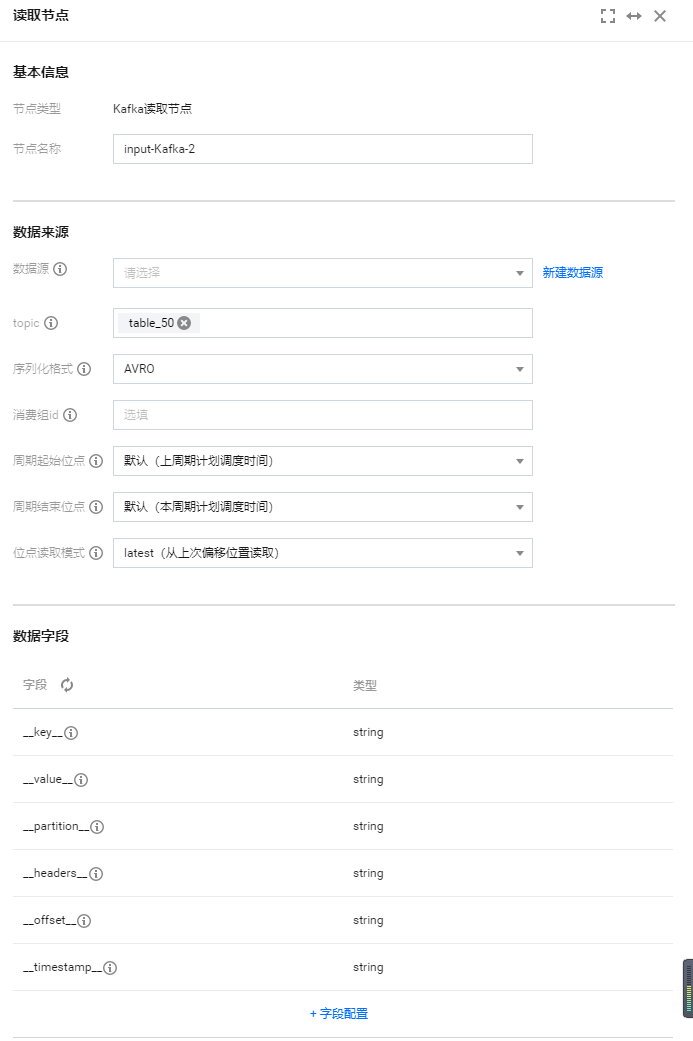
消费组当前位点:从任务配置上面指定的消费群组 ID 保存的位点开始读取数据,一般是使用这个群组 ID 读数据的进程上次停止的位点(最好确保使用这个群组 ID 的进程只有配置的这个数据集成任务,避免共用群组 ID 造成数据丢失),如果使用群组当前位点,一定要配置消费群组 ID,否则数据集成任务会随机生成一个群组ID,而新的群组 ID 因为没有保存过位点,根据位点重置策略的不同会引起任务报错或从开始或结束位点开始读取数据。另外群组位点在客户端会定时自动提交到 Kafka 服务端,所以在任务失败后,如果重跑任务时,可能有数据重复或者丢失,另外向导模式下会自动丢弃读到的超过结束位点的记录,而这些丢弃数据的群组位点已经提交到服务端,在下一个周期任务运行时将无法读到这些丢弃的数据