TCHouse-C 基于开源 ClickHouse 构建,在保持与社区版架构一致的前提下,针对云端场景在易用性、安全性和稳定性方面进行了深度增强。
整体架构
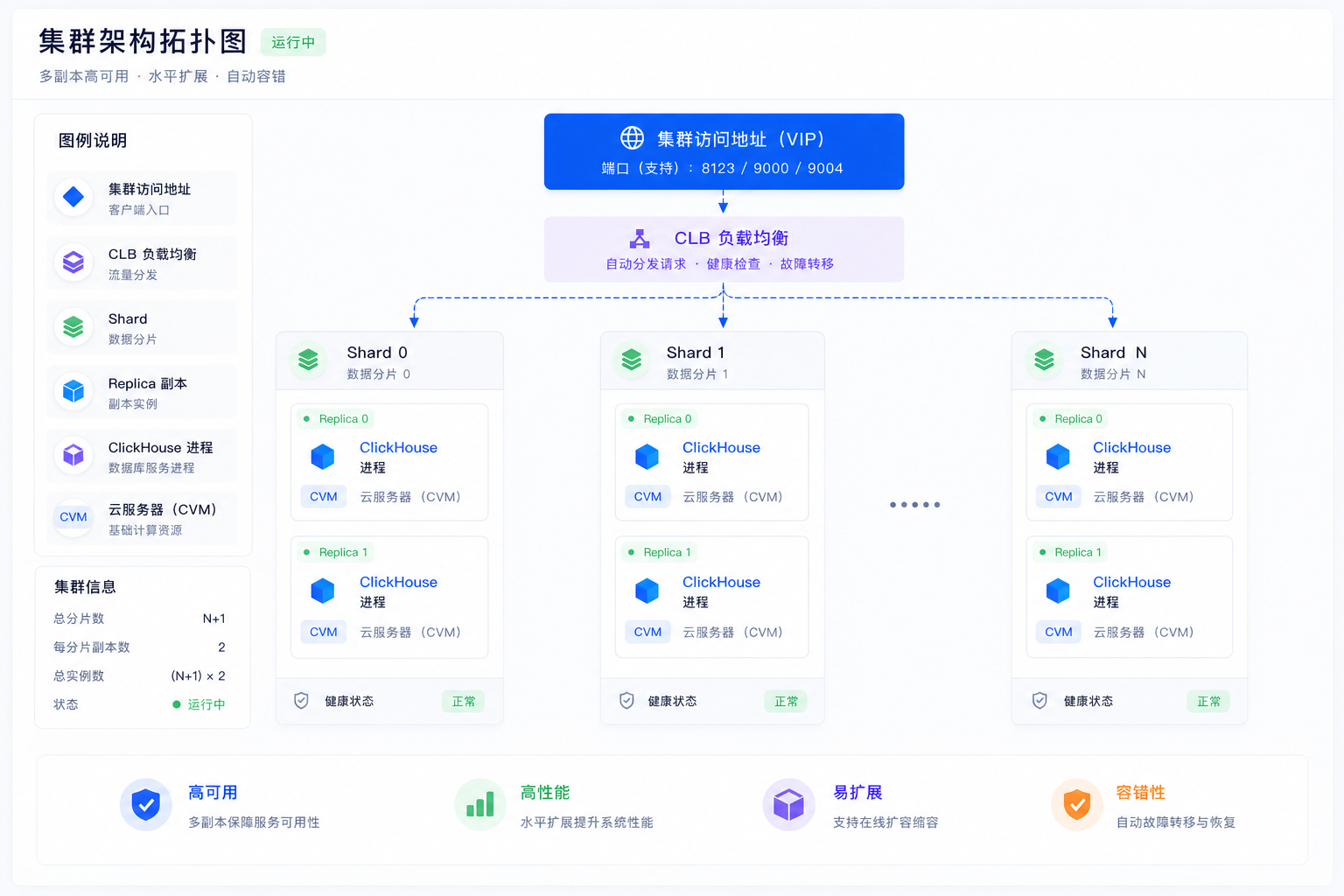
TCHouse-C 集群由三个核心层组成:
接入层
组件 | 职责 |
负载均衡(CLB) | 提供集群统一访问地址,自动将连接分发到可用的计算节点 |
TCP 端口(9000) | ClickHouse 原生协议,适用于 clickhouse-client 及各语言 SDK |
MySQL 端口(9004) | 使用标准的 MySQL 命令行工具或编程语言的 MySQL 驱动来查询 ClickHouse |
HTTP 端口(8123) | HTTP 端口,适用于 REST 调用、JDBC/ODBC 连接 |
计算层
计算层由多个分片(Shard)组成,每个分片包含 1~2 个副本(Replica)节点:
数据存储:每个副本节点上运行 ClickHouse Server 进程,管理本地表数据的写入、压缩、索引和查询。
并行计算:查询通过分布式表(Distributed Table)自动分发到所有分片并行执行,最终汇总结果返回。
弹性伸缩:支持在线增加分片数量以扩展计算和存储容量。
计算节点规格选型参考:
节点类型 | 节点存储 | 适用场景 |
标准型(推荐) | 支持挂载增强型 SSD 云硬盘和高性能云硬盘,支持独立扩容、最大单节点支持 320TB,支持透明数据加密(部分地域),写入云硬盘的数据自动加密。 | 大多数分析场景 |
高性能型 | 搭载 NVMe SSD 本地盘,提供更高 I/O 性能,节点磁盘空间固定、不支持独立扩容磁盘。 | 对 I/O 延迟极敏感的高频查询 |
大存储型 | 搭载大容量 HDD 本地盘,节点磁盘空间固定、不支持独立扩容磁盘。 | 海量冷数据存储、日志归档 |
协调层(ZooKeeper 或 ClickHouse Keeper)
TCHouse-C 使用 3 节点 ZooKeeper 或 ClickHouse Keeper 集群负责分布式协调:
副本同步:协调 ReplicatedMergeTree 引擎的跨副本数据同步。
DDL 管理:确保分布式 DDL 操作(如建表、改表)在所有节点上一致执行。
Leader 选举:管理合并(Merge)任务的 Leader 选举。
说明:
ZooKeeper 或 ClickHouse Keeper 节点由 TCHouse-C 全托管,用户无需关心其部署和运维。
高可用 vs 非高可用架构对比
维度 | 高可用模式 | 非高可用模式 |
副本数 | 每分片 2 副本 | 每分片 1 副本 |
表引擎 | ReplicatedMergeTree | MergeTree |
故障切换 | 自动:节点故障时查询自动路由到副本 | 不支持:节点故障则分片不可用 |
数据安全 | 双副本冗余,单节点损坏不丢数据 | 依赖云硬盘三副本保障(非本地盘) |
成本 | 约为非高可用模式的 2 倍 | 更低 |
推荐场景 | 生产环境 | 开发测试、非关键业务 |
云端增强能力(相比自建 ClickHouse)
TCHouse-C 并非简单的 ClickHouse「搬上云」,而是在以下方面做了深度增强:
能力维度 | TCHouse-C | 自建 ClickHouse |
部署交付 | 控制台一键创建,分钟级就绪 | 需手动部署配置,通常耗时数小时 |
集群管理 | 控制台可视化管理,内置监控告警 | 需自行编写运维脚本和监控 |
版本升级 | 支持滚动升级,降低业务影响 | 需停机手动升级,风险较高 |
弹性扩容 | 控制台一键操作 | 扩容需手动添加节点、迁移数据 |
高可用 | 内置 ZK 全托管,高可用一键开启 | 需自行搭建 ZooKeeper、配置副本 |
安全合规 | VPC 隔离 + 云硬盘加密,开箱即用 | 需自行配置网络隔离和加密 |



