数据湖计算 DLC 支持通过 spark 引擎创建机器学习资源组的方式,协助用户进行模型训练等机器学习场景。
通过本篇文档,您可根据我们提供的 demo 数据集与代码示例,体验在 Scikit-learn 的框架下进行模型训练的实践体验。
说明:
资源组:Spark 标准引擎计算资源的二级队列划分,资源组隶属于父级标准引擎且同一引擎下的资源组彼此资源共享。
DLC Spark 标准引擎的计算单元(CU)可按需被划分到多个资源组中,并设置每个资源组可使用CU数量的最小值和上限、启停策略、并发数和动静态参数等,从而满足多租户、多任务等复杂场景下的计算资源隔离与工作负载的高效管理。实现不同类别任务间的资源隔离,避免个别大查询将资源长期抢占。
目前 DLC 机器学习资源组、WeData Notebook 探索、机器学习均为开白功能,如需使用,请 提交工单 联系 DLC 与 WeData 团队开通机器学习资源组、Notebook、MLFlow 服务。
开通账号与产品
开通账号与产品
DLC 账号与产品开通功能均需腾讯云主账号进行开通,主账号完成后,默认主账号下所有子账号均可使用。如果需要调整,可通过 CAM 功能进行调整。具体操作指引请参见 新用户开通全流程。
Wedata 账号与产品开通请参见 准备工作、数据湖计算 DLC(DLC)。
Wedata的 MLflow 服务开通为主账号粒度,一个主账号操作完成后,该主账号下的所有子账号均可使用。
需要提供客户的地域信息、APPID、主账号UIN、VPC ID和子网ID,其中 VPC 和子网信息用于 MLflow 服务的网络打通操作。
说明:
因产品中多个功能需要进行网络打通操作,为确保网络连通性,建议后续购买执行资源组、创建 Notebook 工作空间等操作都在这一个 VPC 和子网中进行。
配置数据访问策略
数据访问策略(CAM role arn)是为了保障数据作业运行过程中访问的数据源及对象存储 COS 上的数据安全,用户在访问管理(CAM)上对数据访问权限进行配置的策略。
在数据湖计算 DLC 中配置数据作业时,需指定对应的数据访问策略,以保证数据安全。
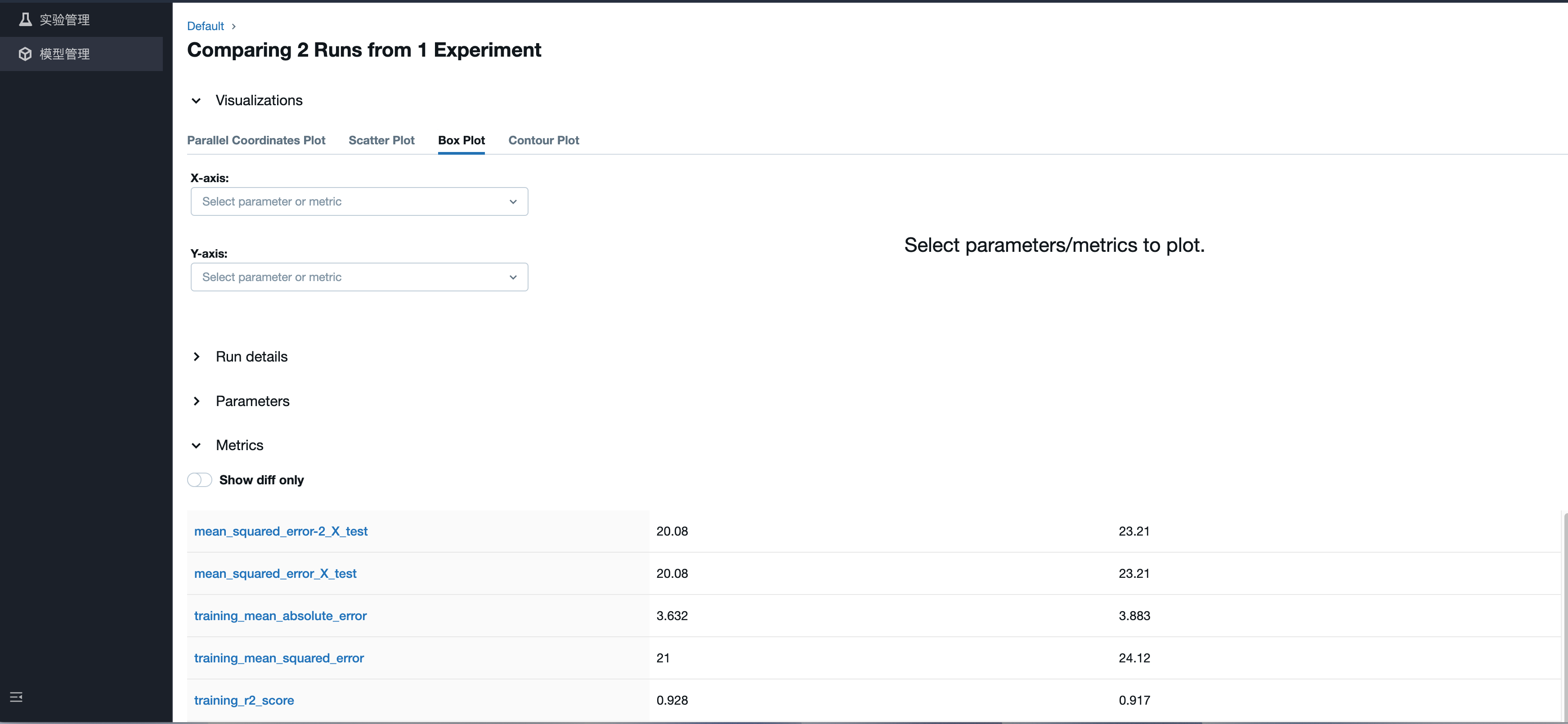
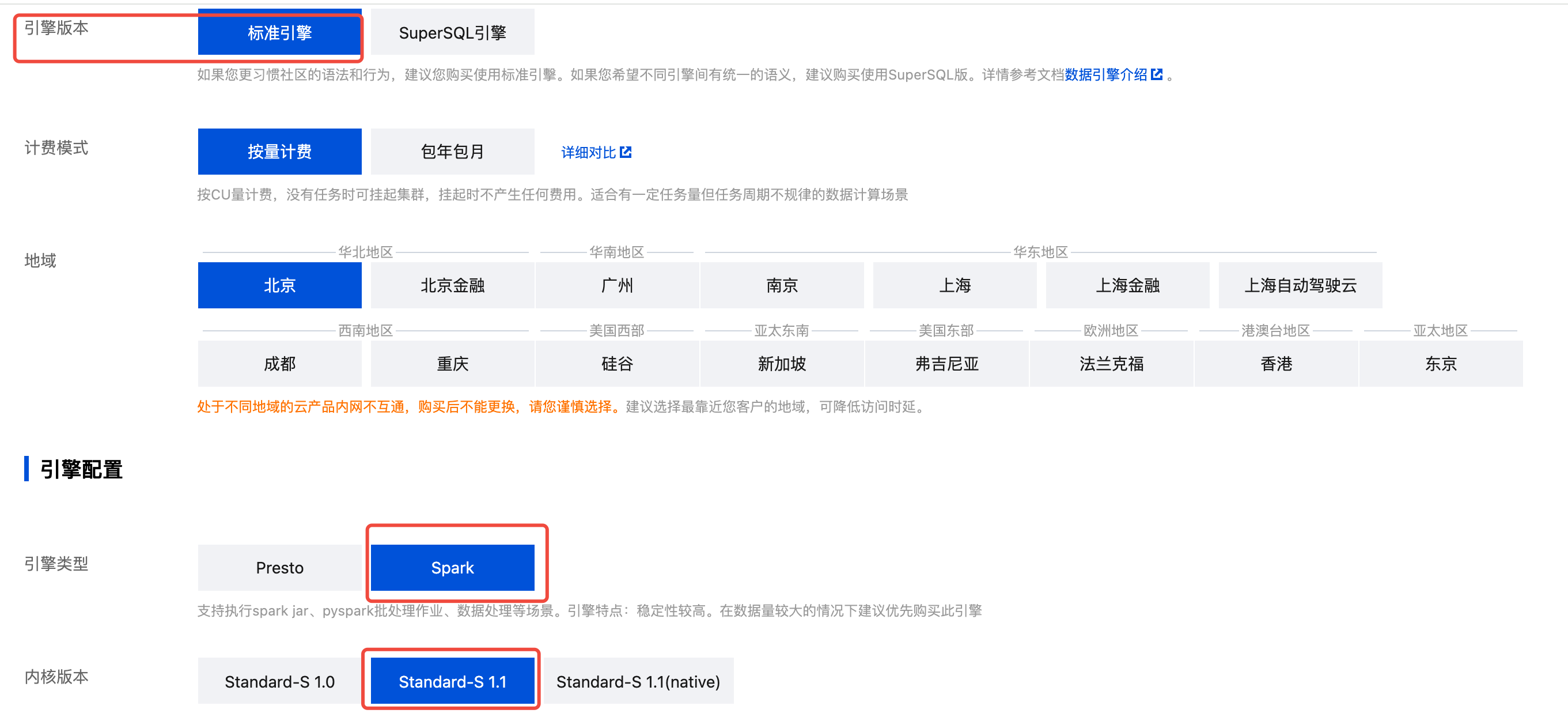
在 DLC 购买计算资源
在产品服务开通完成后,您可先通过数据湖计算 DLC 购买计算资源。如果您需要使用机器学习功能,请确认购买的引擎类型为:标准引擎-spark,内核版本为:Standard-S 1.1。
1. 进入数据湖计算DLC > 标准引擎页面。
2. 选择“创建资源”。
3. 购买标准引擎-spark,内核版本选择:Standard1.1。
说明:
1. 购买账号需要有财务权限或是主账号进行购买。
2. 计费模式您可根据您的业务场景进行选择。
3. 集群规格建议选择64CU以上。
4. 购买成功后,首次启动会有数分钟的等待时间,如长时间未能完成启动,请 提交工单。
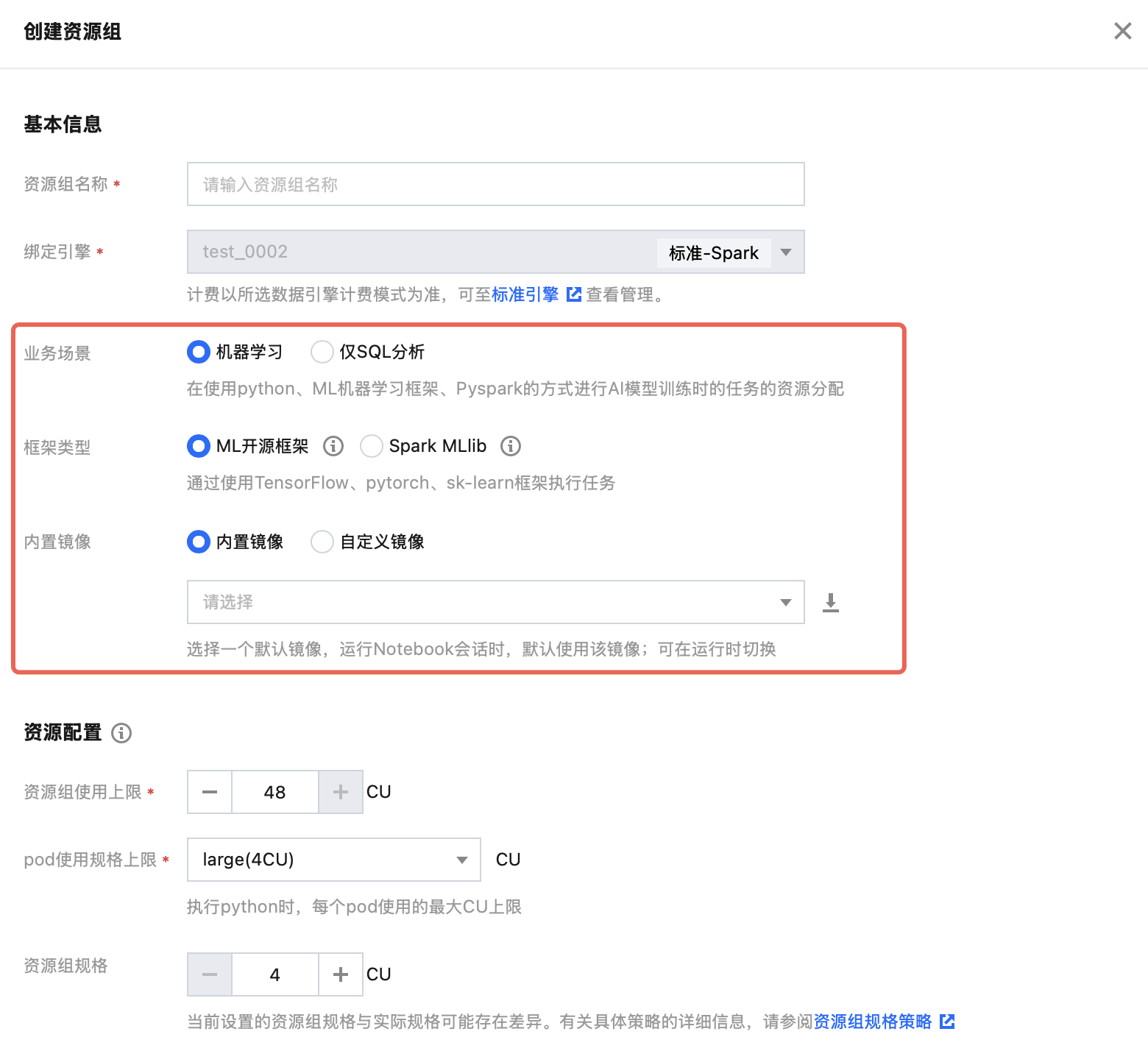
创建机器学习资源组
注意:
资源组创建完成后,不支持编辑更改,可通过删除重新创建的方式进行管理。
1. 单击管理资源组。

2. 进入资源组页面后,单击左上角创建资源组按钮。
3. 创建机器学习资源组类型。
说明:
数据湖计算 DLC AI 资源组目前支持通过:Scikit-learn(1.6.0)、TensorFlow(2.18.0)、PyTorch(2.5.1)、Spark MLlib(3.5)框架执行机器学习。
业务场景选择:机器学习。
框架类型:您可根据实际业务场景,选择适合的框架创建。
如果您需要体验我们提供的demo,请选择ML开源框架,镜像包请选择:scikit-learn-v1.6.0。
资源配置:可按需选择。
配置完成后,单击确认返回资源组列表页。数分钟后,可单击列表页上方刷新按钮进行确认。
上传机器学习数据集至 COS
如果您需要通过数据湖计算 DLC 与 Wedata 的方式进行机器学习,目前仅支持数据上云的方式进行交互。我们推荐您使用对象存储进行组合使用。
说明:
目前暂支持通过 spark 直接读取 cos 数据。
如果有其他框架诉求,目前绕行方案:先把数据上传至COS > 下载至本地生成本地文件,再进行学习操作。该绕行方案,可能会出现上传及下载时间较长的情况出现。
该功能优化我们正在开发支持中。
2. 登录 对象存储,选择存储桶,上传该数据集。
3. 上传完成后,进入元数据管理,单击创建数据目录,或使用已有数据目录上传外表。
4. 进入 DLC 控制台 > 数据管理,单击数据库 tab 页。
5. 单击创建数据库,命名为:database_testnotebook。
6. 进入创建好的数据库,单击创建外表。
注意:
请留意您上传外表的数据库表名称,在 Notebook 上会通过 select 调用库、表名称。
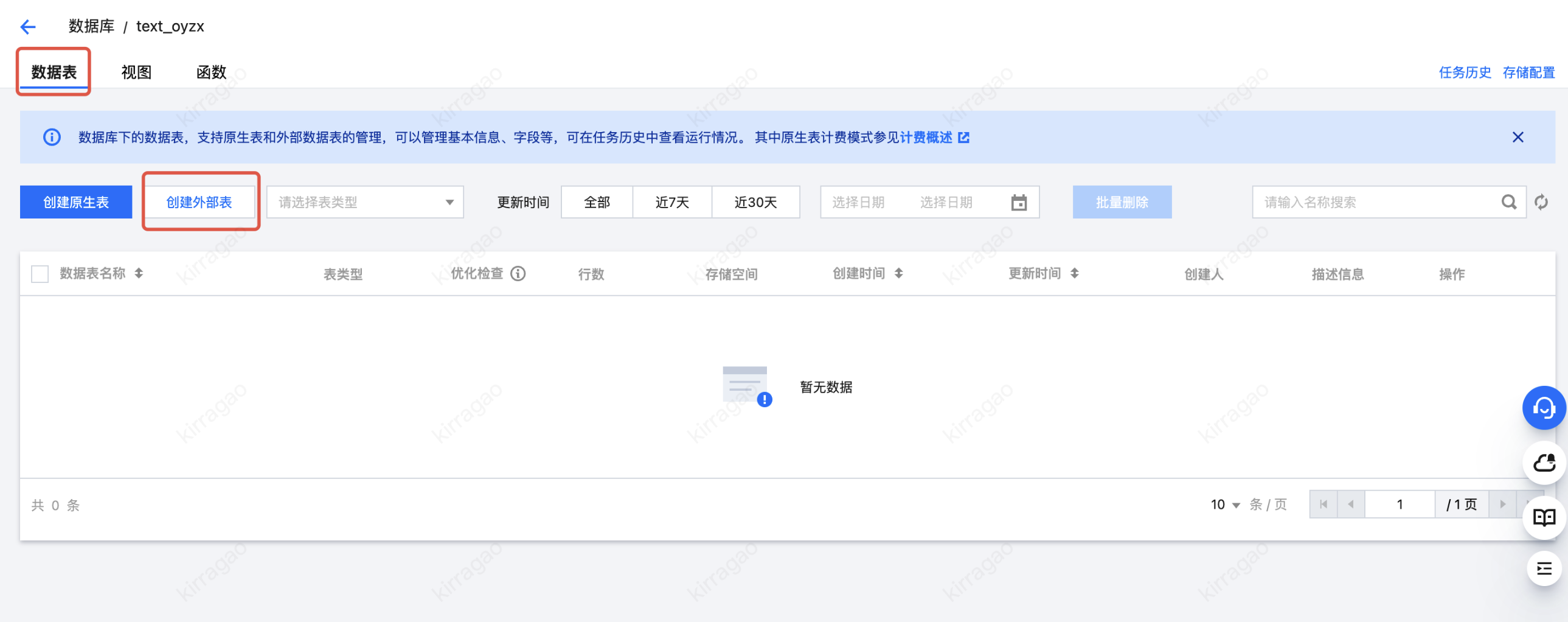
7. 选择 cos 存储桶路径,找到 demo 数据集。
8. 数据格式选择为 csv,并进行相关配置。
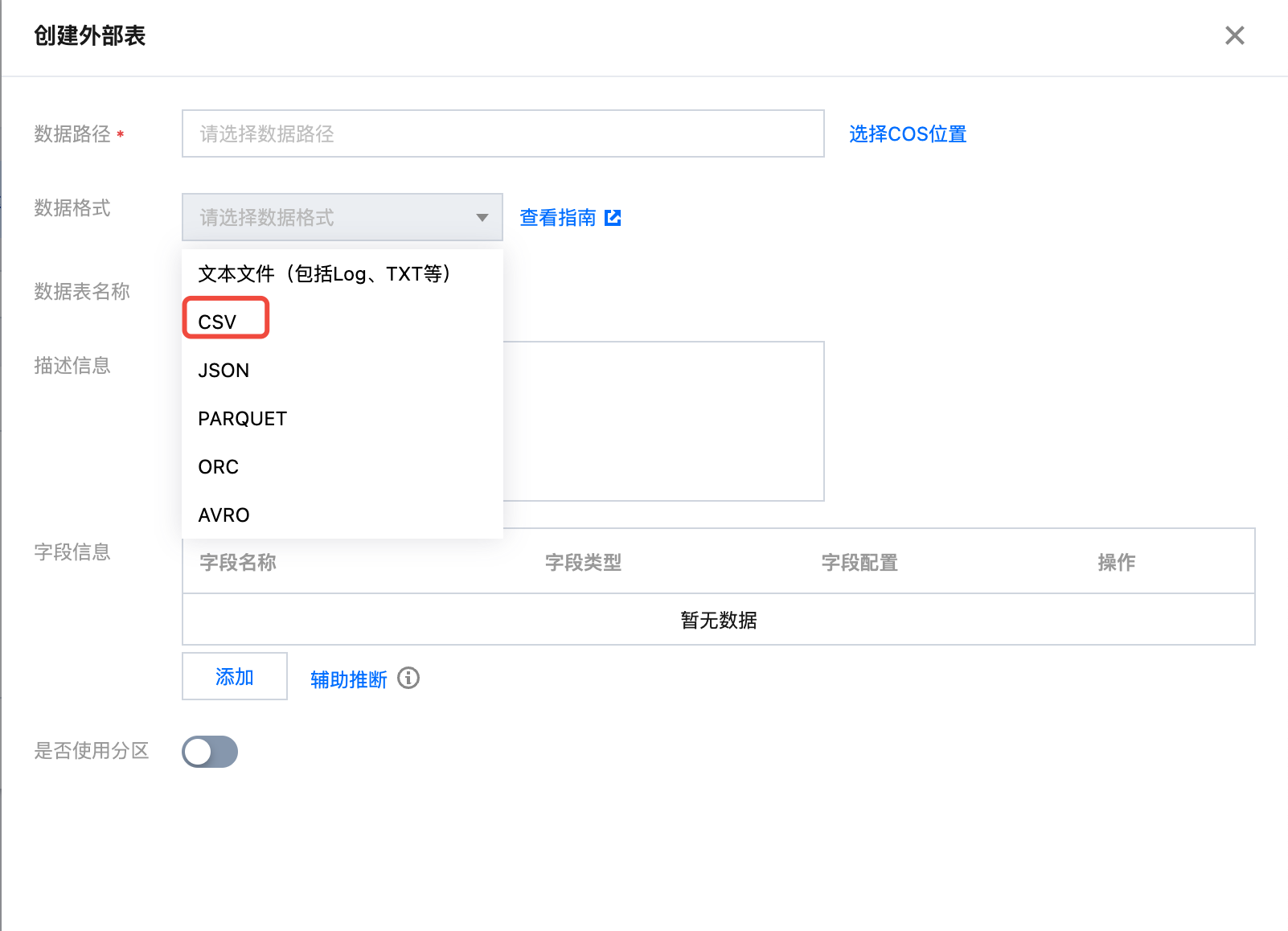
9. 创建表名称为:demo_test_sklearn。
10. 创建完成后,单击确认返回。
CREATE TABLE database_testnotebook.demo_test_sklearn (at STRING COMMENT 'from deserializer',v STRING COMMENT 'from deserializer',ap STRING COMMENT 'from deserializer',rh STRING COMMENT 'from deserializer',pe STRING COMMENT 'from deserializer')USING csvLOCATION 'cosn://your cos location'
前往 Wedata-Notebook 功能进行 demo 实践
资源组与 demo 数据集创建完成后,前往 Wedata 通过 Notebook 和 MLFlow 进行模型训练实践。
创建 WeData 项目并关联 DLC 引擎
1. 创建项目或选择已有的项目,详情请参见 项目列表。
2. 在配置存算引擎中选择所需的 DLC 引擎。
购买执行资源组并关联项目
操作步骤:
1. 进入“执行资源组 > 调度资源组 > 标准调度资源组”,单击创建。
2. 资源组配置。
地域:调度资源组所在地域需要与存算引擎所在地域保持一致,例如购买了国际站-新加坡地域的DLC引擎,则需要购买相同地域的调度资源组。
VPC 和子网:建议直接选择1.1中的 VPC 和子网,如选择其他 VPC 和子网,需要确保所选 VPC 和子网与1.1中的 VPC 和子网之间网络互通。
规格:按照任务量进行选择。
3. 创建完成后,在资源组列表的操作栏单击“关联项目”,将该调度资源组与所需使用的项目进行关联。
创建 Notebook 工作空间
1. 在项目中,选择数据治理功能,单击 Notebook 功能,并创建或使用已有工作空间。
2. 创建工作空间时,请选择购买标准 spark 引擎,standard1.1版本的引擎,勾选机器学习选项以及 MFlow 服务。
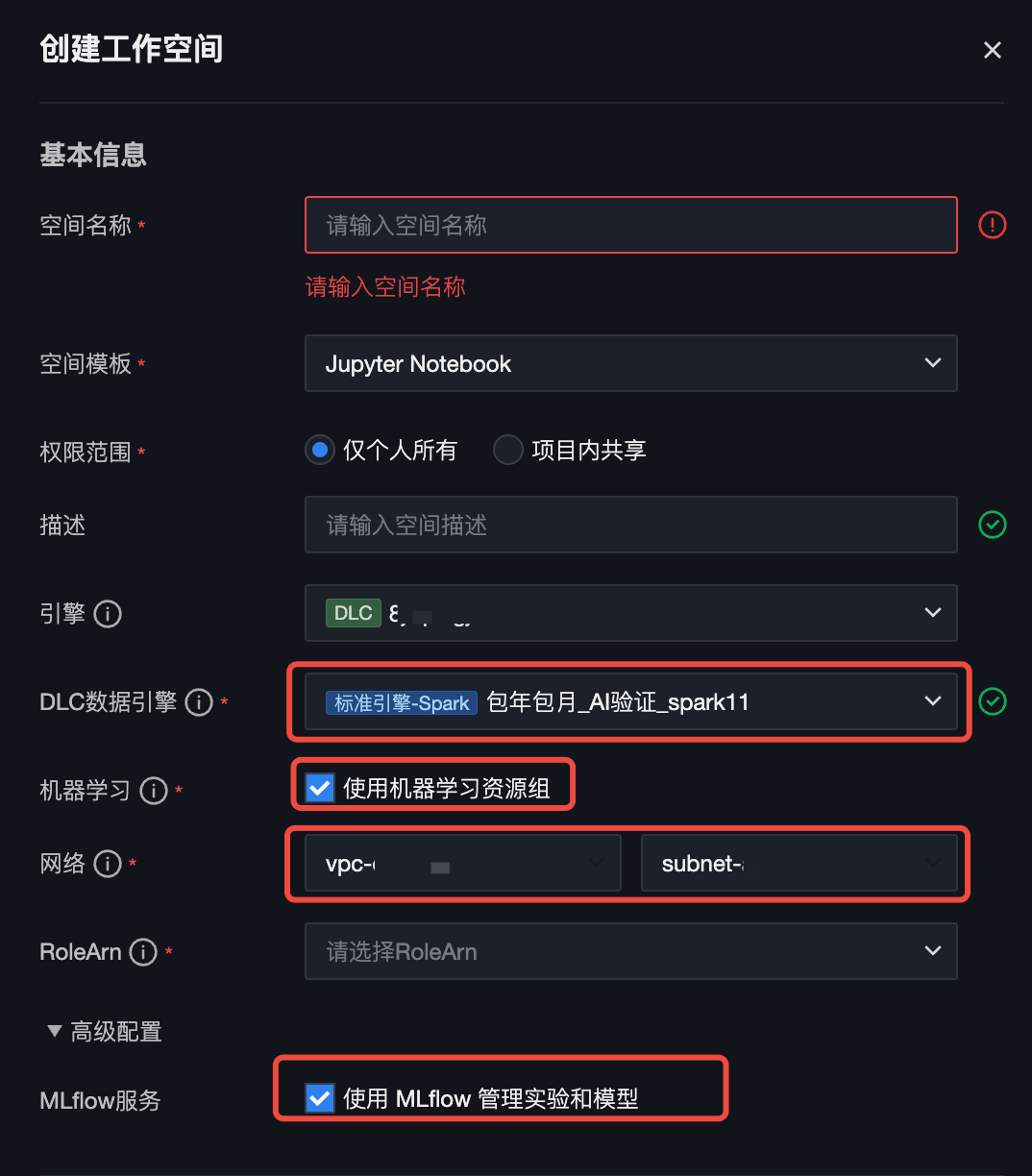
基本信息 | 属性项名称 | 属性项配置 |
引擎 | 选择一个您需要使用 Notebook 任务访问的 DLC 引擎。 当前项目项目管理中中绑定的 DLC 引擎。 | |
DLC 数据引擎 | 选择一个您需要使用 Notebook 任务访问的 DLC 数据引擎。 | |
机器学习 | 如果您选择的 DLC 数据引擎中含有“机器学习”类型的资源组,则会出现该选项,并默认选中。 | |
网络 | 建议直接选择1.1中的 VPC 和子网,如选择其他 VPC 和子网,需要确保所选 VPC 和子网与1.1中的 VPC 和子网之间网络互通。 | |
RoleArn | ||
高级配置 | MFlow 服务 | 使用 MFlow 管理实验和模型,默认为不勾选。 勾选后,则在 Notebook 任务中使用MFlow函数创建实验和机器学习,均会上报到1.1中部署的 MFlow 服务中,后续可以在机器学习 > 实验管理、模型管理中进行查看。 |
创建 Notebook 文件
在左侧资源管理器可以创建文件夹和Notebook文件,注意:Notebook文件需要以(.ipynb)结尾。在资源管理器中,预先内置了三个大数据系列教程,支持用户开箱即用。
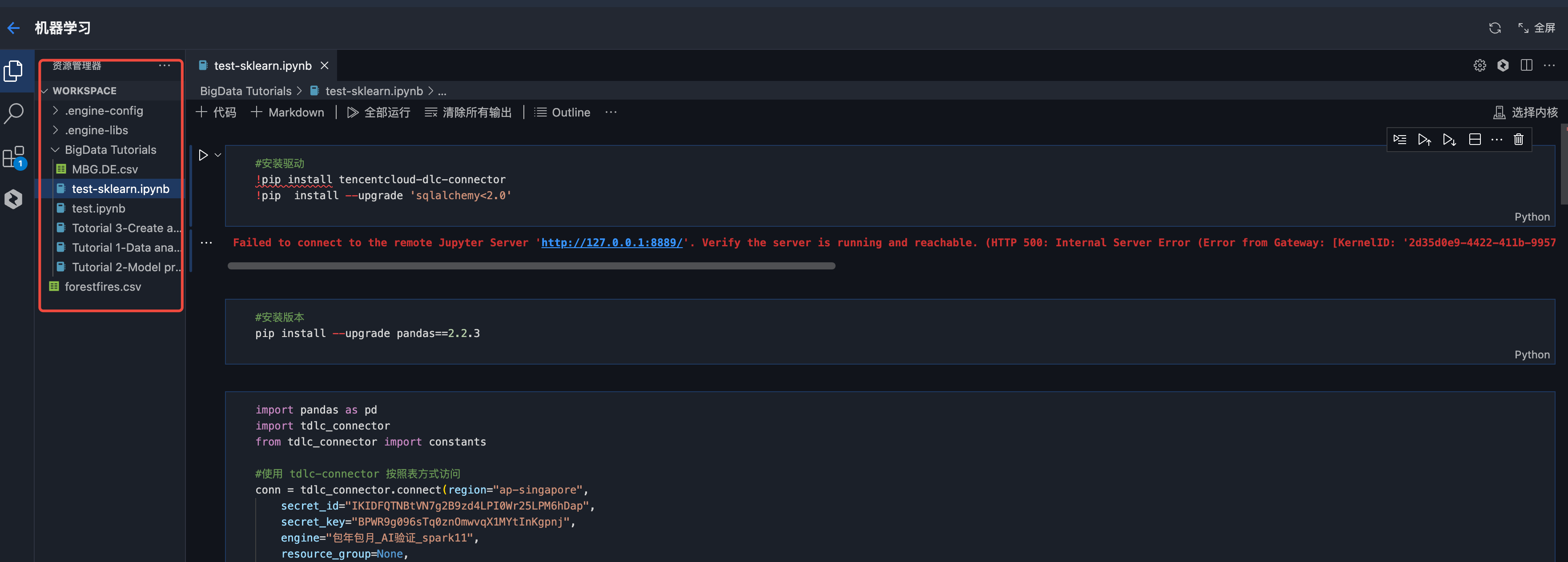
选择内核(kernel)
1. 单击选择内核。

2. 在弹出的下拉选项中选择“DLC 资源组”。
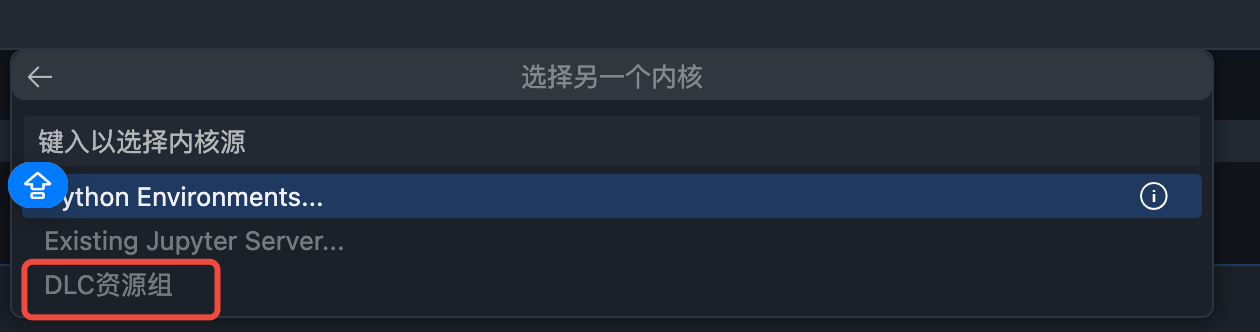
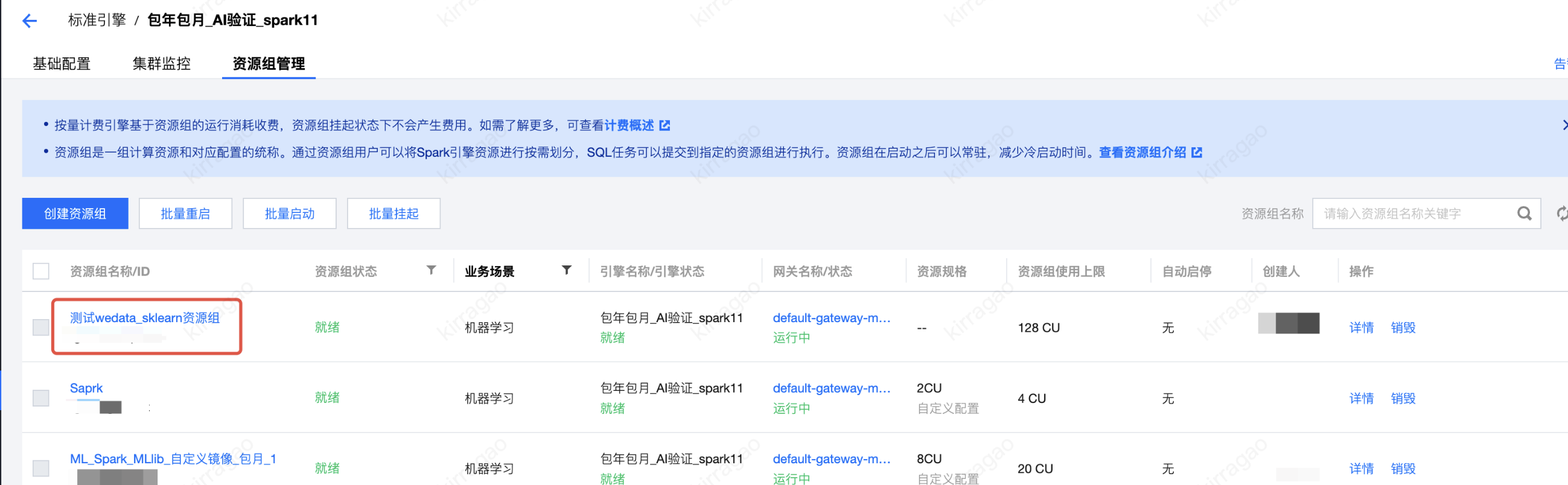
3. 在下一级选项中选择 DLC 数据引擎中的您创建的 Scikit-learn 资源组。

例如,上图选择的名为“machine learning -(测试 wedata_sklearn 资源组)”的资源组,与 DLC 数据引擎中的资源组名称一致:
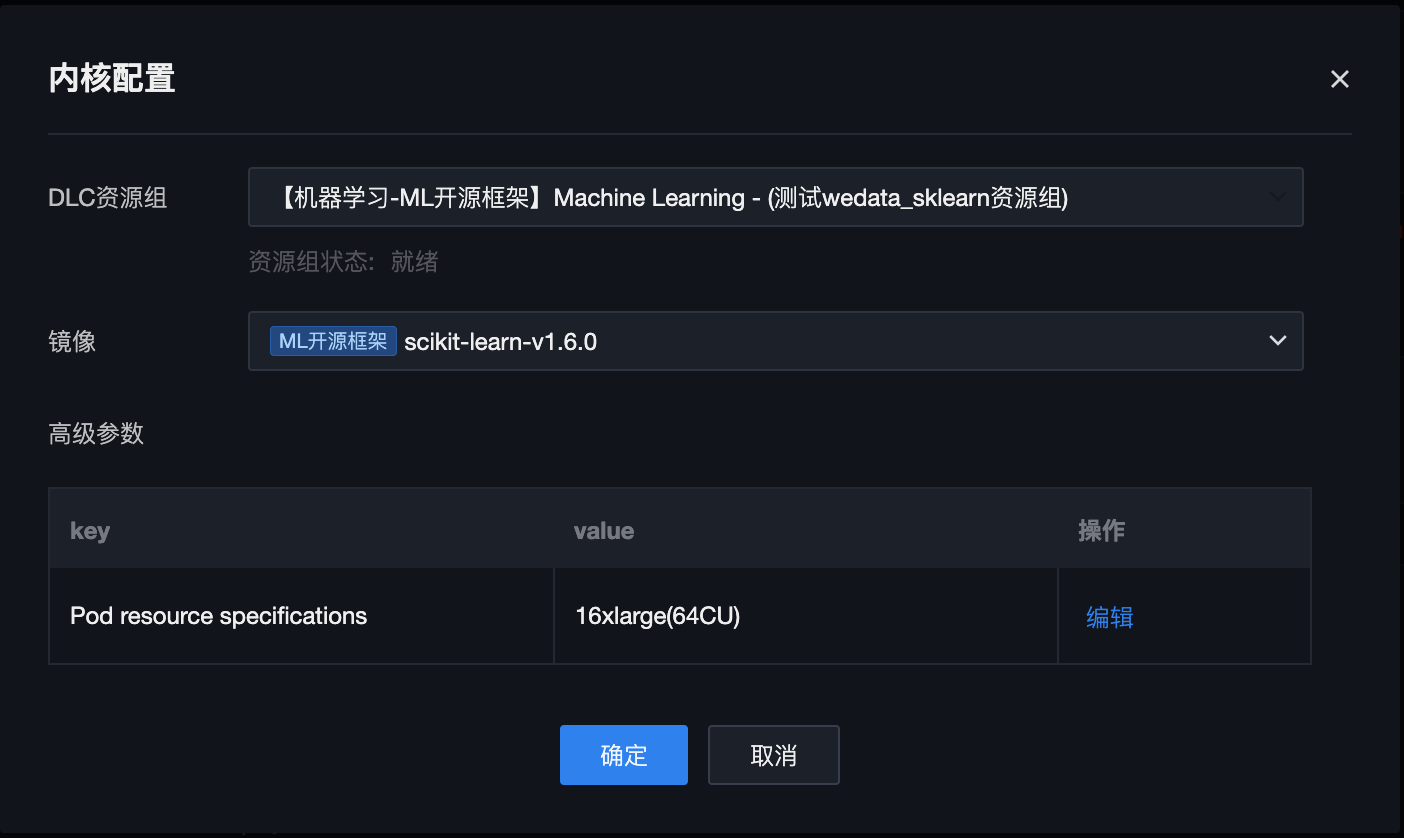
运行 Notebook 文件
1. 确认初始化配置。
2. 执行实践教程:利用公开数据鸢尾花集进行演示,采用逻辑回归模型对不同类型的花分类,并对分类结果可视化。
注意:
在运行模型前,需安装必要的tencentcloud-dlc-connector,并完成相应配置。
#安装驱动!pip install tencentcloud-dlc-connector!pip install --upgrade 'sqlalchemy<2.0'#安装版本!pip install --upgrade pandas==2.2.3!pip install numpy!pip install matplotlibimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom matplotlib.colors import ListedColormapimport tdlc_connectorfrom tdlc_connector import constantsimport mlflowmlflow.sklearn.autolog()#使用 tdlc-connector 按照表方式访问conn = tdlc_connector.connect(region="ap-***", #填入正确地址,如ap-Singapore,ap-Shanghaisecret_id="*******",secret_key="*******",engine="your engine",#填入购买的引擎名称resource_group=None,engine_type=constants.EngineType.AUTO,result_style=constants.ResultStyles.LIST,download=True)query = """SELECT `sepal.length`, `sepal.width`,`petal.length`,`petal.width`,species FROM at_database_testnotebook.demo_test_sklearn"""#读取数据iris = pd.read_sql(query, conn)iris.head()#划分数据集X = iris[['petal.length', 'petal.width']].valuescategory_map = {'setosa': 0,'versicolor': 1,'virginica': 2}y= iris['species'].replace(category_map)from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)print('Labels count in y:', np.bincount(y))print('Labels count in y_train:', np.bincount(y_train))print('Labels count in y_test:', np.bincount(y_test))#数据归一化from sklearn.preprocessing import StandardScalersc = StandardScaler()sc.fit(X_train)X_train_std = sc.transform(X_train)X_test_std = sc.transform(X_test)X_combined_std = np.vstack((X_train_std, X_test_std))y_combined = np.hstack((y_train, y_test))#逻辑回归进行分类,可视化分类结果from sklearn.linear_model import LogisticRegressionlr = LogisticRegression(C=100.0, random_state=1, solver='lbfgs', multi_class='ovr')lr.fit(X_train_std, y_train)plot_decision_regions(X_combined_std, y_combined,classifier=lr, test_idx=range(105, 150))plt.xlabel('petal length [standardized]')plt.ylabel('petal width [standardized]')plt.legend(loc='upper left')plt.tight_layout()plt.show()#查看模型准确率y_pred = lr.predict(X_test_std)print(accuracy_score(y_test, y_pred))
前往 MFlow 查看训练结果与注册模型
1. 选择机器学习功能。
2. 查看实验记录,并选择最优训练结果注册为模型。