功能简介
用于支持参数在上下游之间传递。例如:将当前任务的计算结果作为参数传递给子任务使用。多个结果可通过列号指定传递对象。
支持范围:Hive SQL、JDBC SQL、Python、Shell、Spark SQL、DLC SQL、Impala、TCHouse-P、DLC PySpark。
参数配置说明
1. 输出当前任务参数
若需要将参数从当前任务传递到下游,则在参数传递中勾选输出当前任务参数并配置参数信息。
输出参数传递给子任务,取值包含以下两种类型:
变量(n、m从0开始计算),支持传递二维数组,具体配置方式如下:
$[n][m]:获取第n行第m列的数据。
$[n][*]:表示获取第n行的数据。
$[*][n]:表示获取第n列的数据。
$[*][*]:表示获取所有行列的数据。
$[0]:表示获取首行第一列的数据。
常量:设置常量作为输出参数。
例如:父任务 A,在代码中计算结果有3列,分别为123,234, 1234, 在此配置中定义一个输出参数名 mark_id, 填写 mark_id = $[0],表示取计算结果首行第一列的值。
2. 引用父任务参数
若当前任务需要引用父任务中定义的参数,则在参数传递中勾选引用父任务参数。
填入定义的引入参数,选择该参数取值的父任务的输出参数(没有父节点则无选项),例如:子任务 B,任意定义参数名 mark_id,取值选择节点 A.mark_id,在代码中使用 ${mark_id},便会将 ${mark_id} 替换成字符串123 。
示例:如图定义参数名 a,取上游父任务 hivesql_1 中定义的参数 a;定义参数名 b,取上游父任务 hivesql_1 中定义的参数 b。
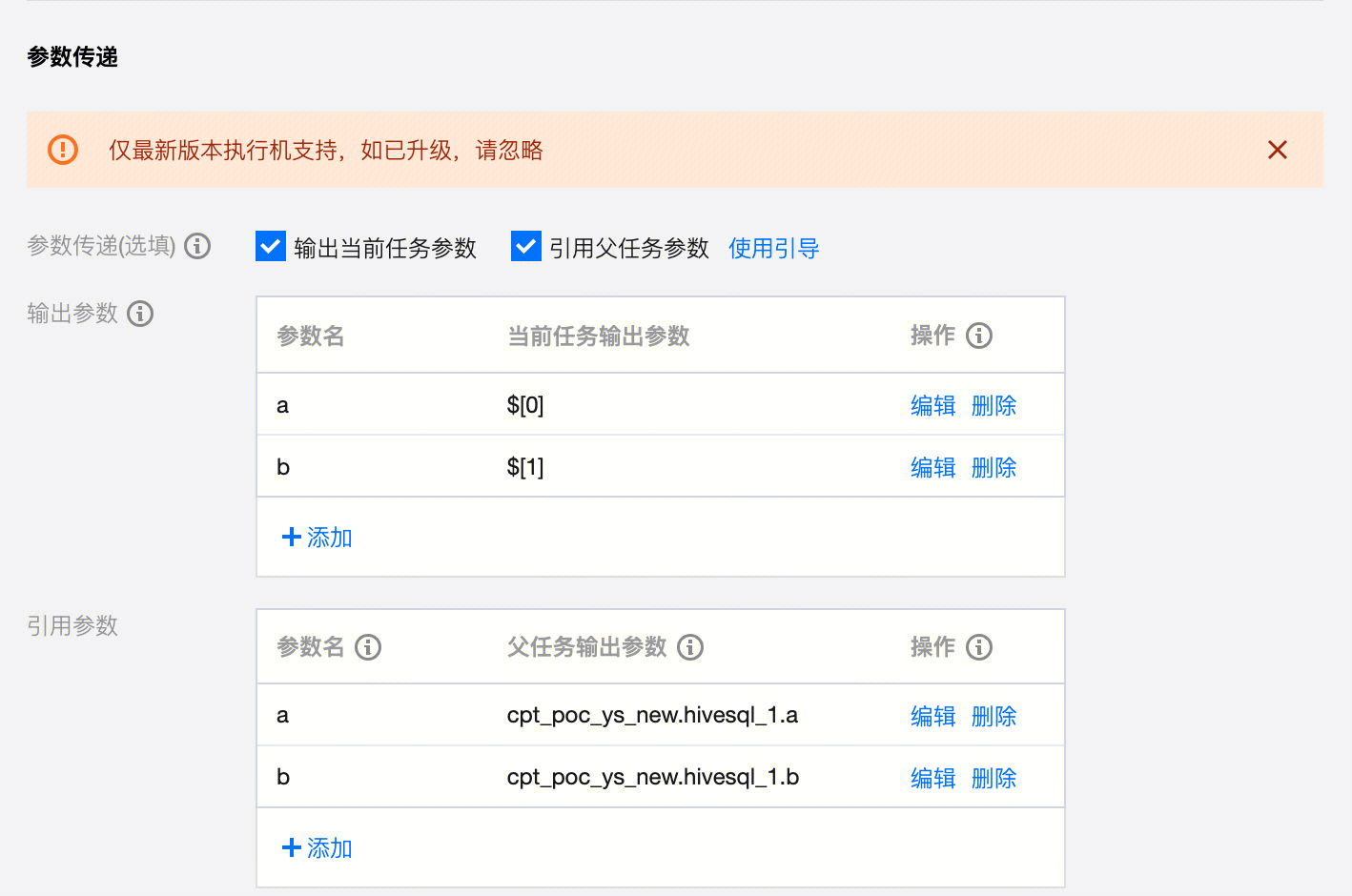
使用示例
分为三类:SQL 类、Shell 类、Python 类,以下为三种类型的使用示例(下文以传递常量为例,也支持传递变量)。
类型 | 任务类型 | 作为输出方(上游) | 作为输入方(下游) | 备注 | ||
| | 参数配置 | 代码 | 参数配置 | 代码 | |
SQL 类 | Hive SQL
JDBC SQL
Spark SQL
DLC SQL
Impala
TCHouse-P | 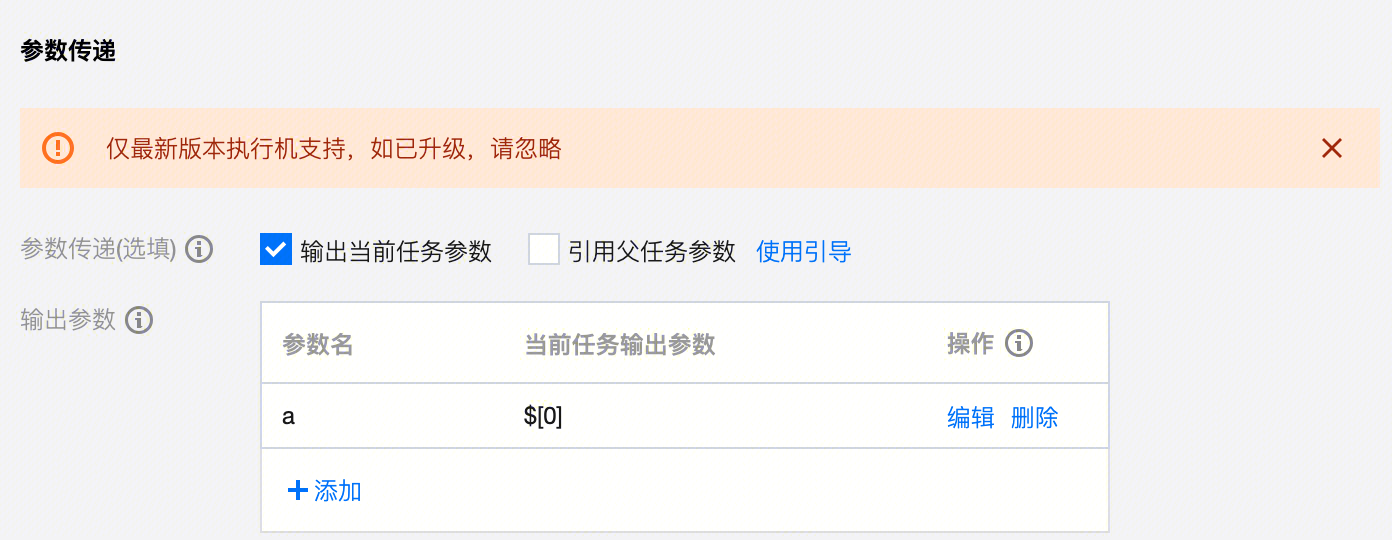 | SELECT "This is the value of the parameter" | 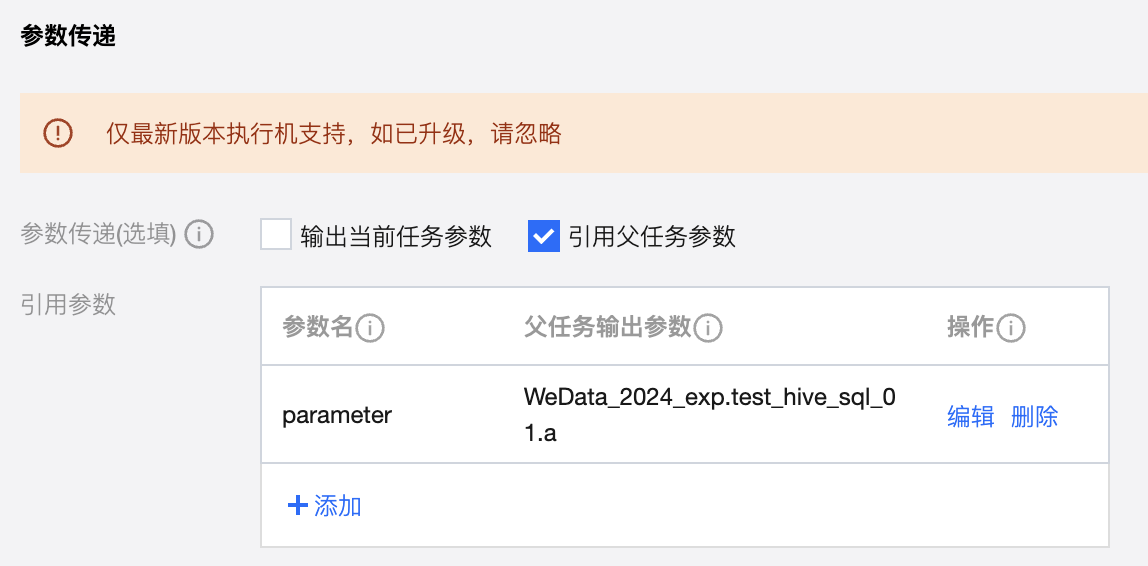 | SELECT '${parameter}' AS parameter_value; | |
Shell 类 | Shell | 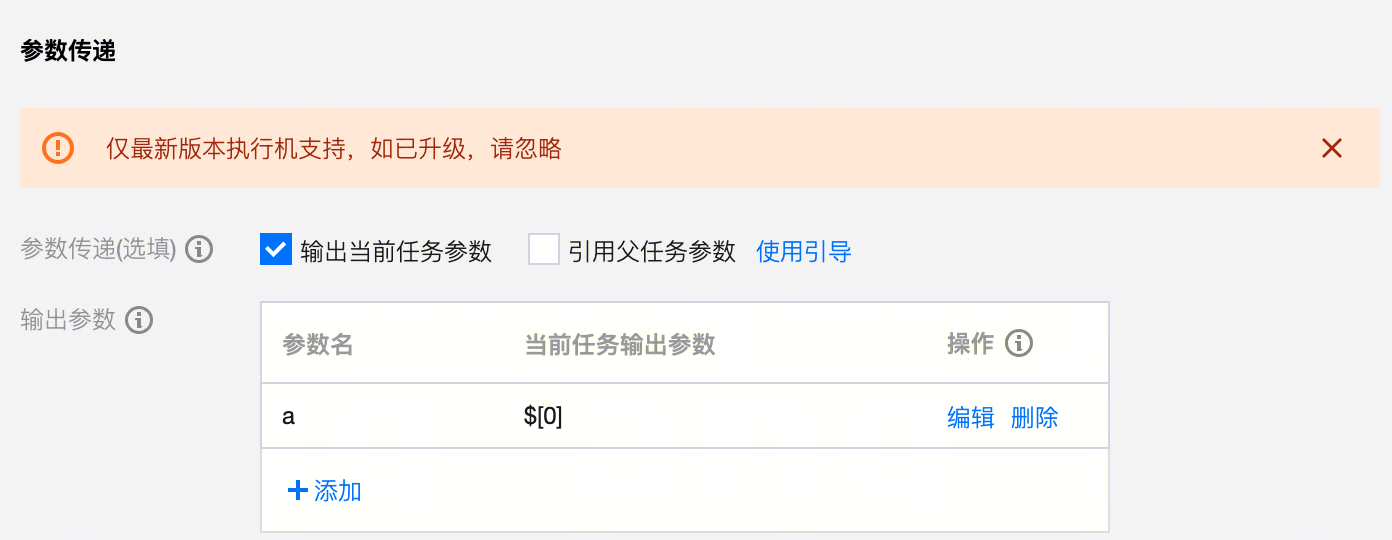 | echo "This is the value of the parameter" | 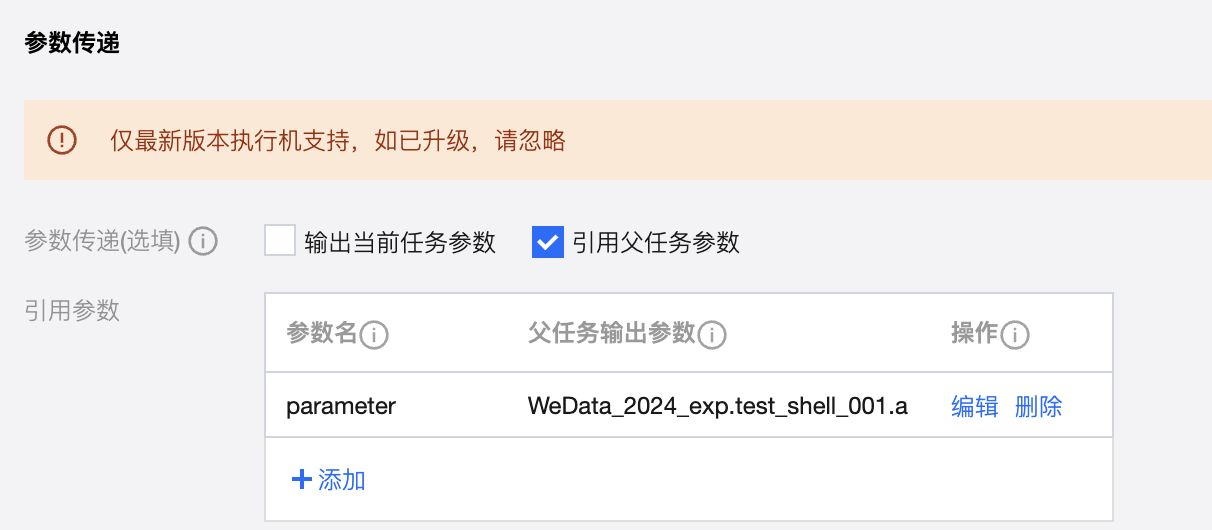 | expr ${parameter} | |
Python 类 | Python | 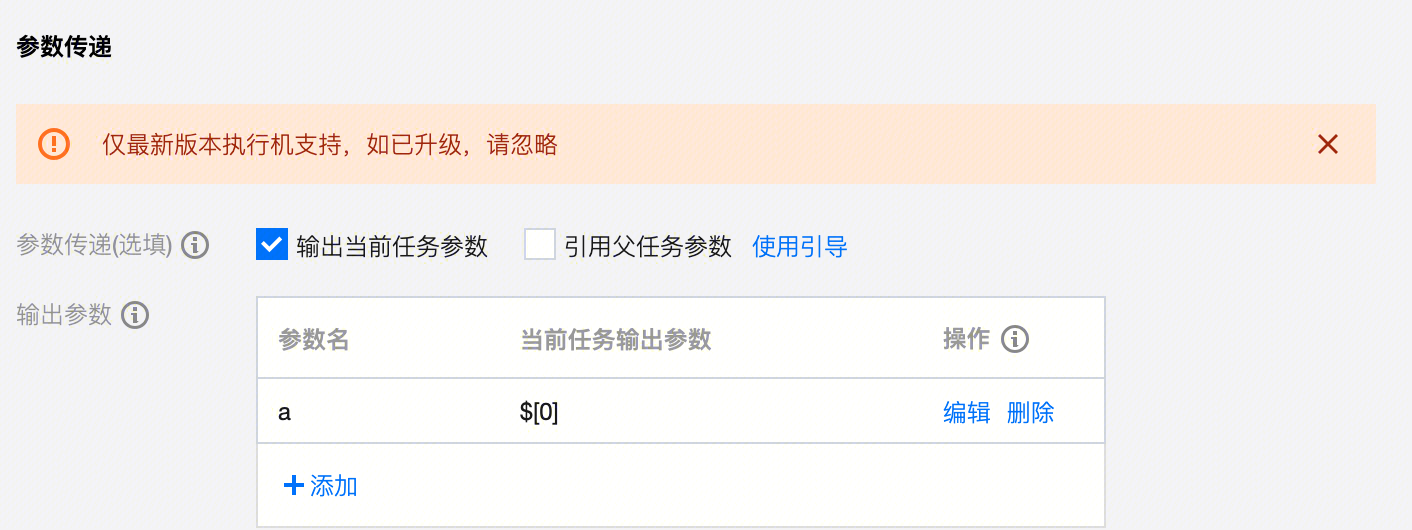 | print("This is the value of the parameter") | 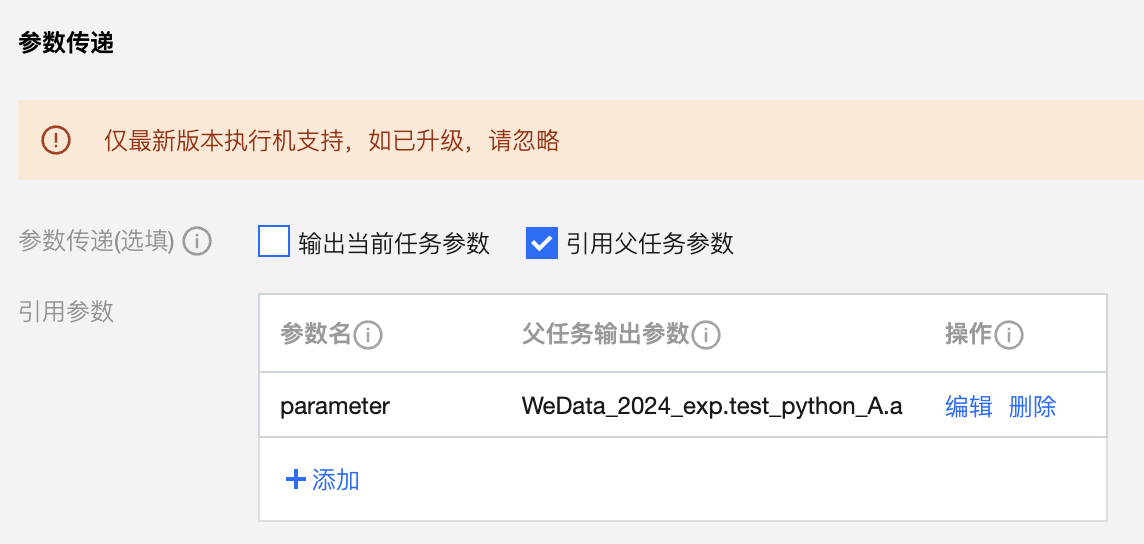 | print('${parameter}') | |



