DLC 分区表
用户可以将数据按照分区目录的方式进行存储,将不同特征的数据存放在不同的目录下,在进行数据探索时,通过 where 条件按照分区进行过滤,DLC 的数据扫描量将大幅减少,提高查询效率。
注意
同一个表的分区应使用相同的数据类型及格式。
DLC 原生表采用隐式分区实现,可不用关注分区目录结构。
创建分区表
创建表格语句中通过 PARTITIONED BY 指定分区字段。
示例:创建分区表 test_part
CREATE EXTERNAL TABLE IF NOT EXISTS `DataLakeCatalog`.`test_a_db`.`test_part` (`_c0` int,`_c1` int,`_c2` string,`dt` string) USING PARQUET PARTITIONED BY (dt) LOCATION 'cosn://testbucket/data/';
添加分区
通过 alter table add partition 添加分区
如果用户的数据分区目录为 Hive 的分区规则:分区列名=分区列值,可采用这种方式添加分区,目录组织方式如图。
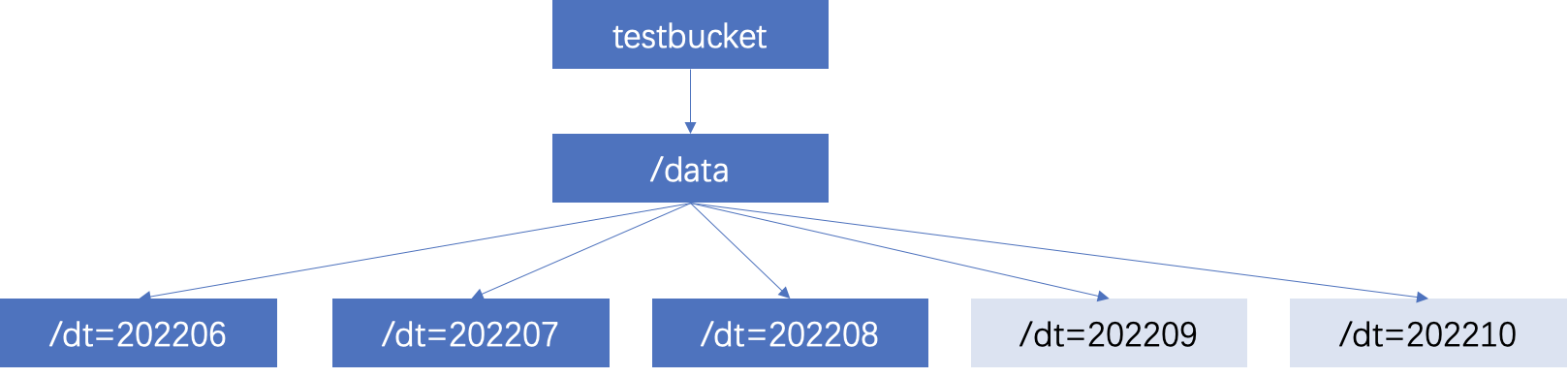
ALTER TABLE `DataLakeCatalog`.`test_a_db`.`test_part` add PARTITION (dt = '202206')ALTER TABLE `DataLakeCatalog`.`test_a_db`.`test_part` add PARTITION (dt = '202207')ALTER TABLE `DataLakeCatalog`.`test_a_db`.`test_part` add PARTITION (dt = '202208')ALTER TABLE `DataLakeCatalog`.`test_a_db`.`test_part` add PARTITION (dt = '202209')ALTER TABLE `DataLakeCatalog`.`test_a_db`.`test_part` add PARTITION (dt = '202210')
通过 alter table 指定 location 添加分区
如果用户的数据组织为普通的 cos 目录(非“分区列名=分区列值”组织方式),可以在 add partition 时指定目录。
SQL 参考:
ALTER TABLE `DataLakeCatalog`.`test_a_db`.`test_part` add PARTITION (dt = '202211') LOCATION 'cosn://testbucket/data2/202211'ALTER TABLE `DataLakeCatalog`.`test_a_db`.`test_part` add PARTITION (dt = '202212') LOCATION 'cosn://testbucket/data2/202212'
使用 MSCK REPAIR 自动添加分区
使用 MSCK REPAIR TABLE 语句,扫描在建表时指定的数据目录。若存在新的分区目录,则系统会自动将这些分区添加到数据表的元数据信息中。
SQL参考:
MSCK REPAIR TABLE `DataLakeCatalog`.`test_a_db`.`test_part`
建议优先选择 alter table 的方式添加分区,如果采用 msck repair 自动添加分区,有如下约束条件:
MSCK REPAIR TABLE 仅向数据表元数据添加分区,不会删除分区。
数据量较大时,不推荐使用 MSCK REPAIR TABLE 的方式,该方式会扫描全部数据量,可能会导致超时。
如果分区目录不为 Hive 的分区规则:分区列名=分区列值,不能采用 MSCK REPAIR TABLE 方式。



