迁移工具特性
基本特性
多线程导出:以 HBase 分区表的 Region 为单位进行数据分片,也可以自行切分数据。
全局限速:支持按字节数或行数进行限速控制。
KV 结构导出:简化配置,无需为每个表自定义 Schema 结构。
导出工具默认行为说明
缺省值处理
date 和 varchar 类型:直接使用空字符。
其他数据类型:使用 "NULL" 填充。
范围导出:start_key 和 end_key 采用左闭右开区间。
选择迁移方案
迁移方案说明
迁移方案 | 说明 |
全量迁移 | 适用场景:首次迁移 特点:一次性迁移所有历史数据 |
增量同步 | 适用场景:持续数据同步 特点:先全量迁移,然后持续同步增量变更 |
迁移限制说明
1. 当前迁移暂不支持断点续传。
2. 增量迁移需自备 Kafka 环境。
环境准备
1. 已 获取迁移工具。
说明:
建议使用最新版本迁移工具。
2. 将工具上传至自定义目录(本文以
/data/tdsql-project/为例说明),并解压。工具目录结构:
/data/tdsql-project/apache-seatunnel-2.3.8/├── bin/ # 存放运行脚本的目录├── config/ # 配置文件目录,包括日志组件,jvm 配置等├── connectors/ # 存放依赖的jar包├── lib/ # 存放依赖的jar包├── licenses/ # 存放依赖的jar包├── plugins/ # 存放依赖的jar包└── starter/ # 存放依赖的jar包├── logging/
3. 准备好待迁移的 HBase 集群,TDSQL Boundless 实例。
4. Kafka 环境准备(仅 HBase 增量同步需要)
docker pull apache/kafka:4.1.0docker run -p 9092:9092 apache/kafka:4.1.0
全量迁移
通过
seatunnel.sh 脚本运行导出工具。可以通过
./bin/seatunnel.sh -h 查看运行脚本的帮助信息。步骤一:创建配置文件
创建配置文件(如
file_config)并保存到 config/ 目录下,配置文件包含三个主要部分:env:环境配置项。
source:HBase 数据源配置。
sink:目标端配置。
env {# 环境配置项 - 控制任务执行环境和资源限制,详见境配置 (env)parallelism = 1job.mode = "BATCH"}source {Hbase {# 定义 HBase 数据源的连接信息、认证方式和数据导出规则,详见 HBase 数据源配置 (source)}}sink {# 配置数据写入目标,支持两种模式 JDBC(推荐)和 localfile,详见目标端配置 (sink)}
1. 环境配置 (env)
env 为导出导入任务的整体配置,主要配置并发度和限速情况(默认不限速)。
env {parallelism = 1 # 指定 Source Sink 时的并发线程数,实际的并发度可能由 Source Sink 配置决定job.mode = "BATCH"read_limit.bytes_per_second = 7000000 # 按照读取 bytes 限速,不填则不限速read_limit.rows_per_second = 200000 # 按照读取行数限速,不填则不限速}
2. HBase 数据源配置 (source)
HBase 中的一行数据最终会被转化为多个 KV 对,取决于该行有多少列。转换后的每个 KV,最终都会作为 TDSQL Boundless 中的一行数据。
TDSQL Boundless KV 状态下的默认表结构:
CREATE TABLE IF NOT EXISTS `{TableName}`(`K` varbinary(1024) not null,`Q` varbinary(256) not null,`T` bigint not null,`V` mediumblob,PRIMARY KEY (`K`, `Q`, `T`))partition by key(`K`) partitions 6;
KV 格式配置模板:
source {Hbase {# HBase连接选项:# 必填zookeeper_quorum = "127.0.0.1:2181,127.0.0.2:2181,127.0.0.3:2181" // HBase 集群的 ZooKeeper 地址及端口,用以连接 HBasehbase_extra_config={ # 额外适配的 HBase 连接设置,如无特殊需求可以不设置zookeeper.znode.parent=/bdphbs07/hbaseidhbase.client.ipc.pool.size=***hbase.client.scanner.timeout.period=6000000hbase.rpc.timeout=6000000hbase.cells.scanned.per.heartbeat.check=10000}SourceModeKV = {specified_namespace = "***" # 指定需要导出的 namespacetable_match_rules = ["***"] # 指定需要导出的表的匹配规则}}}
说明:
多线程说明:
多线程需要先在 env 配置下指定需要的线程数量。
导出任务按照默认规则进行切分:对于每张表,按照表在 regionServer 上的分布来进行分片,每个分片作为一个导出任务。
由于同时存在多张表,这里导出任务分片在多线程之间的调度策略优先按照表进行,会按照扫描表时的顺序(字典序),优先调度同一张表的导出任务
3. 目标端配置 (sink)
配置数据写入目标,支持两种模式 JDBC(直接写入 TDSQL Boundless 数据库)和 LocalFile(导出到本地文件系统)。
方式一(推荐):通过 JDBC 导入。
sink {jdbc {# url 里需要开启 bulkload,必须打开 rewriteBatchedStatements=true,否则都是单条 insert,导入效率极差url = "jdbc:mysql://{ip}:{port}/?rewriteBatchedStatements=true&sessionVariables=tdsql_bulk_load='ON'"driver = "com.mysql.cj.jdbc.Driver"user = "test"password = "test123"schema_save_mode = "CREATE_SCHEMA_WHEN_NOT_EXIST"enable_upsert = false # 不开启 upsertmax_retries = 3 # 重试次数generate_sink_sql = "true" # 根据 DB 生成导入SQLdatabase = "hbase" # 需要把表导入到hbase dbbatch_size = 500000 # 工具攒批事务的大小,为了效率会攒够指定数量在往下刷# 在不超过工具所在机器内存限制的情况下,越大越好batch_interval_ms = 500transaction_timeout = 60000 # 事务超时设为60秒(避免大批次超时)}}
方式二:LocalFile
sink {LocalFile {# 不可修改:file_format_type = "text" # 导出文件格式,目前仅支持 textfield_delimiter = "," # 数据分隔符,仅支持逗号row_delimiter = "\\n" # 每行分隔符,仅支持换行符is_enable_transaction = false # 不支持事务# 必填:path = "/root/dumper_test/apache-seatunnel-2.3.4" # 导出路径tmp_path = "/root/dumper_test/apache-seatunnel-2.3.4" # 导出时会先导出到 tmp_path,再 mv 到 path,因此必须设置 tmp_path,否则会占用根目录空间result_table_name = "test_mytable" # 导出表名result_database_name = "test_mydatabase" # 导出数据库名,用于生成文件名result_column_names = ["id", "name"] # 导出列的列名,必须和 source 中s chema 里的 columns 数量相同# 选填:parent_directory = "test_directory" # 实际导出文件的父目录,即如果填写,则文件真实目录为:path/parent_directory/file,如果不填,则真实目录为:path/filefile_start_index = 1000 # 文件名的起始序列,文件名中的序列会从此数字开始递增,默认为0}}
说明:
如果选择导出到 LocalFile,只是把 HBase 数据转写为本地 SQL 文件,还需要借助 myloader 等工具将 LocalFile 导入到 TDSQL Boundless。
4. 参数调整
修改 SeaTunnel 工具分配给 JVM 的内存,编辑
config/jvm_client_options 配置。# 配置文件里的初始值给的很小,在高并发下可能会因为内存资源调用不足导致无法进行工作,可根据机器资源大小适当给就行-Xms32g #指定 JVM 初始堆内存大小为 32GB-Xmx128G
在执行数据迁移前,请先登录 TDSQL Boundless 实例,执行以下命令,调整参数配置。
set persist tdsql_bulk_load_allow_auto_organize_txn = on; -- 允许 bulkload自组织事务导入,增量迁移下需要关闭set persist tdsql_bulk_load_allow_unsorted = on; -- 允许 bulkload 事务乱序set persist tdsql_bulk_load_commit_threshold = 4294967296; -- commit 阈值调整set persist tdsql_bulk_load_rpc_timeout = 7200000; -- rpc 超时时间
步骤二:执行数据迁移
在填写好配置文件后,可以准备开始导出,其中每一个配置文件都会作为一个 SeaTunnel 任务被执行。本文介绍如何以本地集群的方式启动 SeaTunnel 导出任务。
1. 在自定义目录(本文以
/data/tdsql-project/apache-seatunnel-2.3.8/为例说明)下,把填好的配置文件存入 ./config 目录下。2. 在自定义目录下,执行以下命令,即可根据该配置文件启动一个 SeaTunnel 本地集群,使用该配置文件进行导出。
nohup ./bin/seatunnel.sh --config ./config/hbase_config -m local > seatunnel_hbase_local.log 2>&1 &tail -f seatunnel_hbase_local.log
参数说明:
--config:指定配置文件路径。-m local:本地模式运行。步骤三:数据校验
校验规则如下:分别从 HBase 和 TDSQL Boundless 按照数据分片读取数据,并且计算每行数据的 CRC32 校验值并累加,比较最终的累加结果。
数据校验步骤如下:
1. 创建并编写校验配置文件
config/validation_config。HBaseDataValidation {parallelism = 10specified_namespace = "default"table_match_rules = []zookeeper_quorum = "127.0.0.1:2181,127.0.0.2:2181,127.0.0.3:2181"// 自行替换用户名和密码,ip portmysql_jdbc_url = "jdbc:mysql://{ip}:{port}/hbase?user=test&password=test1234"}
2. 执行数据校验
校验程序被打包在
hbase-connector.jar 中,可以在包部署目录下运行脚本:./bin/validateKV.sh ./config/validation_config
工具目录结构:
## dir tree./apache-seatunnel-2.3.8/bin/├── install-plugin.cmd├── install-plugin.sh├── seatunnel-cluster.cmd├── seatunnel-cluster.sh├── seatunnel.cmd├── seatunnel-connector.cmd├── seatunnel-connector.sh├── seatunnel.sh└── validateKV.sh
增量同步(包含快照全量同步 + 增量同步)
增量同步涉及到准备全量快照数据以及开启增量数据接收的位点,迁移工具会先做快照全量数据的同步,并在快照数据同步完成后,进行增量数据的同步,而无需自行同步全量数据。
注意:
增量同步模式中,工具需要对 HBase 集群做以下操作:
1. 如果表本身
replication_scope 属性没有打开,需要执行 disable table; enable table;。2. 创建快照,并恢复一个快照表,作为全量快照数据的导出点。
3. 对原 HBase 集群执行 add_peer,用来捕获增量数据。
步骤一:环境检测
1. 检查待同步表的列族属性,其属性
replication_scope 必须为1(开启同步),否则需要打开工具对应的开关 auto_enable_replication = true。# 确认待同步表的列簇 replication_scope 属性为 1hbase shelldescribe 'your_table_name'
2. 网络连通性验证:确保 HBase 集群可通过域名访问迁移工具节点。
3. Kafka 集群:确保迁移机器能正确访问 Kafka,迁移工具需要暂存增量数据,等全量同步完成后,再逐个消费暂存的增量数据,增量数据会暂存在 Kafka 集群中。如果数据量比较大,建议提供一个稳定的 Kafka 环境,也可以本地用 Docker 快速部署一个 Kafka 集群,命令如下:
docker pull apache/kafka:4.1.0docker run -p 9092:9092 apache/kafka:4.1.0
4. 端口确认: 增量迁移工具会自启动一个 HBase,期间会使用本地目录,以及指定端口(默认是2181、16000、16010、16020、16030)来启动迁移工具依赖的 HBase 结构,需确保上述端口可用,否则需要在配置文件中指定端口使用。
步骤二:开始增量同步
1. 创建增量校验配置文件。
注意:
1.
job.mode 必须为 STREAMING,否则不会走增量模式,会按照全量数据导出。2. 开启表复制属性时,会先 disable 表再 enable 表,这个过程通常很快,但还是建议将
auto_enable_replication 设置默认为 false。如果表的复制属性(replication_scope)没有打开,需打开该开关或自行将表的列族 replication_scope 属性设置为1。3. Kafka 集群配置,如果是按照上文通过 Docker 启动,则不需要额外配置,保持默认即可。
4. 详细参数说明请参见 配置参数。
env {parallelism = 4job.mode = "STREAMING" // 增量模式需要配置为STREAMING模式job.retry.times = 0}source {Hbase {HbaseCDCConfig {auto_enable_replication = truekafka_bootstrap_servers = "localhost:9092" // 如果是使用docker启动,保持默认即可peer_name = "incr_001" // hbase peer name// 以下为增量迁移工具自启动的hbase,如端口冲突可自行配置端口,否则默认使用2181 16000 16010 16020 16030端口zk_host = "ip:12181"hbase.master.port = 26000hbase.master.info.port = 26010hbase.regionserver.port = 26020hbase.regionserver.info.port = 26030}SourceModeKV = {specified_namespace = "***" // 指定需要导出的 namespacetable_match_rules = ["***"] // 指定需要导出的表的匹配规则dump_create_schema = truedump_source_split_metrics = false}zookeeper_quorum = "127.0.0.1:2181"# 可选配置is_kerberos_connection=true # 是否需要kerberos验证,默认false。仅当该项为true,才需要填写接下来的四项。kerberos_ms_name="xxx" # hbase.master.kerberos.principalkerberos_rs_name="xxx" # hbase.regionserver.kerberos.principalkerberos_user_name="xxx"kerberos_keytab="xxx"}}sink {jdbc {// 开启bulk_loadurl = "jdbc:mysql://127.0.0.1:6050/?rewriteBatchedStatements=true&sessionVariables=tdsql_bulk_load='ON'"driver = "com.mysql.cj.jdbc.Driver"properties {autoReconnect = "true"failOverReadOnly = "false"maxReconnects = "10"tcpKeepAlive = "true"rewriteBatchedStatements = "true"}user = "test"password = "test123"schema_save_mode = "CREATE_SCHEMA_WHEN_NOT_EXIST"enable_upsert = truemax_retries = 1generate_sink_sql = truedatabase = "hbase" // 导入到hbase库batch_size = 500000}}
2. 参数调整
修改 SeaTunnel 工具分配给 JVM 的内存,编辑
config/jvm_client_options 配置。# 配置文件里的初始值给的很小,在高并发下可能会因为内存资源调用不足导致无法进行工作,可根据机器资源大小适当给就行-Xms32g #指定 JVM 初始堆内存大小为 32GB-Xmx128G
在执行数据迁移前,请先登录 TDSQL Boundless 实例,执行以下命令,调整参数配置。
set persist tdsql_bulk_load_allow_unsorted = on; -- 允许 bulkload 事务乱序set persist tdsql_bulk_load_commit_threshold = 4294967296; -- commit 阈值调整set persist tdsql_bulk_load_rpc_timeout = 7200000; -- rpc 超时时间
3. 启动同步任务
在自定义目录(本文以
/data/tdsql-project/apache-seatunnel-2.3.8/为例说明)下,执行以下命令,开始增量同步。./bin/seatunnel.sh --config ./config/incremental_config -m local
步骤三:观察增量数据校验进度,适时停止增量迁移
工具会先同步全量数据,这一过程通常比较漫长,全量数据同步完成后,会开始增量数据的迁移。
可以通过查看日志中的 Progress Information 来查看整体同步情况。
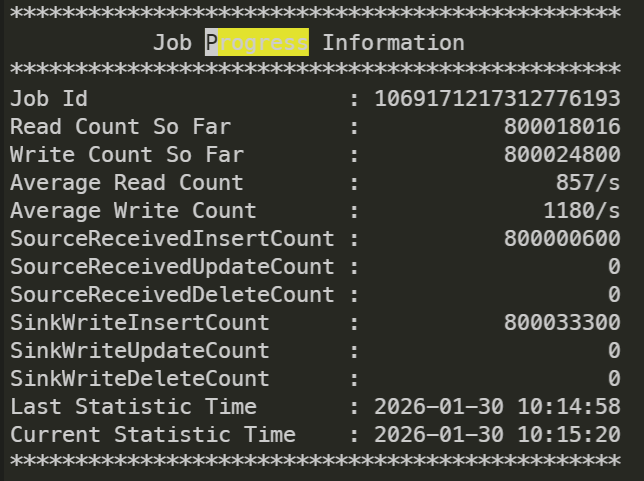
通过 IncSplit Progress Information 来查看增量同步的情况。
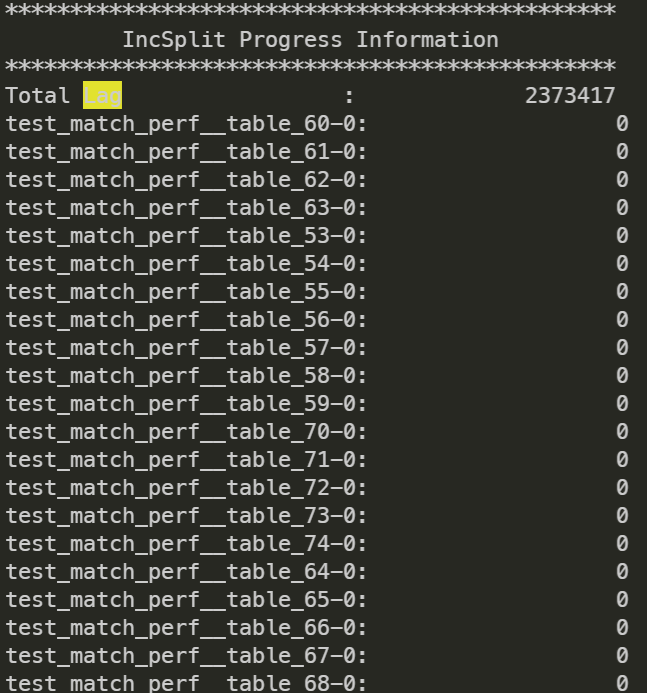
工具会打印出增量同步时,每张表在 Kafka 中的 LAG,即增量数据消费情况。
步骤四:数据校验
1. 迁移完成后,进行数据校验。请先停掉业务流量,创建校验配置文件
config/validation_config。HBaseDataValidation {parallelism = 10specified_namespace = "default" // hbase中的namespacetable_match_rules = ["(?!.*snapshot_for_seatunnel_incremental_source).*"] // 需要校验的表,过滤掉校验工具创建的快照表zookeeper_quorum = "127.0.0.1:2181,127.0.0.2:2181,127.0.0.3:2181"// 自行替换用户名和密码,ip portmysql_jdbc_url = "jdbc:mysql://{ip}:{port}/hbase?user=test&password=test1234"}
2. 增量迁移工具会在原 HBase 中创建一张快照表,快照表默认以
$(originTableName)_snapshot_for_seatunnel_incremental_source 格式命名,在正式开始校验前,需要注意在 table_match_rules 中过滤掉"_snapshot_for_seatunnel_incremental_source"结尾的表,避免受到影响,或者参考 步骤五,运行清理工具,将该表清理掉。3. 执行校验,校验程序被打包在
hbase-connector.jar 中,可以在包部署目录下运行脚本。./bin/validateKV.sh ./config/validation_config
步骤五:运行清理工具,清理增量迁移过程残留的环境
校验通过后,使用工具脚本清理 HBase 中创建的复制对(Peer),Kafka topic,等临时资源。
假设你使用了
config/incr_migration_config 去做增量迁移,运行以下脚本做清理,无需写配置文件,直接复用迁移时的配置文件即可。./bin/cleanupIncrementResource.sh ./config/incr_migration_config
配置参数说明
迁移类型 | 参数分类 | 参数名 | 参数说明 | 取值示例 |
全/增量迁移 | 环境配置(env) | parallelism | 指定 Source/Sink 并发线程数,实际并发度可能受数据源分片影响 | 1、4、10 |
全/增量迁移 | 环境配置(env) | job.mode | 任务运行模式,全量迁移需指定为批处理模式,增量需为流处理模式 | "BATCH" "STREAMING" |
全/增量迁移 | 环境配置(env) | read_limit.bytes_per_second | 按读取字节数限速,控制全量迁移对 HBase 集群的压力 | 7000000(7MB/s) |
全/增量迁移 | 环境配置(env) | read_limit.rows_per_second | 按读取行数限速,辅助控制迁移速率 | 200000(20万行/s) |
全/增量迁移 | HBase 数据源(source) | zookeeper_quorum | HBase 集群 ZooKeeper 地址及端口,用于建立 HBase 连接 | "127.0.0.1:2181,127.0.0.2:2181" |
全/增量迁移 | HBase 数据源(source) | SourceModeKV.specified_namespace | 指定需导出的 HBase 命名空间(Namespace) | "default"、"hbase_test" |
全/增量迁移 | HBase 数据源(source) | SourceModeKV.table_match_rules | 指定需导出的表匹配规则(支持通配符) | ["table_*", "user_info"] |
全/增量迁移 | 目标端(sink-jdbc) | url | TDSQL Boundless JDBC 连接地址 | "jdbc:mysql://{ip}:{port}/?rewriteBatchedStatements=true&sessionVariables=tdsql_bulk_load='ON'" |
全/增量迁移 | 目标端(sink-jdbc) | batch_size | 工具攒批事务大小,影响同步效率和内存占用 | 500000、1000000 |
增量迁移 | HBase 数据源(source) | HbaseCDCConfig.auto_enable_replication | 自动开启 HBase 表列族的 replication_scope 属性(需为1) | true、false |
增量迁移 | HBase 数据源(source) | HbaseCDCConfig.kafka_bootstrap_servers | 增量数据暂存的 Kafka 集群地址 | "localhost:9092"、"192.168.1.1:9092" |
全/增量迁移 | HBase 数据源(source) | is_kerberos_connection | 是否启用 Kerberos 认证连接 HBase | true、false |
全/增量迁移 | HBase 数据源(source) | kerberos_ms_name | HBase Master 节点 Kerberos 主体名称 | "hbase/master@EXAMPLE.COM" |
全/增量迁移 | HBase 数据源(source) | kerberos_rs_name | HBase RegionServer 节点 Kerberos 主体名称 | "hbase/regionserver@EXAMPLE.COM" |
全/增量迁移 | HBase 数据源(source) | kerberos_user_name | Kerberos 认证用户名 | "hbase_user" |
全/增量迁移 | HBase 数据源(source) | kerberos_keytab | Kerberos 认证 keytab 文件路径 | "/etc/kerberos/keytabs/hbase.keytab" |
全/增量迁移 | 目标端(sink-jdbc) | enable_upsert | 启用 UPSERT 语义(存在则更新,不存在则插入) | true、false |
增量迁移 | HBase 端口配置 | hbase.master.port | 手动指定 HBase Master 服务端口(解决默认端口16000冲突) | 16001、16002 |
增量迁移 | HBase 端口配置 | hbase.master.info.port | 手动指定 HBase Master Web UI 端口(解决默认端口16010冲突) | 16011、16012 |
增量迁移 | HBase 端口配置 | zk_host | 手动指定 HBase ZK 端口 | "ip:port" "127.0.0.1:12181" |
增量迁移 | HBase 端口配置 | hbase.regionserver.port | 手动指定 HBase RegionServer 端口(解决默认端口16020冲突) | 16021、16022 |



