数据导出(Export)是 Doris 提供的一种将数据导出的功能。该功能可以将用户指定的表或分区的数据,以文本的格式,通过 Broker 进程导出到远端存储上,如 HDFS/BOS 等。本文档主要介绍 Export 的基本原理、使用方式、实践教程以及注意事项。
名词解释
FE:Frontend,Doris 的前端节点。负责元数据管理和请求接入。
BE:Backend,Doris 的后端节点。负责查询执行和数据存储。
Broker:Doris 可以通过 Broker 进程对远端存储进行文件操作。
Tablet:数据分片。一个表会划分成多个数据分片。
原理
用户提交一个 Export 作业后。Doris 会统计这个作业涉及的所有 Tablet。然后对这些 Tablet 进行分组,每组生成一个特殊的查询计划。该查询计划会读取所包含的 Tablet 上的数据,然后通过 Broker 将数据写到远端存储指定的路径中,也可以通过S3协议直接导出到支持S3协议的远端存储上。
总体的调度方式如下:
+--------+| Client |+---+----+| 1. Submit Job|+---v--------------------+| FE || || +-------------------+ || | ExportPendingTask | || +-------------------+ || | 2. Generate Tasks| +--------------------+ || | ExportExporingTask | || +--------------------+ || || +-----------+ | +----+ +------+ +---------+| | QueryPlan +----------------> BE +--->Broker+---> || +-----------+ | +----+ +------+ | Remote || +-----------+ | +----+ +------+ | Storage || | QueryPlan +----------------> BE +--->Broker+---> || +-----------+ | +----+ +------+ +---------++------------------------+ 3. Execute Tasks
1. 用户提交一个 Export 作业到 FE。
2. FE 的 Export 调度器会通过两阶段来执行一个 Export 作业:
PENDING:FE 生成 ExportPendingTask,向 BE 发送 snapshot 命令,对所有涉及到的 Tablet 做一个快照。并生成多个查询计划。
EXPORTING:FE 生成 ExportExportingTask,开始执行查询计划。
查询计划拆分
Export 作业会生成多个查询计划,每个查询计划负责扫描一部分 Tablet。每个查询计划扫描的 Tablet 个数由 FE 配置参数
export_tablet_num_per_task 指定,默认为 5。即假设一共 100 个 Tablet,则会生成 20 个查询计划。用户也可以在提交作业时,通过作业属性 tablet_num_per_task 指定这个数值。
一个作业的多个查询计划顺序执行。 查询计划执行
一个查询计划扫描多个分片,将读取的数据以行的形式组织,每 1024 行为一个 batch,调用 Broker 写入到远端存储上。
查询计划遇到错误会整体自动重试 3 次。如果一个查询计划重试 3 次依然失败,则整个作业失败。
Doris 会首先在指定的远端存储的路径中,建立一个名为
__doris_export_tmp_12345 的临时目录(其中 12345 为作业 id)。导出的数据首先会写入这个临时目录。每个查询计划会- 生成一个文件,文件名示例:export-data-c69fcf2b6db5420f-a96b94c1ff8bccef-1561453713822。其中 c69fcf2b6db5420f-a96b94c1ff8bccef 为查询计划的 query id。1561453713822 为文件生成的时间戳。当所有数据都导出后,Doris 会将这些文件 rename 到用户指定的路径中。
Broker 参数
Export 需要借助 Broker 进程访问远端存储,不同的 Broker 需要提供不同的参数。
开始导出
导出到 HDFS
EXPORT TABLE db1.tbl1PARTITION (p1,p2)[WHERE [expr]]TO "hdfs://host/path/to/export/"PROPERTIES("label" = "mylabel","column_separator"=",","columns" = "col1,col2","exec_mem_limit"="2147483648","timeout" = "3600")WITH BROKER "hdfs"("username" = "user","password" = "*******");
label:本次导出作业的标识。后续可以使用这个标识查看作业状态。column_separator:列分隔符。默认为 \\t。支持不可见字符,例如 '\\x07'。columns:要导出的列,使用英文状态逗号隔开,如果不填这个参数默认是导出表的所有列。line_delimiter:行分隔符。默认为 \\n。支持不可见字符,例如 '\\x07'。exec_mem_limit: 表示 Export 作业中,一个查询计划在单个 BE 上的内存使用限制。默认 2GB。单位字节。timeout:作业超时时间。默认 2小时。单位秒。tablet_num_per_task:每个查询计划分配的最大分片数。默认为 5。导出到对象存储
直接导出到云存储,而不通过broker。
EXPORT TABLE db.tableTO "s3://your_bucket/xx_path"PROPERTIES("label"="your_label","line_delimiter"="\\n","column_separator"="\\001",)WITH S3("AWS_ENDPOINT" = "http://cos.ap-beijing.myqcloud.com","AWS_ACCESS_KEY" = "********","AWS_SECRET_KEY"="*******","AWS_REGION"="AWS_REGION");
AWS_ACCESS_KEY/AWS_SECRET_KEY:是您访问 OSS API 的密钥。AWS_ENDPOINT:表示 OSS 的数据中心所在的地域。AWS_REGION:Endpoint 表示 OSS 对外服务的访问域名。查看导出状态
提交作业后,可以通过 SHOW EXPOR 命令查询导入作业状态。结果举例如下:
mysql> show EXPORT\\G;*************************** 1. row ***************************JobId: 14008State: FINISHEDProgress: 100%TaskInfo: {"partitions":["*"],"exec mem limit":2147483648,"column separator":",","line delimiter":"\\n","tablet num":1,"broker":"hdfs","coord num":1,"db":"default_cluster:db1","tbl":"tbl3"}Path: hdfs://host/path/to/export/CreateTime: 2019-06-25 17:08:24StartTime: 2019-06-25 17:08:28FinishTime: 2019-06-25 17:08:34Timeout: 3600ErrorMsg: NULL1 row in set (0.01 sec)
JobId:作业的唯一 ID。
Label:自定义作业标识。
State:作业状态:
PENDING:作业待调度。
EXPORTING:数据导出中。
FINISHED:作业成功。
CANCELLED:作业失败。
Progress:作业进度。该进度以查询计划为单位。假设一共 10 个查询计划,当前已完成 3 个,则进度为 30%。
TaskInfo:以 Json 格式展示的作业信息:
db:数据库名。
tbl:表名。
partitions:指定导出的分区。
* 表示所有分区。exec mem limit:查询计划内存使用限制。单位字节。
column separator:导出文件的列分隔符。
line delimiter:导出文件的行分隔符。
tablet num:涉及的总 Tablet 数量。
broker:使用的 broker 的名称。
coord num:查询计划的个数。
Path:远端存储上的导出路径。
CreateTime/StartTime/FinishTime:作业的创建时间、开始调度时间和结束时间。
Timeout:作业超时时间。单位是秒。该时间从 CreateTime 开始计算。
ErrorMsg:如果作业出现错误,这里会显示错误原因。
实践教程
查询计划的拆分
一个 Export 作业有多少查询计划需要执行,取决于总共有多少 Tablet,以及一个查询计划最多可以分配多少个 Tablet。因为多个查询计划是串行执行的,所以如果让一个查询计划处理更多的分片,则可以减少作业的执行时间。但如果查询计划出错(例如调用 Broker 的 RPC 失败,远端存储出现抖动等),过多的 Tablet 会导致一个查询计划的重试成本变高。所以需要合理安排查询计划的个数以及每个查询计划所需要扫描的分片数,在执行时间和执行成功率之间做出平衡。一般建议一个查询计划扫描的数据量在 3-5 GB内(一个表的 Tablet 的大小以及个数可以通过
SHOW TABLET FROM tbl_name; 语句查看)。exec_mem_limit
通常一个 Export 作业的查询计划只有
扫描-导出 两部分,不涉及需要太多内存的计算逻辑。所以通常 2GB 的默认内存限制可以满足需求。但在某些场景下,例如一个查询计划,在同一个 BE 上需要扫描的 Tablet 过多,或者 Tablet 的数据版本过多时,可能会导致内存不足。此时需要通过这个参数设置更大的内存,例如 4GB、8GB 等。EXPORT 到腾讯云 COS
COS 域名获取
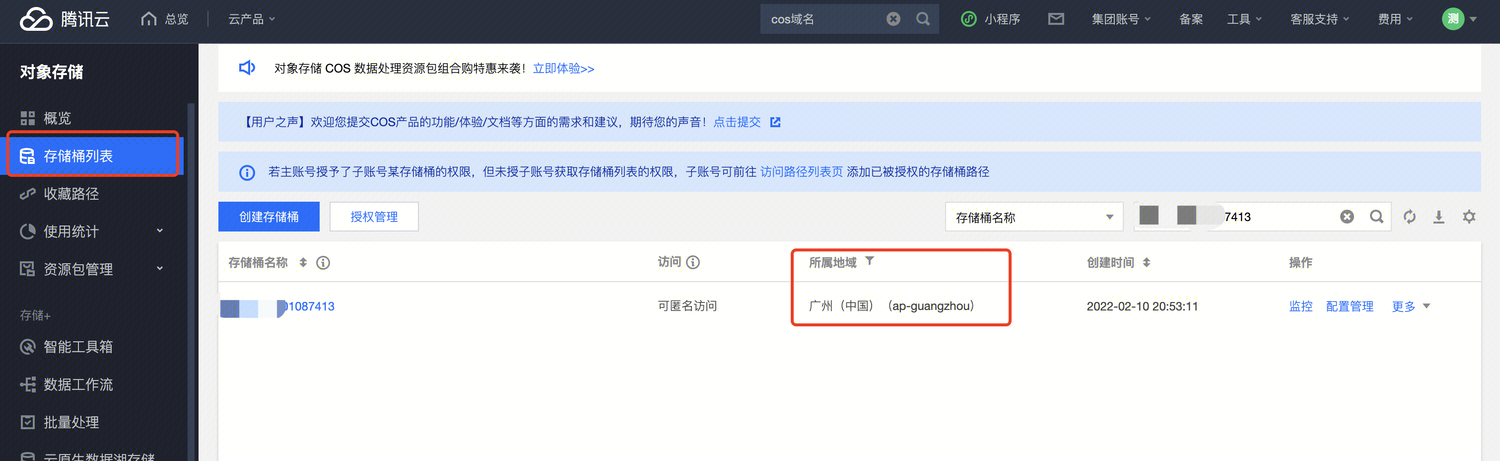
使用 EXPORT 语句时,需要指定 AWS_ENDPOINT 参数,这里即是 cos 的域名地址,格式为:
https://cos.[region_id].myqcloud.com
其中 region_id 为 cos 所属地域名称,例如上图中的:ap-guangzhou,其他字段不变。
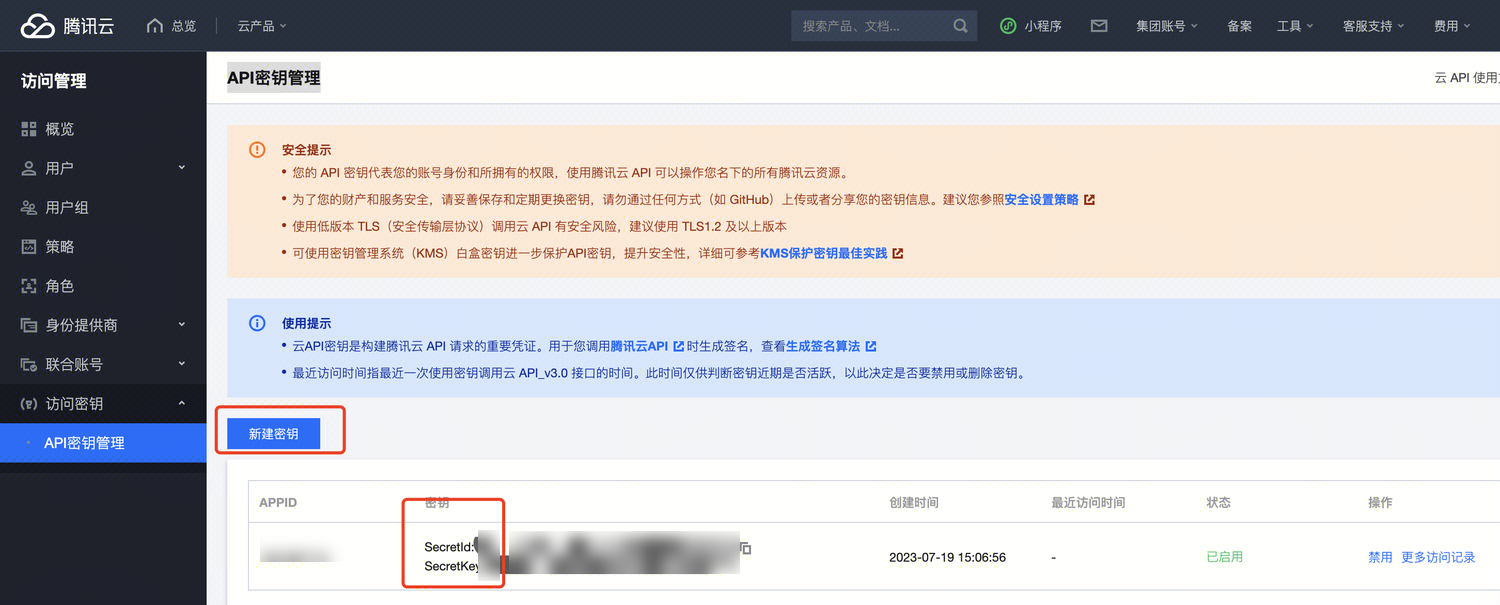
COS 的 SecretId 和 SecretKey 获取
COS 的 SecretId 对应 S3 协议的 ACCESS_KEY,COS 的 SecretKey 对应 S3 协议的 SECRET_KEY,其中 COS 的 SecretId 和 SecretKey 获取需要从腾讯云 API 密钥管理获取如有现成密钥可以直接使用,如果没有则创建密钥。
开启导出任务
根据上面拿到的信息,可以创建 EXPORT 任务。这里以导出一个62G包含6亿行数据的 lineitem 表为例子。
EXPORT TABLE lineitem TO "s3://doris-1301087413/doris-export/export_test"WITH s3 ("AWS_ENDPOINT" = "https://cos.ap-guangzhou.myqcloud.com","AWS_ACCESS_KEY" = "*********","AWS_SECRET_KEY"="*********","AWS_REGION" = "ap-guangzhou");
其中,s3://doris-1301087413/doris-export/export_test 中。
s3是固定前缀,告知 doris 目标指定。
doris-1301087413为 cos 存储桶。
/doris-export/export_test 为指定导出位置的路径,如果路径不存在,doris 会自动创建。
"AWS_ENDPOINT" = "https://cos.ap-guangzhou.myqcloud.com" 是根据存储桶地域填写的 cos 服务器域名。
"AWS_REGION" = "ap-guangzhou" 是存储桶地域。
查看导出任务进度和信息
通过 show export; 命令可以查看 export 任务的进度和报错信息。

关注 State 和 Progress 字段,如果任务失败,ErrorMsg 字段会有对应的报错信息。
COS 数据文件导入到 DORIS
导入指令:
LOAD LABEL test_db.exmpale_label_4(DATA INFILE("s3://doris-1301087413/doris-export/export_test/*")INTO TABLE test_tb COLUMNS TERMINATED BY "\\t")WITH S3("AWS_ENDPOINT" = "https://cos.ap-guangzhou.myqcloud.com","AWS_ACCESS_KEY" = "******","AWS_SECRET_KEY"="******","AWS_REGION" = "ap-guangzhou")PROPERTIES("timeout" = "7600");
其中:
LABEL test_db.exmpale_label_4:test_db 为导入 db 名称。
exmpale_label_4为本次导入的标签,唯一标记一次导入任务 DATA INFILE("s3://doris-1301087413/doris-export/export_test/*") :doris-1301087413/doris-export/export_test/ 为导入文件路径。
* 代表导入该路径下的所有文件都进行导入,也可以指定唯一文件名称。
EXPORT到腾讯云EMR的HDFS
网络确认
确认 Doris 集群与 EMR 集群在同一个 VPC 网络下。
创建导出任务
EXPORT TABLE orders TO "hdfs://hdfs_ip:hdfs_port/your_path"PROPERTIES ("column_separator"="\\t","line_delimiter" = "\\n")WITH BROKER "Broker_Doris" ("username"="******","password"="******")
其中:
Broker_Doris:Broker_Doris 为腾讯云 Doris 中 Broker 默认名称,无需修改。
username:访问 HDFS 的用户名。
password:访问 HDFS 的密码。
查看导出任务状态
通过 show export; 命令可以查看 export 任务的进度和报错信息。
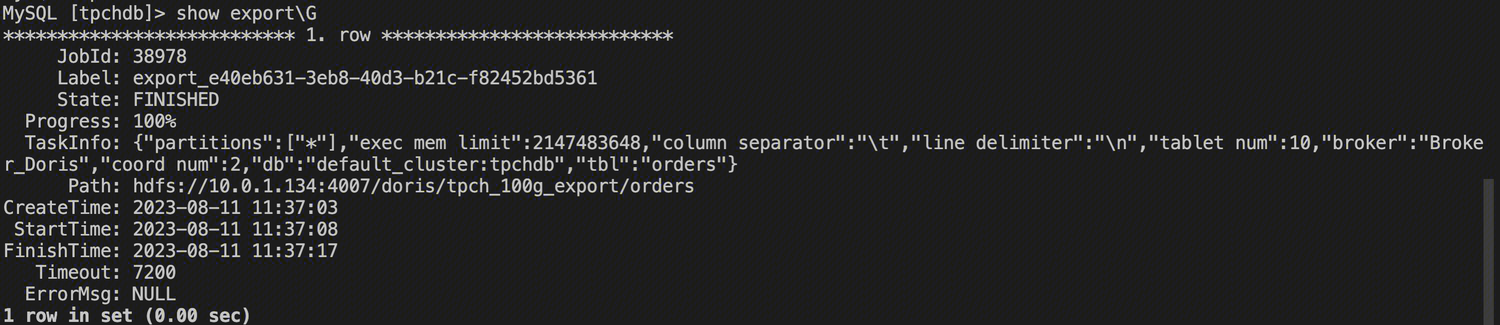
关注 State 和 Progress 字段,如果任务失败,ErrorMsg 字段会有对应的报错信息。
腾讯云 EMR 的 HDFS 导入 Doris
导入指令:
LOAD LABEL tpchdb.load_orders_recover(DATA INFILE("hdfs://hdfs_ip:hdfs_port/your_path/*")INTO TABLE orders_recoverCOLUMNS TERMINATED BY "\\t")WITH BROKER "Broker_Doris"("username" = "*****","password" = "*****")PROPERTIES("timeout"="1200","max_filter_ratio"="0.1");
其中:
LABEL tpchdb.load_orders_recover:tpchdb 为导入 db 名称
load_orders_recover 为本次导入的标签。
DATA INFILE("hdfs://hdfs_ip:hdfs_port/your_path/*") :hdfs://hdfs_ip:hdfs_port/your_path/* 为导入文件路径。
* 代表导入该路径下的所有文件都进行导入,也可以指定唯一文件名称。
常见问题
导入报错 Scan byte per file scanner exceed limit:xxxxx
发现:show load 命令可以查看导入任务运行状态,ErrorMsg 展示报错信息。
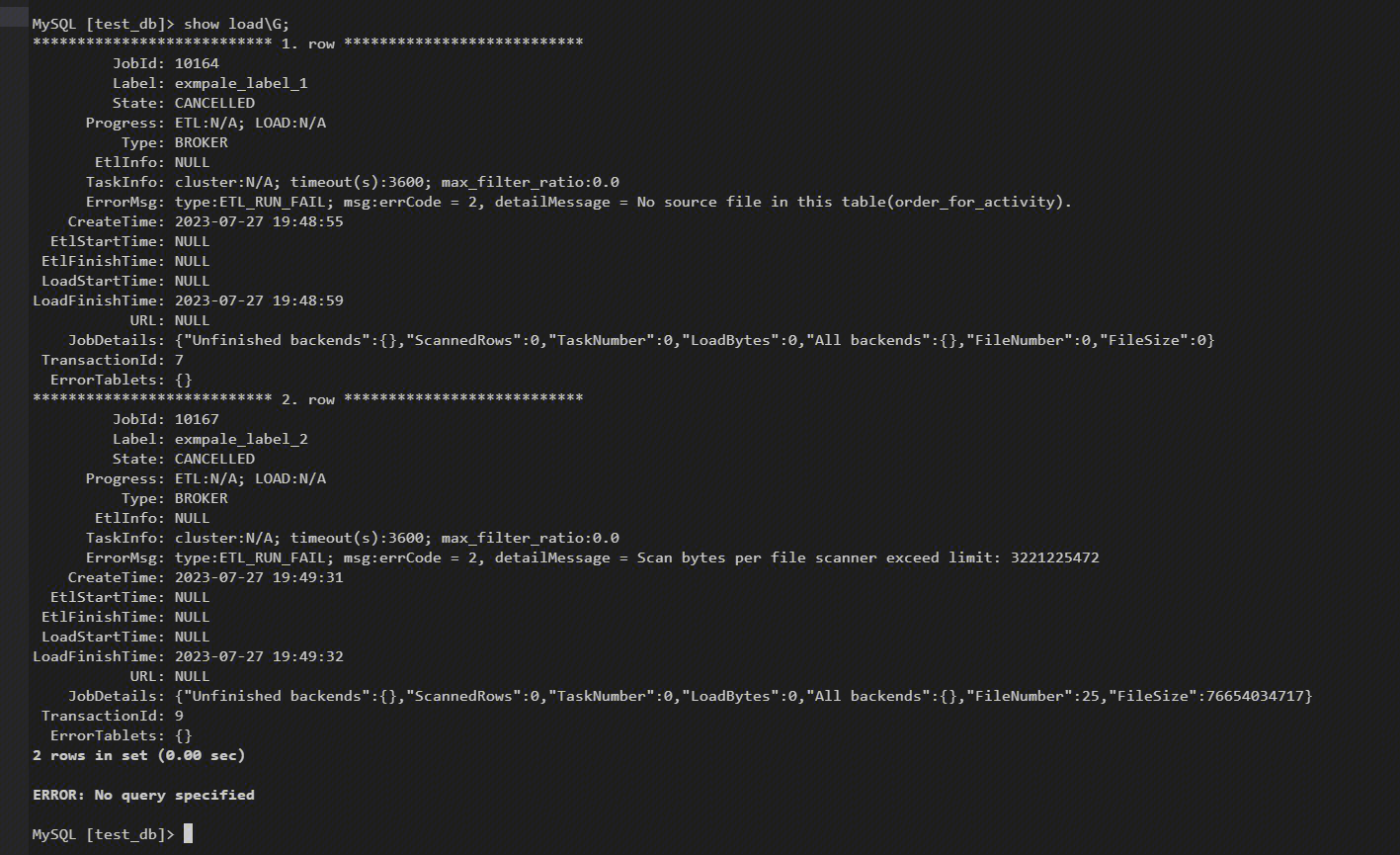
原因:导入文件大小超过集群设置的最大值。
解决:修改 fe.conf 中配置max_broker_concurrency = BE 个数当前导入任务单个 BE 处理的数据量 = 原始文件大小 /max_broker_concurrencymax_bytes_per_broker_scanner >= 当前导入任务单个 BE 处理的数据量
设置方式:
ADMIN SET FRONTEND CONFIG ("max_bytes_per_broker_scanner" = "52949672960");ADMIN SET FRONTEND CONFIG ("max_broker_concurrency" = "3");
注意事项
不建议一次性导出大量数据。一个 Export 作业建议的导出数据量最大在几十 GB。过大的导出会导致更多的垃圾文件和更高的重试成本。
如果表数据量过大,建议按照分区导出。
在 Export 作业运行过程中,如果 FE 发生重启或切主,则 Export 作业会失败,需要用户重新提交。
如果 Export 作业运行失败,在远端存储中产生的
__doris_export_tmp_xxx 临时目录,以及已经生成的文件不会被删除,需要用户手动删除。如果 Export 作业运行成功,在远端存储中产生的
__doris_export_tmp_xxx 目录,根据远端存储的文件系统语义,可能会保留,也可能会被清除。例如在百度对象存储(BOS)中,通过 rename 操作将一个目录中的最后一个文件移走后,该目录也会被删除。如果该目录没有被清除,用户可以手动清除。当 Export 运行完成后(成功或失败),FE 发生重启或切主,则
SHOW EXPORT 展示的作业的部分信息会丢失,无法查看。Export 作业只会导出 Base 表的数据,不会导出 Rollup Index 的数据。
Export 作业会扫描数据,占用 IO 资源,可能会影响系统的查询延迟。
相关配置
FE
export_checker_interval_second:Export 作业调度器的调度间隔,默认为 5 秒。设置该参数需重启 FE。export_running_job_num_limit:正在运行的 Export 作业数量限制。如果超过,则作业将等待并处于 PENDING 状态。默认为 5,可以运行时调整。export_task_default_timeout_second:Export 作业默认超时时间。默认为 2 小时。可以运行时调整。export_tablet_num_per_task:一个查询计划负责的最大分片数。默认为 5。


