Distribution Policy(DP) 是 TDSQL Boundless 管理数据对象分布的规则系统,通过对数据对象显式设置规则,元数据服务(MC)可以进行相应的调度。通过设置不同的调度规则,用户可以精细化控制数据对象的分布,如副本数量,副本位置分布,Replication Group Leader 位置等。
规则介绍
Distribution Policy 通常由多条具体的规则组成。元数据服务会对用户指定的多条规则进行校验,以确保规则本身的正确性以及多条规则之间不会互相冲突,具体的校验规则可参考注意事项。DP 的单条规则的设计参考了 Kubernetes 的 LabelConstraint 的设计,通常由含有
key, op, values 字段的 JSON 组成,如下所示:{"key": "key1", "op": "op1", "values": ["value1","value2"]}
目前 TDSQL Boundless 支持的规则如下所示:
key | op | values |
region | "in", "notIn", "exists", "notExists" | 地域列表,如 ["guangzhou"] |
zone | "in", "notIn", "exists", "notExists" | 可用区列表,如 ["guangzhou-1"] |
rack | "in", "notIn", "exists", "notExists" | 机架列表,如 ["rack-1","rack-2"] |
host | "in", "notIn", "exists", "notExists" | 主机列表,如 ["host-1","host-2","host-3"] |
node | "in", "notIn" | 节点列表,如 ["node-tdsql3-xxx-001"] |
replica-count | "=" | 副本数量,如 ["3"] |
follower-count | "=" | RG follower 数量,如 ["2"] |
learner-count | "=" | RG learner 数量,如 ["1"] |
witness-count | "=" | RG witness 数量,如 ["1"] |
leader-preferences | "=" | RG leader 偏好,用法参考说明2 |
fault-tolerance-level | "=" | 容灾级别,如 ["zone"] |
tdsql-storage-type | "in", "notIn", "exists", "notExists" | 磁盘类型列表,如 ["CLOUD_TCS","CLOUD_BSSD"] |
说明:
1. 操作符含义:
in:给定 key 对应的 value 包含在给定的 values 列表中。
notIn:给定 key 对应的 value 不包含在给定的 values 列表中。
exists:包含给定 key。
notExists:不包含给定 key。
2. leader-preferences 的 values 由嵌套结构组成,例如:["{\\"key\\": \\"zone\\", \\"op\\": \\"in\\", \\"values\\": [\\"guangzhou-1\\"]}", "{\\"key\\": \\"zone\\", \\"op\\": \\"in\\", \\"values\\": [\\"guangzhou-2\\"]}"]。为了方便您的使用,推荐您 使用 SQL 创建 Distribution Policy。
注意:
1. RG 副本相关的规则说明:RG leader 数量 + RG follower 数量 = replica-count - learner-count - witness-count。
当不指定 learner-count 或 witness-count 时,默认 learner 和 witness 的数量均为0。
例如指定 replica-count = 4 时表示 RG leader 数量为1,follower 数量为3。
2. 使用 node 作为 key 时的规则说明:
2.1 必须保证 values 中的节点是真实存在于实例中。
2.2 如指定副本数时,values 中的节点数量需要大于等于副本数,否则 DP 将无法调度。
3. 使用 leader-preferences 时的规则说明:RG leader 的位置应该始终是副本位置约束的子集,例如当指定副本位置位于可用区 ["zone1", "zone2", "zone3"] 时,需要保证 RG leader 的位置也指定在上述可用区中。
警告:
元数据服务在发现不合理的 DP 设置时,会拒绝进行调度,但不会影响其他功能的可用性以及数据的正确性。
使用 Distribution Policy
本节以工具
mc-ctl 为例,使用对应的 HTTP 接口也可得到相同的效果。开启和关闭 Distribution Policy
distribution-policy-enabled 在 v18.0.0 默认开启开启 Distribution Policy:
./mc-ctl schedule set --config_key distribution-policy-enabled --config_value 1
关闭 Distribution Policy:
./mc-ctl schedule set --config_key distribution-policy-enabled --config_value 0
创建 Distribution Policy
./mc-ctl dp create --data'{"policy_name":"$name","constraints":[{"key": "key1", "op": "op1", "values": ["value1","value2"]},...]}'
说明:
创建 DP 输入的 JSON 字符串需要指定 policy_name 和 constraints,constraints 可包含多条如前文所述的 DP 规则。
修改 Distribution Policy
./mc-ctl dp modify --data'{"policy_id": $id,"policy_name":"$name","constraints":[{"key": "key1", "op": "op1", "values": ["value1","value2"]},...]}'
注意:
修改 DP 输入的 JSON 字符串要指定 policy_id,同时需要指定需要修改的 policy_name 或 constraints。只有未绑定数据对象的 DP 规则可以被修改,如果需要修改已绑定数据对象的 DP,需要先解除数据对象与 DP 的绑定。
删除 Distribution Policy
# 通过 ID 删除./mc-ctl dp delete --distribution_policy_id ${id}# 通过 distribution policy name 删除./mc-ctl dp delete --distribution_policy_name ${policy_name}
注意:
DP 可以通过 distribution_policy_id 或 distribution_policy_name 删除。只有未绑定数据对象的 DP 规则可以被删除,如果需要删除已绑定数据对象的 DP,需要先解除数据对象与 DP 的绑定。
查看 Distribution Policy
# 查看已创建的所有 DP./mc-ctl dp info all# 通过 distribution policy name 查看单条 DP./mc-ctl dp info single --distribution_policy_name ${policy_name}
数据对象绑定 DP
在创建 DP 完成之后,可将数据对象与 DP 绑定,从而达到对应的调度效果。
数据库绑定 DP
CREATE DATABASE db1 USING distribution policy ${policy_name};
单表绑定 DP
CREATE TABLE t1(a INT) USING distribution policy ${policy_name};
分区表绑定 DP
CREATE TABLE t1(a INT) PARTITION BY HASH(a) PARTITIONS 4 USING distribution policy ${policy_name};
说明:
DP 在数据对象中遵循继承规则。例如上述例子中,创建数据库 db1 并绑定 DP 后,在该数据库中创建的所有单表和分区表都将使用与数据库相同的 DP,但如果直接对该数据库中的一张表绑定另一种 DP,其优先级高于继承规则。
典型 DP 示例
场景1:创建一个5副本的 DP。
./mc-ctl dp create --data '{"policy_name": "policy_1", "constraints": [{"key": "replica-count", "op": "=", "values": ["5"]}]}'
场景2:创建一个4副本并包含一个 learner 的 DP。
./mc-ctl dp create --data '{"policy_name": "policy_2", "constraints": [{"key": "replica-count", "op": "=", "values": ["4"]}, {"key": "learner-count", "op": "=", "values": ["1"]}]}'
场景3:创建一个副本位于 node-001, node-002, node-003 节点,且 RG Leader 位于 node-001 节点的 DP。
./mc-ctl dp create --data '{"policy_name": "policy_3", "constraints": [{"key": "node", "op": "in", "values": ["node-001", "node-002", "node-003"]},{"key": "leader-preferences", "op": "=", "values": ["{\\"key\\": \\"node\\", \\"op\\": \\"in\\", \\"values\\": [\\"node-001\\"]}"]}]}'
场景4:创建一个副本放置于磁盘类型是 SSD 的 DP。
./mc-ctl dp create --data '{"policy_name": "policy_4", "constraints": [{"key": "tdsql-storage-type", "op": "in", "values": ["SSD"]}]}'
使用 SQL 创建 Distribution Policy
v21.2.3版本提供了 SQL 语法用于创建 Distribution Policy。使用 SQL 创建 DP 在语法设计上尽量贴合了
mc-ctl 的用法,避免用户二次学习成本。具体的用法如下:SQL in DP 中与规则
key 相关的关键字有:REGION, ZONE, RACK, HOST, NODE, REPLICA_COUNT, FOLLOWER_COUNT, LEARNER_COUNT, WITNESS_COUNT, STORAGE_TYPE,FAULT_TOLERANCE_LEVEL, LEADER_PREFERENCES与
op 相关的关键字有:IN, NOT IN, EXISTS, NOT EXISTS SQL 创建 Distribution Policy
# 创建一条副本需要放置在 zone1 和 zone2 的可用区上并且副本数为 2 的 DPCREATE DISTRIBUTION POLICY "policy_1" SET ZONE IN ("zone1", "zone2") AND REPLICA_COUNT = 2;
SQL 修改 Distribution Policy
# 将名称为 "policy_1" 的 DP 约束修改为:副本需要放置在磁盘类型为 "SSD" 的磁盘上ALTER DISTRIBUTION POLICY "policy_1" SET STORAGE_TYPE IN ("SSD");# 将 DP "old_dp_name" 的名称修改为 "new_dp_name"RENAME DISTRIBUTION POLICY "old_dp_name" TO "new_dp_name";
SQL 删除 Distribution Policy
# 将名称为 "policy_1" 的 DP 删除DROP DISTRIBUTION POLICY "policy_1";
SQL 查询 Distribution Policy
information_schema 中新增了视图 META_CLUSTER_DPS,表结构如下:
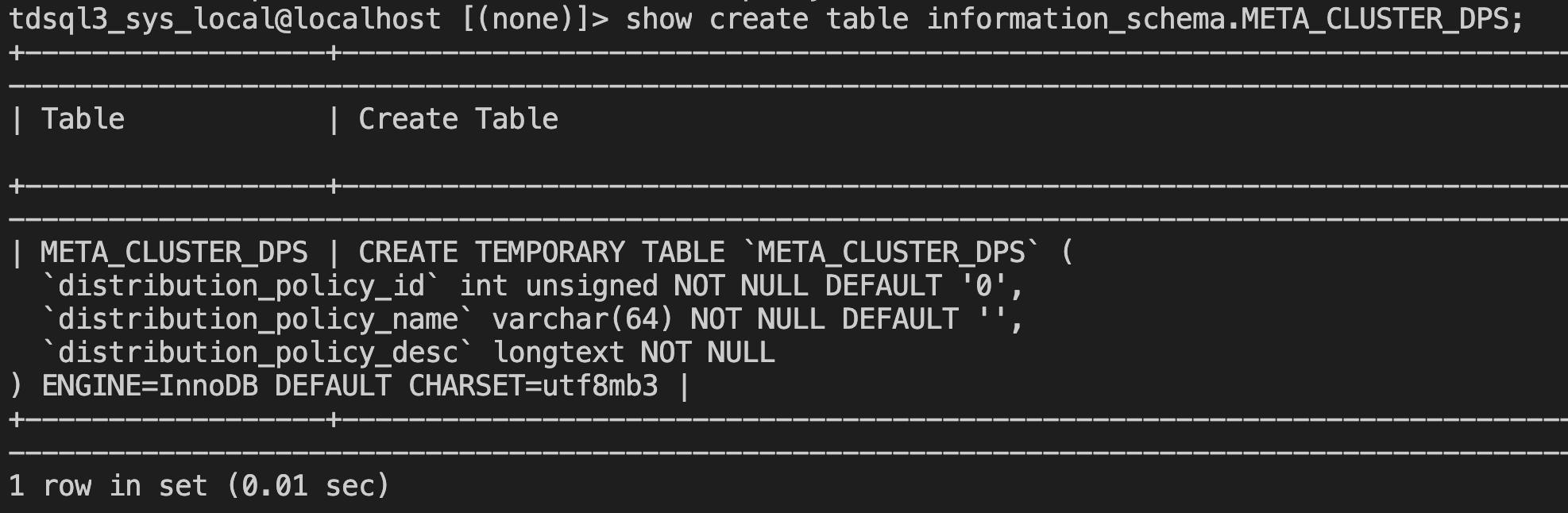
使用该视图可以实时查询已有的 DP。
高级特性
v21.2.3版本提供了一种高级 DP 特性,RANGE 和 RANGE COLUMNS 并以时间类型为分区键的分区表可以绑定该种高级 DP,其效果可以让分区表的部分分区在指定时间后再进行调度,一种典型的场景是自动对分区进行落冷,以下是具体介绍:
使用 SQL 创建如下 DP
CREATE DISTRIBUTION POLICY "policy_x" SET PARTITION_METHOD = "RANGE" ANDPARTITION_KEY_TO_TIME_TYPE = "predefined:TO_DAYS" ANDEXPIRE = "1 YEAR" ANDSTART_TIME = "2024-06-11 00:11:22" ANDEND_TIME = "2025-06-11 00:11:22" ANDSTORAGE_TYPE IN ("HDD");
这条 DP 中的几个关键字解释如下:
PARTITION_METHOD:表示 DP 支持的分区表所对应的分区方式,目前仅支持 RANGE 和 RANGE COLUMNS。PARTITION_KEY_TO_TIME_TYPE:仅在RANGE分区方式时需要指定,用来将分区边界值转换为时间类型。该 key 对应的 values 是转换函数,系统提供了三个预定义的转换函数,即 TO_DAYS, UNIX_TIMESTAMP 和 YEAR。用户也可自定义转换函数,自定义函数需要给出年月日时分秒的计算公式,遵从的格式为:year/month/day/hour/minute/second:(含有标识符 v 的数学公式),其中v是标识符,表示的是分区边界的整型值。如将 values 设置为 ["year:v/100", "month:v%100"],省略的 day/hour/minute/second 则按照对应时间单位的零值处理。EXPIRE:分区过期时间,正整数 + 单位的格式,如 1 YEAR 。可用单位有:YEAR, MONTH, DAY, HOUR。START_TIME:非必选项,默认为分区的起始,如指定这一项,则表示从这个时间之后开始应用 DP 规则。END_TIME:非必选项,默认为分区的结束,如指定这一项,则表示从这个时间之后拒绝应用 DP 规则。注意:
1. 仅支持一级 RANGE 和 RANGE COLUMNS 分区使用相关特性,其分区键也必须是时间类型。
2. RANGE COLUMNS 分区仅支持一个分区列。
案例说明
案例1:基于 UNIX_TIMESTAMP 的自动冷数据归档
# 使用预定义函数UNIX_TIMESTAMP创建policy_x1CREATE DISTRIBUTION POLICY "policy_x1" SET PARTITION_METHOD = "RANGE" ANDPARTITION_KEY_TO_TIME_TYPE = ("predefined:UNIX_TIMESTAMP") ANDEXPIRE = "1 MONTH" ANDSTORAGE_TYPE IN ("HDD");# 创建 RANGE 分区表并绑定 policy_x1CREATE TABLE t_order_1(id bigint NOT NULL,gmt_modified timestamp NOT NULL)PARTITION BY RANGE(unix_timestamp(gmt_modified))(PARTITION p1 VALUES LESS THAN(unix_timestamp('2025-11-11')),PARTITION p2 VALUES LESS THAN(unix_timestamp('2025-12-11'))) USING DISTRIBUTION POLICY policy_x1;
调度行为说明
p1 分区调度:
分区边界时间:2025-11-11
过期时间偏移:1个月
调度触发时间:2025-11-11 + 1个月 = 2025-12-11
调度动作:将 p1 分区的数据副本迁移到 HDD 存储
p2 分区调度:
分区边界时间:2025-12-11
过期时间偏移:1个月
调度触发时间:2025-12-11 + 1个月 = 2026-01-11
调度动作:将 p2 分区的数据副本迁移到 HDD 存储
案例2:自定义时间转换函数的精确调度控制
# 使用自定义函数创建policy_x2CREATE DISTRIBUTION POLICY "policy_x2" SET PARTITION_METHOD = "RANGE" ANDPARTITION_KEY_TO_TIME_TYPE = ("year:v/100", "month:v%100") ANDEXPIRE = "1 MONTH" ANDLEADER_PREFERENCES = (ZONE in ("zone1")) ANDSTART_TIME = "2025-12-10 00:00:00";# 创建 RANGE 分区表并绑定policy_x2CREATE TABLE t_order_2(id bigint NOT NULL,gmt_modified datetime NOT NULL)PARTITION BY RANGE(YEAR(gmt_modified) * 100 + MONTH(gmt_modified))(PARTITION p1 VALUES LESS THAN(202511),PARTITION p2 VALUES LESS THAN(202512),PARTITION p3 VALUES LESS THAN(202601)) USING DISTRIBUTION POLICY policy_x2;
转换函数解析
自定义函数: year:v/100, month:v%100分区边界值 v = YEAR(gmt_modified) * 100 + MONTH(gmt_modified)示例计算:- p1: v=202511 → year=202511/100=2025, month=202511%100=11- p2: v=202512 → year=202512/100=2025, month=202512%100=12- p3: v=202601 → year=202601/100=2026, month=202601%100=1
分区时间边界计算
分区 | 边界值 | 转换后时间 | 调度触发时间 | 是否受约束 |
p1 | 202511 | 2025-11-01 00:00:00 | 2025-12-01 00:00:00 | 不受约束 |
p2 | 202512 | 2025-12-01 00:00:00 | 2026-01-01 00:00:00 | 不受约束 |
p3 | 202601 | 2026-01-01 00:00:00 | 2026-02-01 00:00:00 | 受约束 |
START_TIME 影响分析
START_TIME = "2025-12-10 00:00:00"
只有分区边界时间 ≥ START_TIME 的分区才会应用 DP 约束
p1(2025-11-01) 和 p2(2025-12-01) < START_TIME(2025-12-10) → 不受约束
p3(2026-01-01) > START_TIME(2025-12-10) → 受约束
案例3:RANGE COLUMNS 分区的时间窗口调度
# 创建policy_x3CREATE DISTRIBUTION POLICY "policy_x3" SET PARTITION_METHOD = "RANGE COLUMNS" ANDEXPIRE = "1 YEAR" ANDNODE NOT IN ("node-tdsql3-x-001") ANDSTART_TIME = "2025-12-10 00:00:00" ANDEND_TIME = "2026-12-10 00:00:00";# 创建 RANGE COLUMNS 分区表并绑定policy_x3CREATE TABLE t_order_3(id bigint NOT NULL,gmt_modified datetime NOT NULL)PARTITION BY RANGE COLUMNS(gmt_modified)(PARTITION p1 VALUES LESS THAN("2024-12-10 00:00:00"),PARTITION p2 VALUES LESS THAN("2025-12-10 00:00:00"),PARTITION p3 VALUES LESS THAN("2026-12-10 00:00:00"),PARTITION p4 VALUES LESS THAN("2027-12-10 00:00:00")) USING DISTRIBUTION POLICY policy_x3;
由于是 RANGE COLUMNS 时间分区绑定的 DP,因此不需要使用 PARTITION_KEY_TO_TIME_TYPE 字段给出转换函数,因为此时分区边界已经是时间类型的值了。同时由于指定了 START_TIME 和 END_TIME,因此只有 p2 和 p3 分区会在到达分区边界时间的一年(EXPIRE = "1 YEAR")后发起调度。
分区 | 边界时间 | 调度触发时间 | 是否在时间窗口内 |
p1 | 2024-12-10 | 2025-12-10 | 早于 START_TIME |
p2 | 2025-12-10 | 2026-12-10 | 在 [START_TIME, END_TIME] 内 |
p3 | 2026-12-10 | 2027-12-10 | 在 [START_TIME, END_TIME] 内 |
p4 | 2027-12-10 | 2028-12-10 | 晚于 END_TIME |



