概述
TDSQL Boundless 支持以 bulk load 的方式向数据库快速导入数据。相比于执行传统 SQL 普通事务写入的方式,bulk load 快速导入模式在性能上通常提升5~10倍以上,适合在业务上线阶段用作迁移现有的大型数据库到全新的 TDSQL Boundless 集群。
目前支持用
INSERT INTO / REPLACE INTO 语句进行 bulk load 导入数据。工作原理
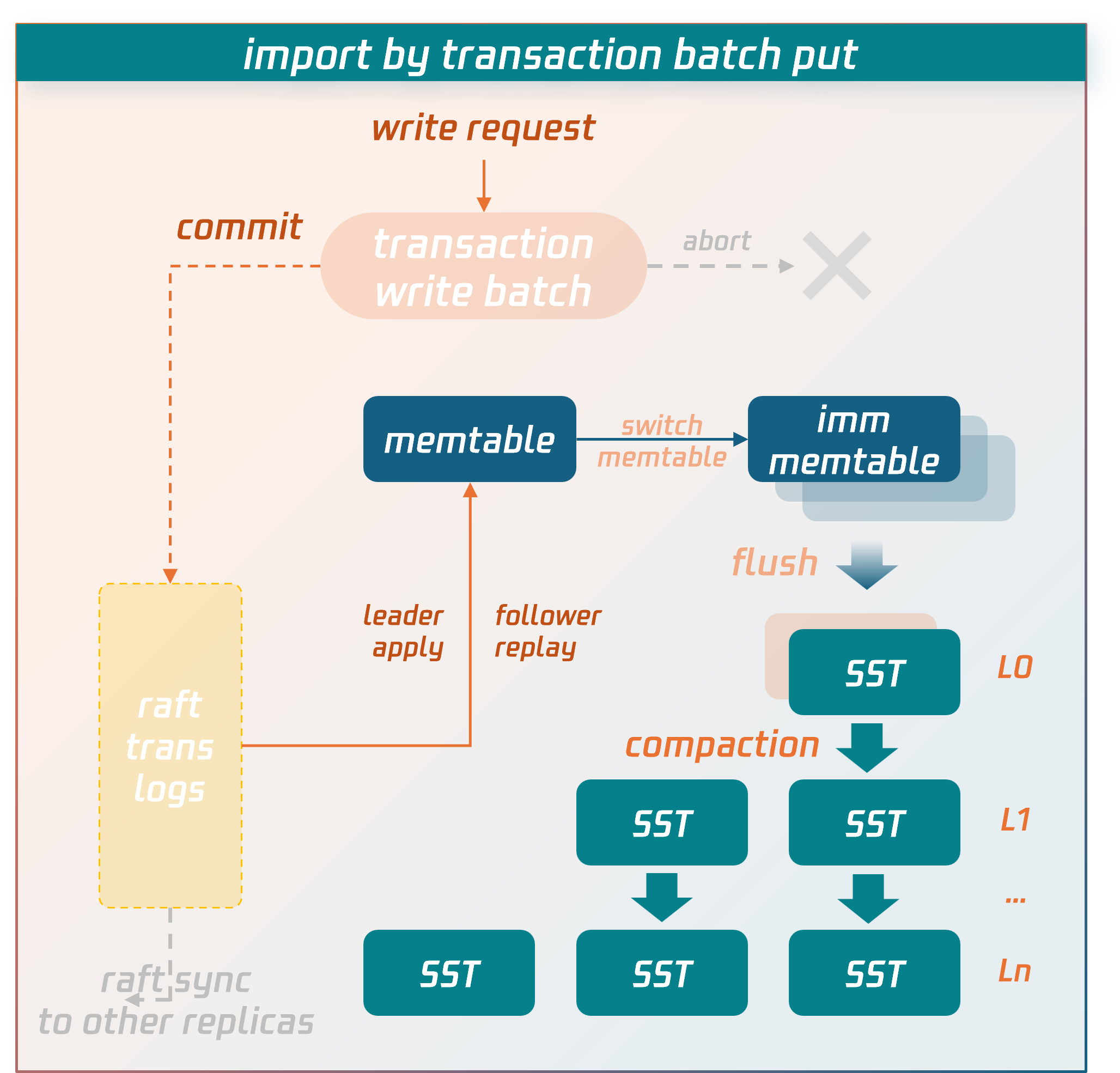
普通事务写入流程
数据在事务提交前会暂存在事务上下文的 write batch 中。进入提交阶段,write batch 中的数据会先落盘形成事务日志,通过 raft 协议同步到各副本所在节点。形成多数派后,数据会先写入内存中的 memtable 结构中,memtable 攒满后会 flush 落盘形成 SST 数据文件。SST 文件以 LSM-tree 结构进行分层组织存放,通过后台异步线程执行 compaction 操作,将数据进行合并和清理。
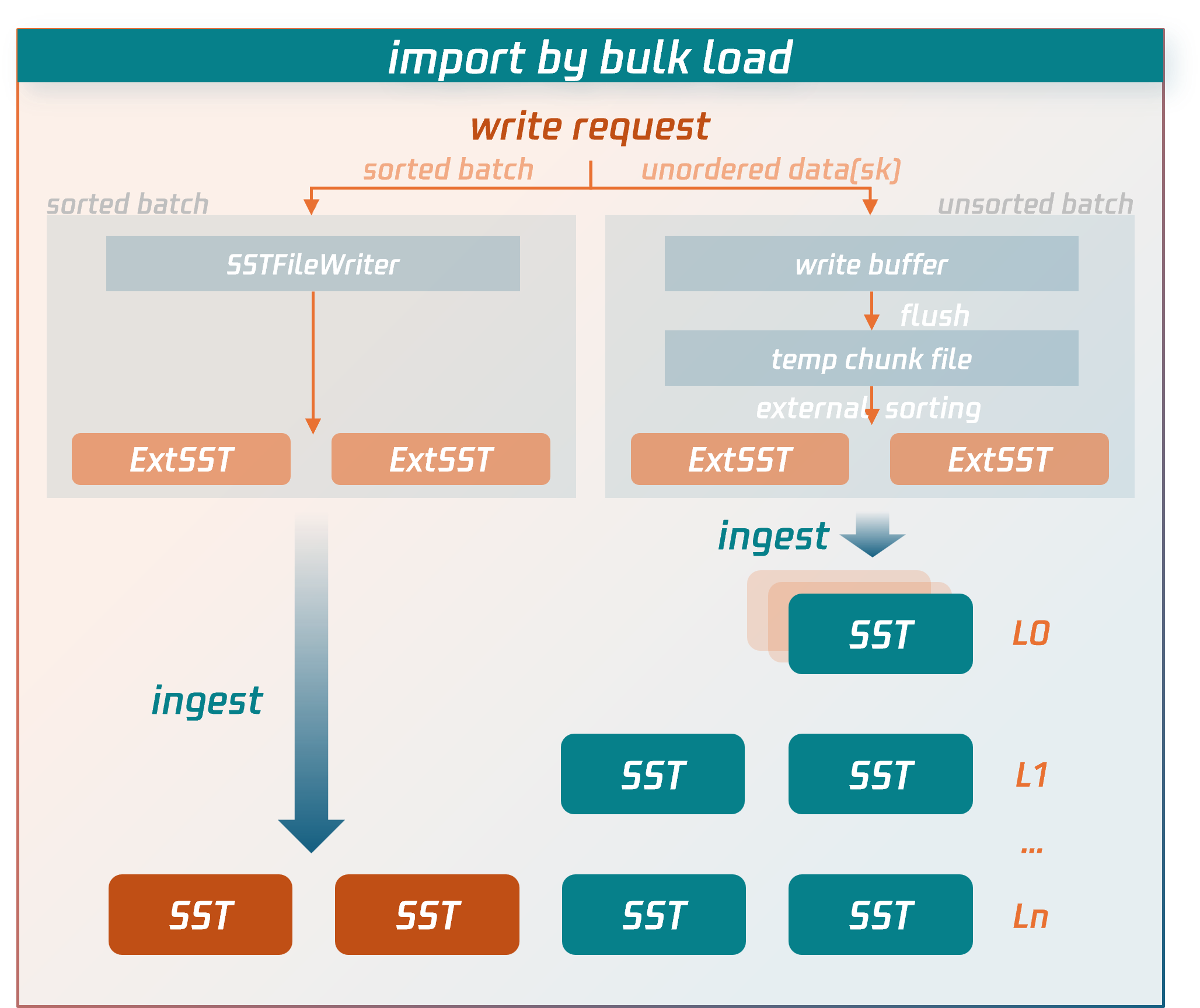
Bulk Load 写入流程
Bulk load 导入的写入流程尽量绕过了普通事务较为冗长的写入链路,直接将数据写入到压缩的数据文件中。
具体流程:
1. 接收到 bulk load 事务写入请求的节点(源节点)会先将 SQL 语句解析和编码成 key-value(KV)。
对于已有序的数据:直接写入到外部 SST 文件中。
对于无序的数据:先写到临时数据文件中,然后进行外部归并排序,生成外部 SST 文件。
2. bulk load 事务进入提交阶段后,源节点从 MC 控制节点拉取最新的 replication group(RG)路由信息,确定外部 SST 文件最终所属的 RG 及副本位置
3. 根据 RG 路由信息,源节点将外部 SST 文件发送到 RG 副本所在节点(数据节点)。
4. 确认外部 SST 文件被数据节点全部接收且校验成功后,源节点向 RG leader 数据节点发送 bulk load 事务提交请求,由 RG leader 数据节点同步一条 bulk load commit log(raft 日志),日志形成多数派后,通过执行或回放这条日志,RG 副本所在数据节点将外部 SST 文件直接插入到 LSM-tree 的合适位置。至此,数据写入到了数据库中。
与普通事务写入流程相比,bulk load 写入流程性能优化关键点:
不进行事务冲突检测。
无需将数据临时驻留在内存 write batch 中,而是直接落盘写入 SST 数据文件。
不需要先将数据落盘到事务日志并同步(注意:虽然 bulk load 事务也会写一条 commit log 用于维持主备数据写入一致,但并不需要将事务数据序列化到日志中,仅同步一些必要的元信息)。
SST 数据文件无需通过 flush、compaction 操作由 LSM-tree 的最上层进入,而是直接将外部 SST 文件尽量插入到 LSM-tree 的尽量底层的位置。
这些 bulk load 所做的针对性优化,显著减少了 CPU、内存和 I/O 资源,是导入性能提升的关键点。
使用说明和限制
下面会介绍 bulk load 导入相关的参数、使用限制,以及性能相关的最佳实践。
相关参数
Session Variables
参数名 | 默认值 | 说明 |
tdsql_bulk_load | false | 开启 bulk load 模式,符合条件的 SQL 语句会以 bulk load 的方式直接写入数据。 |
tdsql_bulk_load_allow_unsorted | false | bulk load 导入的主键数据是否支持乱序。当 tdsql_bulk_load_allow_unsorted 打开后,会对待导入数据进行额外的排序,使得导入速度降低。 |
tdsql_bulk_load_allow_sk | true | 是否支持导入二级索引数据。 如果导入的表已经存在二级索引,那么该变量需要设置为 true,否则无法走 bulk load 优化(仍然走正常事务逻辑或者 batch put 优化)。当打开时,需要由数据源端来保证数据唯一性,即不存在主键冲突。如果存在 unique secondary index 时,也需要数据源端保证二级索引数据的唯一性。否则会导致主键和二级索引不一致,或者打破二级索引数据唯一性的约束。 |
tdsql_bulk_load_allow_insert_ignore | true | 是否允许含有 ignore 语法的 SQL 语句( INSERT IGNORE)走 bulk load 优化。注意:当打开时,需要由数据源端来保证数据唯一性,即不存在主键冲突。因为 bulk load 模式不做主键冲突检查,即便允许 ignore 关键字,新数据仍会静默地覆盖掉旧数据,而不会遵循 ignore 语法(丢弃新数据保留旧数据)。 |
tdsql_bulk_load_allow_auto_organize_txn | false | 是否开启 bulk load 事务自动攒批提交,由数据库自行控制 bulk load 事务数据到合适的规模后发起自动提交。 注意:该选项开启后,当客户端返回事务提交成功请求时,对应的数据可能还在攒批,未达到自动提交的数据量阈值,因此可能不可见。通常用于对性能要求更高的大规模数据迁移导入,且迁移阶段无读请求,对该阶段数据无实时可见性要求,导入完毕后达到最终一致状态即可的场景。 |
使用限制
bulk load 也并非数据导入 TDSQL Boundless 的“银弹”(No Silver Bullet)。总体而言,bulk load 导入模式是以一定程度上牺牲事务的 ACID 属性,来换取更高的导入性能。例如,bulk load 事务之间不做冲突检测,需要由使用者来处理好源数据中的数据冲突,或者用户需要知悉 bulk load 对于冲突数据的处理逻辑。以及,当 bulk load 事务提交失败时,如果涉及到多个 RG 的数据,可能出现半提交现象,即一部分 RG 的数据写入成功,一部分 RG 写入失败,这实际上违反了事务的原子性。因此遇到提交失败的情况时,重试成功后会达到数据最终一致。
此外,使用 bulk load 模式存在如下具体场景和限制。
语法层面:
SET SESSION tdsql_bulk_load = ON,即 bulk load 模式需要打开。仅优化
INSERT INTO/ REPLACE INTO语句,其他语句不支持 bulk load 模式。INSERT INTO/ REPLACE INTO形式的 SQL,必须有多个 VALUES。如果只有一行数据,不支持 bulk load 模式。INSERT INTO SET/ REPLACE INTO SET形式的 SQL 只能写入一行数据,不支持 bulk load 模式。不优化
INSERT INTO ... ON DUPLICATE KEY UPDATE。因为 bulk load 模式下不会去检测已存在的 primary key,也就无法进行UPDATE操作。对于
INSERT INTO,实际上执行的是REPLACE INTO语法。即当导入的新数据与旧数据存在主键冲突时,并不会报错,而是直接静默地用新数据把旧数据覆盖掉。对于含有
IGNORE语法的 SQL 语句(INSERT IGNORE INTO),需要提前 SET SESSION tdsql_bulk_load_allow_insert_ignore = ON,否则无法走 bulk load 导入。对于含有
IGNORE语法的 SQL 语句(INSERT IGNORE INTO),bulk load 导入时,需要由源端数据保证数据唯一性,即导入的新数据与旧数据不存在主键冲突,导入的新数据之间也不存在主键冲突。否则,由于 bulk load 模式下,主键数据会被静默地覆盖掉,只保留一行,这会违反IGNORE语法(即丢弃新数据保留旧数据)。二级索引:
当表上有 secondary index 二级索引时,需要提前
SET SESSION tdsql_bulk_load_allow_sk = ON,否则无法走 bulk load 优化。当表上有 secondary index 二级索引时,bulk load 模式下需要由源端数据保证数据唯一性,即导入的新数据与旧数据不存在主键冲突,导入的新数据之间也不存在主键冲突。否则,由于 bulk load 模式下,主键数据会被静默地覆盖掉,只保留一行,但是二级索引数据编码后的 key 是没有唯一性的,就会出现二级索引数据的新旧两条记录都被保存下来了,导致主键和二级索引不一致。
对于需要建立 secondary index 二级索引的表,在 21.x 或之后的版本,用 bulk load 导数据时,优先推荐建表时先不建立 secondary index。待导入完成后,再创建 secondary index,创建 secondary index 的过程可以开启 fast online DDL 优化(需要手动开启),性能上会更好,而且可以绕过“源端数据唯一性”的限制。
当表上有 unique secondary index 唯一二级索引时,需要由源端数据保证数据唯一性,即既不存在主键冲突,也不违反二级索引数据的唯一性。否则会导致主键和二级索引不一致,或者打破二级索引数据唯一性的约束。
其他限制:
系统表不支持 bulk load 模式。因为系统表不应该发生大规模写入,而且一旦系统表有问题,集群将无法启动。因此系统表采用更加稳健的写入路径。
存在触发器的表,不支持 bulk load 模式导入。
bulk load 模式目前与 DDL 是互斥的。即表上若存在进行中的 DDL,不支持 bulk load 模式;若正处于 bulk load 模式下导数据,新的 DDL 请求会被拒绝。
通过 bulk load 模式导入的数据,不会生成 binlog,不会同步到灾备集群的备实例。
性能调优
为了使 bulk load 导入模式能够达到理想性能,最大化利用系统资源,我们将一些在实践过程中积累的调优经验总结罗列如下,供参考。
按序导入
按序导入是指数据按照主键从小到大的顺序去导入,数据库可以更高效地处理有序的数据。相对于乱序导入,按序导入性能提高20%~300%。
这里的按序,分为两个层面的有序。
bulk load 事务内部有序:在一个 bulk load 事务内部,数据需要按照主键顺序排列。
bulk load 事务之间可排序:将一个事务所写入数据的最小主键和最大主键作为这个事务的区间,如果事务的区间互相没有重叠,则认为事务之间是可排序的。换句话说,将两个事务所写入的数据,按照主键从小到大的顺序进行排序,不存在相互交叉的情况,则这两个事务是可排序的。
当以上两个有序的条件同时满足时,认为数据导入是完全有序的,性能最佳。
如果第一条不满足,即事务内部的一条条记录还没有按照主键顺序排好序,那么在导入之前,必须将参数 tdsql_bulk_load_allow_unsorted 打开,否则会失败报错。当 tdsql_bulk_load_allow_unsorted 打开后,每个事务中的数据会先暂存在临时文件中,在提交阶段对其进行外部归并排序,最后再按序输出到外部 SST 文件中。如果事务内部数据有序,则不需要该步骤,直接写到外部 SST 文件。因此事务内部无序要比有序消耗更多的 CPU 和 I/O 资源。
如果第二条不满足,那么事务和事务之间生成的外部 SST 文件会有区间重叠,当插入到 LSM-tree 时,会因为相互重叠导致在下层没有合适的插入位置,导致更多的 SST 文件被最终插入到最上层(level-0),会触发向下层的 compaction 操作,在 bulk load 数据导入期间,消耗一部分 I/O 资源,影响整体性能。
并发导入
当磁盘性能较好时(NVMe 磁盘),bulk load 性能瓶颈点很可能在 CPU 而不在 I/O,可以尝试适当增加导入线程的并发数(50~100)来提升导入效率。
系统支持通过
tdstore_bulk_load_sorted_data_sst_compression、tdstore_bulk_load_unsorted_data_sst_compression、tdstore_bulk_load_temp_file_compression参数(需要超级管理员权限)调整 bulk load 导入过程中产生的外部 SST 文件和待排序临时数据文件所使用的压缩算法, 来平衡 CPU 和 I/O、磁盘空间。SET GLOBAL tdstore_bulk_load_sorted_data_sst_compression=zstd,snappy,lz4,auto,nocompression,...;
控制事务大小
与普通事务先把未提交数据暂存在内存的 write batch 不同,bulk load 事务会把未提交数据直接写到外部 SST文件。因此大事务不会导致内存占用过多 OOM。
与之相反,bulk load 事务不宜过小,否则一方面会产生较小的 SST 文件,另一方面频繁的 bulk load 事务提交导致导入性能也不会好。
通常一个 bulk load 事务的数据量在200M以上,会达到比较好的性能。注意,外部 SST 文件默认是开启压缩算法的,以 ZSTD 为例,与原始数据相比,压缩率可能在10倍甚至更多,因此可以考虑让一个 bulk load 事务写入的原始数据量在2GB以上。
事务自动攒批提交
对于性能要求更高的大规模数据迁移导入,且迁移阶段无读请求的使用场景,也可以考虑开启 bulk load 事务自动攒批提交,
SET GLOBAL tdsql_bulk_load_allow_auto_organize_txn = ON; 由数据库自行控制 bulk load 事务数据到合适的规模后发起自动提交,从而维持较高的导入性能。但需注意,该选项开启后,当客户端返回事务提交成功请求时,对应的数据可能还在攒批,未达到自动提交的数据量阈值,因此可能不可见。建议导入完毕后进行行数校验。二级索引
对于表上存在二级索引的场景,表上的二级索引越多,bulk load 性能会变差。这是因为二级索引数据一定是无序的,需要进行额外的排序操作,从而增加了导入过程中的计算开销。针对存在二级索引的场景,优化建议适当增大 bulk load 事务的大小。
在21.x或之后的版本,更为推荐的方式是:用 bulk load 导数据时,考虑建表时先不建立二级索引。待导入完成后,再创建二级索引,创建二级索引时开启 fast online DDL 优化(需要手动开启),整体性能上会更好。
分区表
从计算层看,每个分区表会分配一个 unique t_index_id。实际处理逻辑跟处理一张普通表是类似的。需要考虑一个 bulk load 事务跨多个分区表的场景。
如果是 range 分区,且按序导入,那么一个 bulk load 事务中的数据通常会集中在一个 range 分区上,或者少量 range 相邻的分区上。此时一个 bulk load 事务通常不会涉及太多的分区表,跟普通表的场景类似,不需要做额外处理。
如果是 hash 分区,且按序导入,那么一个 bulk load 事务中的数据会被均匀地打散到各个 hash 分区上。此时一个 bulk load 事务会几乎涉及所有的分区表。此时需要把 bulk load 事务大小继续调大,从而保证一个 bulk load 事务中分配到每个 hash 分区上的数据量不要太少。假设一共 N 个 hash 分区,那么推荐 bulk load 事务大小比普通表场景扩大 N 倍。目前在分成16个 hash 分区的场景下,性能要比不进行 hash 分区(普通表)损失15%左右。
如果存在二级分区,需要考虑一个 bulk load 事务中的数据会涉及多少个二级分区,最终分配到每个二级分区上的数据量不要过少。
总而言之,如果一个 bulk load 事务涉及的分区数量越多,性能会逐渐退化。从存储层去看,其实就是一个 bulk load 事务涉及了过多的 RG 作为事务参与者。类似于普通事务也会有类似的问题,涉及的分区越多,RG 层面的参与者越多,性能越差。



