操作场景
北极星对运行的实例、接口提供了多项监控指标,用以监测北极星节点及服务的运行情况,例如:CPU、内存、网络等系统指标。您可以根据这些指标实时了解北极星实例的运行状况,针对可能存在的风险及时处理,保障系统的稳定运行。本文为您介绍通过 TSF 控制台查看北极星监控数据的操作方法。
监控指标及含义
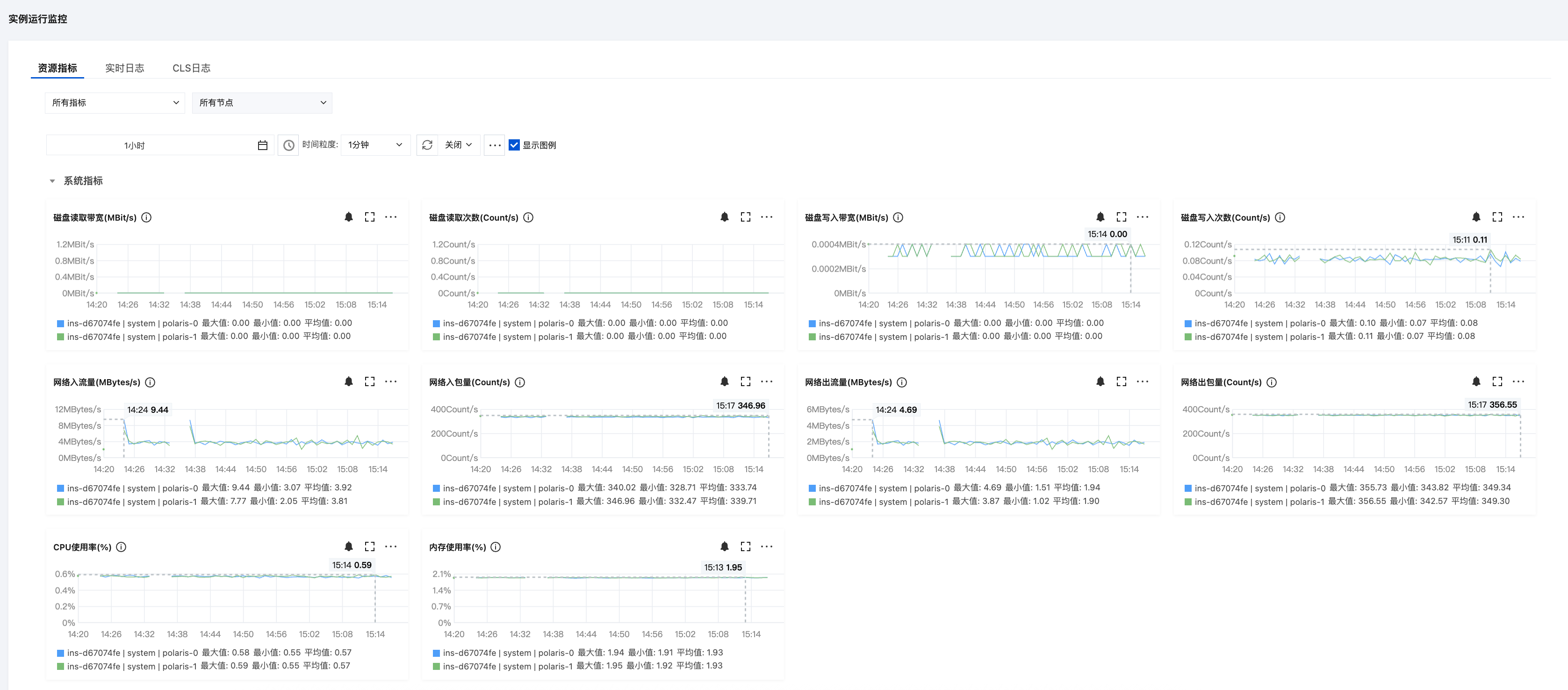
资源指标
指标分类 | 指标名 | 指标含义 | 指标单位 |
CPU | CPU使用率 | 服务端进程占用的CPU资源百分比 | % |
内存 | 内存使用率 | 服务端进程占用的内存资源百分比 | % |
网络 | 网络入包量 | 服务端每秒接收的网络数据包数量 | 个/s |
| 网络出包量 | 服务端每秒发送的网络数据包数量 | 个/s |
| 网络入流量 | 服务端每秒接收的数据量 | MBytes/s |
| 网络出流量 | 服务端每秒发送的数据量 | MBytes/s |
磁盘 | 磁盘读取次数 | 服务端每秒从磁盘读取的操作次数 | 次 |
| 磁盘写入次数 | 服务端每秒从磁盘写入的操作次数 | 次 |
| 磁盘读取带宽 | 服务端每秒从磁盘读取的数据量 | Bit/s |
| 磁盘写入带宽 | 服务端每秒从磁盘写入的数据量 | Bit/s |
实时日志
支持实时展示北极星实例的日志,并支持关键词查找。

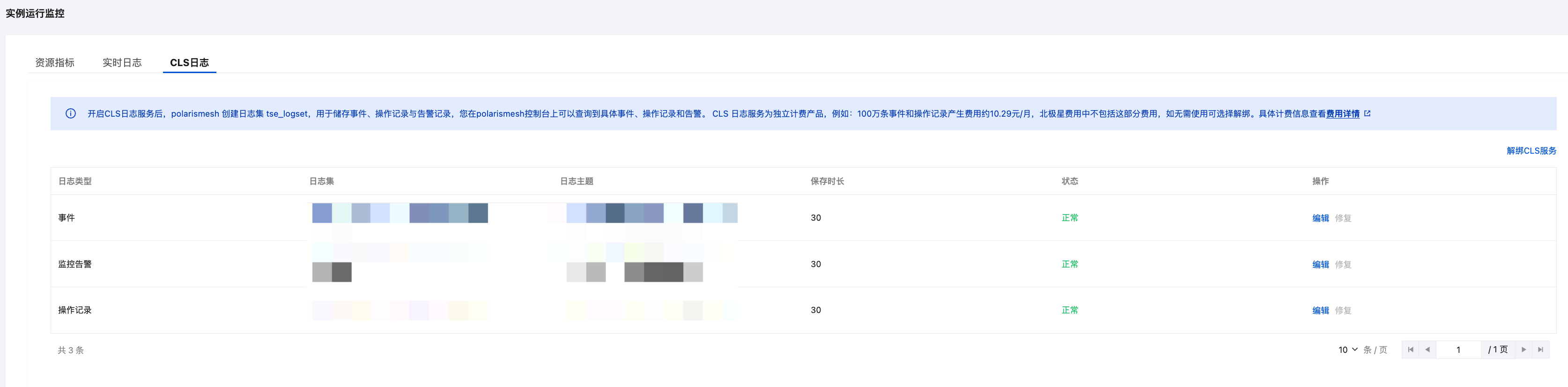
CLS日志
开启CLS日志服务后,创建日志集 tse_logset,用于储存事件、操作记录与告警记录,您在北极星控制台上可以查询到具体事件、操作记录和告警。
说明:
查看监控入口
1. 登录 TSF 控制台,在左侧导航栏选择 Polaris(北极星)进入引擎实例列表页。
2. 在北极星实例列表页,单击目标实例的“ID”,进入基本信息页面。
3. 在左边页签单击实例运行监控,可查看业务指标和系统指标。
选择好指标、节点和命名空间,设置好时间范围(支持近1小时、近12小时、近1天、近30天和自定义)和时间粒度(1分钟、5分钟),可查看对应的监控数据。
图标 | 说明 |
 | 单击可查看监控指标同环比。 |
 | 单击可刷新获取最新的监控数据。 |
 | |
 | 勾选后可在图表上显示图例信息。 |
 |
选择好指标、节点和接口,设置好时间范围(支持近1小时、近12小时、近1天、近30天和自定义),可查看对应的监控数据。
1. 选择好节点后,可查看对应节点的运行日志。
2. 在日志页面的搜索框,可以通过关键字查询相关日志。输入关键词查询,例如:“info”,注意日志检索区分大小写。

Polaris 持久化日志、事件中心、操作记录、告警数据存储在CLS服务中,开启CLS日志服务后可查看。




