WeData 支持集成 EMR 计算引擎创建 Hive、MR、Spark、Trino 和 Kyuubi 等任务,实现 EMR 中的表管理和任务配置。本文介绍 WeData 在 EMR 集群上进行任务开发的注意事项。
使用背景
弹性 MapReduce (EMR) 是基于云原生技术和泛 Hadoop 生态开源技术的安全、低成本、高可靠的开源大数据平台。提供易于部署及管理的 Hive、Spark、HBase、Flink、StarRocks、Iceberg、Alluxio 等开源大数据组件,帮助客户高效构建云端企业级数据湖技术架构。基于 WeData 和 EMR 可以快速构建基于开源大数据的数据仓库。详情请参见 EMR 创建和管理集群。
使用限制
限制类型 | 限制说明 |
弹性 MapReduce(EMR)集群类型 | 目前 WeData 支持 EMR on CVM 及 EMR on TKE 集群。 目前 EMR 支持创建的版本如下: "EMR-V2.0.1" "EMR-V2.2.0" "EMR-V2.3.0" "EMR-V2.5.0" "EMR-V2.6.0" "EMR-V2.7.0" "EMR-V3.0.0" "EMR-V3.1.0" "EMR-V3.2.0" "EMR-V3.2.1" "EMR-V3.3.0" "EMR-V3.4.0" "EMR-V3.5.0" |
WeData 功能 | WeData 数据开发中支持的 EMR 任务类型包括:HiveSQL、SparkSQL、Spark、MapReduce、PySpark、Shell、Impala、Trino。其中 Kyuubi 数据源需要使用 SparkSQL 类型的任务来使用。 |
使用流程
在 WeData 中使用 EMR 的主要流程包括以下步骤:
准备工作
准备类别 | 操作说明 | 参考链接 |
弹性 MapReduce(EMR) | 为了保证在 WeData 中顺利使用 EMR 相关的建表和数据开发功能,需要保证 EMR 集群满足基本的配置。至少需要 EMR 集群中安装 Hive 和 Spark 服务。其他服务如果在WeData 中使用也需要在 EMR中 做相应的开启。例如,ranger、Kyuubi 等。 | |
WeData | 绑定 EMR 的集群,从 EMR 集群中获取最新的集群配置。配置对应的认证方式和账号映射。 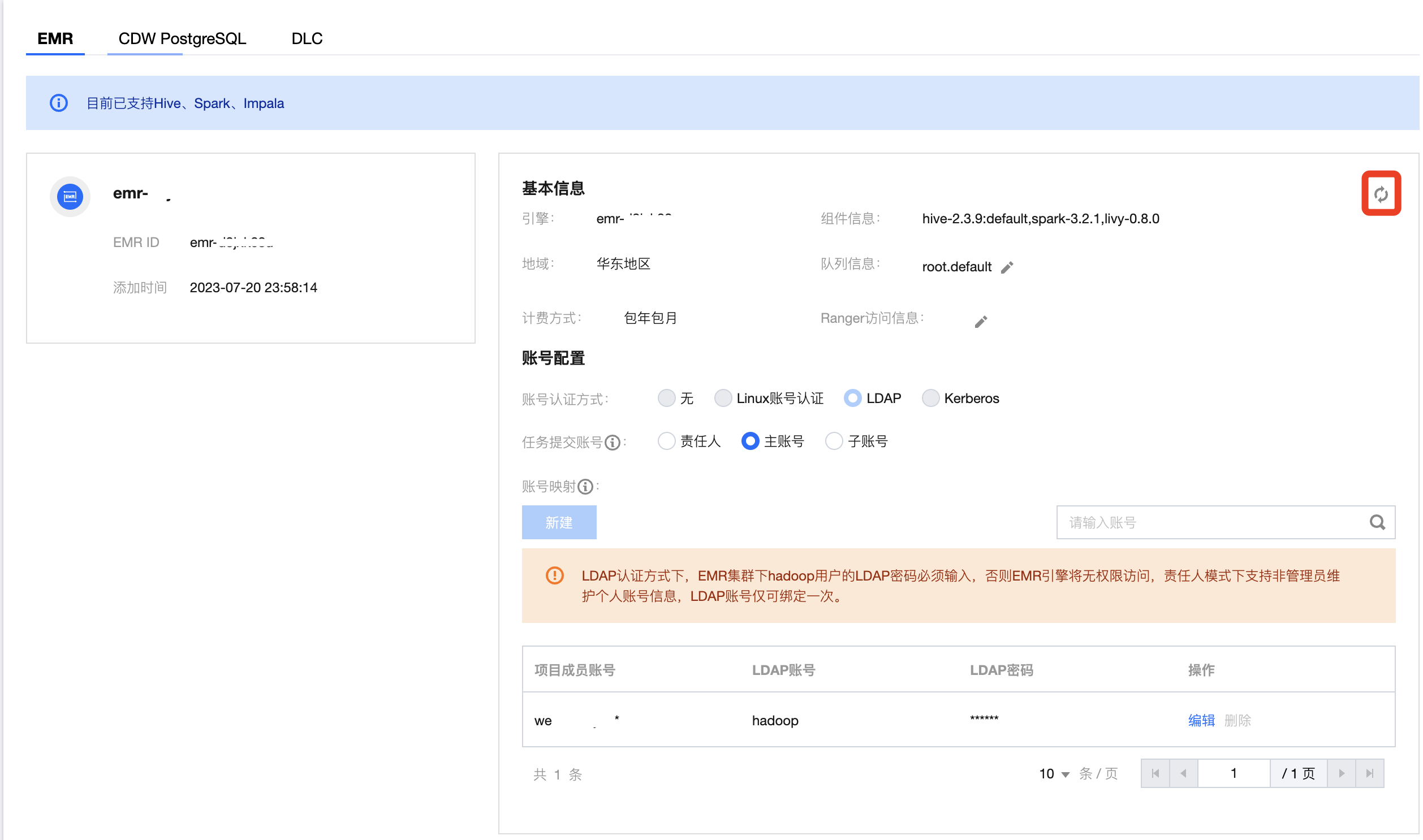 | - |
任务开发
创建工作流
任务开发基于数据工作流编排实现计算任务的流程化执行,创建计算任务前需要创建数据工作流,然后在工作流中编排计算任务运行流程。
创建 EMR 节点
WeData 基于 EMR 引擎进行任务开发,EMR 集群上不同类型的组件服务在 WeData 中默认作为系统数据源接入(Hive、Trino、kyuubi 和 Impala),用户可以根据业务需要选择合适的组件创建 EMR 服务资源,将 EMR 集群与 WeData 中的项目进行绑定。创建 EMR 组件服务,详情请参见 EMR 新增组件。
任务开发
完成 EMR 引擎与 WeData 项目绑定后,在已创建的数据工作流中创建 EMR 支持的计算任务类型,在任务节点的配置过程中,使用 EMR 提供的系统数据源进行任务开发、调试。
任务提交
使用 EMR 系统源数据配置调试无误后,保存对应的计算任务,再将计算任务所在的工作流提交发布后,即可在运维中心调度运行。
后续操作
EMR 任务开发完成后,可以在 WeData 进行 EMR 数据资产管理、数据质量监控与数据安全管理,保证 EMR 数据能够正常产出,并进行数据质量与数据安全方面的流程把控。



