=EngineTypes.HIVE_ENGINE,data_source_name=data_source_name,timestamp_key="event_timestamp",tags={ # 业务标签"purpose": "demo","create_by": "wedata"})# 创建用户特征表--DLC on iceberg(不开启catalog)# create user's feature table--DLC on iceberg(disable catalog)feature_table = client.create_table(name=table_name, # 表名database_name=database_name,primary_keys=["wine_id"], # 主键df=wine_features_df, # 数据engine_type=EngineTypes.ICEBERG_ENGINE,data_source_name=data_source_name,timestamp_key="event_timestamp",tags={ # 业务标签"purpose": "demo","create_by": "wedata"})# 创建用户特征表--DLC on iceberg(开启catalog)# create user's feature table--DLC on iceberg(enable catalog)feature_table = client.create_table(name=table_name, # 表名primary_keys=["wine_id"], # 主键df=wine_features_df, # 数据engine_type=EngineTypes.ICEBERG_ENGINE,data_source_name=data_source_name,timestamp_key="event_timestamp",tags={ # 业务标签"purpose": "demo","create_by": "wedata"},catalog_name=catalog_name)
错误码
ValueError:当 schema 与数据不匹配时会进行报错。
register_table
将普通的表注册为特征表,并返回特征表数据。
输入参数
参数名 | 是否必填 | 字段类型 | 字段说明 | 入参示例 |
name | 是 | str | 特征表名称 | "user_features" |
timestamp_key | 是 | str | 时间戳键(用于后续离在线特征同步) | "timestamp" |
engine_type | 是 | wedata.feature_store.constants.engine_types.EngineTypes | 引擎类型 EngineTypes.HIVE_ENGINE -- HIVE 引擎 EngineTypes. ICEBERG_ENGINE -- ICEBERG 引擎 | EngineTypes.HIVE_ENGINE |
data_source_name | 是 | str | 数据源名称 | "hive_datasource" |
database_name | 否 | Optional[str] | 特征库名称 | "feature_db" |
primary_keys | 否 | Union[str, List[str]] | 主键列名(仅当 engine_type 为 EngineTypes.HIVE_ENGINE 时有效) | "user_id" |
catalog_name | 如果未开启 catalog,则无需填入 如果开启 catalog,则必填 | str | 特征表所在的 catalog 名 | "DataLakeCatalog" |
输出参数
结果名 | 字段类型 | 字段说明 |
dataframe | pyspark.DataFrame | 包含特征表数据的 DataFrame 对象 |
调用示例
from wedata.feature_store.constants.engine_types import EngineTypes# 注册特征表--EMR on hive# register feature table--EMR on hiveclient.register_table(database_name=database_name, name=register_table_name, timestamp_key="event_timestamp",engine_type=EngineTypes.HIVE_ENGINE, data_source_name=data_source_name, primary_keys=["wine_id",])# 注册特征表--DLC on iceberg(不开启catalog)# register feature table--DLC on iceberg(disable catalog)client.register_table(database_name=database_name, name=register_table_name, timestamp_key="event_timestamp",engine_type=EngineTypes.ICEBERG_ENGINE, data_source_name=data_source_name, primary_keys=["wine_id",])# 注册特征表--DLC on iceberg(开启catalog)# register feature table--DLC on iceberg(enable catalog)client.register_table(database_name=database_name, name=register_table_name, timestamp_key="event_timestamp",engine_type=EngineTypes.HIVE_ENGINE, data_source_name=data_source_name, primary_keys=["wine_id",], catalog_name=catalog_name)
错误码
无特定错误码。
read_table
读取特征表数据。
输入参数
参数名 | 是否必填 | 字段类型 | 字段说明 | 入参示例 |
name | 是 | str | 特征表名称 | "user_features" |
database_name | 否 | Optional[str] | 特征库名 | "feature_db" |
is_online | 否 | bool | 是否读取在线特征表(默认False) | True |
online_config | 否 | Optional[RedisStoreConfig] | 在线特征表配置(仅当is_online为 True 时有效) | RedisStoreConfig(...) |
entity_row | 否 | Optional[List[Dict[str, Any]]] | 实体行数据(仅当is_online为 True 时有效) | [{"user_id": ["123", "456"]}] |
catalog_name | 如果未开启 catalog,则无需填入 如果开启 catalog,则必填 | str | 特征表所在的 catalog 名 | "DataLakeCatalog" |
输出参数
结果名 | 字段类型 | 字段说明 |
dataframe | pyspark.DataFrame | 包含特征表数据的 DataFrame 对象 |
调用示例
# 读取离线特征表--EMR on hive--&--DLC on iceberg(不开启catalog)# read offline feature table--EMR on hive--&--DLC on iceberg(disable catalog)get_df = client.read_table(name=table_name, database_name=database_name)get_df.show(30)# 读取在线特征表--EMR on hive--&--DLC on iceberg(不开启catalog)# read online feature table--EMR on hive--&--DLC on iceberg(disable catalog)online_config = RedisStoreConfig(host=redis_host, port=redis_password, db=redis_db, password=redis_password)primary_keys_rows = [{"wine_id": 1},{"wine_id": 3}]result = client.read_table(name=table_name,database_name=database_name, is_online=True, online_config=online_config, entity_row=primary_keys_rows)result.show()# 读取离线特征表--DLC on iceberg(开启catalog)# read offline feature table--DLC on iceberg(enable catalog)get_df = client.read_table(name=table_name, database_name=database_name, catalog_name=catalog_name)get_df.show(30)# 读取在线特征表--DLC on iceberg(开启catalog)# read online feature table--DLC on iceberg(enable catalog)primary_keys_rows = [{"wine_id": 1},{"wine_id": 3}]result = client.read_table(name=table_name,database_name=database_name, is_online=True, online_config=online_config, entity_row=primary_keys_rows, catalog_name=catalog_name)result.show()
错误码
无特定错误码。
get_table
获取特征表数据。
输入参数
参数名 | 是否必填 | 字段类型 | 字段说明 | 入参示例 |
name | 是 | str | 特征表名称 | "user_features" |
database_name | 否 | Optional[str] | 特征库名 | "feature_db" |
catalog_name | 如果未开启 catalog,则无需填入 如果开启 catalog,则必填 | str | 特征表所在的 catalog 名 | "DataLakeCatalog" |
输出参数
结果名 | 字段类型 | 字段说明 |
feature_table | FeatureTable | 包含特征表元数据的 FeatureTable 对象 |
调用示例
# 获取特征表数据--EMR on hive--&--DLC on iceberg(不开启catalog)# get feature table data--EMR on hive--&--DLC on iceberg(disable catalog)featureTable = client.get_table(name=table_name, database_name=database_name)# 读取在线特征表--DLC on iceberg(开启catalog)# get feature table data--DLC on iceberg(enable catalog)featureTable = client.get_table(name=table_name, database_name=database_name, catalog_name=catalog_name)
错误码
无特定错误码。
drop_table
删除特征表。
输入参数
参数名 | 是否必填 | 字段类型 | 字段说明 | 入参示例 |
name | 是 | str | 要删除的特征表名称 | "user_features" |
database_name | 否 | Optional[str] | 特征库名 | "feature_db" |
catalog_name | 如果开启 catalog,则必填 | str | 特征表所在的 catalog 名 | "DataLakeCatalog" |
输出参数
结果名 | 字段类型 | 字段说明 |
无 | None | 无返回值 |
调用示例
# 删除特征表--EMR on hive--&--DLC on iceberg(不开启catalog)# drop feature table data--EMR on hive--&--DLC on iceberg(disable catalog)client.drop_table(table_name)# 删除特征表--DLC on iceberg(开启catalog)# drop feature table data--DLC on iceberg(enable catalog)client.drop_table(table_name,catalog_name="DataLakeCatalog")
错误码
无特定错误码。
write_table
写入数据到特征表(支持批处理和流式处理)。
输入参数
参数名 | 是否必填 | 字段类型 | 字段说明 | 入参示例 |
name | 是 | str | 特征表全称(格式:<table>) | "user_features" |
df | 否 | Optional[DataFrame] | 要写入的数据 DataFrame | spark.createDataFrame([...]) |
database_name | 否 | Optional[str] | 特征库名 | "feature_db" |
mode | 否 | Optional[str] | 写入模式(默认 APPEND) | "overwrite" |
checkpoint_location | 否 | Optional[str] | 流式处理的检查点位置 | "/checkpoints/user_features" |
trigger | 否 | Dict[str, Any] | 流式处理触发器配置 | {"processingTime": "10 seconds"} |
catalog_name | 如果未开启 catalog,则无需填入 如果开启 catalog,则必填 | str | 特征表所在的 catalog 名 | "DataLakeCatalog" |
输出参数
结果名 | 字段类型 | 字段说明 |
streaming_query | Optional[StreamingQuery] | 如果是流式写入返回 StreamingQuery 对象,否则返回 None |
调用示例
from wedata.feature_store.constants.constants import APPEND# 批处理写入--EMR on hive--&--DLC on iceberg(不开启catalog)# batch write--EMR on hive--&--DLC on iceberg(disable catalog)client.write_table(name="user_features",df=user_data_df,database_name="feature_db",mode="append")# 流式处理写入--EMR on hive--&--DLC on iceberg(不开启catalog)# strem write--EMR on hive--&--DLC on iceberg(disable catalog)streaming_query = client.write_table(name="user_features",df=streaming_df,database_name="feature_db",checkpoint_location="/checkpoints/user_features",trigger={"processingTime": "10 seconds"})# 批处理写入--DLC on iceberg(开启catalog)# batch write--EMR on hive--&--DLC on iceberg(enable catalog)client.write_table(name="user_features",df=user_data_df,database_name="feature_db",mode="append",catalog_name=catalog_name)# 流式处理写入--DLC on iceberg(开启catalog)# strem write--EMR on hive--&--DLC on iceberg(enable catalog)streaming_query = client.write_table(name="user_features",df=streaming_df,database_name="feature_db",checkpoint_location="/checkpoints/user_features",trigger={"processingTime": "10 seconds"},catalog_name=catalog_name)
错误码
无特定错误码。
离线特征消费
Feature Lookup
对特征表进行特征查找。
输入参数
参数名 | 是否必填 | 字段类型 | 字段说明 | 入参示例 |
table_name | 是 | str | 特征表的名称 | "user_features" |
lookup_key | 是 | Union[str, List[str]] | 用于在特征表和训练集之间进行联接的键,一般使用主键 | "user_id" 或 ["user_id", "session_id"] |
is_online | 否 | bool | 是否读取在线特征表(默认False) | True |
online_config | 否 | Optional[RedisStoreConfig] | 在线特征表配置(仅当is_online为True 时有效) | RedisStoreConfig(...) |
feature_names | 否 | Union[str, List[str], None] | 要从特征表中查找的特征名称 | ["age", "gender", "preferences"] |
rename_outputs | 否 | Optional[Dict[str, str]] | 特征重命名映射 | {"age": "user_age"} |
timestamp_lookup_key | 否 | Optional[str] | 用于时间点查找的时间戳键 | "event_timestamp" |
lookback_window | 否 | Optional[datetime.timedelta] | 时间点查找的回溯窗口 | datetime.timedelta(days=1) |
输出参数
结果名 | 字段类型 | 字段说明 |
FeatureLookup 对象 | FeatureLookup | 构造完成的 FeatureLookup 实例 |
调用示例
from wedata.feature_store.entities.feature_lookup import FeatureLookup# 特征查找--EMR on hive--&--DLC on iceberg(不开启catalog)--&--DLC on iceberg(开启catalog)# feature lookup--EMR on hive--&--DLC on iceberg(disable catalog)--&--DLC on iceberg(enable catalog)wine_feature_lookup = FeatureLookup(table_name=table_name,lookup_key="wine_id",timestamp_lookup_key="event_timestamp")
错误码
无特定错误码。
create_training_set
对特征表进行特征查找。
输入参数
参数名 | 是否必填 | 字段类型 | 字段说明 | 入参示例 |
df | 否 | Optional[DataFrame] | 要写入的数据 DataFrame | spark.createDataFrame([...]) |
feature_lookups | 是 | List[Union[FeatureLookup, FeatureFunction]] | 特征查询列表 | [FeatureLookup(...), FeatureFunction(...)] |
label | 是 | Union[str, List[str], None] | 标签列名 | "is_churn" 或 ["label1", "label2"] |
exclude_columns | 否 | Optional[List[str]] | 排除列名 | ["user_id", "timestamp"] |
database_name | 否 | Optional[str] | 特征库名 | "feature_db" |
catalog_name | 如果未开启 catalog,则无需填入 如果开启 catalog,则必填 | str | 特征表所在的 catalog 名 | "DataLakeCatalog" |
输出参数
结果名 | 字段类型 | 字段说明 |
training_set | TrainingSet | 构造完成的 TrainingSet 实例 |
调用示例
from wedata.feature_store.entities.feature_lookup import FeatureLookupfrom wedata.feature_store.entities.feature_function import FeatureFunction# 定义特征查找# define feature lookupwine_feature_lookup = FeatureLookup(table_name=table_name,lookup_key="wine_id",timestamp_lookup_key="event_timestamp")# 构建训练数据# prepare training datainference_data_df = wine_df.select(f"wine_id", "quality", "event_timestamp")# 创建训练集--EMR on hive--&--DLC on iceberg(不开启catalog)# create trainingset--EMR on hive--&--DLC on iceberg(disable catalog)training_set = client.create_training_set(df=inference_data_df, # 基础数据feature_lookups=[wine_feature_lookup], # 特征查找配置label="quality", # 标签列exclude_columns=["wine_id", "event_timestamp"] # 排除不需要的列)# 创建训练集--DLC on iceberg(开启catalog)# create trainingset--DLC on iceberg(enable catalog)training_set = client.create_training_set(df=inference_data_df, # 基础数据feature_lookups=[wine_feature_lookup], # 特征查找配置label="quality", # 标签列exclude_columns=["wine_id", "event_timestamp"], # 排除不需要的列database_name=database_name,catalog_name=catalog_name)# 获取最终的训练DataFrame# get final training DataFrametraining_df = training_set.load_df()# 打印训练集数据# print trainingset dataprint(f"\\n=== 训练集数据 ===")training_df.show(10, True)
错误码
ValueError: FeatureLookup 必须指定 table_name。
log_model
记录 MLflow 模型并关联特征查找信息。
输入参数
参数名 | 是否必填 | 字段类型 | 字段说明 | 入参示例 |
model | 是 | Any | 要记录的模型对象 | sklearn.RandomForestClassifier() |
artifact_path | 是 | str | 模型存储路径 | "churn_model" |
flavor | 是 | ModuleType | MLflow 模型类型模块 | mlflow.sklearn |
training_set | 否 | Optional[TrainingSet] | 训练模型使用的 TrainingSet 对象 | training_set |
registered_model_name | 否 | Optional[str] | 要注册的模型名称(开启 catalog 后需要写 catalog 的模型名称) | "churn_prediction_model" |
model_registry_uri | 否 | Optional[str] | 模型注册中心地址 | "databricks://model-registry" |
await_registration_for | 否 | int | 等待模型注册完成的秒数(默认300秒) | 600 |
infer_input_example | 否 | bool | 是否自动记录输入示例(默认False) | True |
输出参数
无
调用示例
# 训练模型# train modelfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import classification_reportfrom sklearn.ensemble import RandomForestClassifierimport mlflow.sklearnimport pandas as pdimport osproject_id=os.environ["WEDATA_PROJECT_ID"]mlflow.set_experiment(experiment_name=expirement_name)# 设置mlflow信息上报地址# set mlflow tracking_urimlflow.set_tracking_uri("http://30.22.36.75:5000")# 将Spark DataFrame转换为Pandas DataFrame用于训练# convert Spark DataFrame to Pandas DataFrame to traintrain_pd = training_df.toPandas()# 删除时间戳列# delete timestamp# train_pd.drop('event_timestamp', axis=1)# 准备特征和标签# prepare features and tagsX = train_pd.drop('quality', axis=1)y = train_pd['quality']# 划分训练集和测试集# split traningset and testsetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 或者把日期转成时间戳(秒)# or convert datatime to timestamp(second)for col in X_train.select_dtypes(include=['datetime', 'datetimetz']):X_train[col] = X_train[col].astype('int64') // 10**9 # 纳秒→秒# 确认没有缺失值导致 dtype 被降级为 object# Verify that no missing values cause the dtype to be downgraded to object.X_train = X_train.fillna(X_train.median(numeric_only=True))# 初始化并训练模型和记录模型--EMR on hive--&--DLC on iceberg(不开启catalog)--&--DLC on iceberg(开启catalog)# Initialize, train and log the model.--EMR on hive--&--DLC on iceberg(disable catalog)--&--DLC on iceberg(enable catalog)model = RandomForestClassifier(n_estimators=100, max_depth=3, random_state=42)model.fit(X_train, y_train)with mlflow.start_run():client.log_model(model=model,artifact_path="wine_quality_prediction", # 模型文件路径名model artifact pathflavor=mlflow.sklearn,training_set=training_set,registered_model_name=model_name, # 模型名称(开启catalog后需要写catalog的模型名称)model name(if enable catalog, must be catalog model name))
错误码
无特定错误码。
score_batch
执行批量推理,如果输入特征缺失(但注意需要传入对应的主键),推理过程中会按照模型所记录的 feature_spec 文件来自动执行特征补全。
输入参数
参数名 | 是否必填 | 字段类型 | 字段说明 | 入参示例 |
model_uri | 是 | str | MLflow 模型 URI 位置 | "models:/churn_model/1" |
df | 是 | DataFrame | 要推理的 DataFrame | spark.createDataFrame([...]) |
result_type | 否 | str | 模型返回类型(默认"double") | "string" |
输出参数
结果名 | 字段类型 | 字段说明 |
predictions | DataFrame | 包含预测结果的 DataFrame |
调用示例
# 运行score_batch--EMR on hive--&--DLC on iceberg(不开启catalog)--&--DLC on iceberg(开启catalog)# run score_batch--EMR on hive--&--DLC on iceberg(disable catalog)--&--DLC on iceberg(enable catalog)result = client.score_batch(model_uri=f"models:/{model_name}/1", df=wine_df)result.show()
错误码
无特定错误码。
在线特征表操作
publish_table
发布离线特征表为一个在线特征表。
输入参数
参数名 | 是否必填 | 字段类型 | 字段说明 | 入参示例 |
table_name | 是 | str | 离线特征表全称(格式:<table>) | "user_features" |
data_source_name | 是 | str | 数据源名称 | "hive_datasource" |
database_name | 否 | Optional[str] | 数据库名 | "feature_db" |
is_cycle | 否 | bool | 是否启用周期性发布(默认False) | True |
cycle_obj | 否 | TaskSchedulerConfiguration | 周期性任务配置对象 | TaskSchedulerConfiguration(...) |
is_use_default_online | 否 | bool | 是否使用默认在线存储配置(默认 True) | False |
online_config | 否 | RedisStoreConfig | 自定义在线存储配置 | RedisStoreConfig(...) |
catalog_name | 如果未开启 catalog,则无需填入 如果开启 catalog,则必填 | str | 特征表所在的 catalog 名 | "DataLakeCatalog" |
输出参数
结果名 | 字段类型 | 字段说明 |
无 | None | 无返回值 |
调用示例
from wedata.feature_store.common.store_config.redis import RedisStoreConfigfrom wedata.feature_store.cloud_sdk_client.models import TaskSchedulerConfigurationonline_config = RedisStoreConfig(host=redis_host, port=redis_password, db=redis_db, password=redis_password)# 将离线特征表发布成为在线特征表--EMR on hive--&--DLC on iceberg(不开启catalog)# publish a offline feature table to online feature table--EMR on hive--&--DLC on iceberg(disable catalog)# Case 1 将离线表table_name通过指定离线数据源传入到默认在线数据源,并采用快照方式# Case 1 Pass the offline table table_name from the specified offline data source to the default online data source in snapshot mode.result = client.publish_table(table_name=table_name, data_source_name=data_source_name, database_name=database_name,is_cycle=False, is_use_default_online=True)# Case 2 将离线表table_name通过指定离线数据源传入到指定数据源(非默认),并采用快照方式, 需注意这里的IP要与录入的数据源中登录的数据源IP信息一致。# Case 2 Sync the offline table table_name from the specified offline data source to the designated non-default data source in snapshot mode. Note that the IP address here must be consistent with the login IP information of the entered data source.result = client.publish_table(name=table_name, data_source_name=data_source_name, database_name=database_name,is_cycle=False, is_use_default_online=False, online_config=online_config)# Case 3 将离线表table_name通过指定离线数据源传入到默认在线数据源,并采用周期的方式,每五分钟运行一次# Sync the offline table table_name from the specified offline data source to the default online data source in cycle mode, with a run interval of every five minutes.cycle_obj = TaskSchedulerConfiguration()cycle_obj.CrontabExpression = "0 0/5 * * * ?"result = client.publish_table(name=table_name, data_source_name=data_source_name, database_name=database_name,is_cycle=True, cycle_obj=cycle_obj, is_use_default_online=True)# 将离线特征表发布成为在线特征表--DLC on iceberg(开启catalog)# publish a offline feature table to online feature table--DLC on iceberg(enable catalog)# Case 1 将离线表table_name通过指定离线数据源传入到默认在线数据源,并采用快照方式# Case 1 Pass the offline table table_name from the specified offline data source to the default online data source in snapshot mode.result = client.publish_table(table_name=table_name, data_source_name=data_source_name, database_name=database_name,is_cycle=False, is_use_default_online=True, catalog_name=catalog_name)# Case 2 将离线表table_name通过指定离线数据源传入到指定数据源(非默认),并采用快照方式, 需注意这里的IP要与录入的数据源中登录的数据源IP信息一致。# Case 2 Sync the offline table table_name from the specified offline data source to the designated non-default data source in snapshot mode. Note that the IP address here must be consistent with the login IP information of the entered data source.result = client.publish_table(table_name=table_name, data_source_name=data_source_name, database_name=database_name,is_cycle=False, is_use_default_online=False, online_config=online_config, catalog_name=catalog_name)# Case 3 将离线表table_name通过指定离线数据源传入到默认在线数据源,并采用周期的方式,每五分钟运行一次# Sync the offline table table_name from the specified offline data source to the default online data source in cycle mode, with a run interval of every five minutes.cycle_obj = TaskSchedulerConfiguration()cycle_obj.CrontabExpression = "0 0/5 * * * ?"result = client.publish_table(table_name=table_name, data_source_name=data_source_name, database_name=database_name,is_cycle=True, cycle_obj=cycle_obj, is_use_default_online=True, catalog_name=catalog_name)
错误码
无特定错误码。
drop_online_table
删除在线特征表。
输入参数
参数名 | 是否必填 | 字段类型 | 字段说明 | 入参示例 |
table_name | 是 | str | 离线特征表全称(格式:<table>) | "user_features" |
online_config | 否 | RedisStoreConfig | 自定义在线存储配置 | RedisStoreConfig(...) |
database_name | 否 | Optional[str] | 数据库名 | "feature_db" |
输出参数
结果名 | 字段类型 | 字段说明 |
无 | None | 无返回值 |
调用示例
from wedata.feature_store.common.store_config.redis import RedisStoreConfig# 删除在线表--EMR on hive--&--DLC on iceberg(不开启catalog)--&--DLC on iceberg(开启catalog)# delete online feature table--EMR on hive--&--DLC on iceberg(disable catalog)--&--DLC on iceberg(enable catalog)online_config = RedisStoreConfig(host=redis_host, port=redis_password, db=redis_db, password=redis_password)client.drop_online_table(table_name=table_name, database_name=database_name, online_config=online_config)
错误码
无特定错误码。



