操作场景
支持配置统计条件或编写查询语句,生成多类型的统计图表;并且支持分组展示图表,构建个性化的数据仪表盘。同时,借助腾讯混元大模型的 AI 能力,用户只需简单描述统计分析需求,即可快速准确地生成图表。该工具致力于让您的业务分析和商业决策更加简单和高效。
注意:
数据仪表盘能力目前仅开放给部分用户进行体验,且仅支持在微信开发者工具 > 云开发控制台中使用,如您无法使用该能力,敬请等待该能力的全量上线。
功能特性
数据看板:提供统计报表展示看板,聚合展示柱状图、折线图、饼图等各类图表,支持添加自定义看板分组。
可视化图表配置:在界面中单击配置数据统计的各项设置,灵活生成各类型统计图表。
编写查询语句:开发人员可手动编写查询语句,或修改 AI 生成的查询语句,进行数据的统计分析。
会话式 AI:描述数据分析需求,AI 自助生成查询语句,并渲染生成图表,实现数据可视化。
打通云数据库:支持快捷添加云开发环境的数据库集合,无需额外的数据库配置。
多平台支持:支持 PC、H5 端访问使用,外出办公依然从容实现数据分析。
操作步骤
安装模板
1. 访问云开发控制台 > 云模板 > 模板中心,安装数据仪表盘。
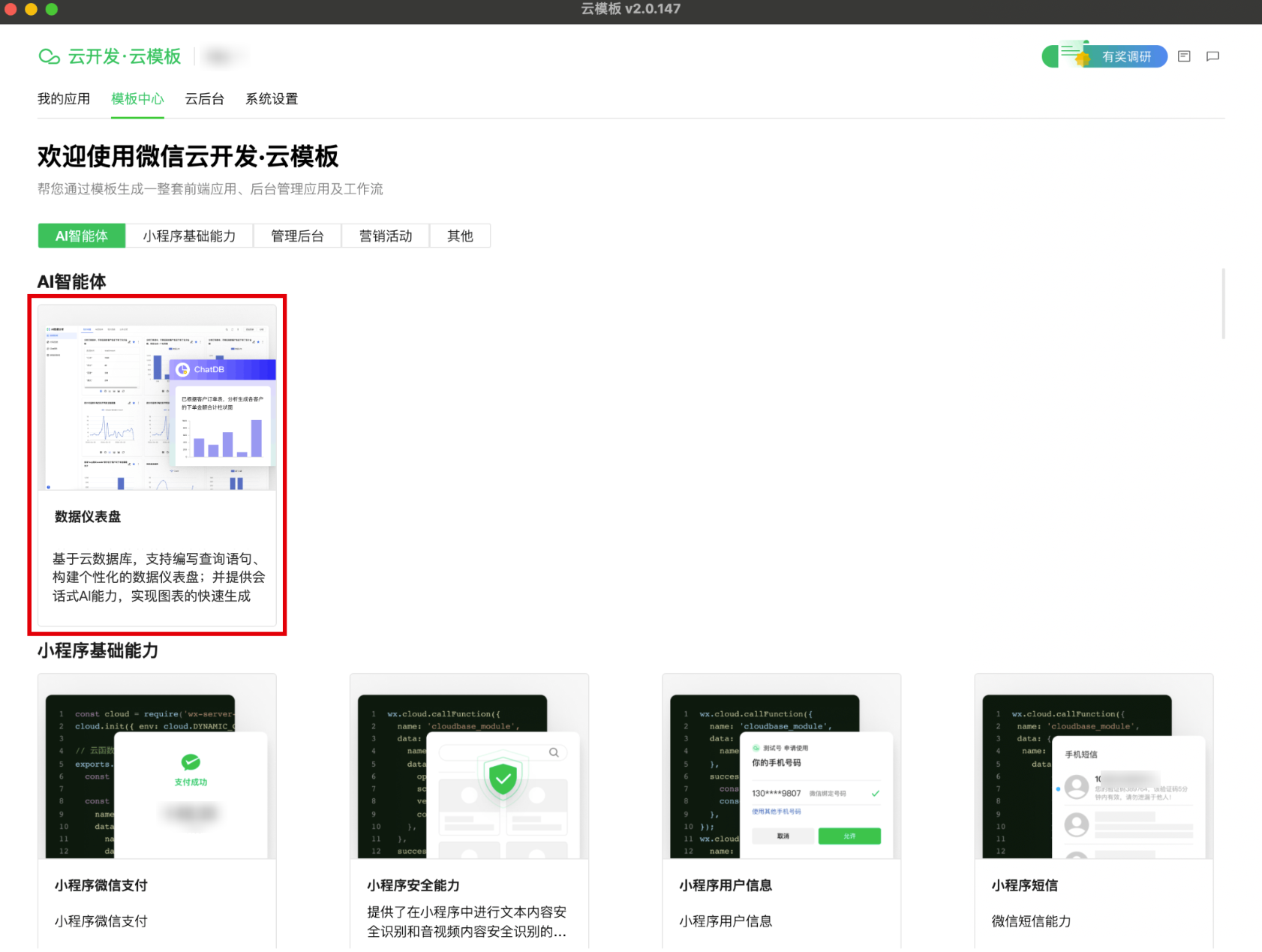
2. 等待安装完成后,单击应用右上角的打开管理端,进入数据仪表盘应用,即可开始使用。
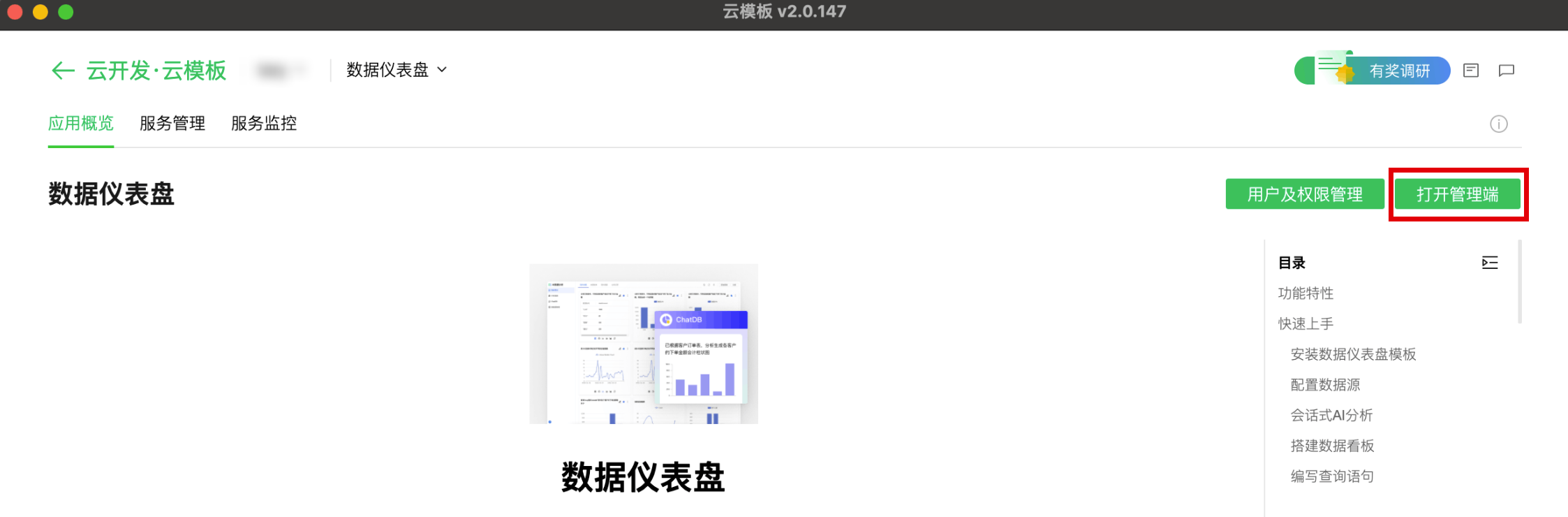
添加图表
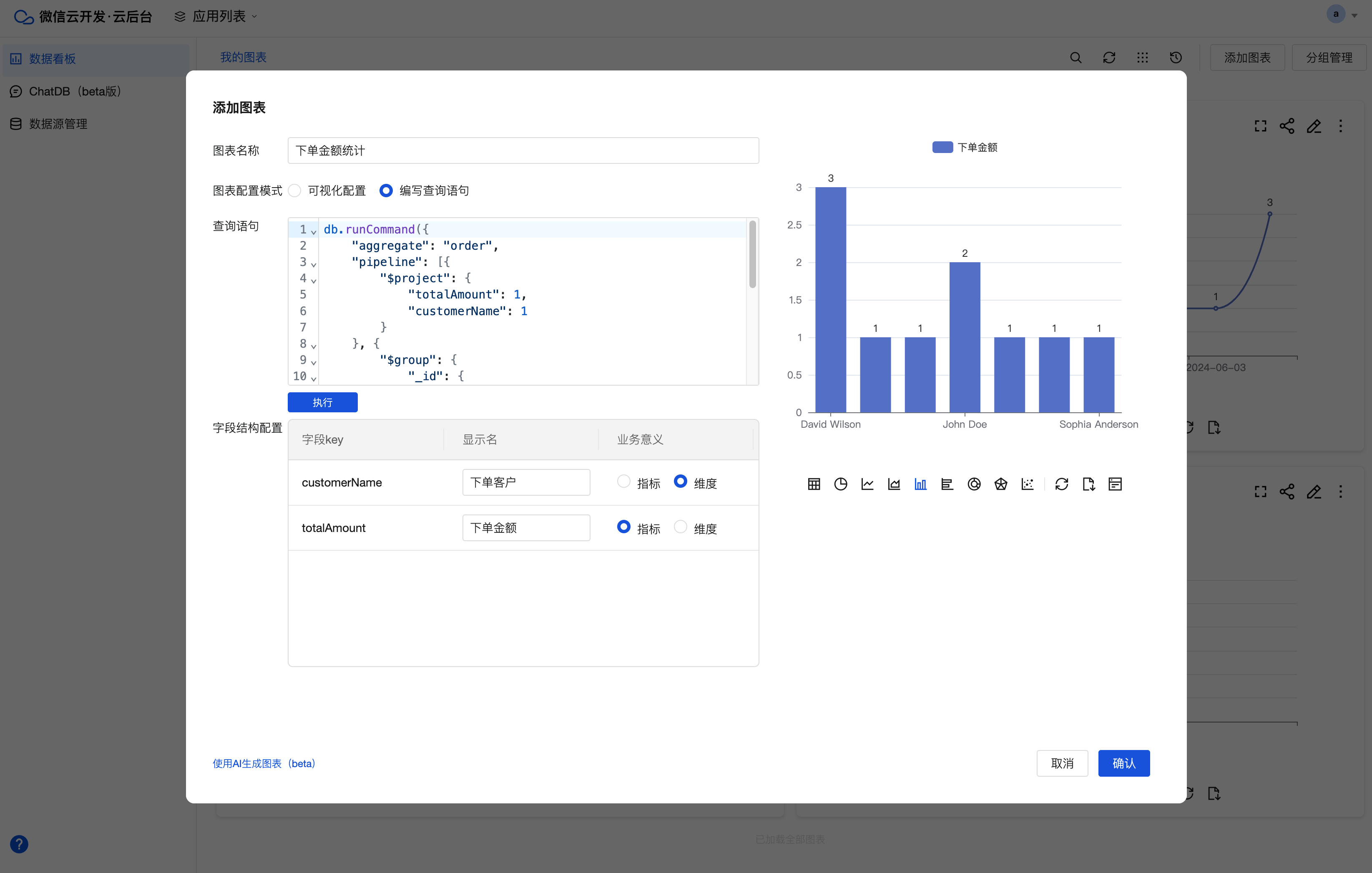
1. 单击数据看板页面右上角的添加图表,即可打开添加图表弹窗。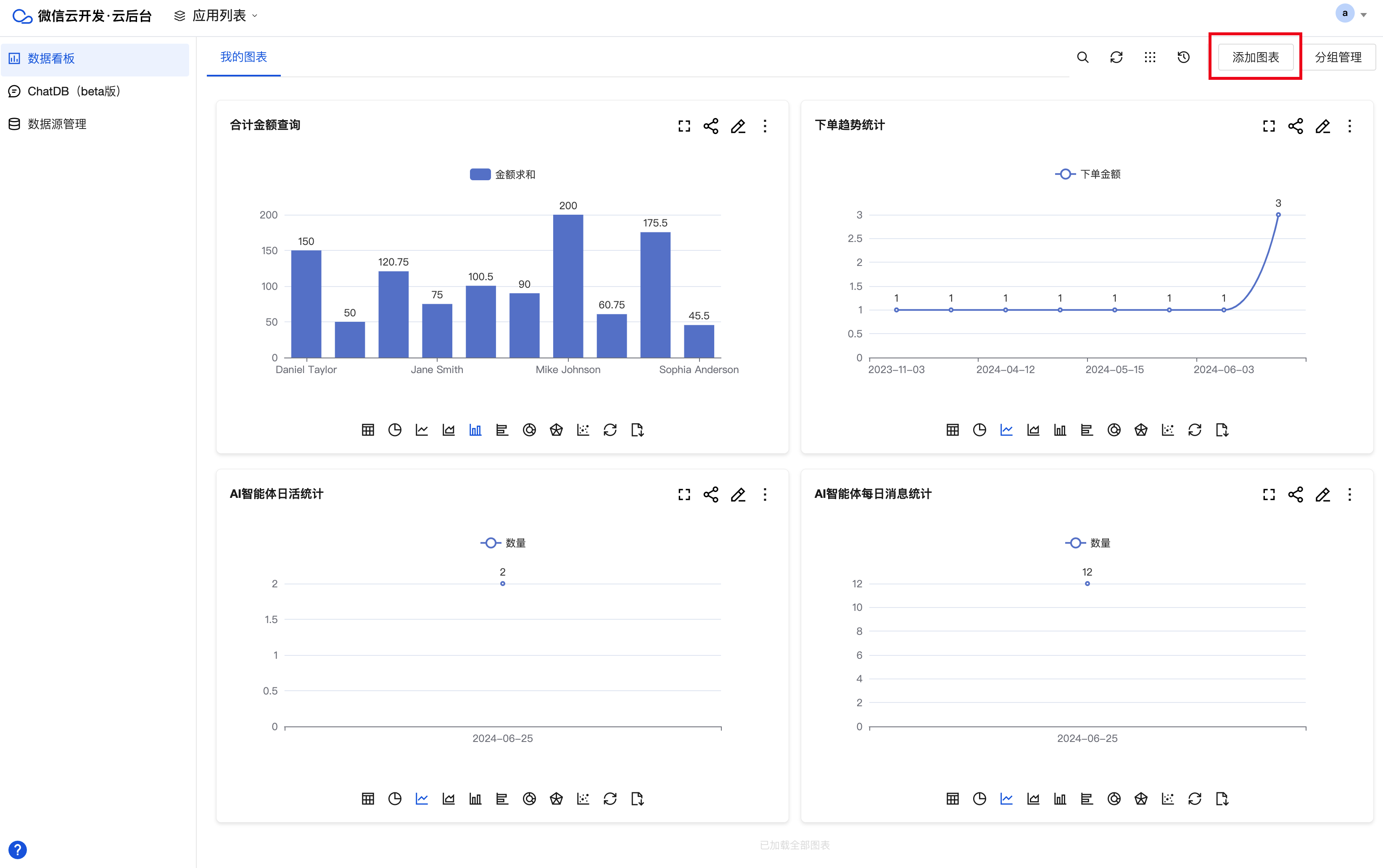
2. 在添加图表弹窗中,可切换图表配置模式:
可视化配置:提供数据源、统计维度、统计指标等配置项,完成快捷配置,单击执行,弹窗右侧即可以表格形式回显统计结果。在表格下方可切换展示为不同的图表类型。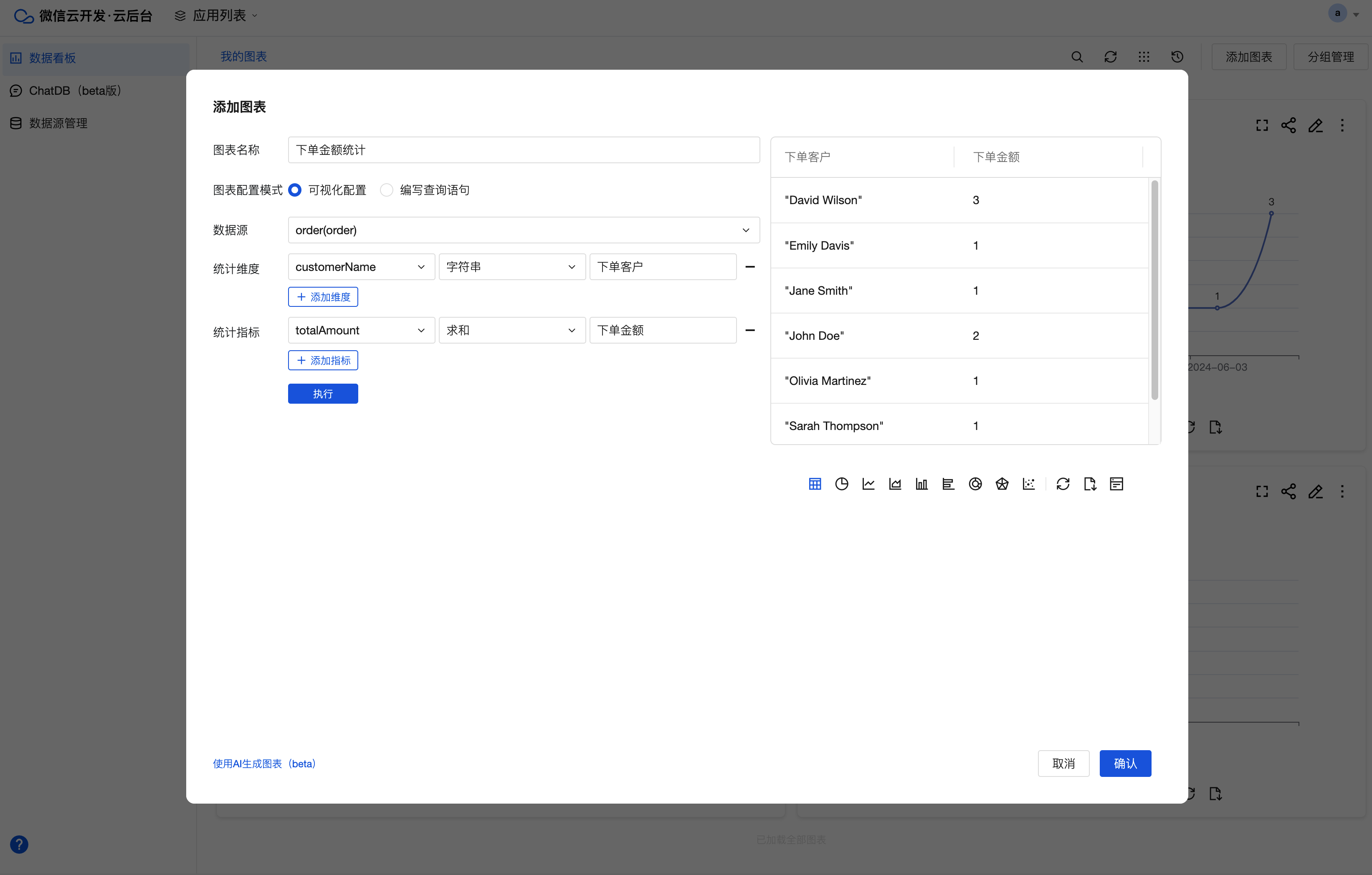
编写查询语句:该模式下,用户可编写查询语句(该文档最下方可查阅查询语句语法说明),实现数据的聚合计算,然后单击执行,等待系统识别执行结果中的字段后,再配置字段的统计或维度即可。
会话式 AI 分析(beta)
1. 单击 ChatDB 菜单,或在添加图表弹窗的单击使用 AI 生成图表链接,可通过对话,告知 AI 数据的统计分析需求,由 AI 进行统计计算和图表生成。
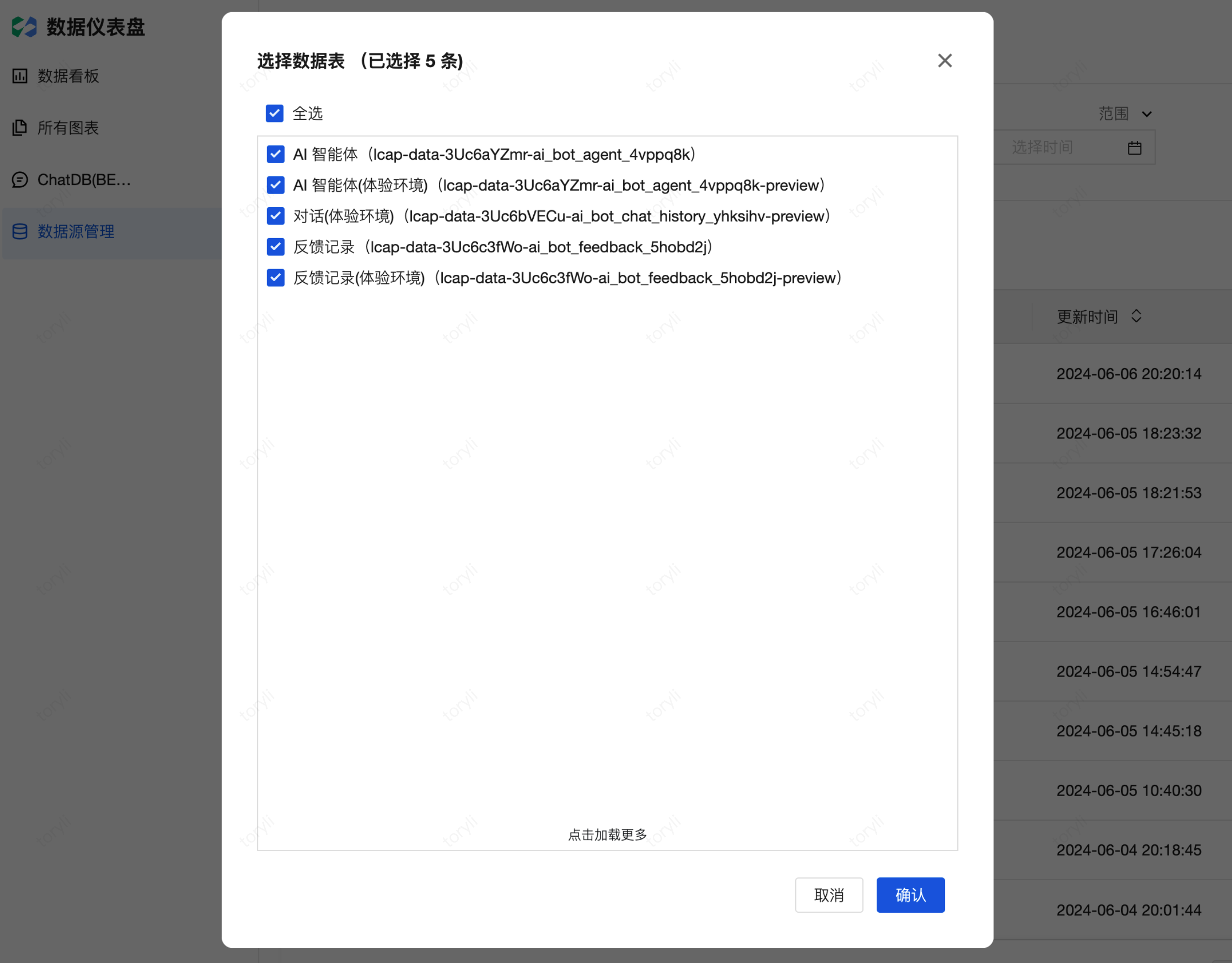
2. 首次使用 AI 时,需要配置用于 AI 分析的云数据库集合。进入数据源管理模块,单击一键自动同步,全选当前云开发环境中的所有集合,单击确认,将集合导入到该应用中。
注意:
安装该模板时,会自动将云数据库中的集合添加到 AI 数据源中,如安装完模板后未添加新的集合,则可略过此步骤。
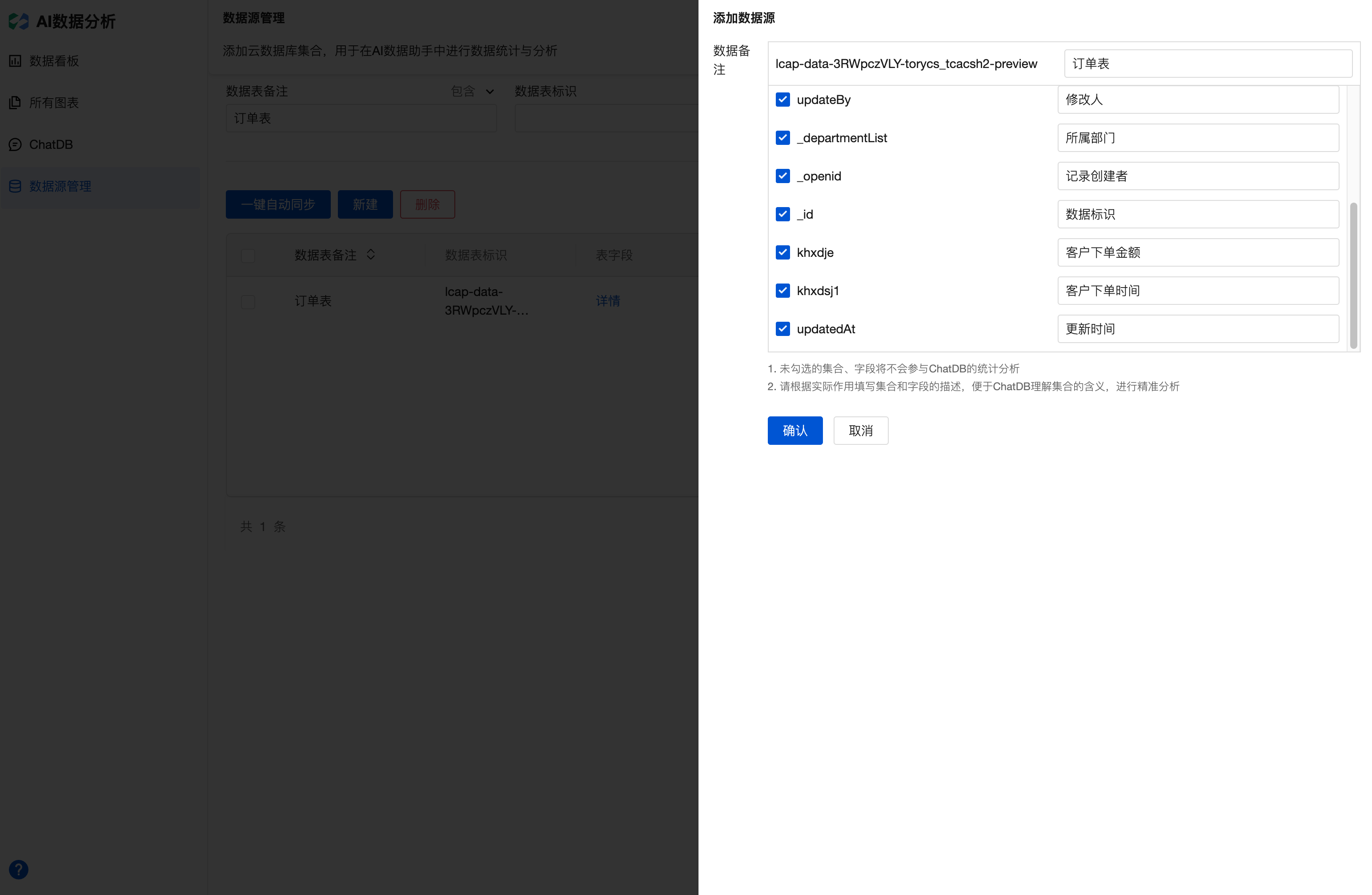
3. 数据仪表盘应用会读取集合中的第1条数据,分析数据结构和字段标识,用于后续的会话式 AI 分析。为了使输入的 prompt 能够更简单,AI 能够更准确的理解数据结构,需要对集合和其中的字段进行备注的补充。在数据源管理列表中,找到需要备注的集合,单击编辑,即可打开备注编辑界面。如下图所示,补充了订单集合和其中各个字段的备注,然后单击确认进行保存即可。
4. 接下来,回到 ChatDB 菜单,输入想要统计的数据需求,AI 仅可分析生成查询语句,对数据进行汇总计算,生成表格。建议您采用以下提示词格式进行提问:
序号 | 建议问法 | 示例 |
1 | 统计“[集合标识]”中的数据,统计维度为“[字段A标识]”,统计指标为“[字段A标识]”的合计值/计数值/最大值 | 统计“order”表中的数据,维度为“customerName”,指标为“totalAmount” 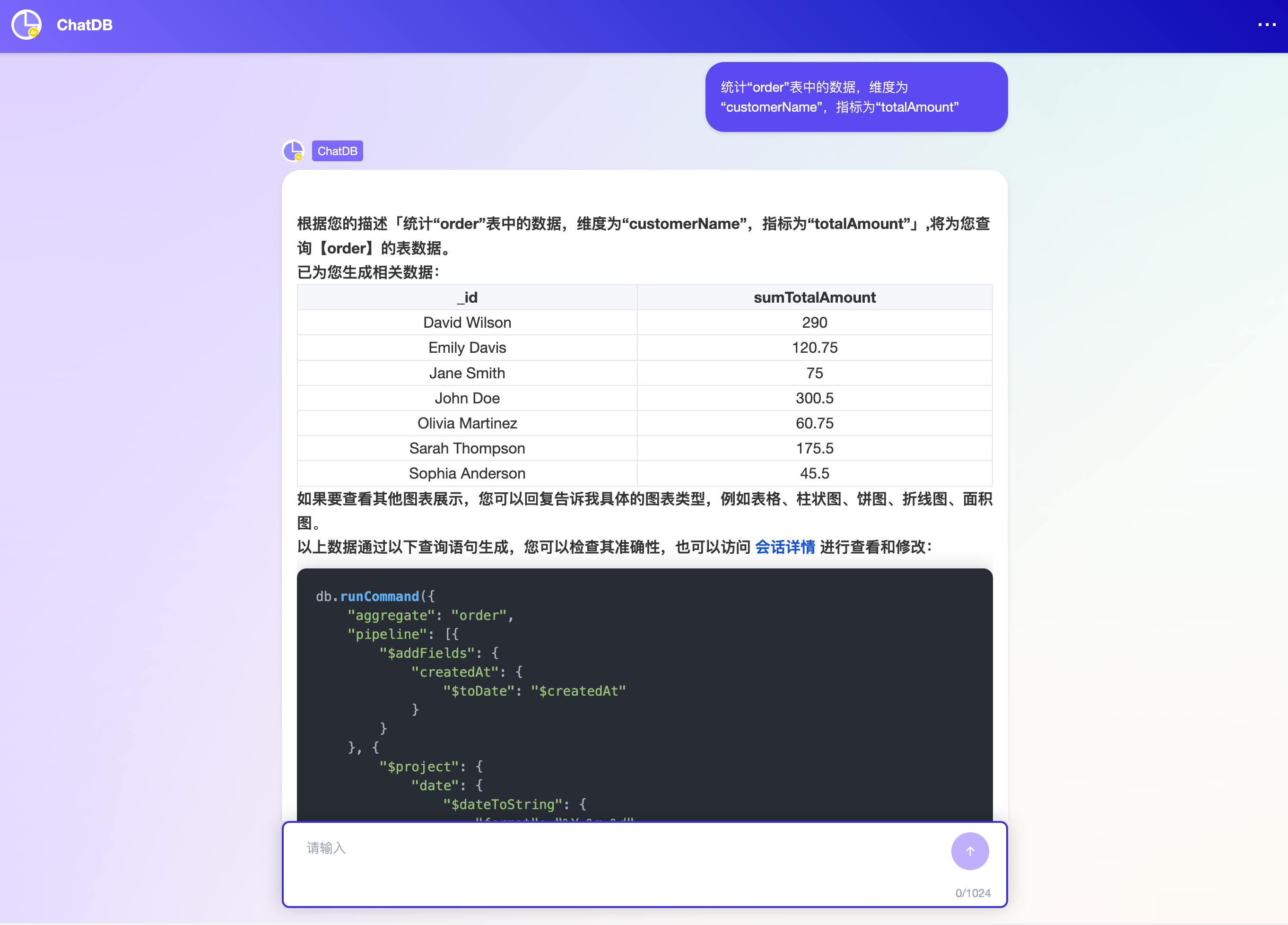 |
2 | 统计[集合备注]中的数据,统计维度为[字段A备注],统计指标为[字段A备注]的合计值/计数值/最大值 | 统计订单表中的数据,统计维度为客户名称,统计指标为下单金额的合计值 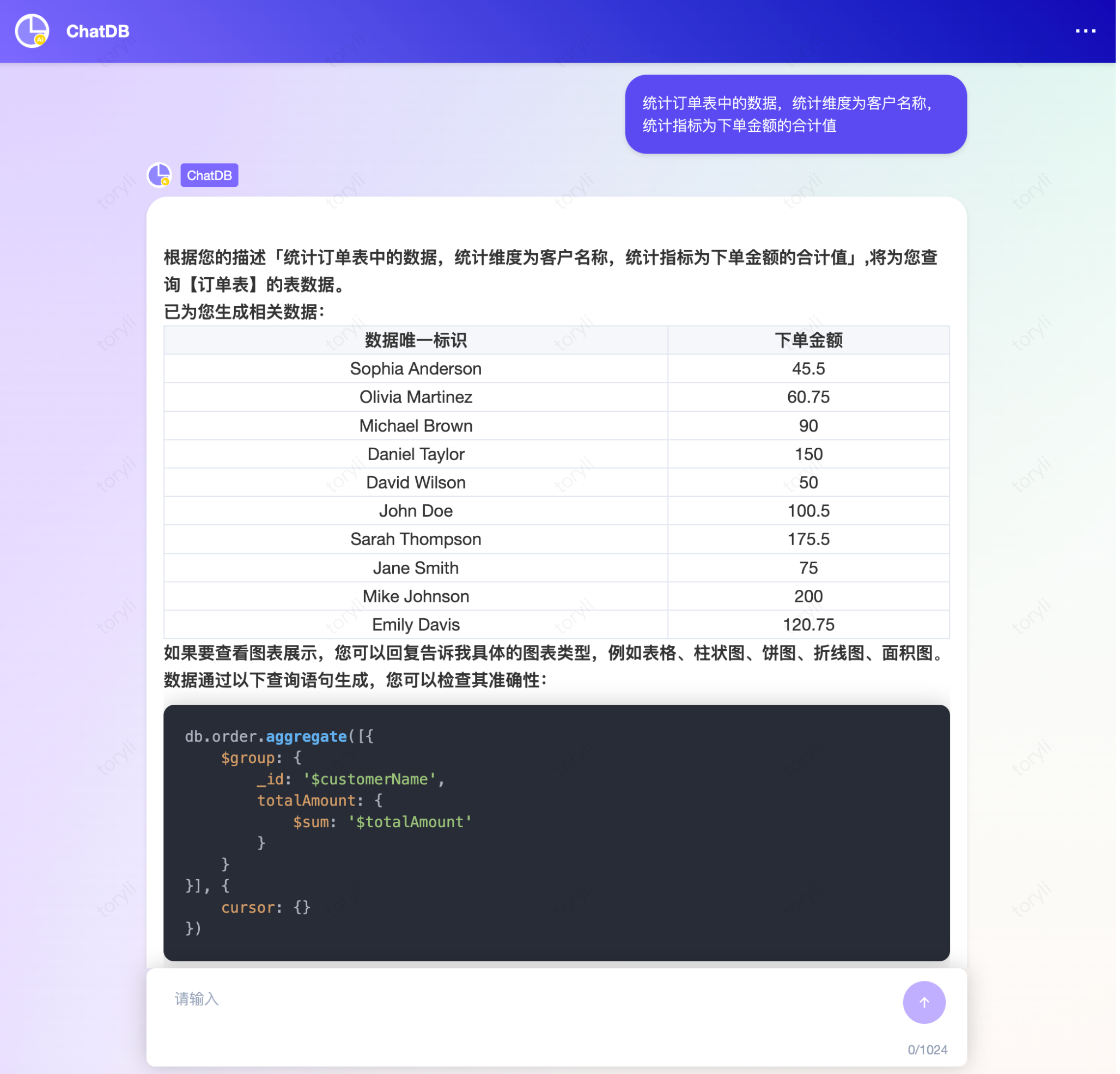 |
3 | 分析[集合备注]中,不同[字段A备注]的数据,分别下单/购买/使用了多少[字段B备注]。 | 统计订单表中的数据,统计维度为客户名称,统计指标为下单金额的合计值 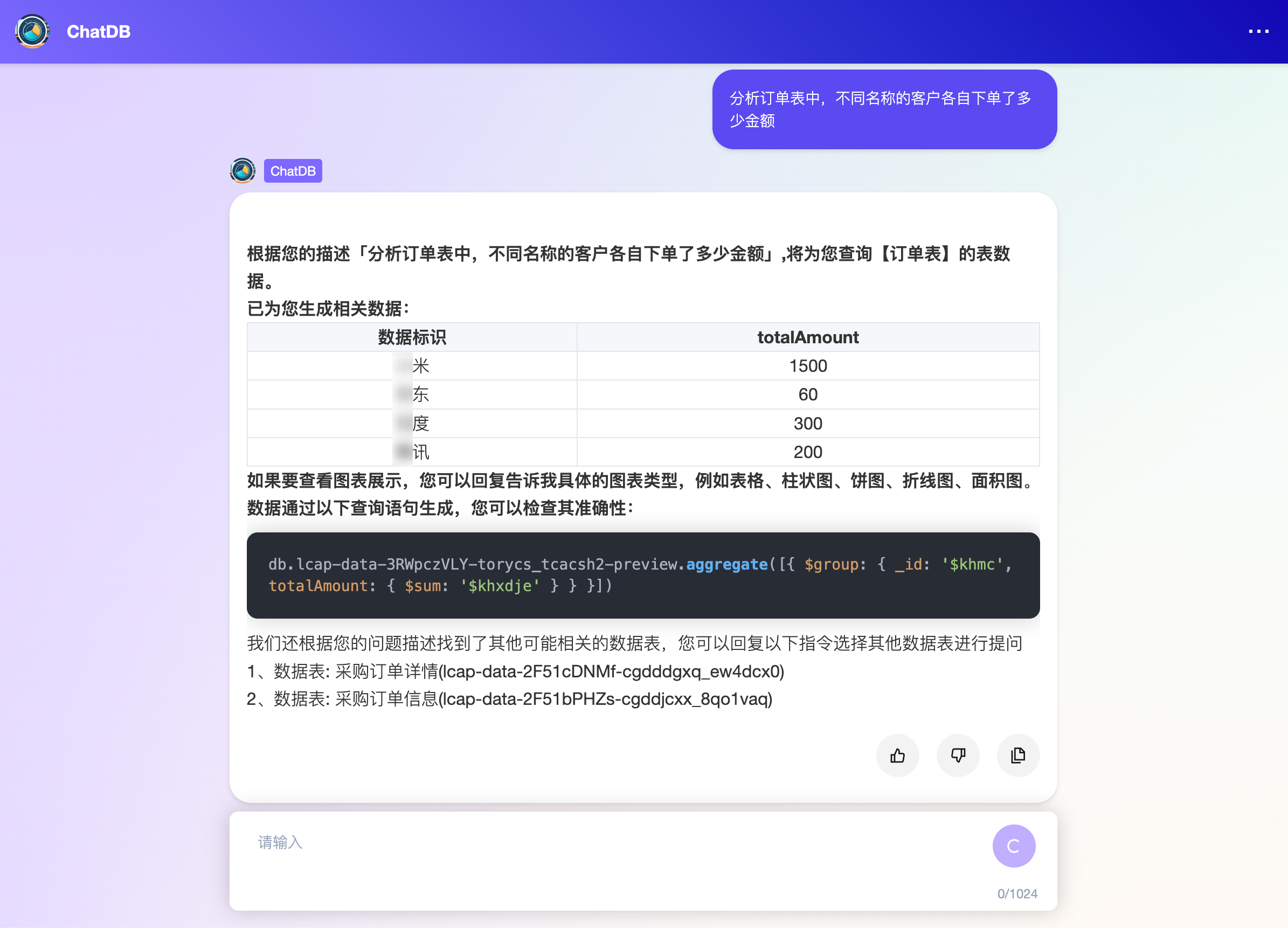 |
4 | [集合备注]表,按[日期类型的字段A备注]分析,每天每月分别下单/购买/使用了多少[字段B备注]。 | 订单表,按下单时间分析,每天分别下单的多少金额。  |
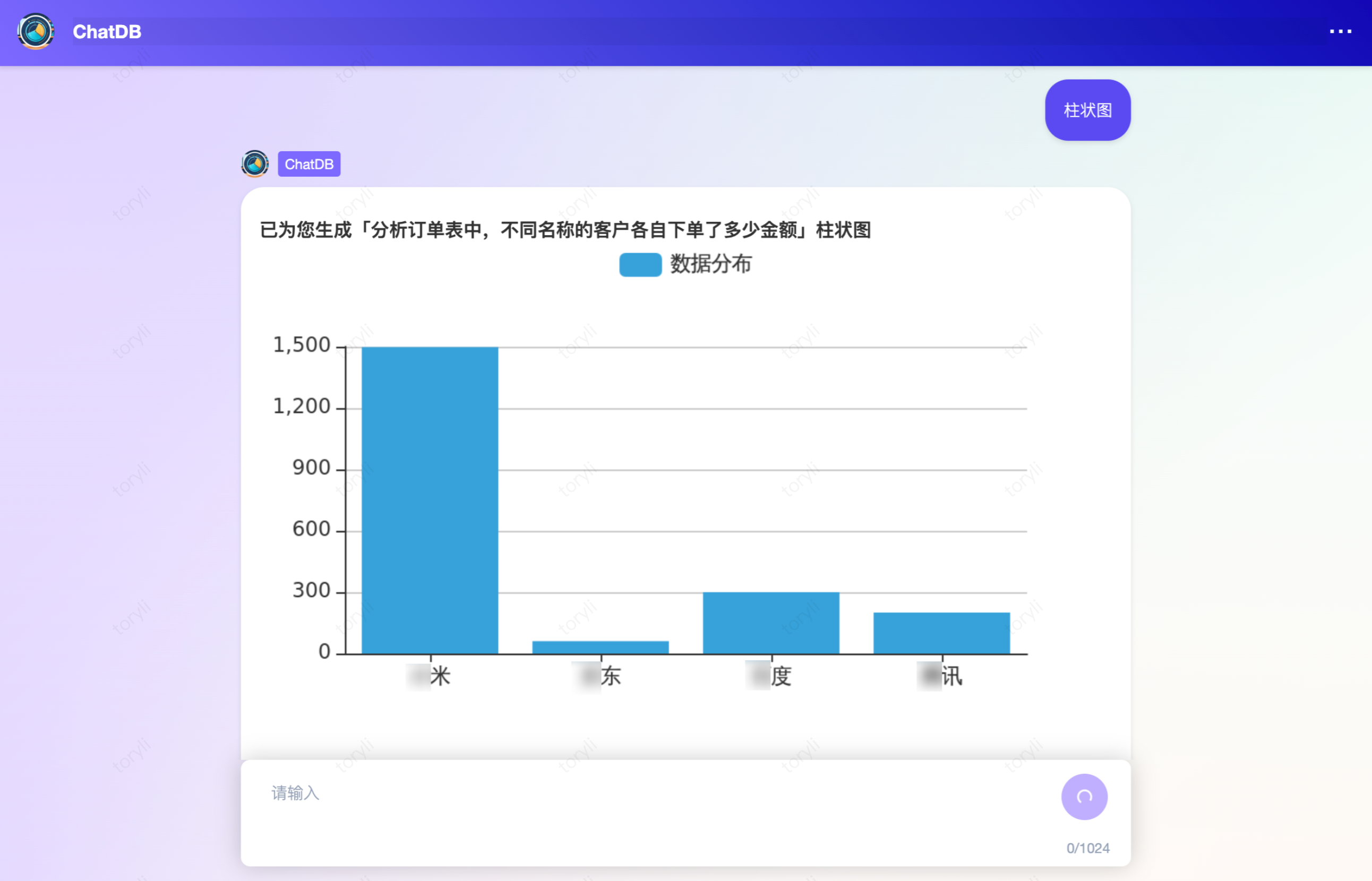
5. 生成数据表格后,回复所需的图表类型,可直接进行图表切换,目前支持:饼图、折线图、面积图、柱状图、水平柱状图、圆环图、雷达图、散点图。
附:查询语句语法说明
1. 查询语句支持 MongoDB 标准的
db.runCommand() 方法来执行 aggregate 操作,实现复杂的数据处理和分析操作。该方法中使用一个管道(pipeline)来处理数据,每个阶段(stage)在管道中执行特定的操作。2. 一个标准的查询语句格式如下:
db.runCommand({aggregate: "<collectionName>",pipeline: [ <aggregationStages> ],<optionalParameters>})
<collectionName>:要执行聚合操作的集合名称,作为字符串传递给 aggregate 字段。<aggregationStages>:一个数组,包含聚合操作的各个阶段。每个阶段都是一个文档,描述了要在聚合过程中执行的操作。您可以按照需要添加多个阶段,每个阶段的顺序将按照数组中的顺序执行。<optionalParameters>:可选的参数,以键值对的形式传递给 db.runCommand() 方法。这些参数可以用于控制聚合操作的行为和结果。3. 查询语句完整语法说明请参见 db.runCommand() 和 db.collection.aggregate() ,以下提供基础说明和常用示例。
4. 常见的 stage 及其用途:
$match:用于筛选满足指定条件的文档,类似于 SQL 中的 WHERE 子句。$group:用于按照指定字段对文档进行分组,类似于 SQL 中的 GROUP BY 子句。$project:用于选择要返回的字段,并可以进行计算、重命名等操作。$sort:用于对文档进行排序,类似于 SQL 中的 ORDER BY 子句。$limit:用于限制返回的文档数量,类似于 SQL 中的 LIMIT 子句。$skip:用于跳过指定数量的文档,类似于 SQL 中的 OFFSET 子句。$unwind:用于将数组字段拆分为多条文档。$lookup:用于在不同集合之间进行关联查询,类似于 SQL 中的 JOIN。5. 以下示例,展示了如何使用 aggregate 方法来执行不同的操作。
5.1 假设我们有一个 sales 集合,包含以下文档:
[{_id: 1,customer: "Customer A",status: "completed",amount: 100},{_id: 2,customer: "Customer B",status: "completed",amount: 200},{_id: 3,customer: "Customer A",status: "completed",amount: 150},{_id: 4,customer: "Customer C",status: "completed",amount: 300},{_id: 5,customer: "Customer B",status: "completed",amount: 250},{_id: 6,customer: "Customer A",status: "completed",amount: 200},{_id: 7,customer: "Customer C",status: "completed",amount: 350}]
5.2 我们想要查询出已完成订单金额最高的前3个客户,按照总金额降序排列,则语句写法为:
db.runCommand({aggregate: "orders",pipeline: [{ $match: { status: "completed" } },{ $group: { _id: "$customer", totalAmount: { $sum: "$amount" } } },{ $sort: { totalAmount: -1 } },{ $limit: 3 }]})
5.3 输出:
{ "_id": "apple", "totalQuantity": 20 }{ "_id": "banana", "totalQuantity": 30 }



