概述
DLC 原生表(TC-Iceberg)是腾讯云基于 Iceberg 拓展的批流一体表格式,兼容并包含 Apache Iceberg 所有优势特性,并提供性能增强及近实时湖仓构建能力。与 Apache Iceberg 相比,TC-Iceberg 具备以下特点:
Apache Iceberg 兼容:TC-Iceberg 基于 Iceberg 格式无侵入式扩展,可支持 Apache Iceberg V2 表所有功能,包括 time travel 查询、upsert 操作等。
近实时湖仓能力拓展:相比 Apache Iceberg 中流式写入的更新数据没办法在下游进行流式消费,TC-Iceberg 在支持流式写入的同时,支持按照 CDC(Change Data Capture)格式读取流式增量数据,并提供可扩展的合并过程满足部分列更新等场景。
性能增强:TC-Iceberg 通过自动分桶机制提升了更新场景下的 merge-on-read 性能。
智能的数据优化:TC-Iceberg 支持对表上的写入及查询操作实时监控,根据监控信息自动按需触发优化任务,调度优化资源,调整优化任务优先级进行合理的智能调度,提升优化质量及效率。
注意:
目前 TC-Iceberg 格式处于公测阶段,仅支持有主键表类型,并存在以下约束及限制:
1. DLC 目前仅支持使用标准引擎 Standard-S 1.1 (暂不支持 Standard-S 1.1 Native)对 TC-Iceberg 表进行 DDL、DML 及合并查询,其他版本引擎支持查询 TC-Iceberg 存量数据(BaseStore 中的数据)。
2. 仅支持使用标准引擎 Standard-S 进行数据优化;TC-Iceberg 表开启数据优化后,优化引擎会产生常驻监控资源消耗(默认为 1 CU),优化作业执行资源根据实际需求弹性伸缩。
3. 目前测试版本暂未支持 Java SDK 写入及 Inlong 入湖。
原生表(TC-Iceberg)原理解析
TC-Iceberg 的设计初衷是在完全兼容开源 Iceberg 表格式的基础上,提供现代数据湖场景下完整具备批流一体场景能力的统一的存储格式。
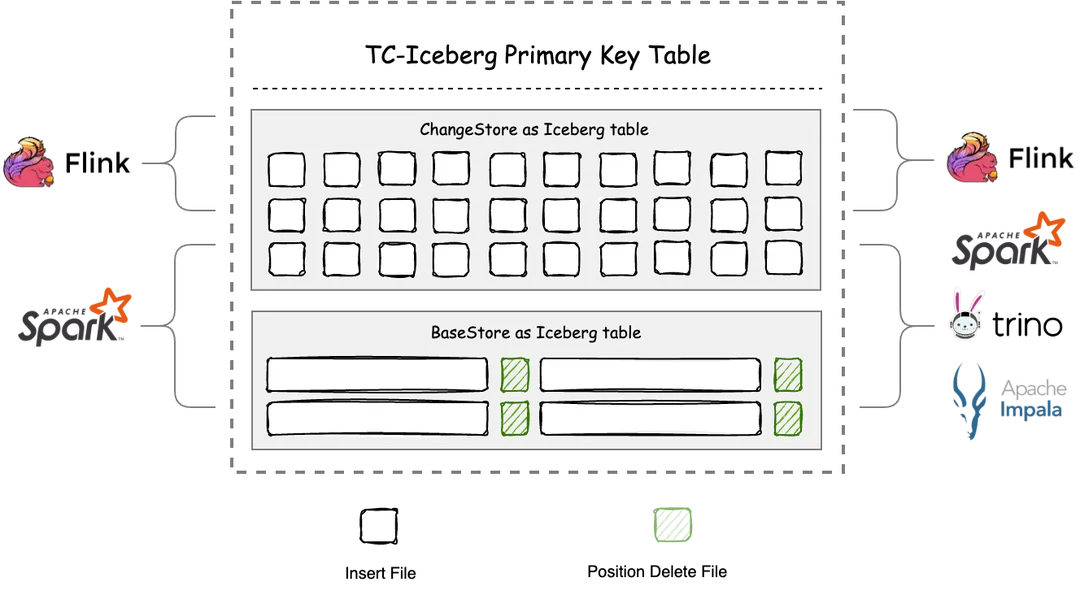
TC-Iceberg 有主键表底层由两张 Iceberg 表构成:
1. ChangeStore:一张独立的 Iceberg 表,存放表中的增量数据,所有表上的操作以追加的方式写入到 ChangeStore 中,写入的数据会自动合并到 BaseStore 中。ChangeStore 的数据一般只保留一段时间,过期的数据会自动被删除。
2. BaseStore:一张独立的 Iceberg 表,存放表中的存量数据,能够兼容 Iceberg 表的原生读写。BaseStore 只有 Insert File 和 Position Delete File,具有较好的数据分析性能,但数据会有一段延迟。
同时 TC-Iceberg 格式中还有两个重要的过程:
1. Merge-On-Read:读时合并 ChangeStore 与 BaseStore 中的数据,能保证数据分析场景下的数据延迟。
2. Auto Compaction:智能优化服务还会定期将 ChangeStore 中的数据自动合并入 BaseStore,以保证 merge-on-read 流程的性能。
BaseStore 和 ChangeStore 均采用 Apache Iceberg 格式,在 Schema、数据格式、数据类型、分区使用等方面与 Iceberg 保持一致。
原生表(TC-Iceberg)建表属性
为更好的管理和使用 DLC 原生表(TC-Iceberg),您创建该类型的表时需要携带一些属性,这些属性参考如下。用户在创建表时可以携带上这些属性值,也可以修改表的属性值,详细的操作请参见 原生表(TC-Iceberg)操作配置。
属性值 | 含义 | 配置指导 |
base.file-index.hash-bucket | BaseStore 中 hash 文件索引使用的桶的个数 | 默认为4,取值必须为2的指数,建议根据分区内的数据量来评估,一般建议每个桶存储1GB~2GB 的数据。 |
change.file-index.hash-bucket | ChangeStore 中 hash 文件索引使用的桶的个数 | 默认为4,取值必须为2的指数,建议根据分区内的增量数据写入情况来评估,一般建议每个桶每次写入的增量数据在1MB~2MB。 |
原生表(TC-Iceberg)核心能力
原生表(TC-Iceberg)在 ACID 事务、隐藏式分区、元数据查询和存储过程等与原生表(Iceberg)具备同样能力,详情请参见 原生表(Iceberg)格式说明。除此之外,TC-Iceberg 提供以下额外核心能力:
CDC 流式消费
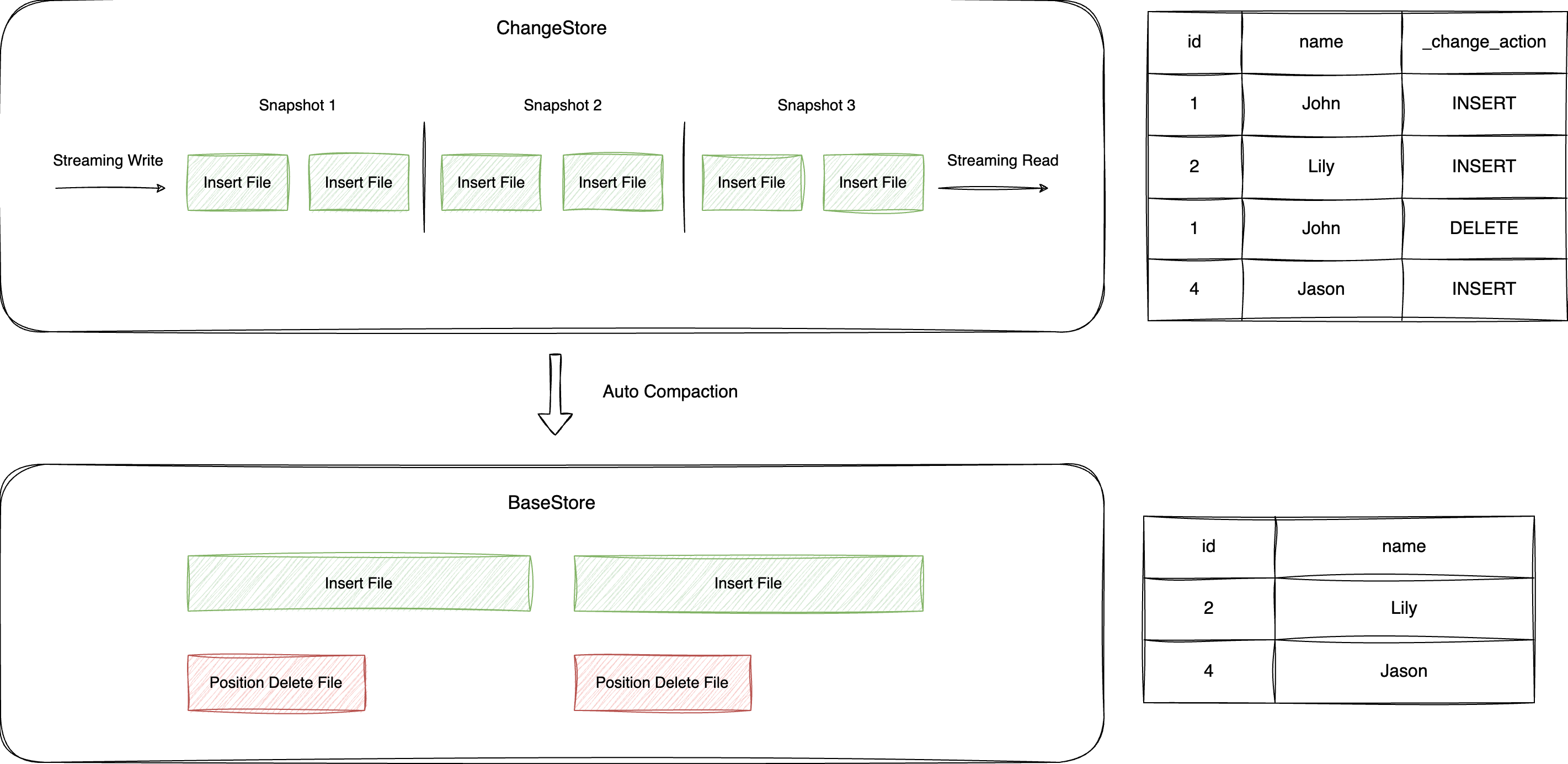
TC-Iceberg 有主键表的结构中,ChangeStore 用来专门存储表中的 CDC 数据,Apache Flink 等流计算引擎将上游产生的 CDC 数据以 Append 的方式定期追加到 ChangeStore 中,下游的 Flink 任务再通过不断刷新表中的新增快照,以流式方式消费表中的 CDC 数据。值得注意的是,ChangeStore 的表结构中会额外多出三个元数据字段:
1. _change_action:标记这行数据的操作类型,可能的值包括:INSERT/UPDATE_BEFORE/UPDATE_AFTER/DELETE。
2. _transaction_id:标记这行数据产生的事务 ID,事务 ID 是从1开始自增的全局 ID,越大的事务 ID 说明数据是越晚写入的。
3. _file_offset:标记这行数据在这个事务里的顺序,越大的顺序表示数据是越晚写入的。
自动分桶加速数据合并
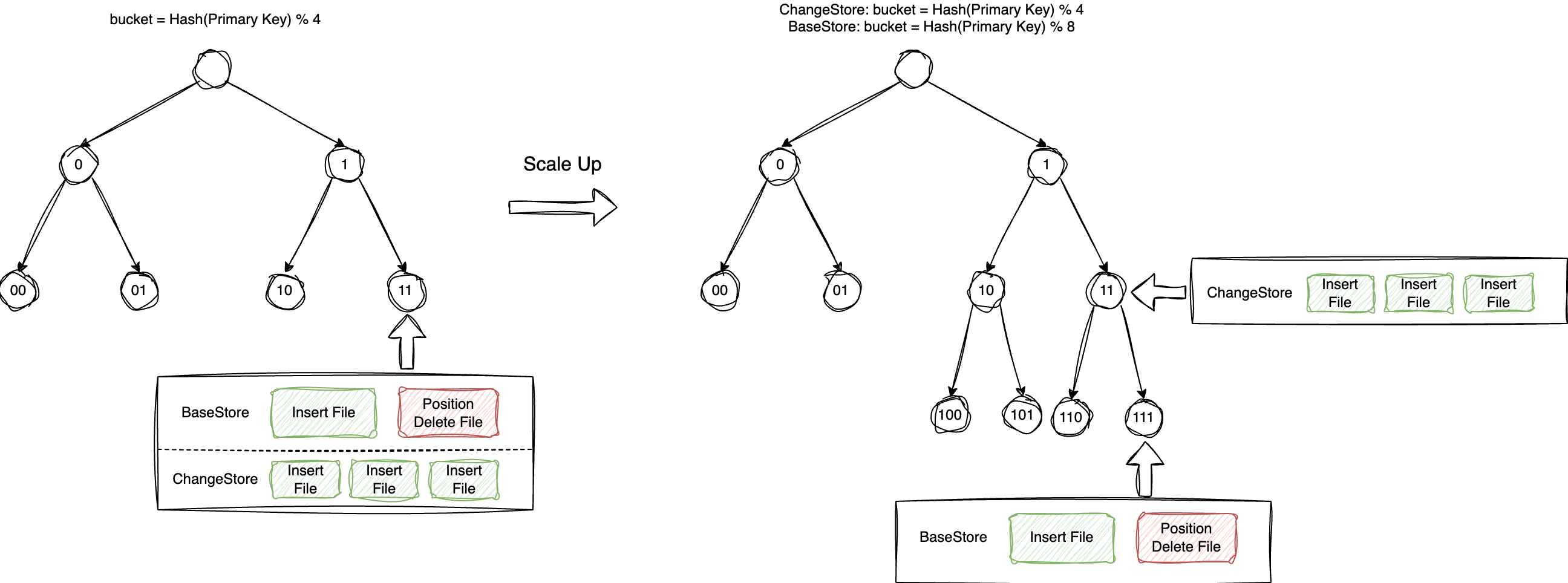
原生表(TC-Iceberg)提供了自动分桶机制来同时提升 merge-on-read 和 Auto Compaction 的性能。自动分桶具体指在 BaseStore 与 ChangeStore 中将数据根据主键拆分到不同的桶中,这样只有相同桶内的数据需要合并,这样不仅缩小了数据合并的范围,同时提升了数据合并的并行度。
BaseStore 与 ChangeStore 拆分桶的个数不一定一样,BaseStore 一般根据表中的数据总量来分桶,一般一个桶存储1GB 到2GB 的数据,ChangeStore 则根据增量数据的写入量来拆分,一般保证一个桶一次写入的数据不少于1MB。
可扩展的合并过程
原生表(TC-Iceberg)中,ChangeStore 中的数据合并入 BaseStore 的过程支持扩展,可以通过在表上设置不同的 merge-function 参数来指定不同的合并过程,现阶段支持的合并过程包括:
1. replace:表示 ChangeStore 里的内容根据主键覆盖 BaseStore 里的内容,这是最常见也是默认的合并方式。
2. partial-update:ChangeStore 里的内容根据主键覆盖 BaseStore 里的内容时,并不是覆盖所有的字段,而是只更新部分字段。这种合并过程通常使用在实时大表打宽的场景,上游使用不同的写入任务写入主键和表中的部分字段,原生表(TC-Iceberg)中在数据合并时根据主键完成数据打宽并更新入 BaseStore 中。
智能数据优化
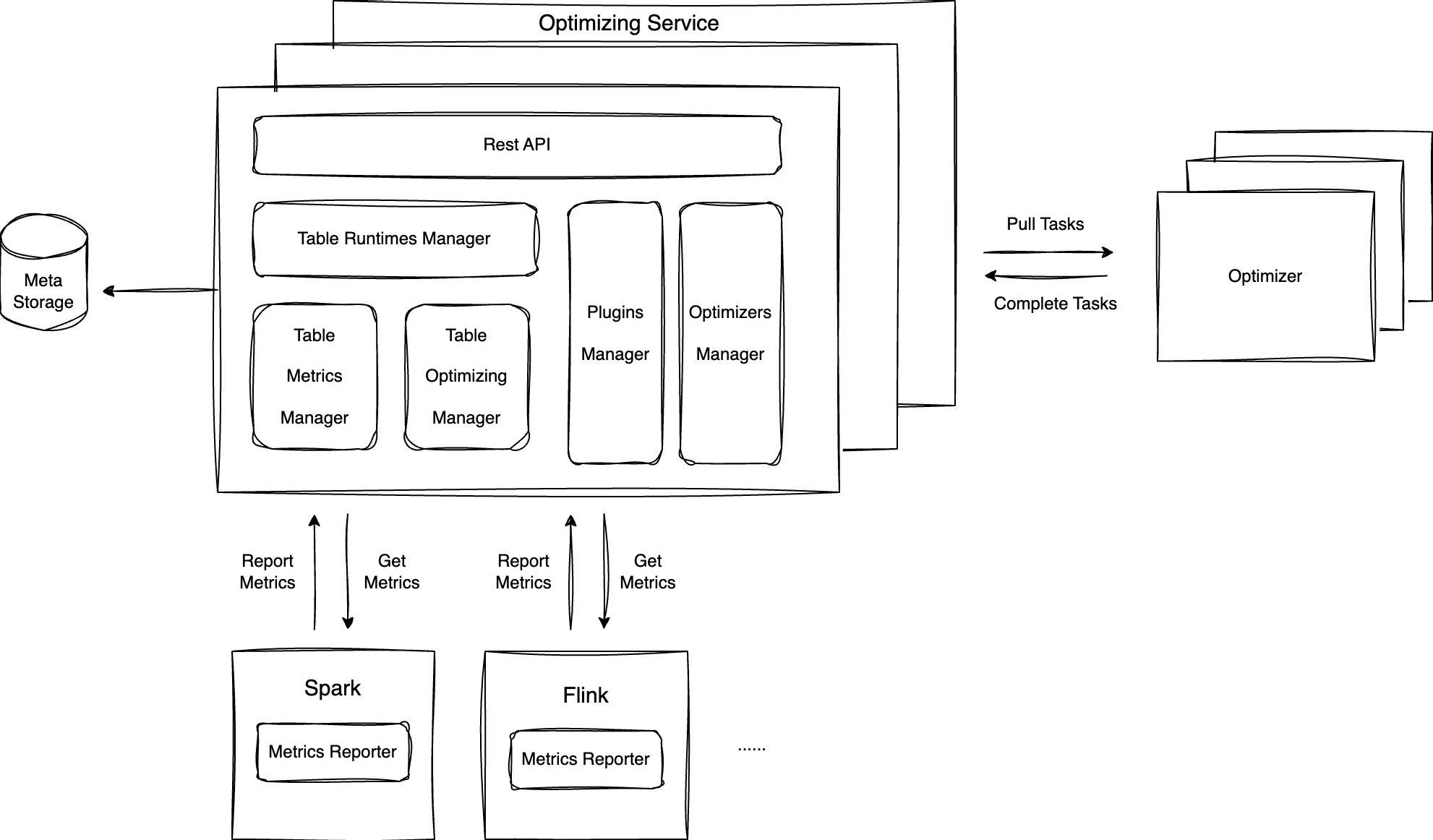
原生表(TC-Iceberg)中 ChangeStore 中的数据自动合并入 BaseStore 的过程由自动优化服务完成。自动优化服务包括以下组件:
1. Metrics Reporter:作为插件安装在计算引擎中(如 Spark/Flink),当表上有写入/读取操作时会产生 metric 事件上报 Optimizing Service。
2. Optimizing Service:合并服务的管理组件,接收 Metrics Reporter 上报的监控事件,根据监控事件智能调度出优化任务,交由 Optimizer 执行。
3. Optimizer:优化任务的执行节点,由 Optimizing Service 根据负载动态调度,从 Optimizing Service 拉取优化任务,执行并上报执行结果。
当前自动优化服务上执行的优化任务包括:
1. 文件合并类任务:包括将 ChangeStore 中的数据合并入 BaseStore,合并 BaseStore 内的小文件,将 Delete File 合并入 Insert File。
2. 存储清理类任务:包括自动过期快照,清理孤儿文件,数据生命周期管理,无效 Delete File 清理等。
3. 分析加速类任务:包括数据自动排序,构建 Bloom Filter/Bitmap 二级索引,构建 Table Statistics/Partition Statistics 等。



