本文介绍 DLC 对 Apache DolphinScheduler 调度工具的支持,并提供示例来演示如何使用 Apache DolphinScheduler 运行 DLC 引擎提交任务。
背景信息
Apache DolphinScheduler 是一个开源的分布式工作流调度系统,旨在为大数据场景提供高效的任务调度和管理。它支持可视化工作流设计、任务依赖管理、定时调度等功能,适用于数据处理、ETL 和机器学习等多种应用场景。如需更多信息,请参见 Apache DolphinScheduler 官方网站。
前提条件
1. Apache DolphinScheduler 环境准备。
1.1 已安装并启动 Apache DolphinScheduler,更多安装及启动 Apache DolphinScheduler 操作,请参见 Apache DolphinScheduler 快速上手。
2. 数据湖计算 DLC 环境准备。
2.1 已开通数据湖计算 DLC 引擎服务。
2.2 如使用 SuperSQL 引擎,准备好 DLC JDBC 驱动,点击下载 JDBC 驱动。
标准 Spark 引擎对接 Apache DolphinScheduler 关键步骤
选择添加 Kyuubi 或 Spark 数据源
注意:
Apache DolphinScheduler 低于3.2.1版本未支持 kyuubi 数据源,只能选择 spark 数据源。
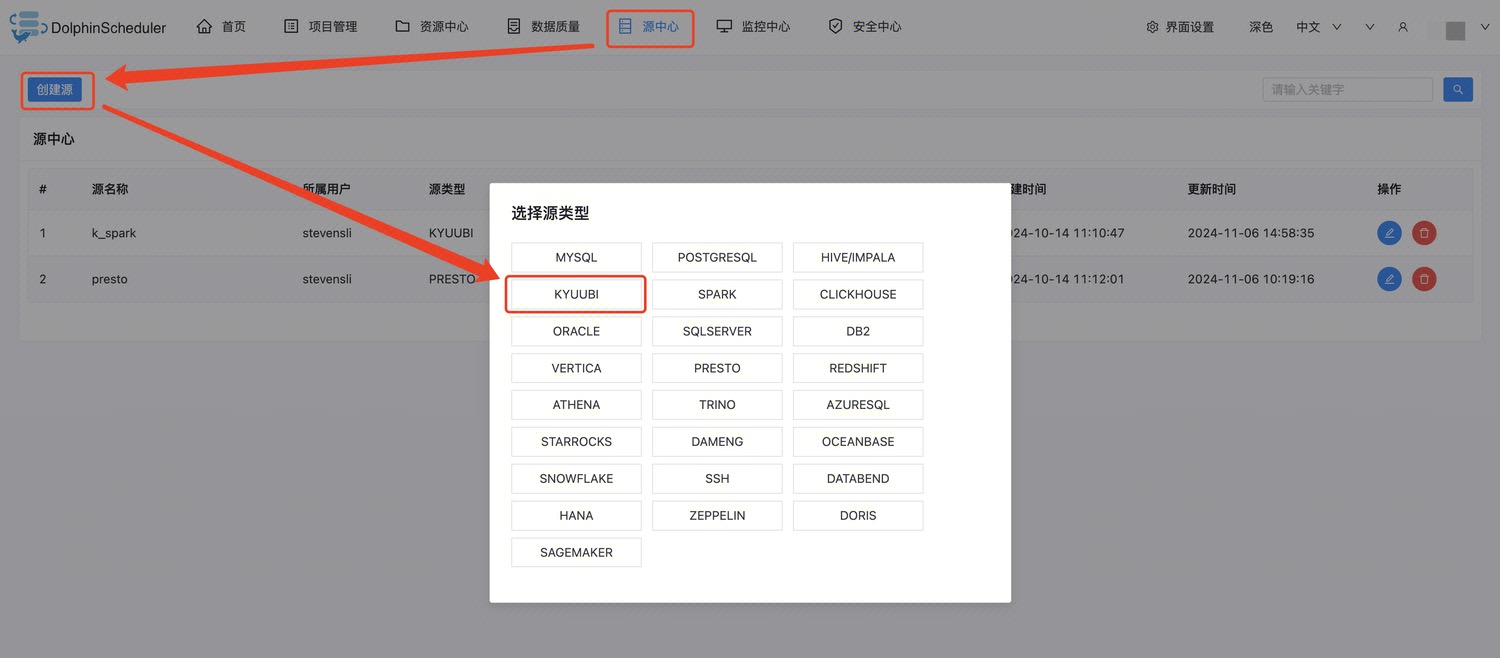
参数如图设置:
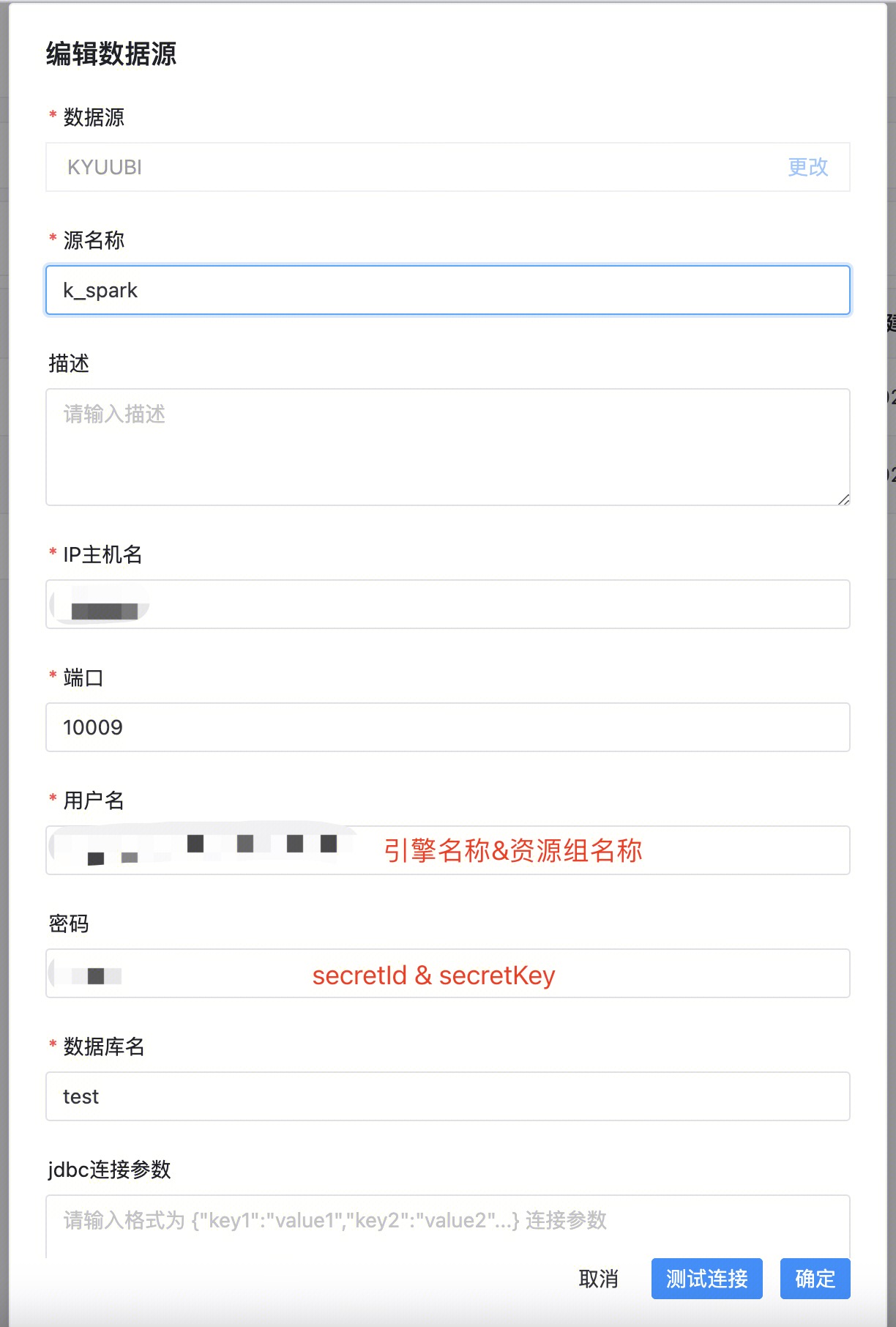
参数说明:
参数 | 必填 | 说明 |
源名称 | 是 | 自定义即可。 |
描述 | 否 | 自定义即可。 |
IP 主机名 | 是 | 填写能访问到引擎的 ip。 如果是内网访问,可以在 DLC 控制台查看,如下图所示:  |
端口 | 是 | 10009 |
用户名 | 是 | 填写引擎名称和资源组名称,两个名称之间用“&”符号连接。 |
密码 | 是 | 填写 SecretId 和 SecretKey,id 和 key 之间用“&”符号连接。 |
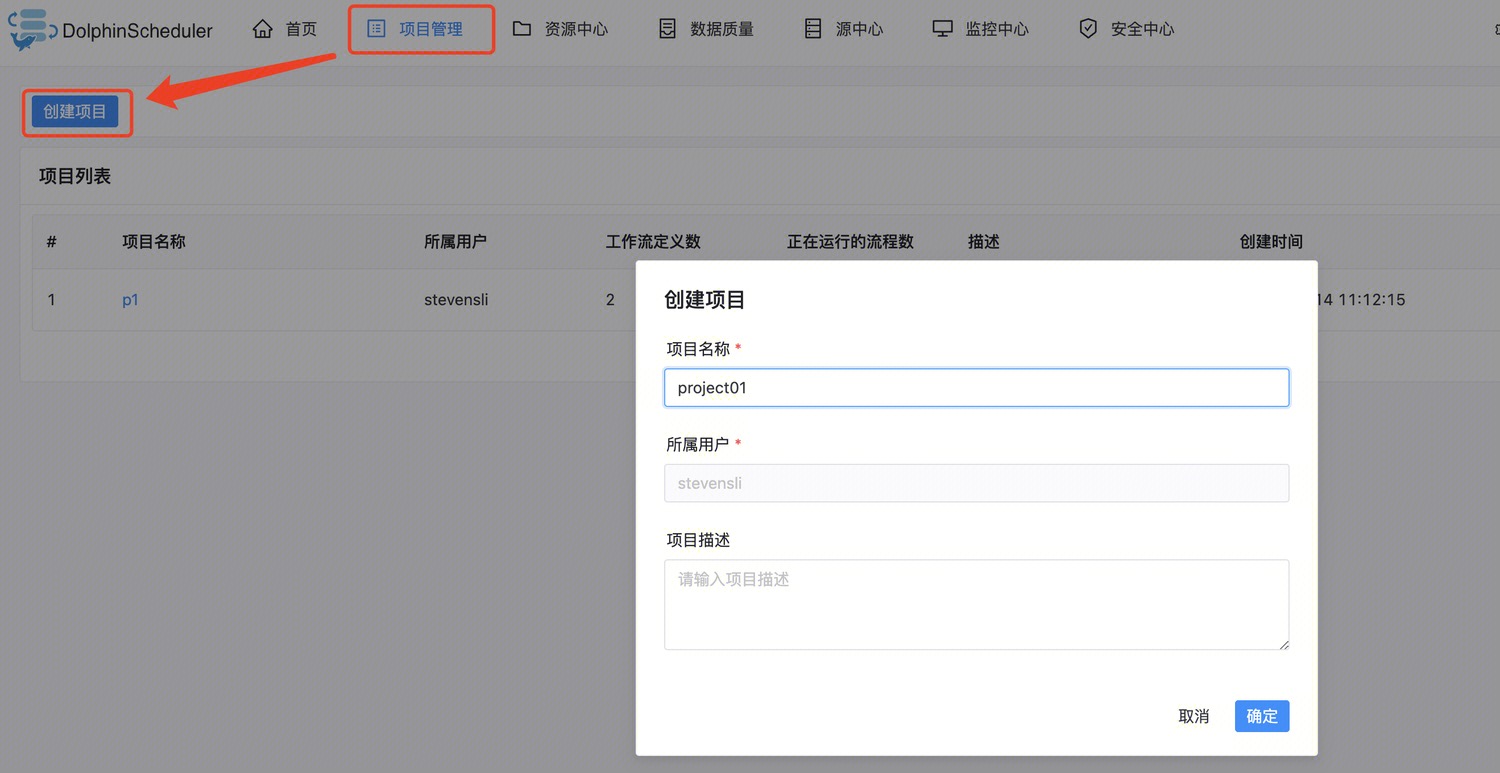
创建项目和工作流
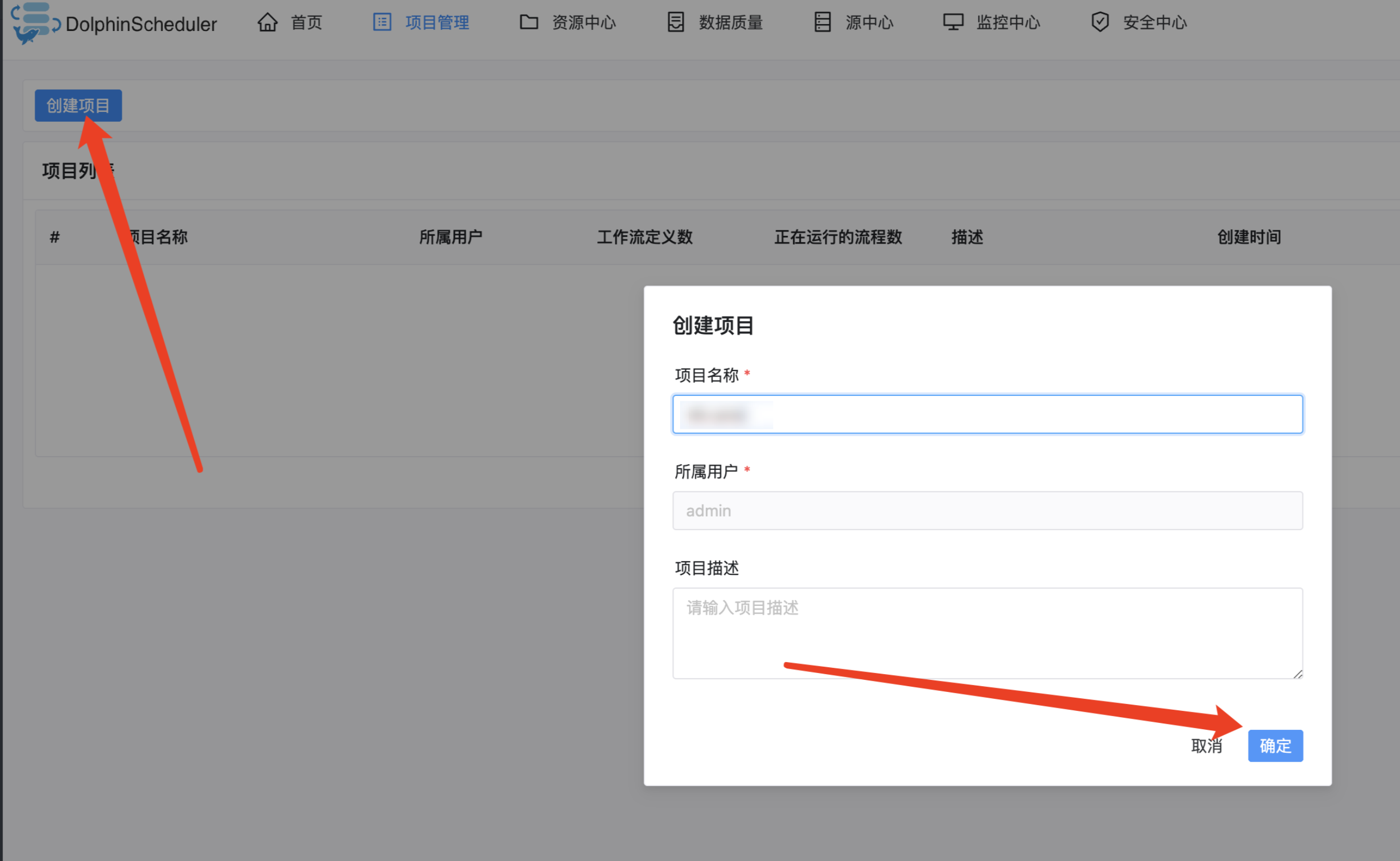
1. 如图在项目管理下创建一个项目:
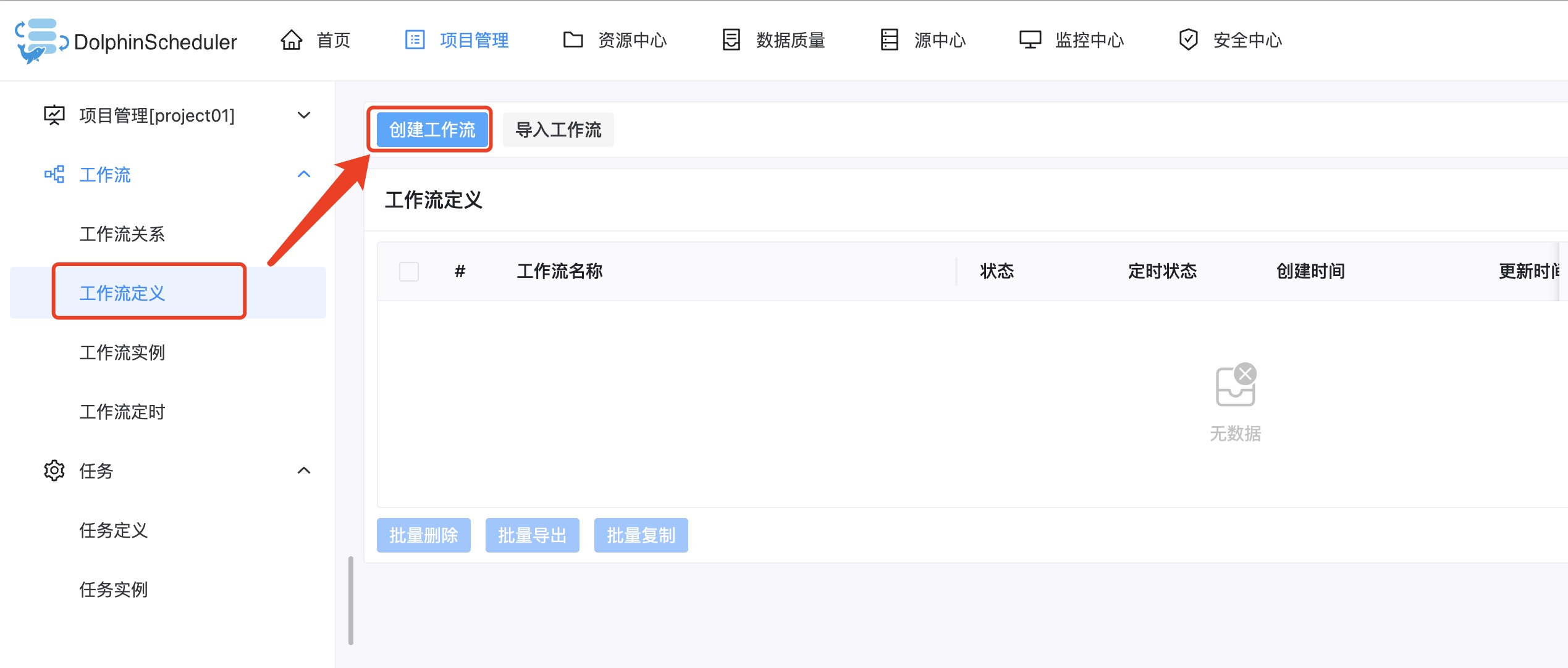
2. 进入项目创建一个工作流:
3. 在工作流中创建一个 SQL 节点,如图选择刚刚创建的数据源实例,并且输入 SQL。
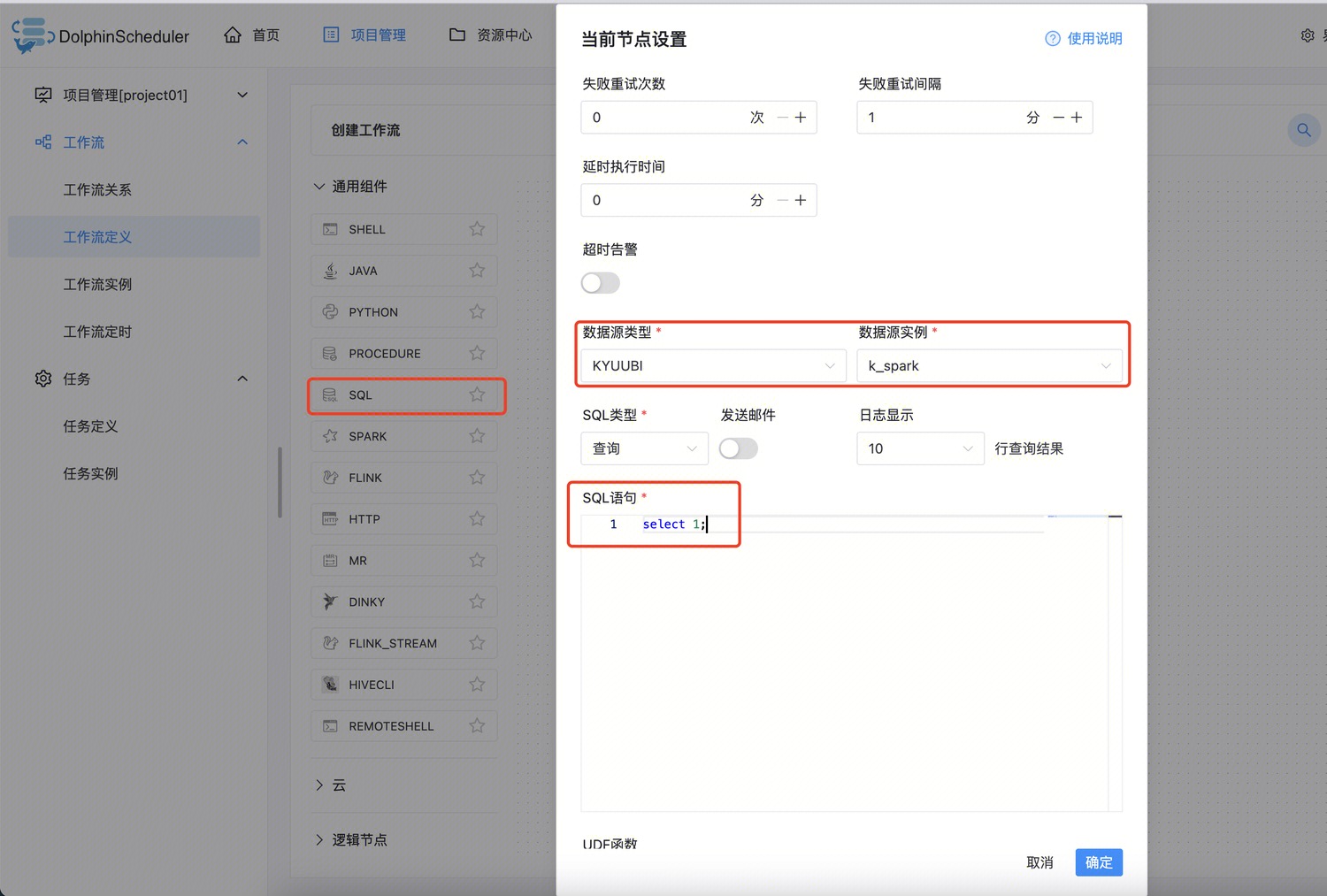
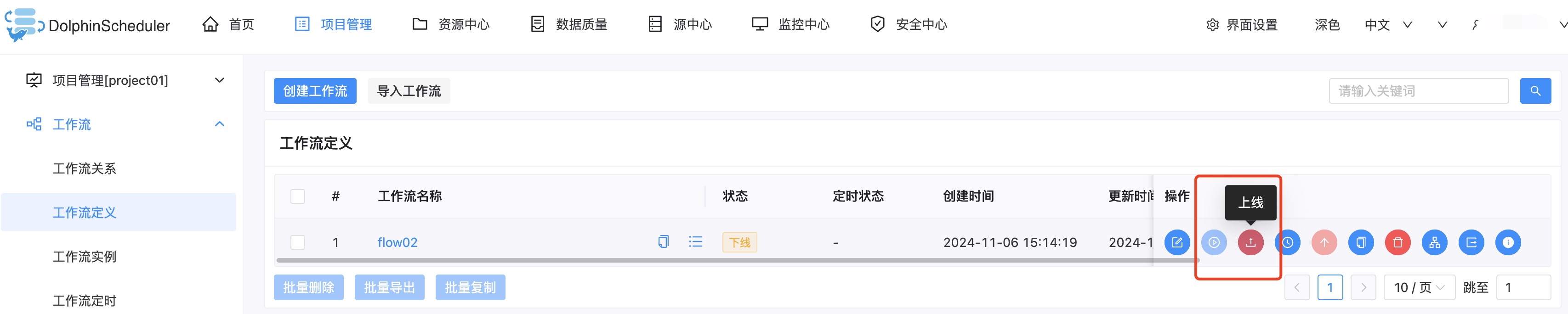
4. 保存该节点和工作流,先将工作流上线再运行:
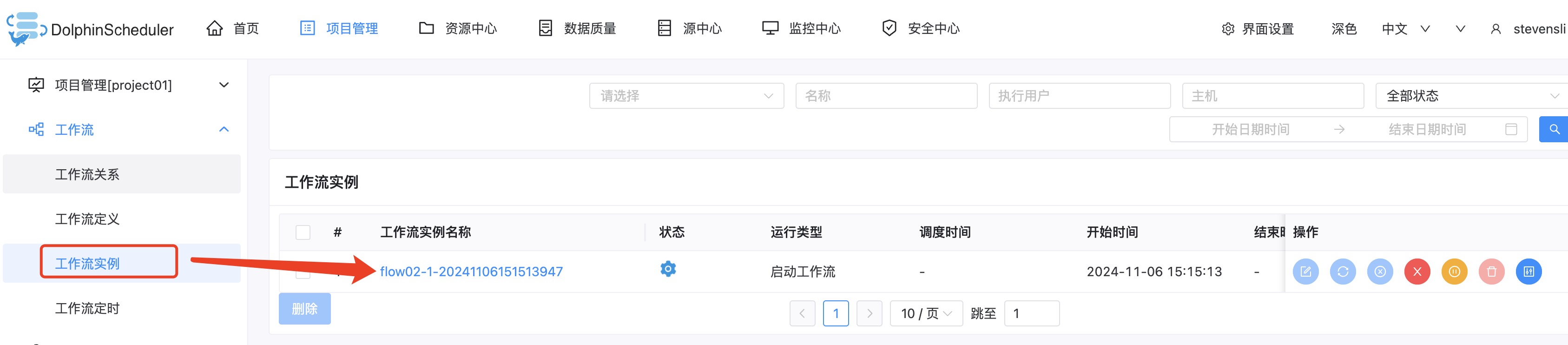
5. 在工作流实例中,能够看到历史运行任务列表,可以点击实例名,查看运行结果,日志等信息:
标准 Presto 引擎对接 Apache DolphinScheduler 关键步骤
当前不支持直接使用 kyuubi 或者 presto 数据源直接连接 presto 引擎,用户可以通过 kyuubi 的 Python 节点访问 DLC。
配置 PYTHON_HOME
找到 Apache DolphinScheduler 安装路径下的配置文件 dolphinscheduler_env.sh,修改其中的 PYTHON_HOME 参数,配置为当前 Python 的路径。或者链接 Python 到指定位置:
ln -s /usr/bin/python /opt/soft/python下载腾讯云 Python SDK
pip install --upgrade tencentcloud-sdk-python创建项目和工作流
1. 如图在项目管理下创建一个项目:
2. 配置节点:
示例代码:
说明:
该脚本会读取本地的 sql_file_path/dlc.sql 文件,将文件内的 sql 全部提交到指定的 DLC presto 引擎。
注意替换脚本中的 secretId、secretKey、region、engineName,文件路径等参数。
import jsonimport typesfrom tencentcloud.common import credentialfrom tencentcloud.common.profile.client_profile import ClientProfilefrom tencentcloud.common.profile.http_profile import HttpProfilefrom tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKExceptionfrom tencentcloud.dlc.v20210125 import dlc_client, modelsimport base64import timeimport sysdef create_task(sql):global errtry:# 实例化一个认证对象,入参需要传入腾讯云账户 SecretId 和 SecretKey,此处还需注意密钥对的保密# 代码泄露可能会导致 SecretId 和 SecretKey 泄露,并威胁账号下所有资源的安全性。以下代码示例仅供参考,建议采用更安全的方式来使用密钥,请参见:https://cloud.tencent.com/document/product/1278/85305# 密钥可前往官网控制台 https://console.cloud.tencent.com/cam/capi 进行获取cred = credential.Credential("secretId", "secretKey")# 实例化一个http选项,可选的,没有特殊需求可以跳过httpProfile = HttpProfile()httpProfile.endpoint = "dlc.tencentcloudapi.com"# 实例化一个client选项,可选的,没有特殊需求可以跳过clientProfile = ClientProfile()clientProfile.httpProfile = httpProfile# 实例化要请求产品的client对象,clientProfile是可选的client = dlc_client.DlcClient(cred, "region", clientProfile)# 实例化一个请求对象,每个接口都会对应一个request对象req = models.CreateTasksRequest()base64sql = base64.b64encode(sql.encode('utf-8')).decode('utf-8')# print(base64sql)# print(base64sql)params = {"DatabaseName": "db","Tasks": {"TaskType": "SQLTask","FailureTolerance": "Terminate","SQL": base64sql,},"DatasourceConnectionName": "DataLakeCatalog","DataEngineName": "engineName"}req.from_json_string(json.dumps(params))# 返回的resp是一个CreateTasksResponse的实例,与请求对象对应resp = client.CreateTasks(req)# 输出json格式的字符串回包print(resp.to_json_string())return respexcept TencentCloudSDKException as err:print(err)if __name__ == "__main__":try:sql_file = "sql_file_path/dlc.sql"print(sql_file)with open(sql_file, 'r') as file:sqls = file.read()print(sqls)create_rsp = create_task(sqls)except Exception as main_err:print(main_err)
SuperSQL 引擎对接 Apache DolphinScheduler 关键步骤
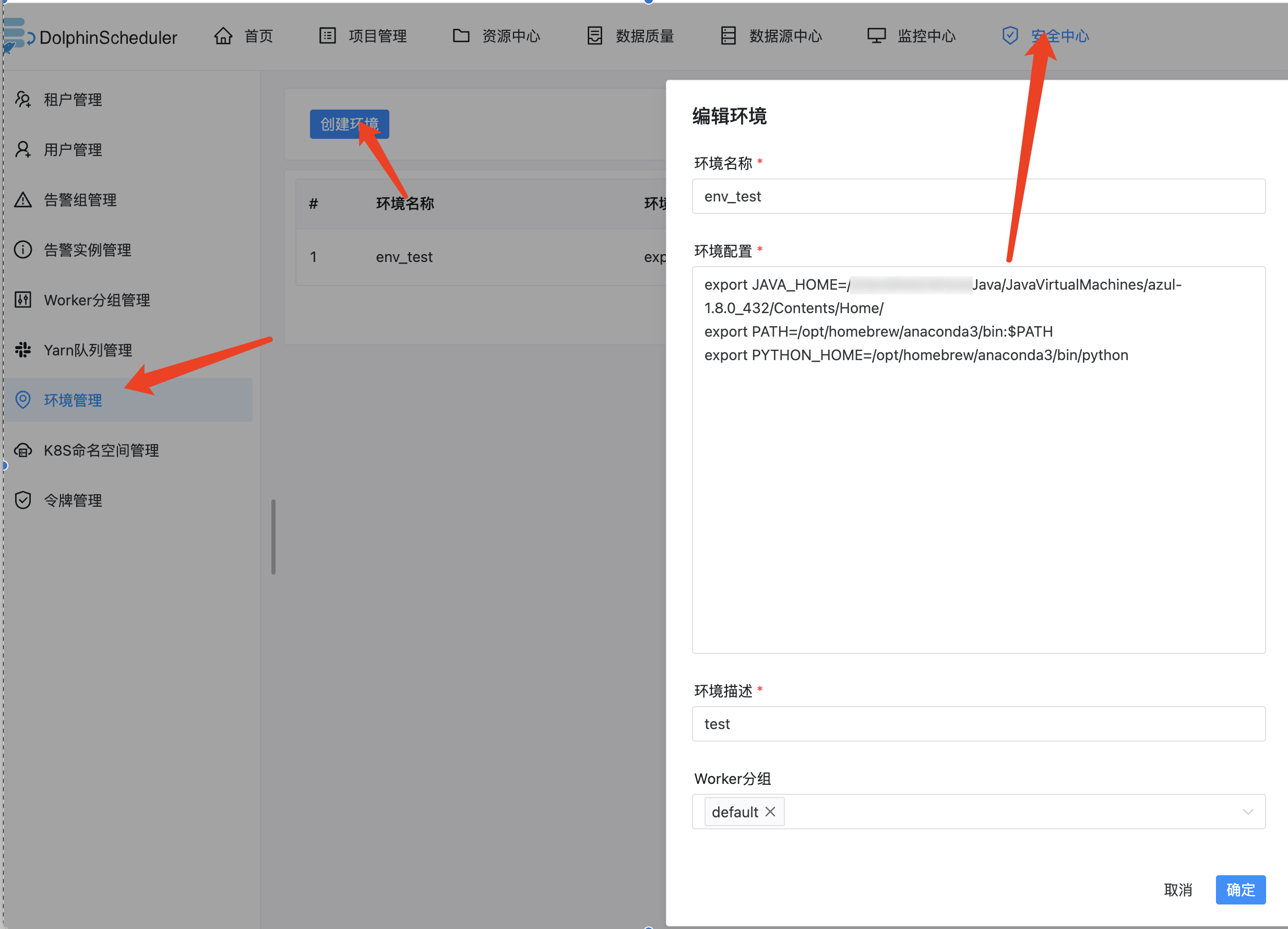
指定环境变量
创建项目和工作流
1. 如图在项目管理下创建一个项目:
2. 进入项目创建一个工作流:
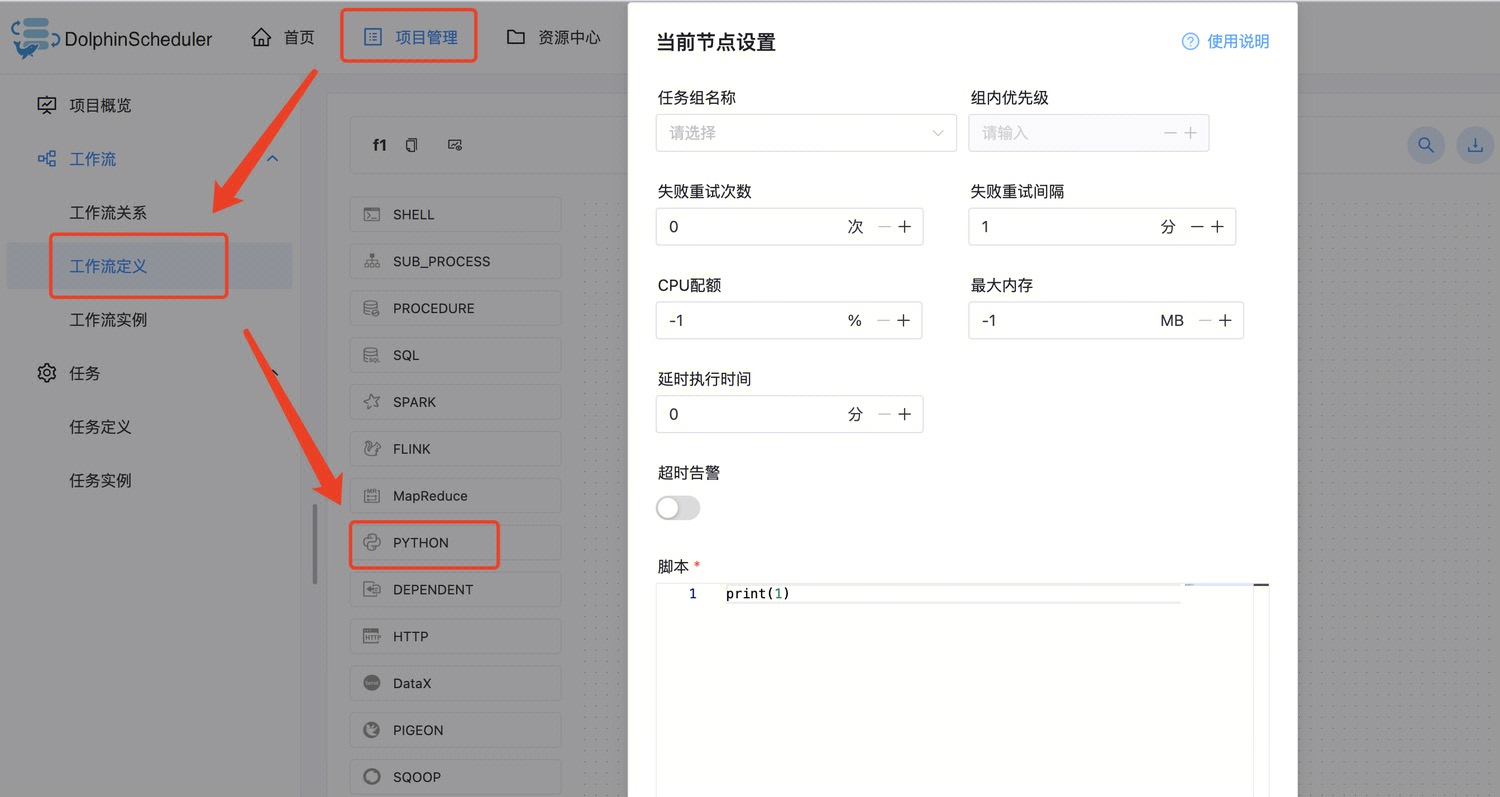
3. 新建 Python 脚本,拖动 Python 组件到编辑区域。
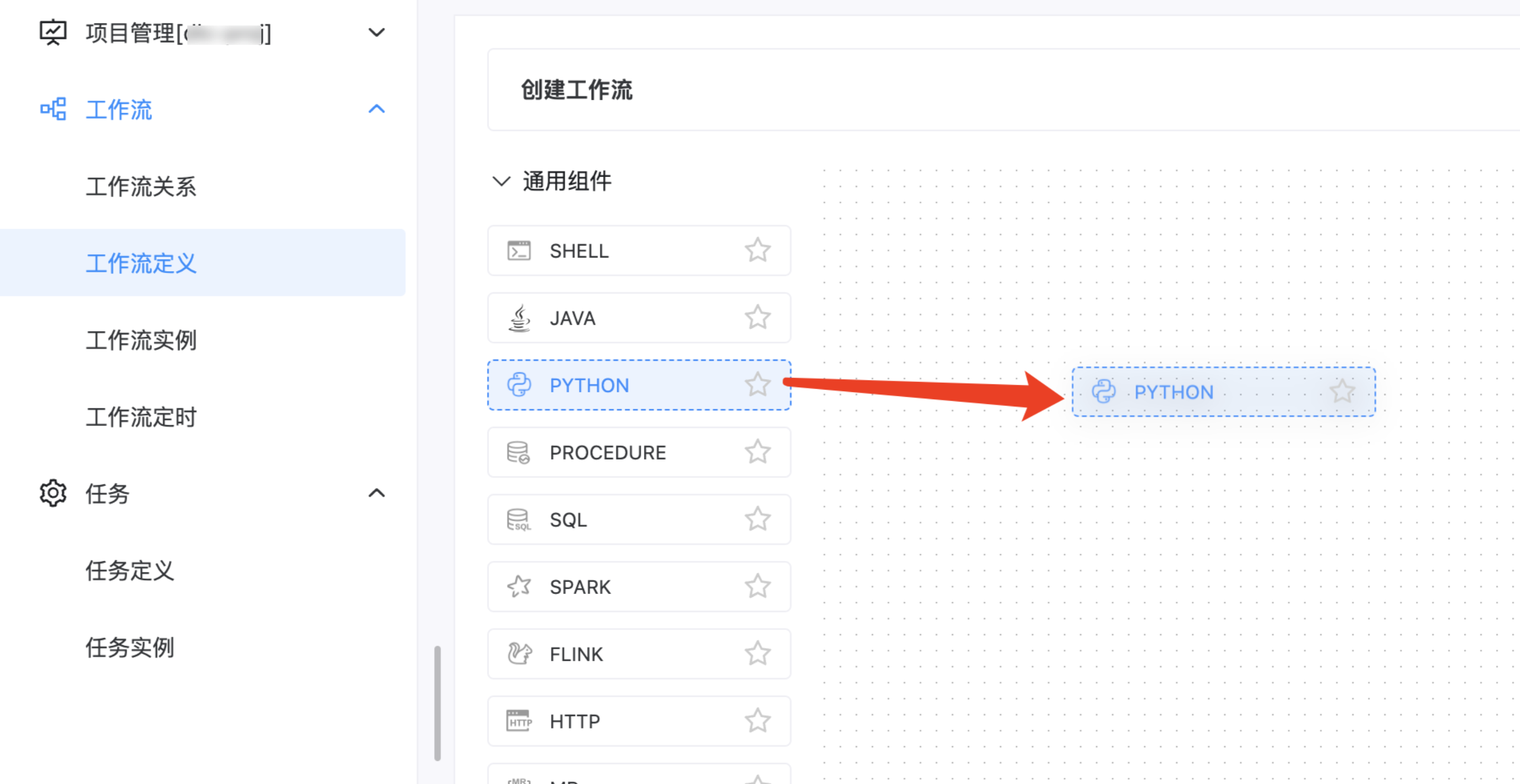
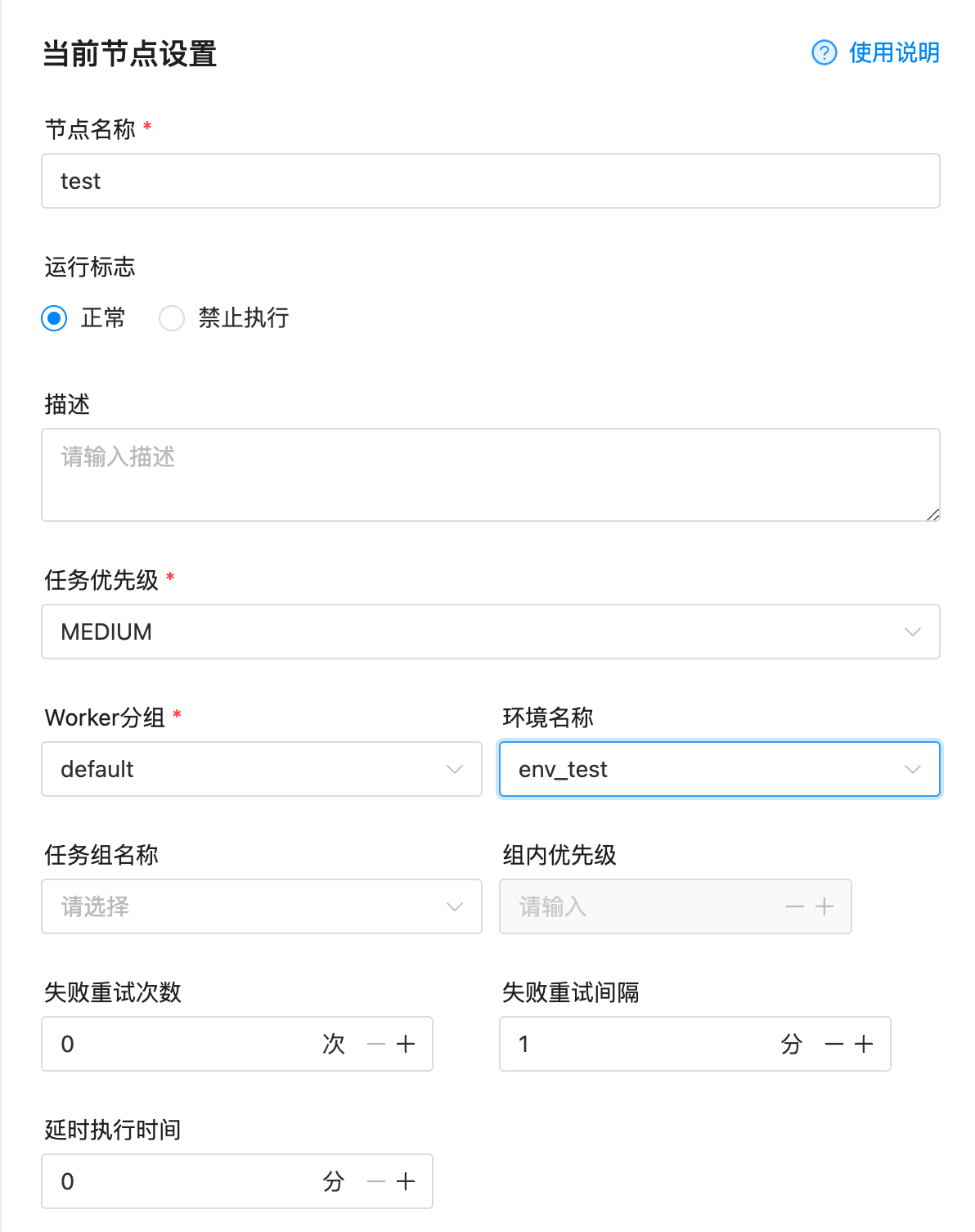
4. 设置节点。
5. 设置脚本。
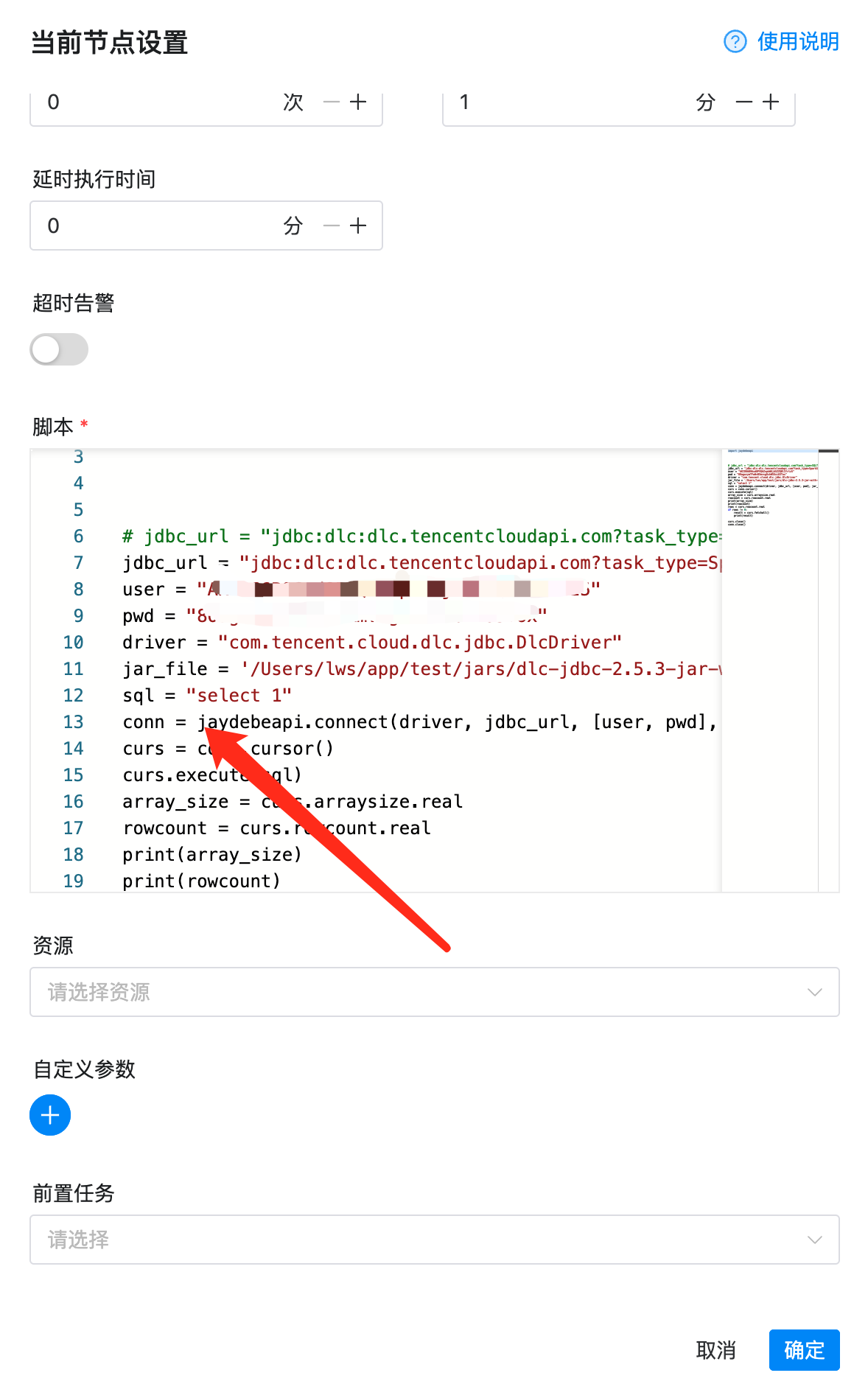
示例代码:
import jaydebeapi jdbc_url = "jdbc:dlc:dlc.tencentcloudapi.com?task_type=SQLTask&datasource_connection_name=DataLakeCatalog®ion=ap-guangzhou&data_engine_name=public-engine" user = "xx" pwd = "xx" driver = "com.tencent.cloud.dlc.jdbc.DlcDriver" jar_file = '/opt/dolphinscheduler/libs/dlc-jdbc-2.2.3-jar-with-dependencies.jar' sql = "select 1" conn = jaydebeapi.connect(driver, jdbc_url, [user, pwd], jar_file) curs = conn.cursor() curs.execute(sql) array_size = curs.arraysize.real rowcount = curs.rowcount.real print(array_size) print(rowcount) rows = curs.rowcount.real if rows != 0: result = curs.fetchall() print(result) curs.close() conn.close()
参数说明:
参数 | 说明 |
jdbc_url | |
user | SecretId |
pwd | SecretKey |
driver | |
jar_file |
6. 单击工作流保存和确定。
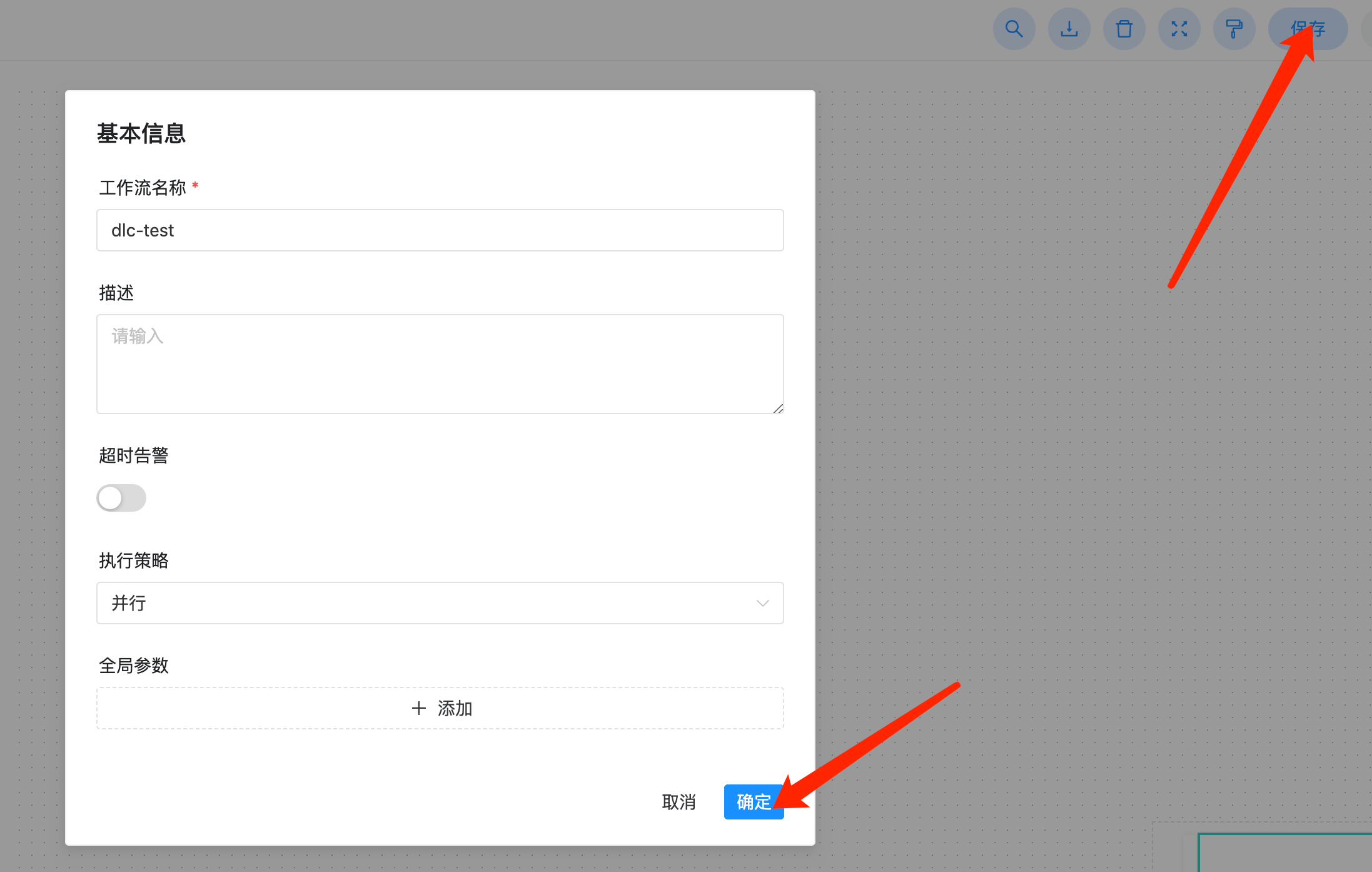
7. 上线工作流。

8. 执行工作流。
9. 查看执行结果。




