本文档介绍 DLC 中依赖包管理的三层级模型与操作方法,帮助您在标准引擎、资源组/作业、Notebook 场景下高效、可控地配置依赖环境。
核心概念
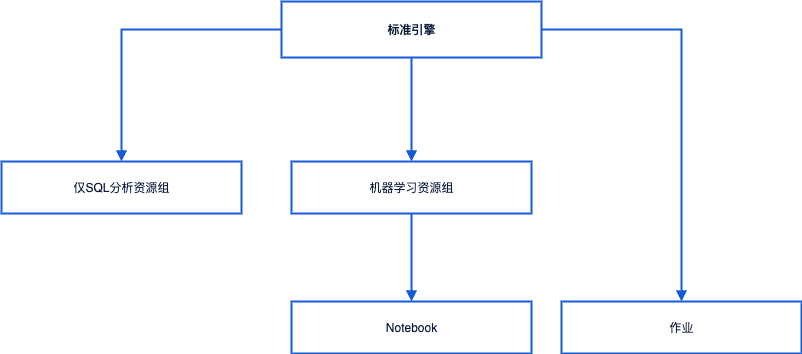
层级模型
为保证依赖环境的一致性与可控性,在“标准引擎”层级之上,DLC 维护一套由引擎内核与标准镜像预置的受保护依赖集合,称为引擎内核基线依赖(下称“基线依赖”)。该集合是所有依赖解析与合并的起点。不同镜像的基线依赖详情可查看运行环境。
引擎内核基线依赖(基线依赖)
描述:随引擎内核版本与标准镜像交付的预置依赖清单。
特性:不可卸载;不可通过 PyPI 直接覆盖。版本调整需在引擎级通过 requirements.txt 实施受控“版本钉死/重写”。
作用:作为全局基线之上限,确保平台运行时的稳定性与一致性。
标准引擎
作用:在“基线依赖”之上进行有限的依赖补充与受控重写,形成租户引擎级的全局依赖基线。
影响范围:所有资源组、作业与 Notebook 默认继承。
资源组
资源组:仅 SQL 分析资源组、机器学习资源组。
作用:团队/业务线的隔离层,承载通用但非全局的依赖配置。
Notebook与作业
作用:个性化与实验性最小增量依赖,贴近开发与调试场景。
继承与定制规则
继承关系:子级默认继承父级依赖配置。
例如:资源组默认继承标准引擎依赖。
定制化添加:任意层级均可新增依赖;新增依赖仅在该层级及其子级生效
例如:在“机器学习资源组”新增的 Python 包,仅对该资源组内的作业/Notebook 生效。
任务实例最终依赖环境 = 基线依赖 + 引擎依赖 + 资源组/作业依赖 + Notebook依赖
安装顺序
安装顺序:引擎/资源组/作业层的新增依赖按“添加时间”正序安装。
冲突规则
冲突语义对齐原生生态:
Maven(Jar):遵循 Maven 解析与冲突处理语义。
PyPI(Python):遵循 pip/PEP 规范 。
详见依赖冲突处理。
覆盖与改写
不可直接改写:引擎内置依赖不可通过 PyPI 方式改写。
可控改写:引擎级支持通过
requirements.txt 对内置依赖进行版本重写。生效时机与安装状态
生效动作:安装、卸载、克隆在计算实例启动时生效。
触发场景:
作业启动
SQL 资源组重启
机器学习资源组:
ML 开源框架与 Python 依赖:在 Wedata Notebook 探索页面点击
RestartSpark MLlib 依赖:在 Wedata Notebook 探索页面重新创建 Spark 会话。
安装状态查看:
引擎级:显示最近一次任一计算实例安装后的状态(如仅 SQL 资源组与作业A先后运行,则展示作业A对应状态)。
资源组/作业/Notebook 级:显示各自维度的安装状态。
支持点击依赖条目查看安装成功/失败详情和日志。
前提条件
注意:
购买标准引擎 Spark。
如需使用存量引擎,请 提交工单 联系售后升级引擎镜像及网关镜像至2025-09-30及以后版本。
操作指南
1. 引擎级依赖管理
导航路径:资源管理 → 标准引擎 → 选择引擎 → 依赖包管理
安装
COS / Local File
支持 Jar 和 Python 包;从 COS 桶或本地上传。
PyPI
填写包名与版本(符合 PyPI 命名);默认使用腾讯云仓库,支持外部源。
Maven
填写 Maven 坐标;默认使用腾讯云仓库,支持自定义远程仓库与排除依赖项。
卸载
选择依赖 → 单击“卸载”。卸载为异步操作,将在下一次计算实例启动时生效。
克隆
从其他引擎一键克隆依赖环境;重复依赖自动跳过。
2. 资源组级依赖管理
导航路径:资源管理 → 标准引擎 → 选择引擎 → 资源组管理 → 选择资源组 → 依赖包管理。
安装/卸载:与引擎级一致。
3. 作业级依赖管理
导航路径:数据开发与探索 → 数据作业 → 创建/编辑作业 → 依赖资源
说明:针对单个作业定制依赖,仅对该作业生效。
安装方式:与引擎级一致。
4. 任务依赖环境总览
导航路径:运维管理 → 历史任务实例 → 选择任务 → 依赖环境。
说明:展示该任务实例最终依赖集合及安装状态(覆盖引擎/资源组/作业级),用于快速排障。
依赖冲突处理
Maven(Jar)
直接依赖冲突:后安装的包安装失败。
传递依赖冲突:系统自动移除冲突传递依赖,安装成功;可查看依赖移除记录。
类冲突:安装成功但可能在运行时冲突。
未使用冲突类:任务正常运行。
使用冲突类:任务失败并在日志中显示原因。
PyPI(Python)
同级重复安装:同名或不同版本的重复安装,后安装的依赖失败。
不同级重复安装:
标准引擎/资源组/作业级别:按照添加时间顺序执行安装,后安装的依赖失败。
Notebook 级别:可以改写父级已有包的版本。
最佳实践
核心原则
最小化引擎级依赖
引擎级是租户引擎级的全局基线,影响全局。除非确认“所有场景均需要”的公共依赖,否则不建议在引擎级添加过多依赖。减少全局耦合与跨团队兼容成本。
优先用资源组做隔离与分层演进
将团队/业务线通用依赖放在资源组级,天然隔离不同团队/项目的差异化需求,避免全局污染。
作业/Notebook 级做最小补充
仅放置该作业/Notebook 独有、短期验证或小范围个性化依赖;当有多个作业复用时,上移到资源组级统一管理。
场景化建议
多团队共用同一引擎
引擎保持“企业通用底座”。
团队差异化依赖放在各自资源组,避免互相牵制。
算法团队快速试验
Notebook 阶段允许快速试装;发布前将依赖固化到资源组级。
常见问题(FAQ)
Q:Maven 传递依赖冲突如何处理?
A:系统自动移除冲突传递依赖并记录详情;请在安装日志与“移除记录”中确认影响范围。
Q:安装/卸载为何未即时生效?
A:依赖变更在计算实例启动时生效。请按“生效动作”重启资源组或重新创建作业/会话。



