数据迁移中的亲和性保证
数据对象(Database Object):包含表、分区、索引等数据库对象。每一个表、分区、索引包含了多个行(记录),每条记录以键值对(KV)形式编码,保证同一表或索引的数据编码连续。如图中,
Table_t1 和 Table_t2 分别有主键索引 和二级索引,每个索引对应连续的 key 区间。数据分片(Region):一段连续的,左闭右开的 key 空间。单个分片最多包含一个数据对象的数据,支持将数据对象拆分为多个分片,保证数据管理的粒度化和规整性。
复制组(Replication Group):对应一个 Raft 日志流,管理多个不同 Region 的数据。支持数据亲和性调度,将关联数据置于同一复制组。
数据亲和性:数据之间存在相关性,例如:表内部的主键和二级索引,不同表之间的连接键,将相关的数据调度到同一个复制组,进行优化。
基于三层数据模型与一体化对等架构两个设计,我们可以做出灵活弹性的调度:包括利用数据亲和性消除分布式事务。

基于数据感知的调度
典型案例分析:
1. 用户创建包含 ID、姓名、年龄的表(表 ID 为100)
2. 在年龄列创建二级索引(索引表 ID 为200)
3. 主键索引 key 前缀为00000064,二级索引 key 前缀000000C8,两者 key 范围相距较远
传统方案:同时向两个独立的 Raft 日志流写入数据,必须通过两阶段提交(2PC)完成分布式事务,事务执行效率显著低于单机事务。
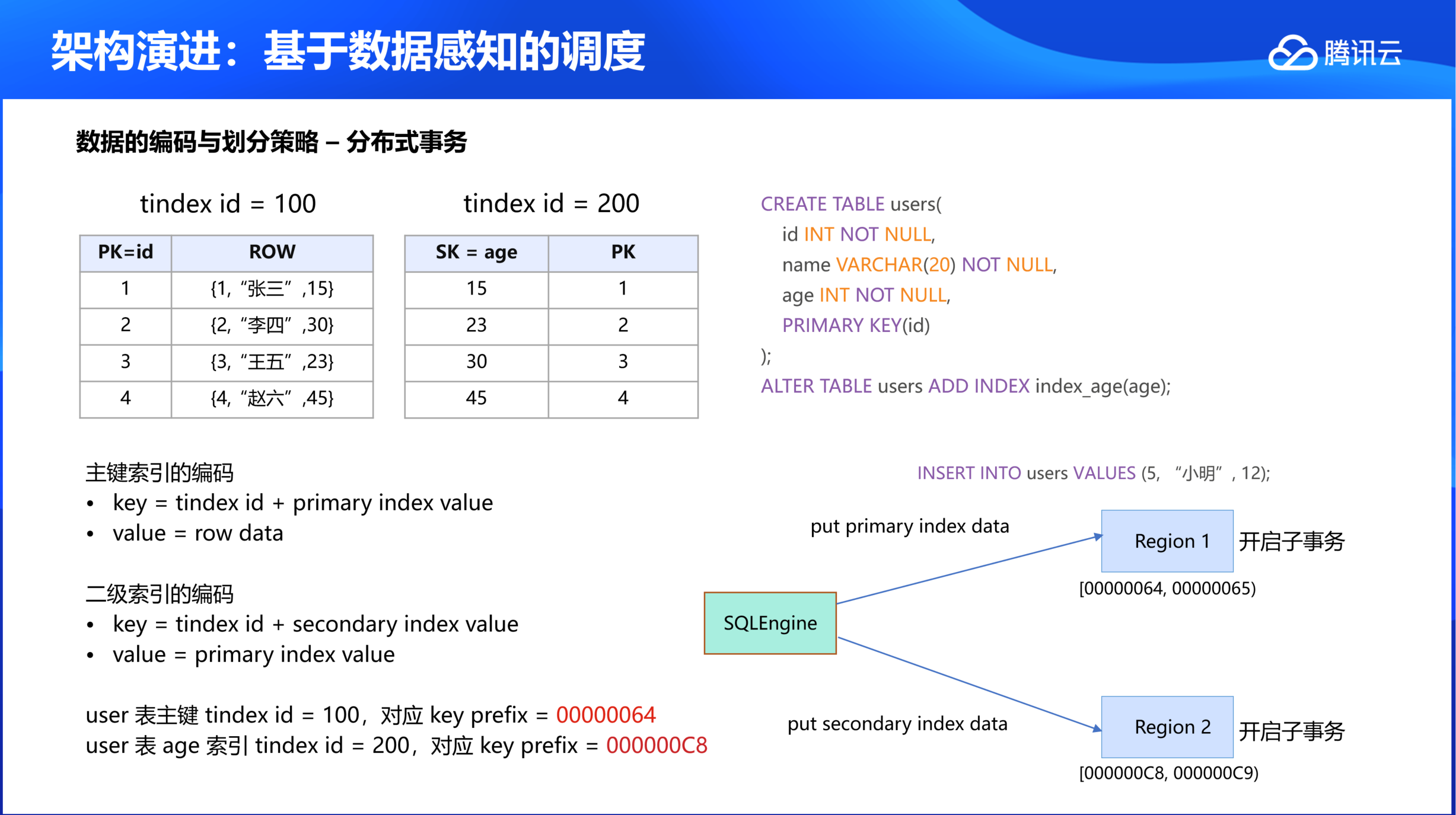
TDSQL Boundless 优化方案:
将关联数据(主键与二级索引)置于同一复制组。
SQLEngine 执行查询读写时,仅需向目标复制组发送请求,事务提交时也只需与单个复制组交互,通过 1PC 协议极大提升事务处理效率

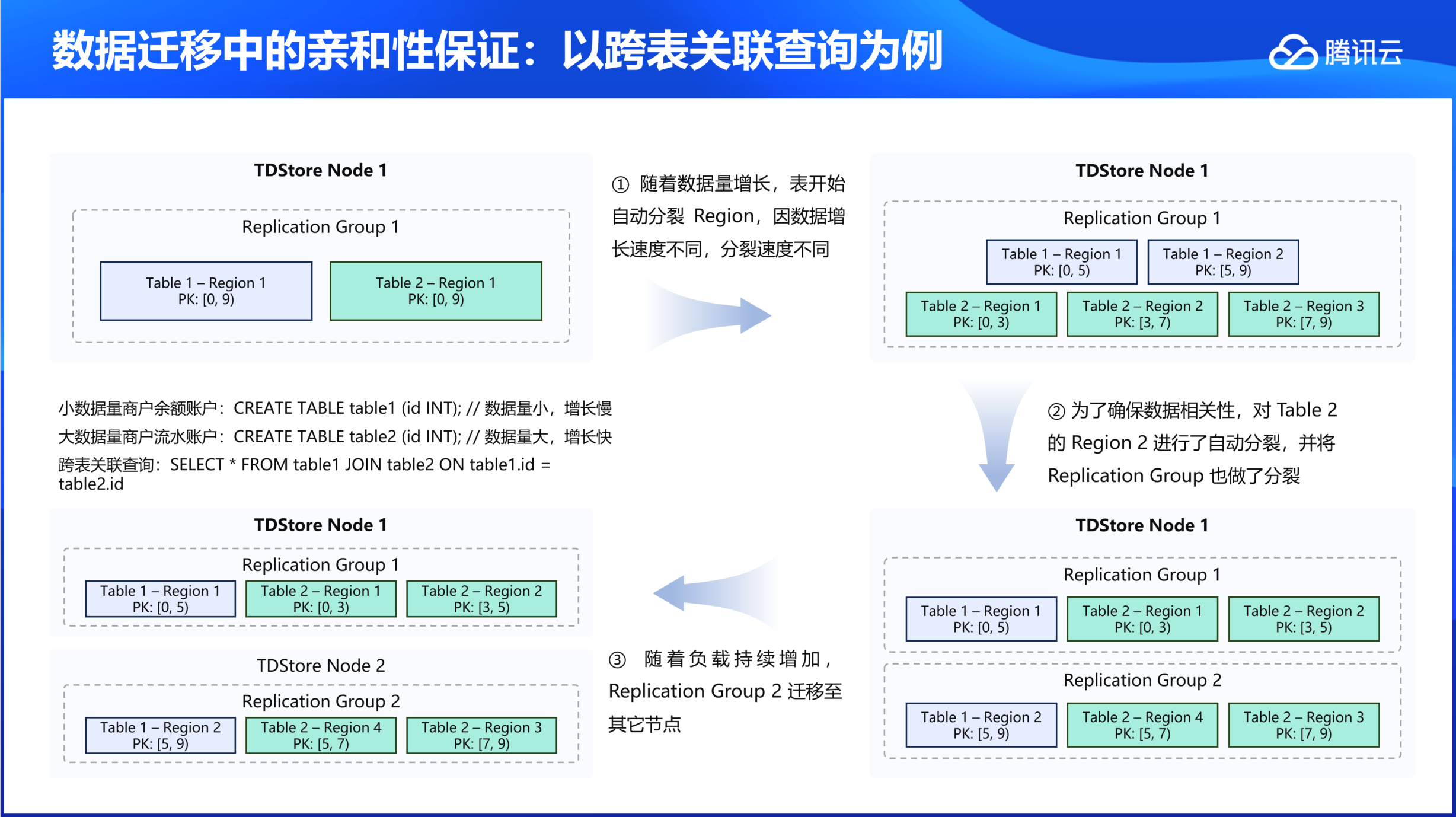
数据迁移中的亲和性保证:以跨表关联查询为例
初始状态:小数据量商户余额账户表与大数据量商户流水账户表共存于同一节点。
数据增长处理:
1. 随着数据量增长,表开始自动分裂 Region,因数据增长速度不同,分裂速度不同。
2. 为了确保数据相关性,对 Table 2的 Region 2进行了自动分裂,并将复制组也做了分裂。
3. 把相同数据范围的数据调度到同一个复制组(如 RG1:数据范围0-5;RG2:数据范围5-9)。当业务进行跨表关联查询的时候,只需要访问同一个复制组就可以达到查询的目的。
4. 随着负载持续增加,RG2迁移至其它节点。实现数据拆分的同时保证单个复制组内数据亲和性。
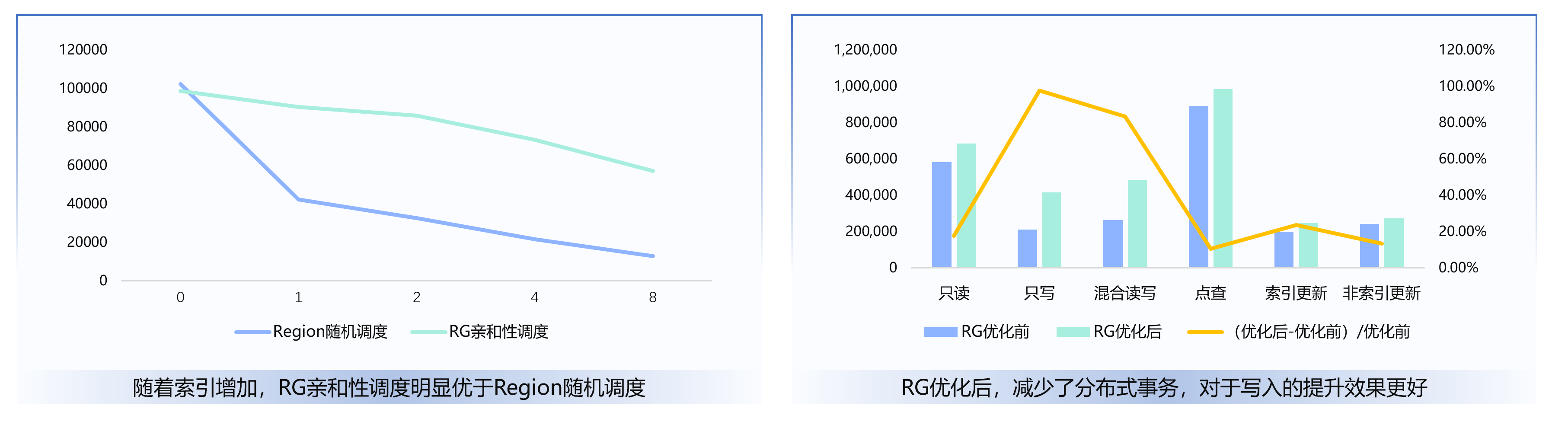
数据迁移中的亲和性保证:收益总结
亲和性保证可以使得经常被共同操作的数据存放在同一个节点,这使得它们的读写涉及更少的数据移动和 RPC 调用,也可以避免分布式事务,大幅度提升性能。