DLC 数据湖计算支持创建原生表(Iceberg)、外表多种场景。具体可参考以下实践案例进行建表。
创建原生表(Iceberg)
Spark ETL 建表场景
适用于:周期的进行 insert into、insert overwrite、merge into 等批作业操作。
/**默认为 copy-on-write 模式,两种模式如果不确定,可不用配置,使用 copy-on-write 模式,merge-on-read 对行级更新场景有较大优化。copy-on-write 适配场景: 查询性能相对更快,写入相对较慢,适用于周期的 ETL 任务或者较多数据量批量更新操作场景。merge-on-read 适配场景: 查询性能相对稍慢,写入更快,适用对写入性能有要求的场景,行级更新能力强,对有频繁小范围(<10%) merge into/update/delete 或者 Oceanus(Flink 流式写入场景) 写入性能提升较大。*//** copy on write 表 */CREATE TABLE dlc_db.iceberg_etl (id INT,name string,age INT) TBLPROPERTIES ('format-version' = '2','write.metadata.previous-versions-max' = '100','write.metadata.delete-after-commit.enabled' = 'true');/** merge on read 表 */CREATE TABLE dlc_db.iceberg_etl (id INT,name string,age INT) TBLPROPERTIES ('format-version' = '2','write.metadata.previous-versions-max' = '100','write.metadata.delete-after-commit.enabled' = 'true','write.update.mode' = 'merge-on-read','write.merge.mode' = 'merge-on-read','write.delete.mode' = 'merge-on-read');
控制台创建:copy-on-write 模式
1. 单击创建原生表。
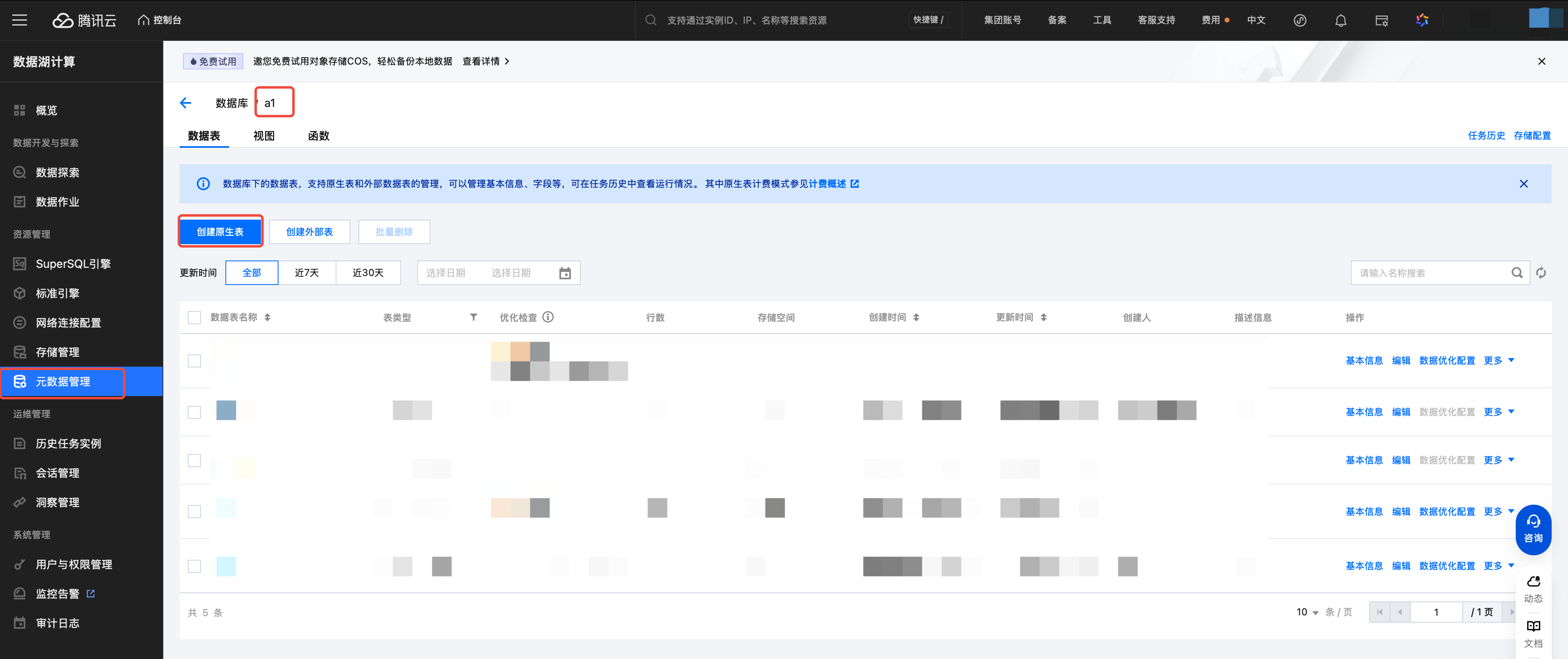
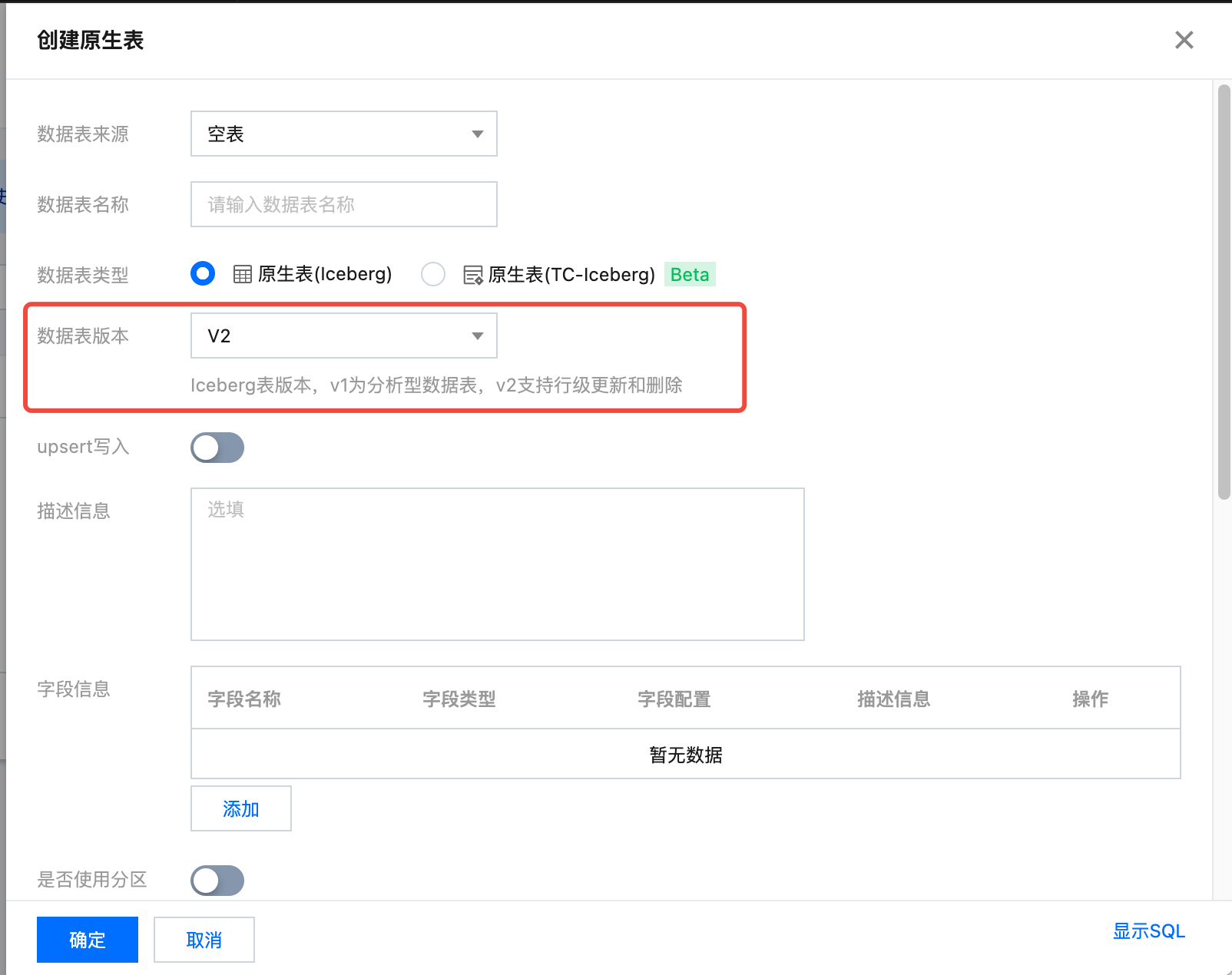
2. 选择数据表版本。
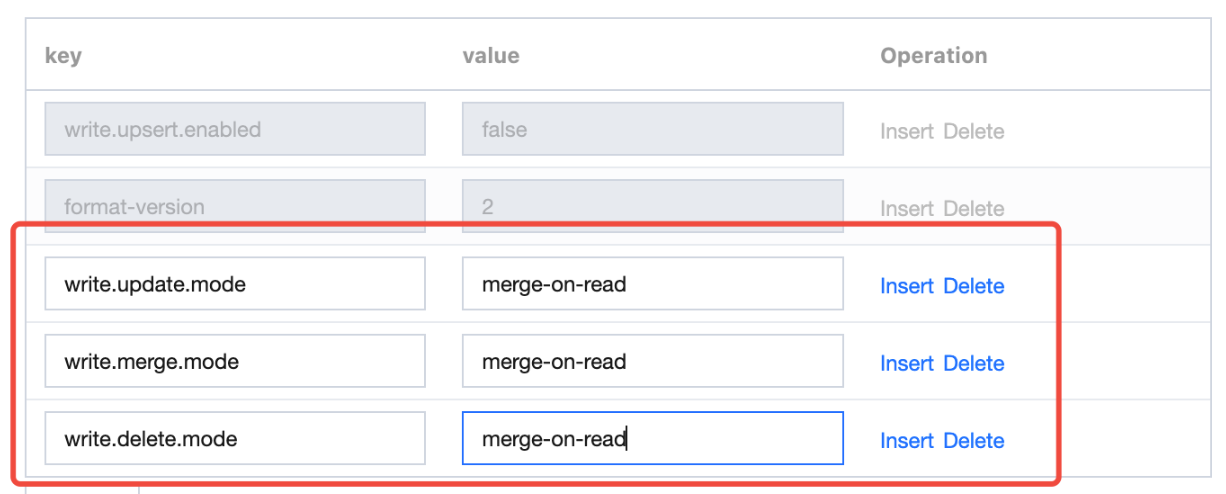
控制台创建:merge-on-read 模式(需要额外添加三个属性值):
Flink 流式写入场景
适用于:Oceanus (Flink 流式写入) 场景。
/** flink 流式写入主键为 id */CREATE TABLE dlc_db.iceberg_cdc_by_id (id INT,name string,age INT) TBLPROPERTIES ('format-version' = '2','write.metadata.previous-versions-max' = '100','write.metadata.delete-after-commit.enabled' = 'true','write.upsert.enabled' = 'true','write.update.mode' = 'merge-on-read','write.merge.mode' = 'merge-on-read','write.delete.mode' = 'merge-on-read','write.distribution-mode' = 'hash','write.parquet.bloom-filter-enabled.column.id' = 'true','dlc.ao.data.govern.sorted.keys' = 'id');/** flink 流式写入主键为 id,name 联合主键 */CREATE TABLE dlc_db.iceberg_cdc_by_id_and_name (id INT,name string,age INT) TBLPROPERTIES ('format-version' = '2','write.metadata.previous-versions-max' = '100','write.metadata.delete-after-commit.enabled' = 'true','write.upsert.enabled' = 'true','write.update.mode' = 'merge-on-read','write.merge.mode' = 'merge-on-read','write.delete.mode' = 'merge-on-read','write.distribution-mode' = 'hash','write.parquet.bloom-filter-enabled.column.id' = 'true','write.parquet.bloom-filter-enabled.column.name' = 'true','dlc.ao.data.govern.sorted.keys' = 'id,name');
控制台创建:主键为 id 的表
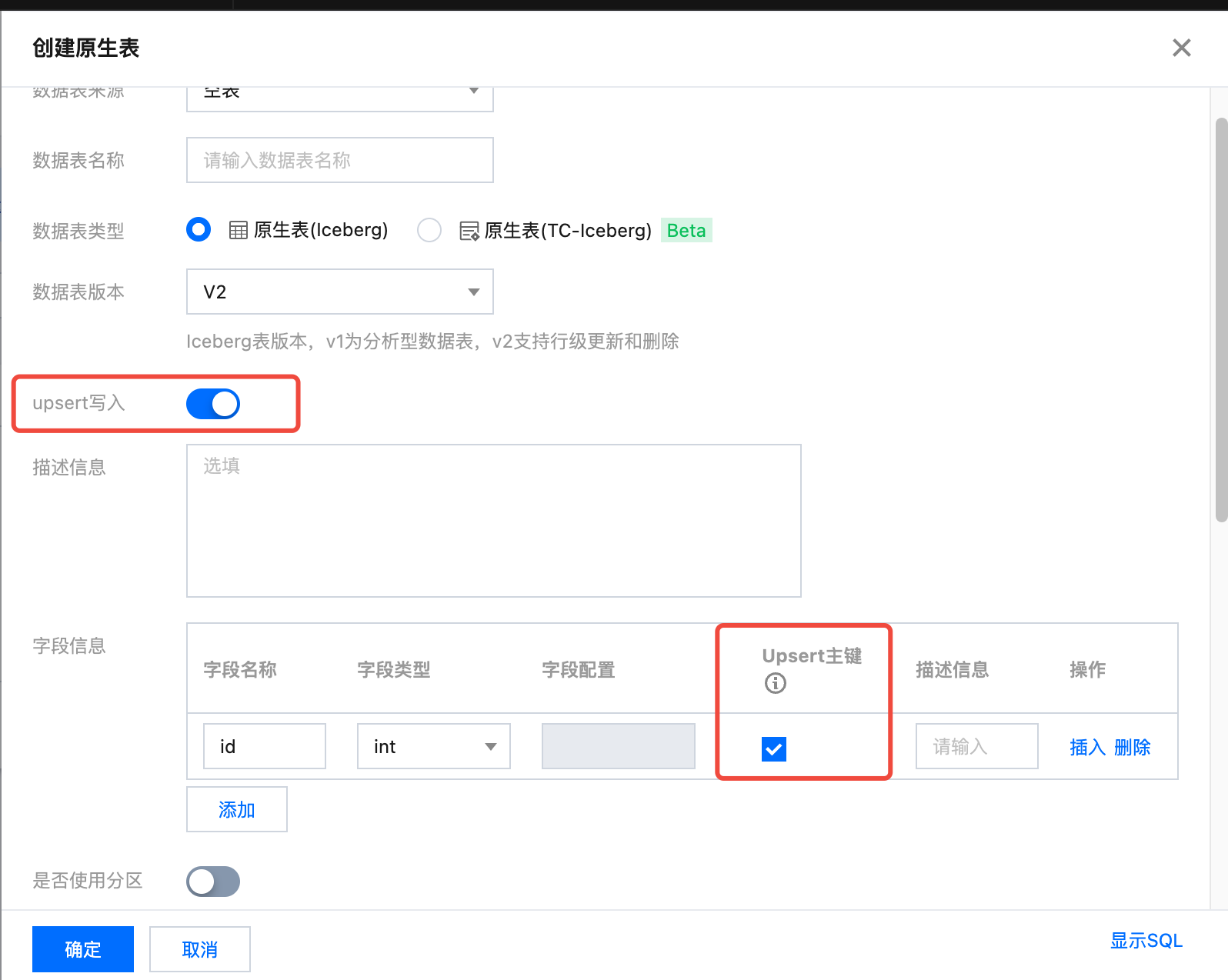
配置说明
属性值 | 含义 | 配置指导 |
format-version | Iceberg 表版本,取值范围1、2。 标准引擎 Spark Standard-S 1.1、SuperSQL Spark 3.5 默认取值为2,其余场景默认值为1 | 建议配置为2 |
write.upsert.enabled | 是否开启 upsert,取值为 true;不设置则为不开启 | 如果用户写入场景有 upsert,必须设置为 true |
write.update.mode | 更新模式 | 缺省为 copy-on-write 默认为 copy-on-write 模式,两种模式如果不确定,可不用配置,使用 copy-on-write 模式,merge-on-read 对行级更新场景有较大优化。 copy-on-write 适配场景: 查询性能相对更快,写入相对较慢,适用于周期的 ETL 任务或者较多数据量批量更新操作场景。 merge-on-read 适配场景: 查询性能相对稍慢,写入更快,适用于对写入性能有要求的场景,行级更新能力强,对有频繁小范围(<10%) merge into/update/delete 或者 Oceanus(Flink 流式写入场景) 写入性能提升较大。 |
write.merge.mode | merge 模式 | 缺省为 copy-on-write 默认为 copy-on-write 模式,两种模式如果不确定,可不用配置,使用 copy-on-write 模式,merge-on-read 对行级更新场景有较大优化。 copy-on-write 适配场景: 查询性能相对更快,写入相对较慢,适用于周期的 ETL 任务或者较多数据量批量更新操作场景。 merge-on-read 适配场景: 查询性能相对稍慢,写入更快,适用于对写入性能有要求的场景,行级更新能力强,对有频繁小范围(<10%) merge into/update/delete 或者 Oceanus(Flink 流式写入场景) 写入性能提升较大。 |
write.parquet.bloom-filter-enabled.column.{col} | 仅用于Oceanus (Flink 流式写入) 场景,开启 bloom,取值为 true 表示开启,缺省不开启 | Flink 流式写入场景必须开启,需要根据上游的主键进行配置;如上游有多个主键,最多取前两个;开启后可提升 MOR 查询和小文件合并性能 |
write.distribution-mode | 写入模式 | 取值为 hash 时,当数据写入时会自行进行 repartition,缺点是影响部分写入性能,建议保持默认行为; Flink 流式写入场景,建议配置为 hash ,可优化写入性能,其他场景建议不配置,保持默认值 |
write.metadata.delete-after-commit.enabled | 开始 metadata 文件自动清理 | 强烈建议设置为 true,开启后 Iceberg 在产生快照时会自动清理历史的 metadata 文件,可避免大量的 metadata 文件堆积 |
write.metadata.previous-versions-max | 设置默认保留的 metadata 文件数量 | 默认值为100,在某些特殊的情况下,用户可适当调整该值,需要配合 write.metadata.delete-after-commit.enabled 一起使用 |
创建外表
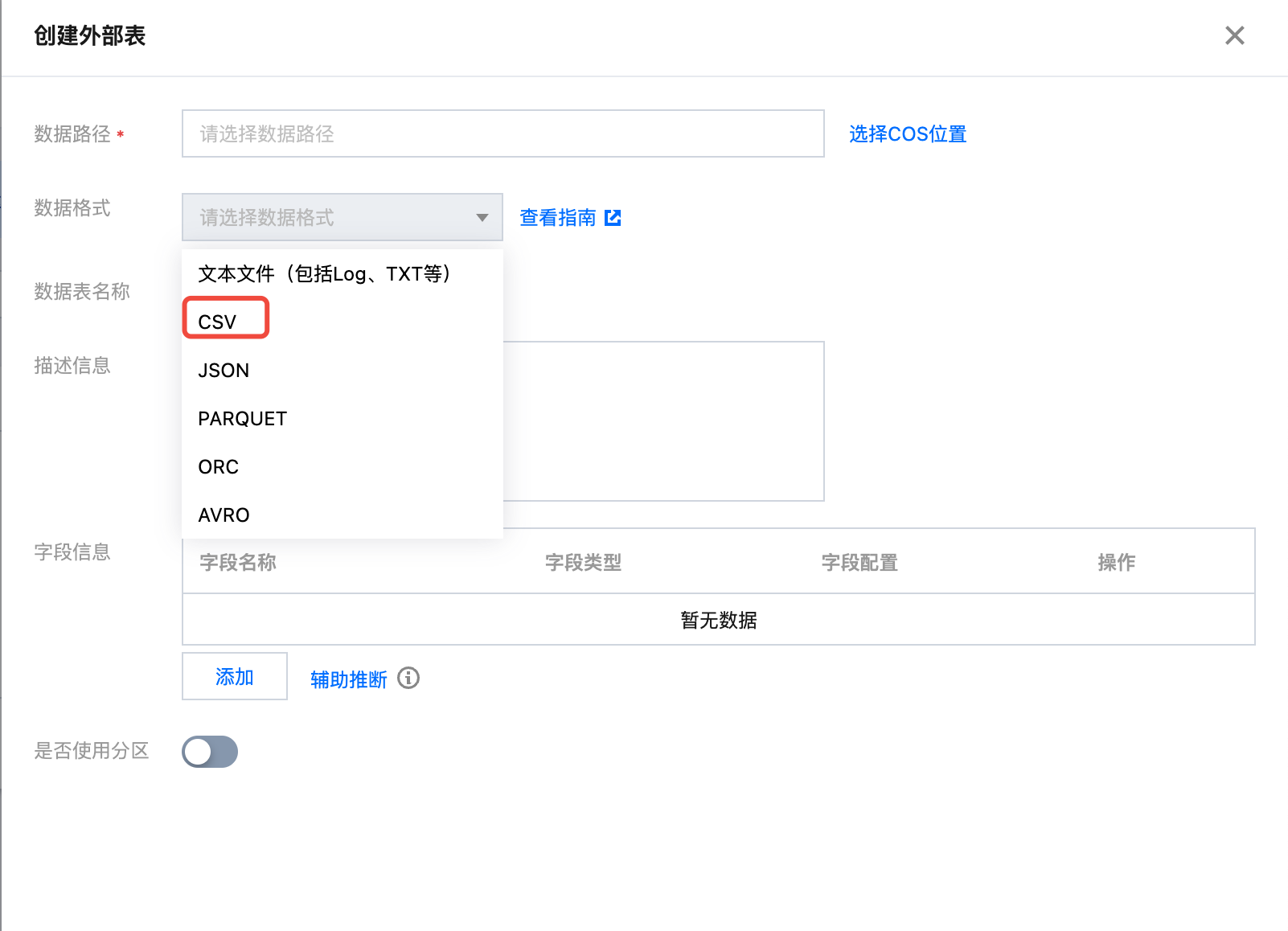
创建 CSV 格式外表
/**1. separatorChar: 分隔符,默认是 , 。用于指定 CSV 文件中字段之间的分隔符,帮助 Hive 正确解析每一行中的字段。2. quoteChar : 引用字符,默认是 " , 如果原始文件无引用字符,可以用默认值。引用字符作用是 可以帮助处理包含分隔符(如逗号)或换行符的字段。例如,column1 字段值 x1,x2 如果被双引号包围 "x1,x2" ,就不会被错误地解析为两个独立的字段。3. LOCATION: 需要修改为对应 cos 上的存储路径4. TBLPROPERTIES 中的 skip.header.line.count 表属性: 默认0,配置1 代表跳过一行,该属性用于指定在读取文件时应跳过的表头行数,因为很多 csv 文件的表头通常包含列名而不是实际数据*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.`csv_tb`(`id` int,`name` string)ROW FORMAT SERDE'org.apache.hadoop.hive.serde2.OpenCSVSerde'WITH SERDEPROPERTIES ('quoteChar'='"','separatorChar'=',')STORED AS INPUTFORMAT'org.apache.hadoop.mapred.TextInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION'cosn://your_cos_location'TBLPROPERTIES ('skip.header.line.count'='1');
控制台创建
创建 JSON 格式外表
/**LOCATION: 指向对应的 cos 存储目录, 其他保持原样*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.json_demo(`id` bigint, `name` string)ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'STORED AS TEXTFILELOCATION 'cosn://your_cos_location'
JSON 文件内容示例,每行是一个独立的 json 串:
{"id":1,"name":"tom"}{"id":2,"name":"tony"}
创建 parquet 格式外表
/**LOCATION: 指向对应的 cos 存储目录,其他保持原样*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.parquet_demo(`id` int, `name` string)PARTITIONED BY (`dt` string)STORED AS PARQUET LOCATION 'cosn://your_cos_location';
创建 ORC 格式外表
/**LOCATION: 指向对应的 cos 存储目录,其他保持原样*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.orc_demo(`id` int,`name` string)PARTITIONED BY (`dt` string)STORED AS ORC LOCATION 'cosn://your_cos_location'
创建 AVRO 格式外表
/**LOCATION: 指向对应的 cos 存储目录,其他保持原样*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.avro_demo(`id` int,`name` string)PARTITIONED BY (`dt` string)STORED AS ORC LOCATION 'cosn://your_cos_location'
补充
列类型和分区列
注意:
二进制类型字段 binary 在执行 select 查询语句时可能会遇到如下报错。原因是引擎默认将结果集写入 csv 文件,暂不支持将二进制数据写入 csv 文件。

解决方法(支持任务级配置):
1. 更改保存结果的文件格式: kyuubi.operation.result.saveToFile.format=parquet (设置存储文件格式,可选项: parquet, orc)。
2. 更改配置不保存结果到 cos: kyuubi.operation.result.saveToFile.enabled=false。
复杂列类型
/**LOCATION: 指向对应的 cos 存储目录其他保持原样*/CREATE EXTERNAL TABLE dlc_db.orc_demo_with_complex_type(col_bigint bigint COMMENT 'id number',col_int int,col_struct struct<x: double, y: double>,col_array array<struct<x: double, y: double>>,col_map map<struct<x: int>, struct<a: int>>,col_decimal DECIMAL(10,2),col_float FLOAT,col_double DOUBLE,col_string STRING,col_boolean BOOLEAN,col_date DATE,col_timestamp TIMESTAMP)PARTITIONED BY (`dt` string)STORED AS ORC LOCATION 'cosn://your_cos_location';
注意:
1. AVRO 格式数据源不支持 map 类型和 array 类型嵌套 struct 结构。
2. AVRO 格式数据源 map 类型字段的 key 仅支持 string 类型。
3. CSV 格式数据源使用 struct、array、map 类型字段时可能会遇到如下报错,原因是引擎对数据格式做了强校验。
解决方法:解除引擎的强校验设置,设置引擎静态参数 spark.sql.storeAssignmentPolicy=legacy。
复杂分区类型
1. LOCATION: 需要修改为对应 COS 上的存储路径。
2. 支持的分区字段类型有TINYINT,SMALLINT,INT,BIGINT,DECIMAL,FLOAT(不推荐,建议使用DECIMAL),DOUBLE(不推荐,建议使用 DECIMAL),STRING,BOOLEAN,DATE,TIMESTAMP。
CREATE EXTERNAL TABLE dlc_db.orc_demo_with_complex_partition(col_int int)PARTITIONED BY (pt_tinyint TINYINT,pt_smallint SMALLINT,pt_decimal DECIMAL(10,2),pt_string STRING,pt_date DATE,pt_timestamp TIMESTAMP )STORED AS ORC LOCATION 'cosn://lcl-bucket-1305424723/dlc/orc_demo_with_complex_partition/';
注意:
HIVE 类型表分区名之和不能超过767个字符。
元数据不区分大小写
元数据中的表名和列名在使用时不区分大小写,但在数据管理界面展示时会保留创建时的原始大小写格式。



