应用场景
DLC 完全兼容开源 Apache Spark,支持用户编写业务程序在 DLC 平台上对数据进行读写和分析。本示例演示通过编写 Java 代码在 COS 上读写数据和在 DLC 上建库表、读写表的详细操作,帮助用户在 DLC 上完成作业开发。
环境准备
依赖: JDK1.8 Maven IntelliJ IDEA
开发流程
开发流程图
DLC Spark JAR 作业开发流程图如下:

创建资源
第一次在 DLC 上运行作业,需新建 Spark 作业计算资源,例如新建名称为 "dlc-demo" 的 Spark 作业资源。
1. 登录 数据湖计算 DLC 控制台,选择服务所在区域,在导航菜单中单击数据引擎。
2. 单击左上角创建资源,进入资源配置购买页面。
3. 在集群配置 > 计算引擎类型项选择 Spark 作业引擎。
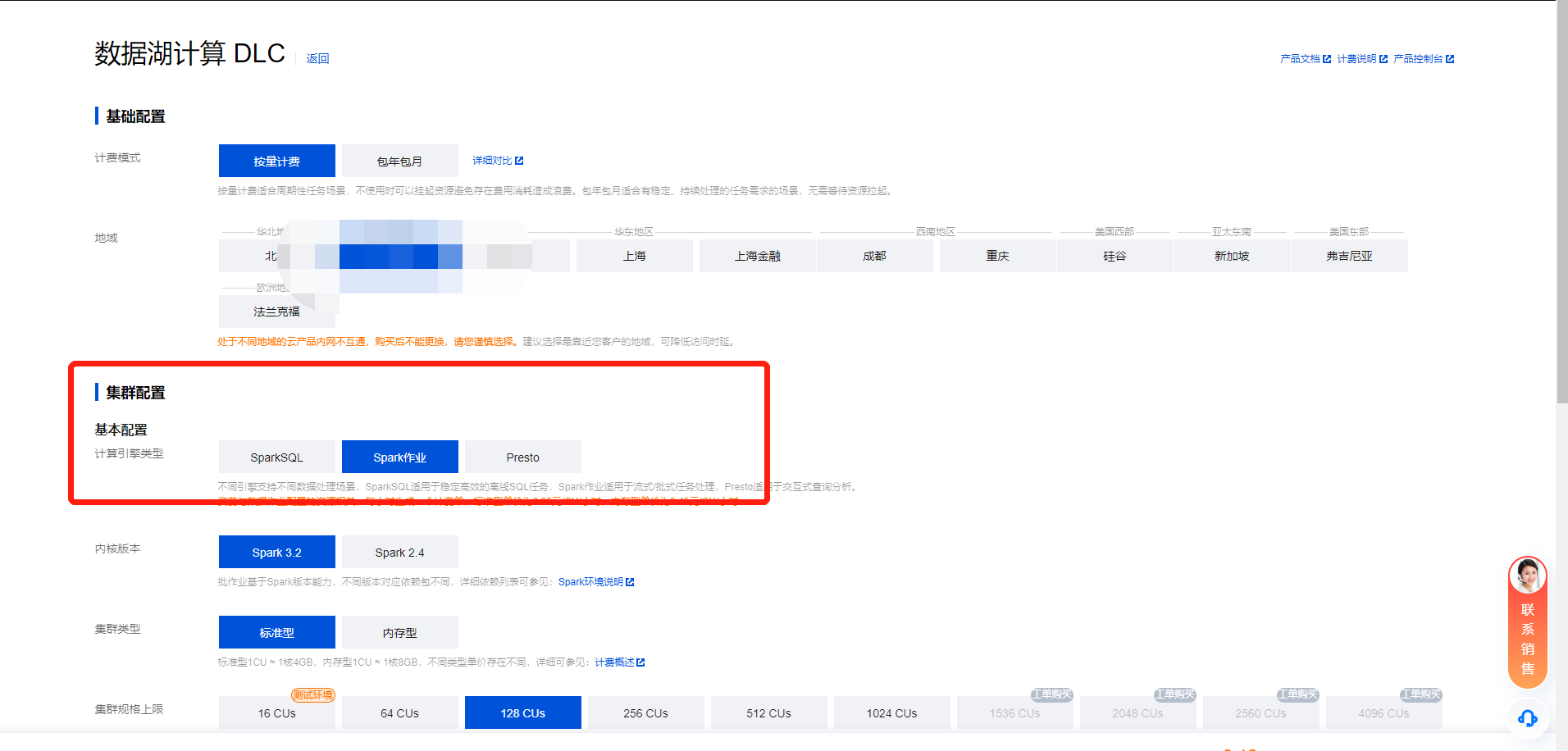
4. 单击立即开通,确认资源配置信息。
5. 确认信息无误后,单击提交,完成资源配置。
上传数据到 COS
创建名称为 “dlc-demo”的存储桶,上传 people.json 文件,用作从 COS 读写数据的示例,people.json 文件的内容如下:
{"name":"Michael"}{"name":"Andy", "age":30}{"name":"Justin", "age":3}{"name":"WangHua", "age":19}{"name":"ZhangSan", "age":10}{"name":"LiSi", "age":33}{"name":"ZhaoWu", "age":37}{"name":"MengXiao", "age":68}{"name":"KaiDa", "age":89}
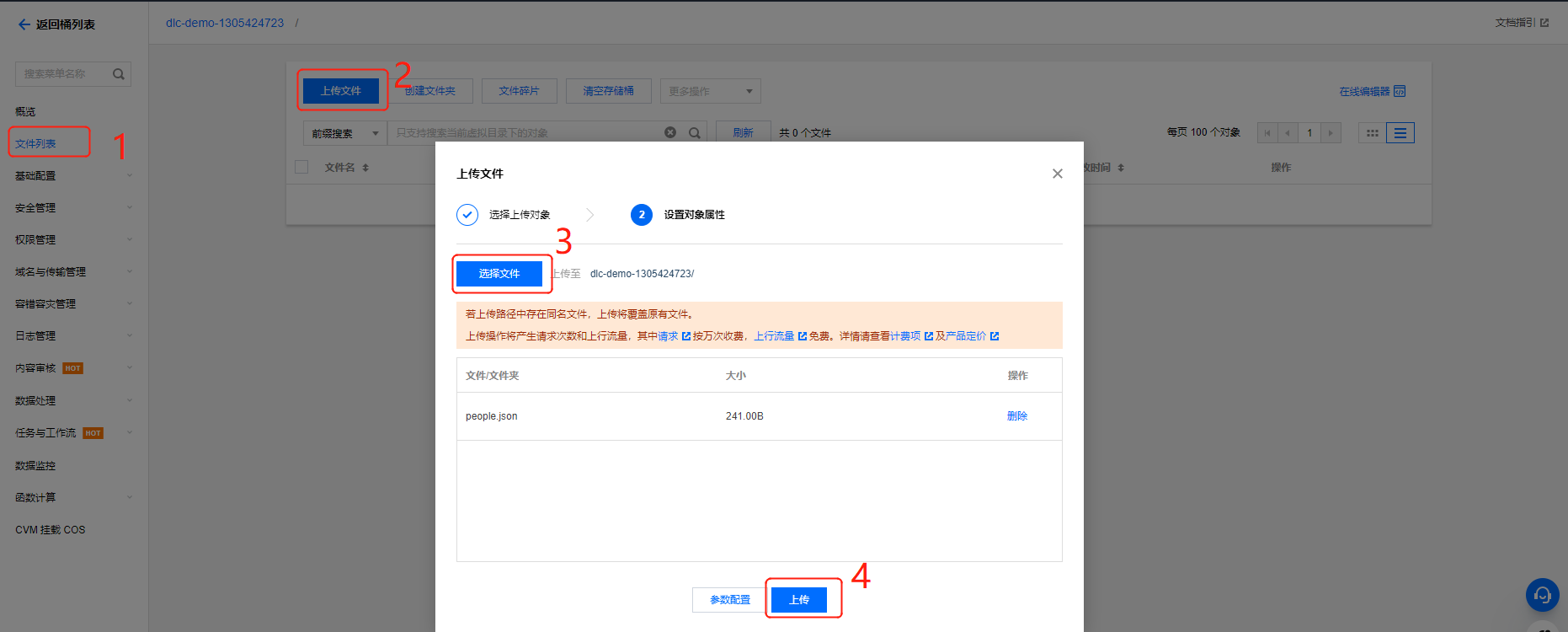
1. 登录 对象存储 COS 控制台,在左侧菜单导航中单击 存储桶列表。
2. 创建存储桶:单击左上角创建存储桶,名称项填写 “dlc-dmo”,单击下一步完成配置。
3. 上传文件:单击文件列表 > 上传文件,选择本地“people.json”文件上传到“dlc-demo-1305424723”桶里(-1305424723是建桶时平台生成的随机串),单击上传,完成文件上传。新建存储桶详情可参见创建存储桶。
新建 Maven 项目
1. 通过 IntelliJ IDEA 新建一个名称为“demo”的 Maven 项目。
2. 添加依赖:在 pom.xml 中添加如下依赖:
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.2.1</version><scope>provided</scope></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.2.1</version><scope>provided</scope></dependency>
编写代码
编写代码功能为从 COS 上读写数据和在 DLC 上建库、建表、查询数据和写入数据。
1. 从 COS 上读写数据代码示例:
package com.tencent.dlc;import org.apache.spark.sql.Dataset;import org.apache.spark.sql.Row;import org.apache.spark.sql.SaveMode;import org.apache.spark.sql.SparkSession;public class CosService {public static void main( String[] args ){//1.创建SparkSessionSparkSession spark = SparkSession.builder().appName("Operate data on cos").config("spark.some.config.option", "some-value").getOrCreate();//2.读取cos上的json文件生成数据集,支持多种类型的文件,如 json,csv,parquet,orc,textString readPath = "cosn://dlc-demo-1305424723/people.json";Dataset<Row> readData = spark.read().json(readPath);//3.对数据集做业务计算操作生成结果数据,计算支持API和SQL形式,这里生成临时表用sql读数据readData.createOrReplaceTempView("people");Dataset<Row> result = spark.sql("SELECT * FROM people where age > 3");//4.结果数据保存到cosString writePath = "cosn://dlc-demo-1305424723/people_output";//写入支持多种类型的文件,如 json,csv,parquet,orc,textresult.write().mode(SaveMode.Append).json(writePath);spark.read().json(writePath).show();//5.关闭sessionspark.stop();}}
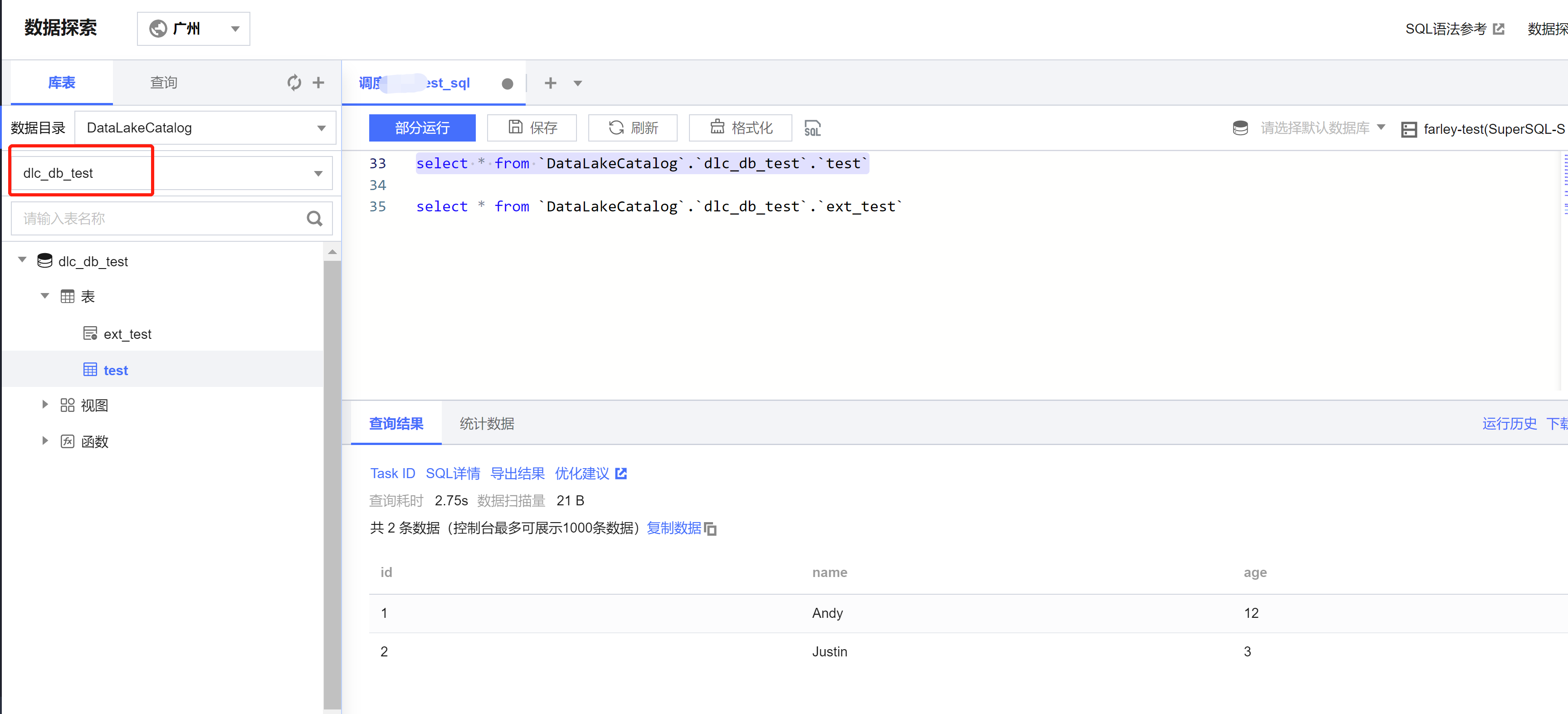
2. DLC 上建库、建表、查询数据和写入数据:
package com.tencent.dlc;import org.apache.spark.sql.SparkSession;public class DbService {public static void main(String[] args) {//1.初始化SparkSessionSparkSession spark = SparkSession.builder().appName("Operate DB Example").getOrCreate();//2.建数据库String dbName = " `DataLakeCatalog`.`dlc_db_test` ";String dbSql = "CREATE DATABASE IF NOT EXISTS" + dbName + " COMMENT 'demo test'";spark.sql(dbSql);//3.建内表String tableName = "`test`";String tableSql = "CREATE TABLE IF NOT EXISTS " + dbName + "." + tableName+ "(`id` int,`name` string, `age` int)";spark.sql(tableSql);//4.写数据spark.sql("INSERT INTO " + dbName + "." + tableName + "VALUES (1,'Andy',12),(2,'Justin',3) ");//5.查询数据spark.sql(" SELECT * FROM " + dbName + "." + tableName).show();//6.建外表String extTableName = "`ext_test`";spark.sql("CREATE EXTERNAL TABLE IF NOT EXISTS " + dbName + "." + extTableName + ""+ " (`id` int, `name` string, `age` int) "+ "ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' "+ "STORED AS TEXTFILE LOCATION 'cosn://dlc-demo-1305424723/ext_test '");//7.写外表数据spark.sql("INSERT INTO " + dbName + "." + extTableName + "VALUES (1,'LiLy',12),(2,'Lucy',3) ");//8.查询外表数据spark.sql(" SELECT * FROM " + dbName + "." + extTableName).show();//9.关闭Sessionspark.stop();}}
建外表时,需按照 上传数据到COS的步骤 先在桶里建对应表名文件夹保存表文件
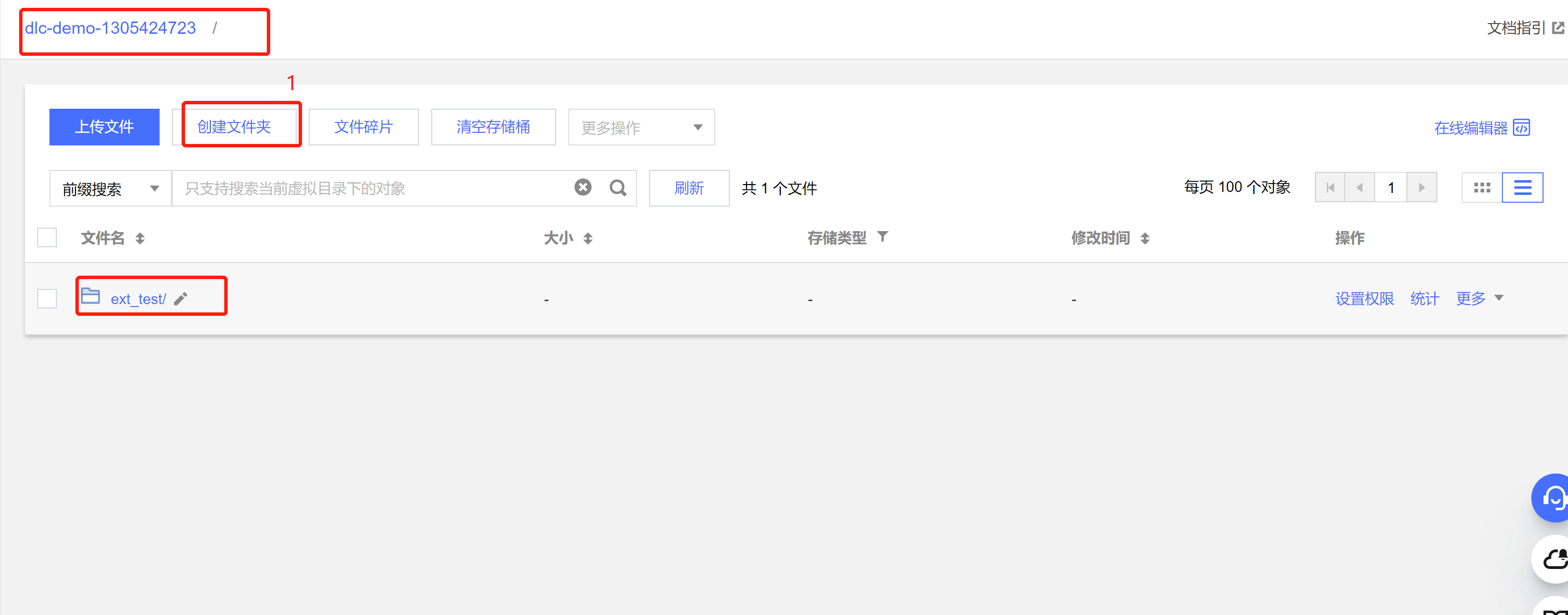
调试、编译代码并打成 JAR 包
通过 IntelliJ IDEA 对 demo 项目编译打包,在项目 target 文件夹下生成JAR包 demo-1.0-SNAPSHOT.jar。
上传 JAR 包到 COS
新建 Spark Jar 数据作业
创建数据作业前,您需先完成数据访问策略配置,保证数据作业能安全地访问到数据。配置数据访问策略详情请参见 配置数据访问策略。如已配置数据策略名称为:qcs::cam::uin/100018379117:roleName/dlc-demo。
1. 登录 数据湖计算 DLC 控制台,选择服务所在区域,在导航菜单中单击数据作业。
2. 单击左上角创建作业,进入创建页面。
3. 在作业配置页面,配置作业运行参数,具体说明如下:
配置参数 | 说明 |
作业名称 | 自定义 Spark Jar 作业名称,例如:cosn-demo |
作业类型 | 选择 批处理类型 |
数据引擎 | 选择 创建资源 步骤创建的 dlc-demo 计算引擎 |
程序包 | 选择 COS,在 上传 JAR 包到 COS 步骤上传的 JAR 包 demo-1.0-SNAPSHOT.jar |
主类(Main Class) | 根据程序代码填写,如: 从 COS 上读写数据填: com.tencent.dlc.CosService 在 DLC 上建库、建表等填:com.tencent.dlc.DbService |
数据访问策略 | 选择该步骤前创建的策略 qcs::cam::uin/100018379117:roleName/dlc-demo |
其他参数值保持默认。
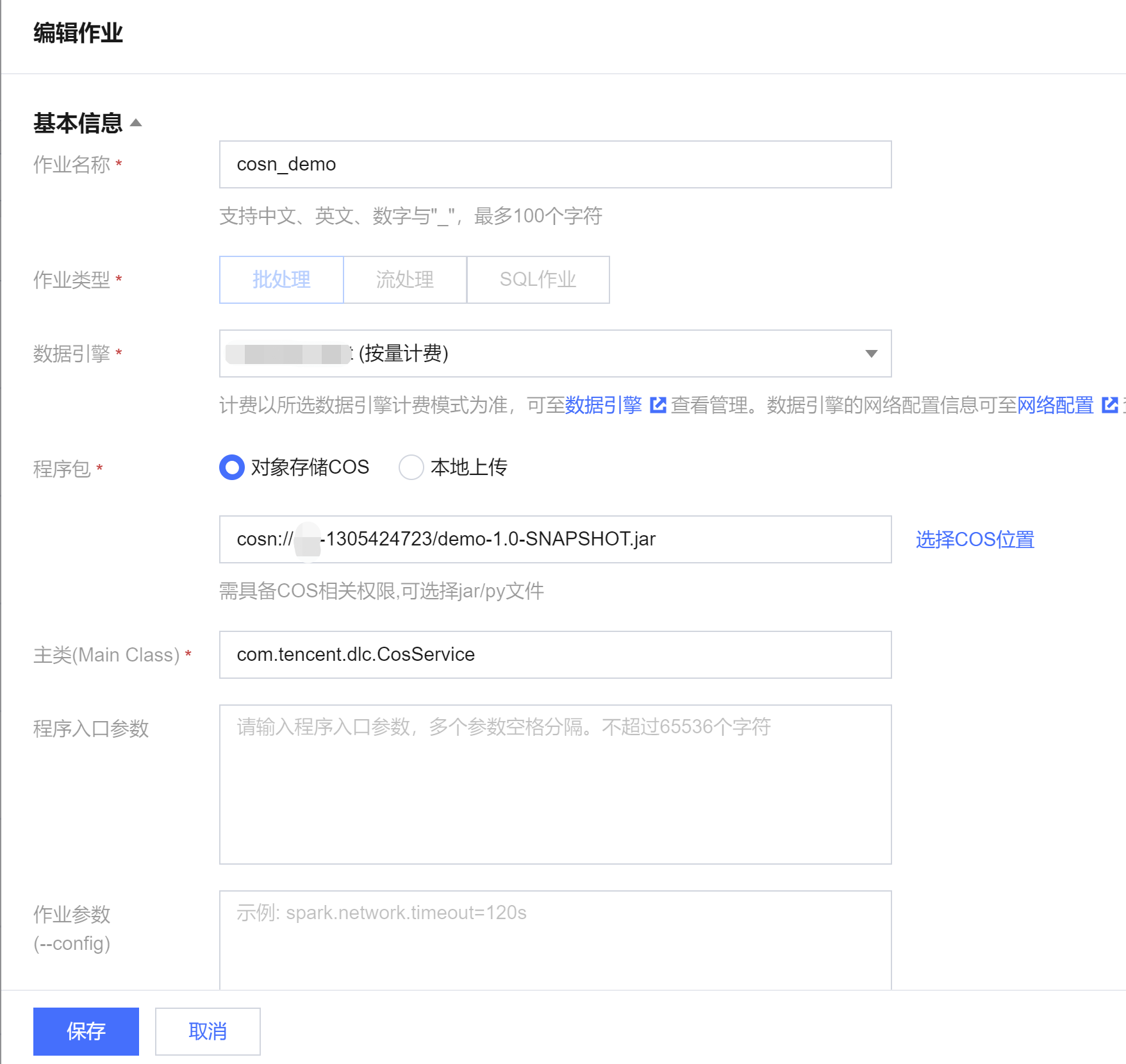
4. 单击保存,在Spark 作业页面可以看到创建的作业。
运行并查看作业结果
1. 运行作业:在Spark 作业页面,找到新建的作业,单击运行,即可运行作业。
2. 查看作业运行结果: 可查看作业运行日志和运行结果。
查看作业运行日志
1. 单击作业名称 > 历史任务,查看任务运行状态。
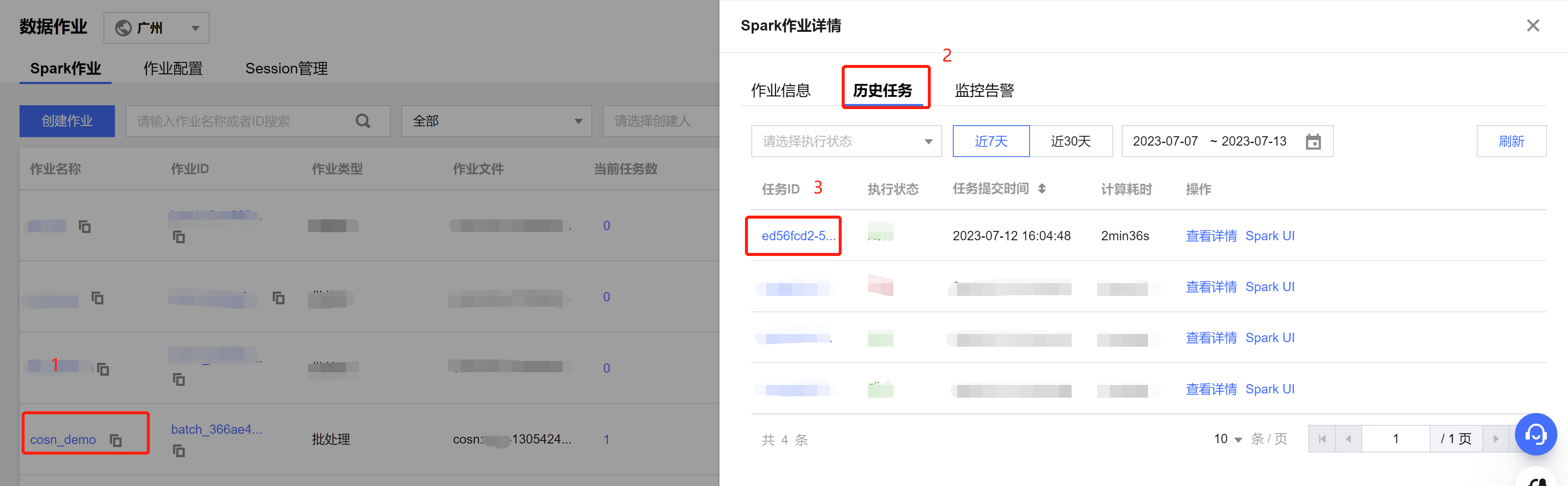
2. 单击任务ID > 运行日志,查看作业运行日志:
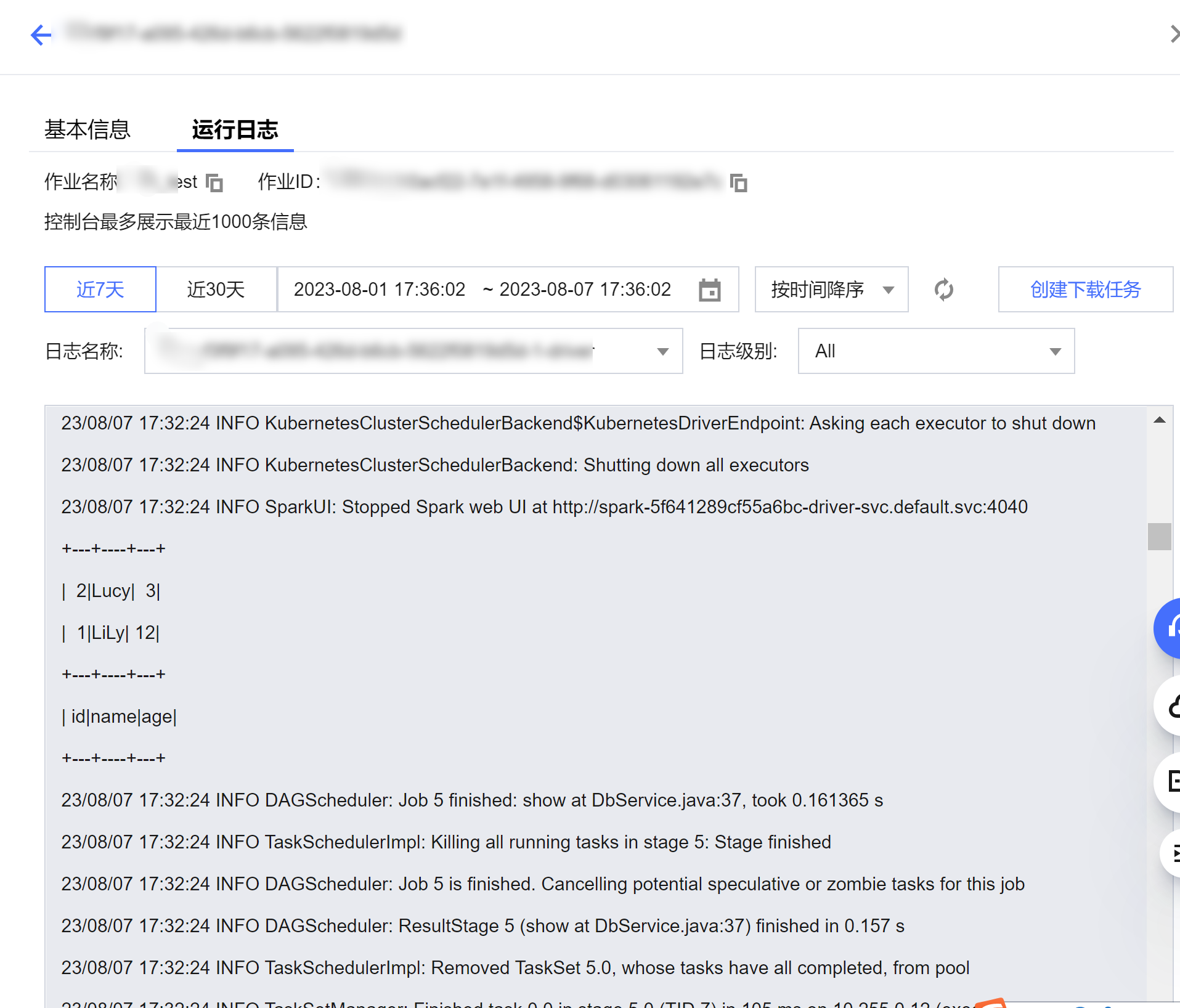
查看作业运行结果
1. 运行从 COS 读写数据示例,则到 COS 控制台查看数据写入结果。
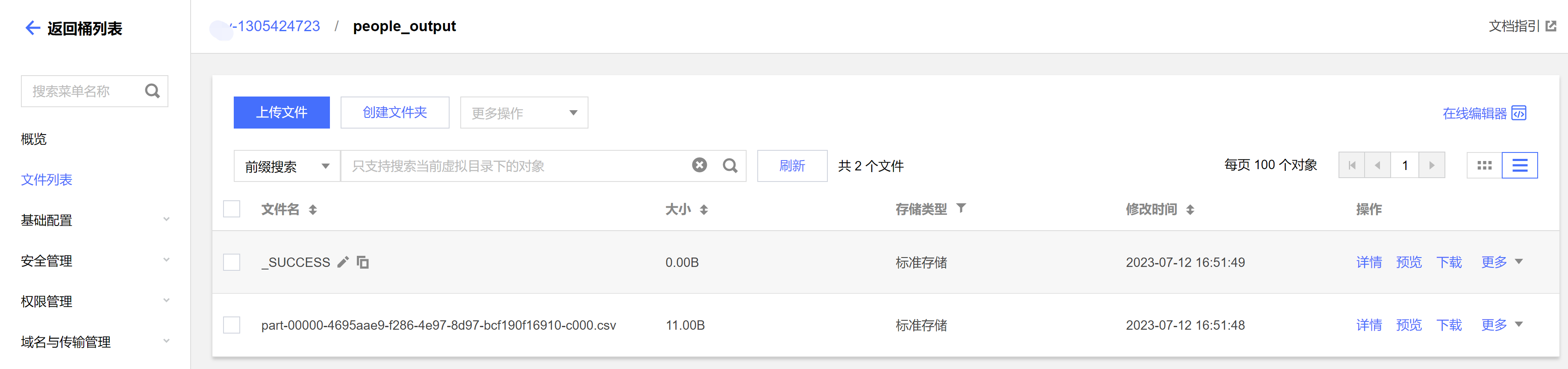
2. 运行在 DLC 上建表、建库,则到 DLC 数据探索页面查看建库、建表。