本文档详细介绍 TDSQL Boundless 的分布式事务实现原理,以及数据亲和性调度如何优化事务性能。
分布式事务原理
事务模型概览
分布式事务设计旨在同时保证正确性与高效性。TDSQL Boundless 对事务的读写和提交链路进行了全面优化。
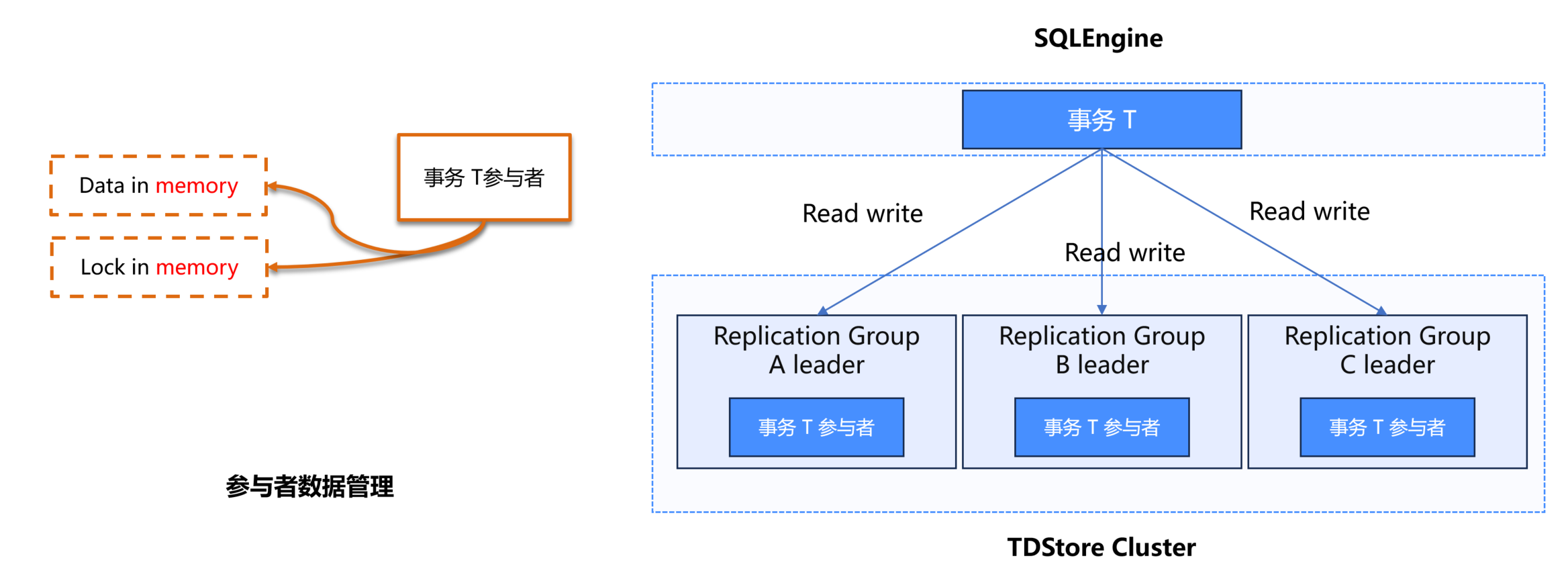
读写阶段
参与者管理机制
复制组为单位:以 Replication Group 为基本单位管理事务参与者
自动创建上下文:当事务访问特定复制组数据时,自动创建对应的参与者上下文
分散缓存:SQLEngine 层不缓存事务数据,由 TDStore 实现分散缓存
事务执行流程
1.
获取读时间戳:事务执行第一条语句时,从 MC 获取时间戳作为读快照
2.
读写操作:访问数据对应的 Replication Group 的 Leader 副本,在该副本上创建参与者上下文
3.
事务提交:选择其中一个参与者担任协调者,向协调者发送提交请求
数据缓存机制
特性 | 说明 |
提交前缓存 | 事务数据在提交前完全缓存在内存中 |
SQLEngine 不缓存 | SQLEngine 层不缓存事务数据 |
分散缓存 | 由 TDStore 实现分散缓存 |
提交时持久化 | 仅在事务提交阶段进行数据持久化操作 |
提交阶段
2PC 下沉
TDSQL Boundless 将 2PC 的实现完全下沉到 TDStore 层,SQLEngine 不感知事务提交流程。
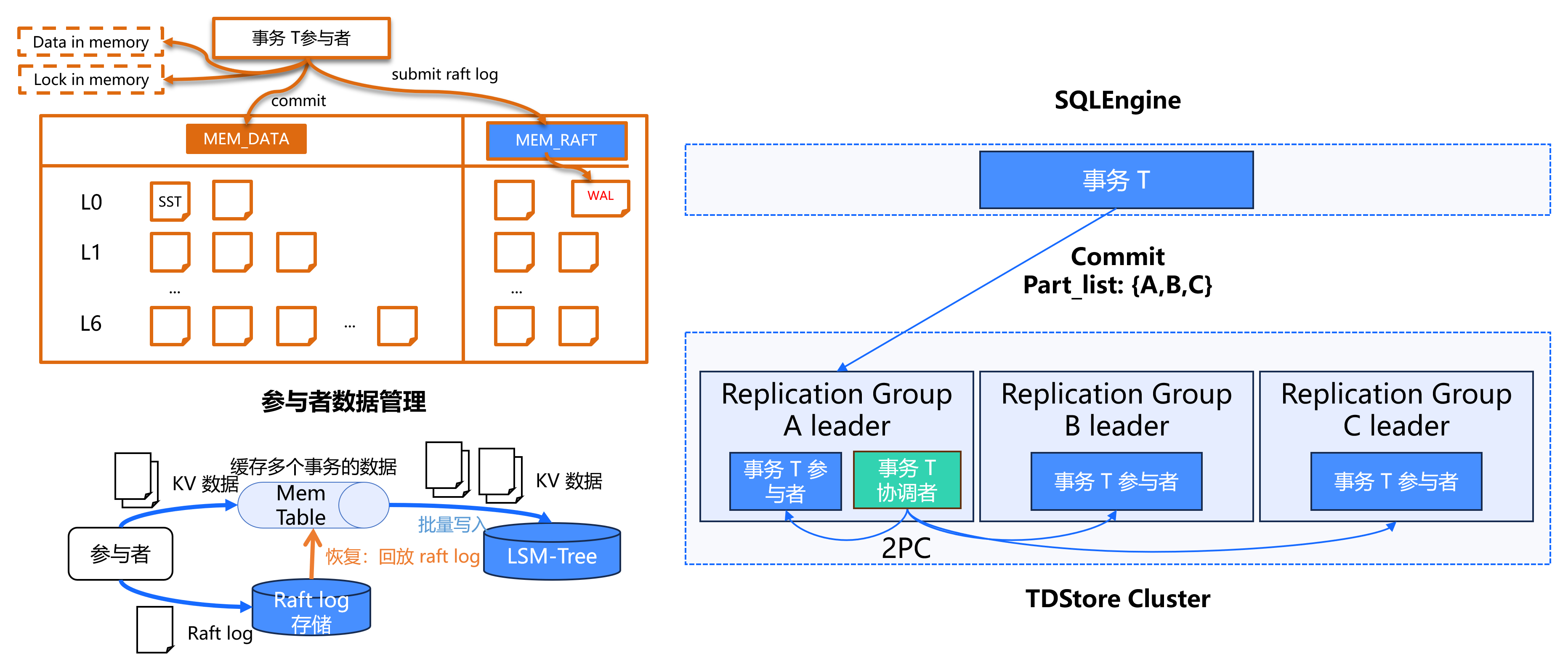
提交流程:
1.
SQLEngine 提交分布式事务,从参与者中选取一个节点作为协调者
2.
向选定的参与者节点发送提交请求,请求中包含事务涉及的所有参与者列表
3.
接收请求的节点在其复制组内创建协调者上下文
4.
协调者负责向其他参与者发送读写请求,推进完整的 2PC 流程
数据持久化
TDStore 直接使用 Raft log 作为 WAL 日志,数据写入 LSM-Tree 不需要额外写 WAL 日志:
1.
节点重启时从上一记录点回放 Raft Log
2.
数据刷新到磁盘后推进日志点,减少宕机时需回放的日志量
3.
通过单一 Log 实现备机数据同步和故障恢复双重功能
日志式 vs 协商式 2PC
TDSQL Boundless 采用协商式 2PC,相比传统日志式 2PC 具有显著优势:
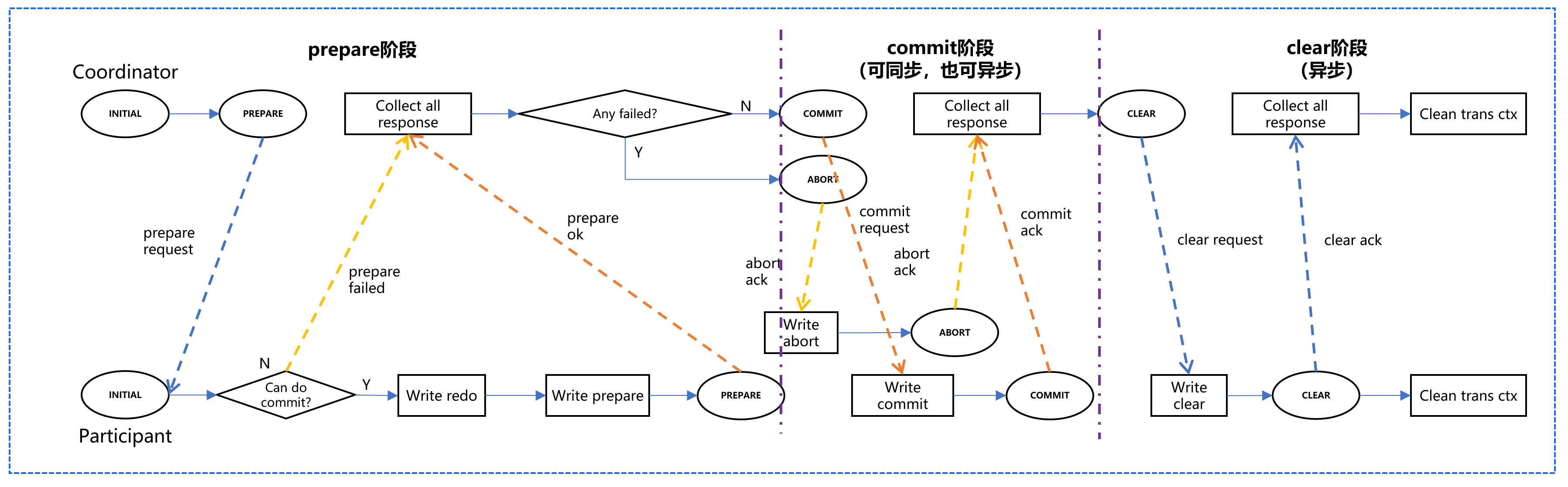
对比项 | 日志式 2PC | 协商式 2PC (TDSQL Boundless) |
RPC 轮数 | 2轮 (prepare、commit) | 3轮 (prepare、commit、clear 异步) |
日志同步次数 | 参与者2次 + 协调者3次 = 5次 | 参与者同步3次(含1次异步) |
故障处理 | 宕机重启,参与者/协调者回放本地日志即可确定状态 | 宕机重启,参与者回放本地日志即可确定状态;协调者需要通过参与者发送的消息确定状态 |
核心优势:
使用协商式 2PC 避免协调者同步日志带来的开销
保证跨 Replication Group 事务的原子性
日志同步次数从5次降低到3次
数据亲和性调度
亲和性定义
数据亲和性:数据之间存在相关性,例如:
表内部的主键和二级索引
不同表之间的连接键
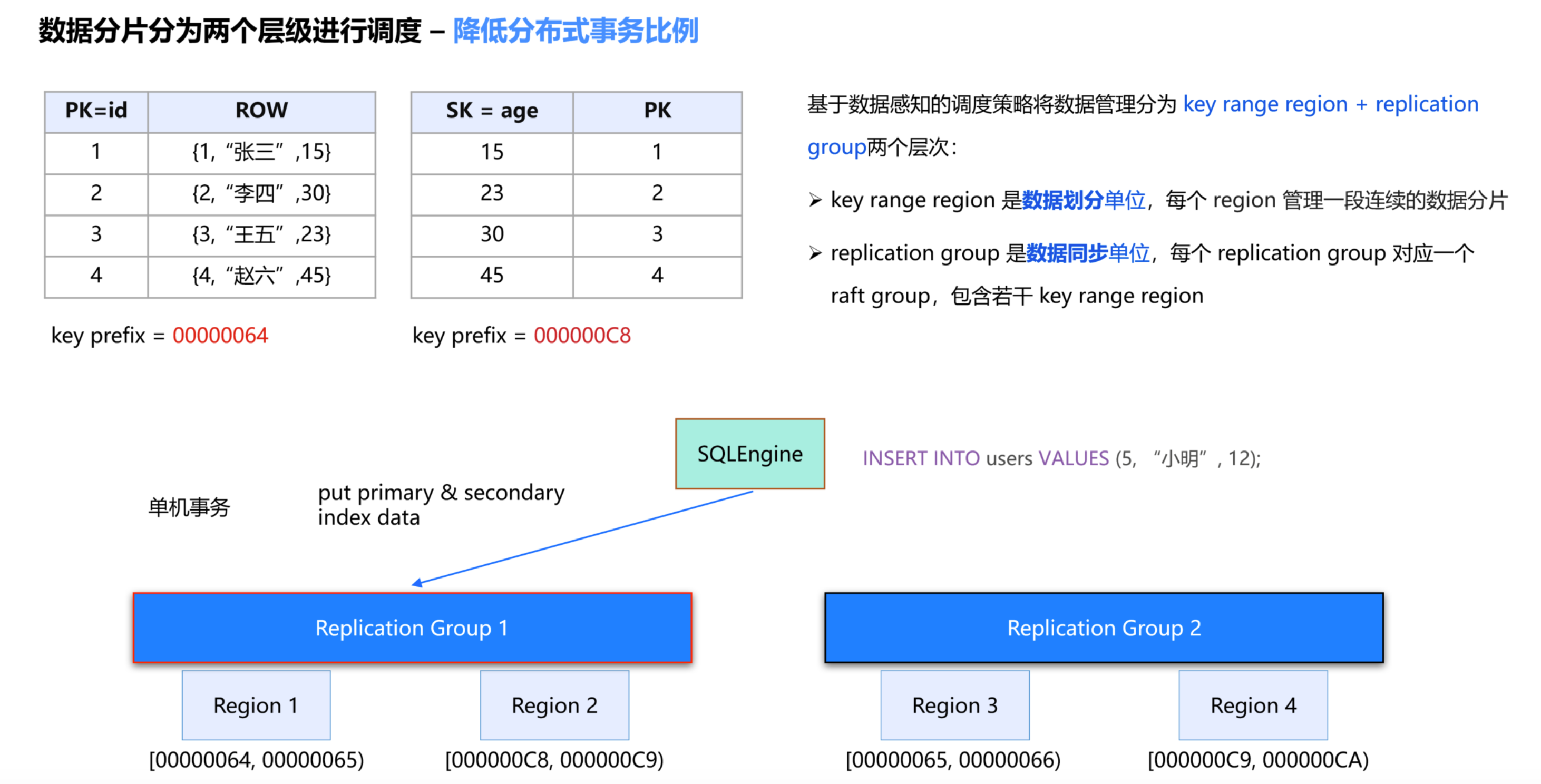
将相关的数据调度到同一个复制组,可以进行事务优化。
典型案例:表内亲和
场景:用户创建包含 ID、姓名、年龄的表,并在年龄列创建二级索引。
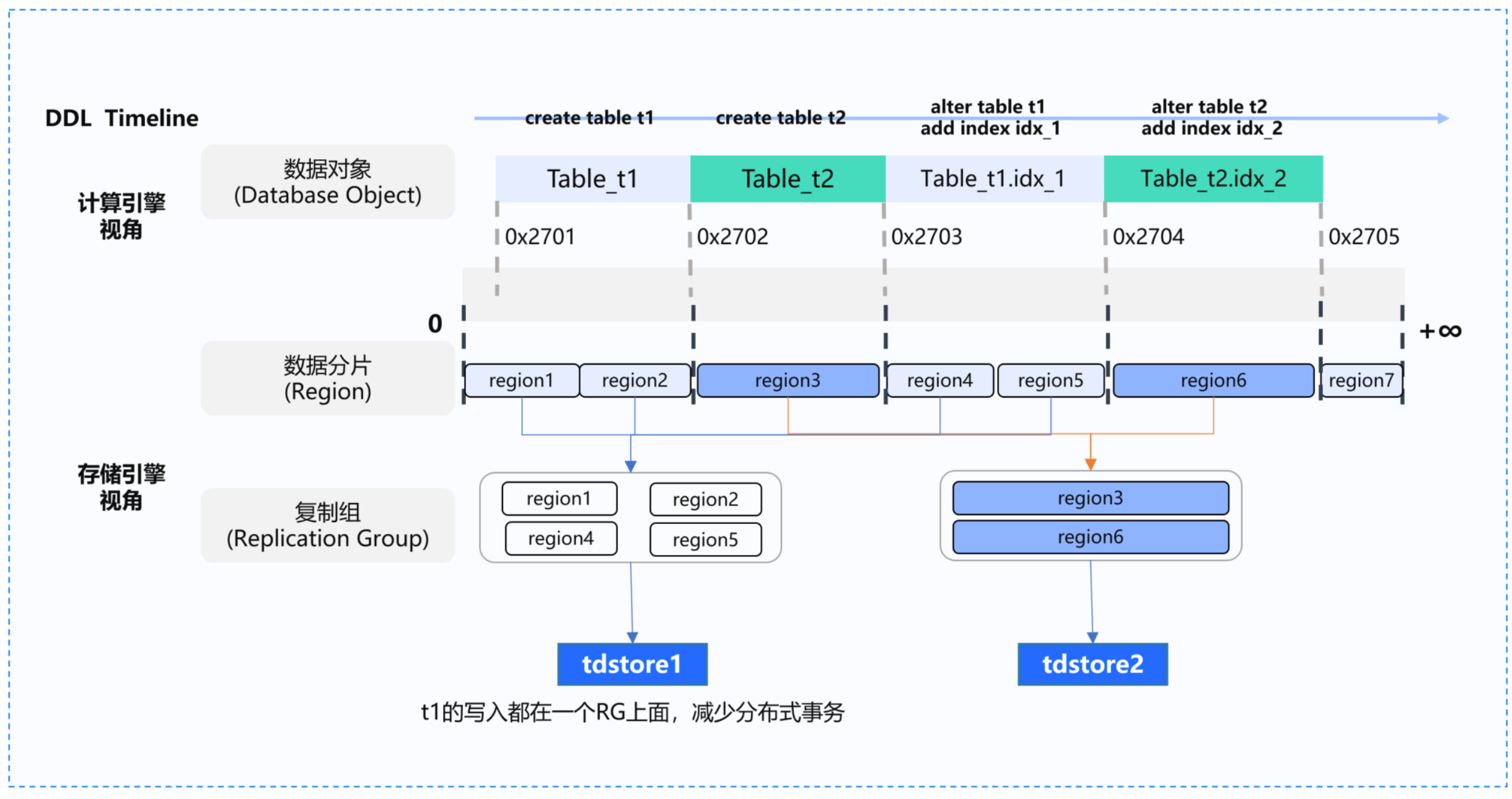
传统方案的问题:
主键索引和二级索引 key 范围相距较远
必须通过 2PC 完成分布式事务
事务执行效率显著低于单机事务
TDSQL Boundless 优化方案:
将关联数据(主键与二级索引)置于同一复制组
查询读写只需向目标复制组发送请求
事务提交只需与单个复制组交互
通过 1PC 协议极大提升事务处理效率
基于数据感知的调度
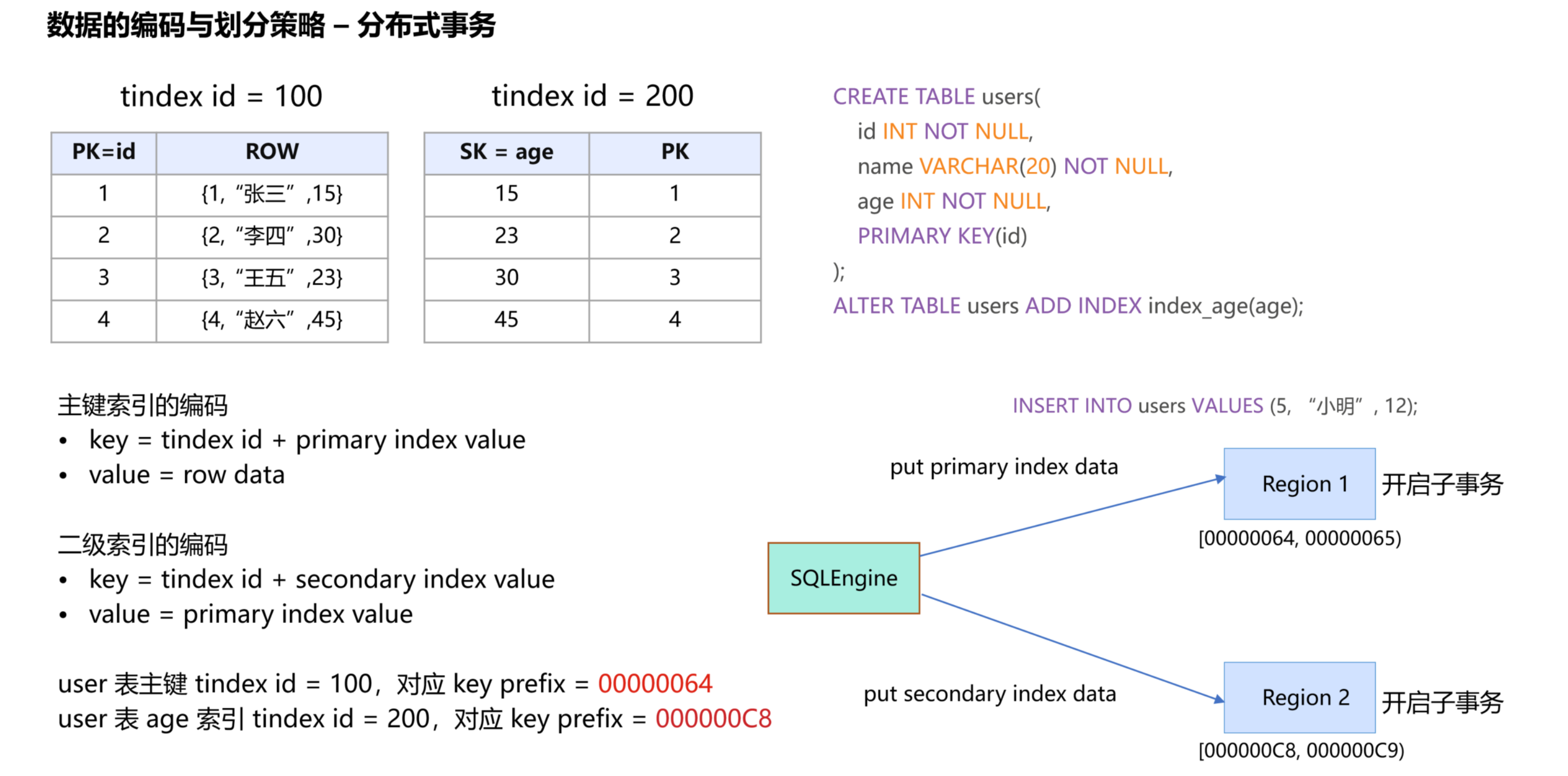
典型案例分析:
1.
用户创建包含 ID、姓名、年龄的表(表 ID 为100)
2.
在年龄列创建二级索引(索引表 ID 为200)
3.
主键索引 key 前缀为00000064,二级索引 key 前缀000000C8,两者 key 范围相距较远
典型案例:跨表亲和
场景:小数据量商户余额账户表与大数据量商户流水账户表共存。
数据增长处理流程:
1.
初始状态:两表共存于同一节点
2.
数据增长:表开始自动分裂 Region(速度不同)
3.
确保相关性:对 Table 2 的 Region 进行自动分裂,将复制组也做分裂
4. 数据范围对齐:RG1管理数据范围0-5,RG2管理数据范围5-9
5. 负载增加时:RG2迁移至其它节点,实现数据拆分同时保证亲和性
亲和性收益总结
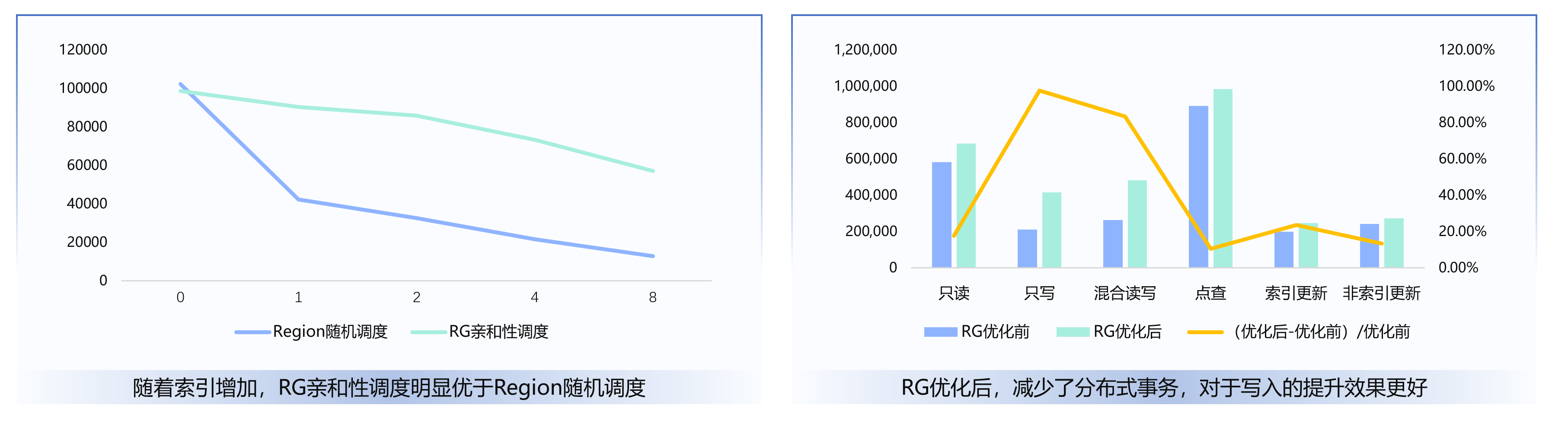
收益 | 说明 |
数据本地化 | 经常被共同操作的数据存放在同一节点 |
减少 RPC | 读写涉及更少的数据移动和 RPC 调用 |
避免分布式事务 | 单复制组内操作无需 2PC |
大幅提升性能 | 显著降低延迟和网络开销 |



