为了提升用户在使用 Prometheus 监控采集功能时的体验,Prometheus 监控团队特推出了新的采集架构,且为用户提供了名为实例诊断的控制台页面。此功能有助于用户对当前 Prometheus 实例采集和存储功能的运行情况有更加细致的了解,并在出现问题时可以更加快速地定位和排查。
说明:
问题一:采集组件升级
现象
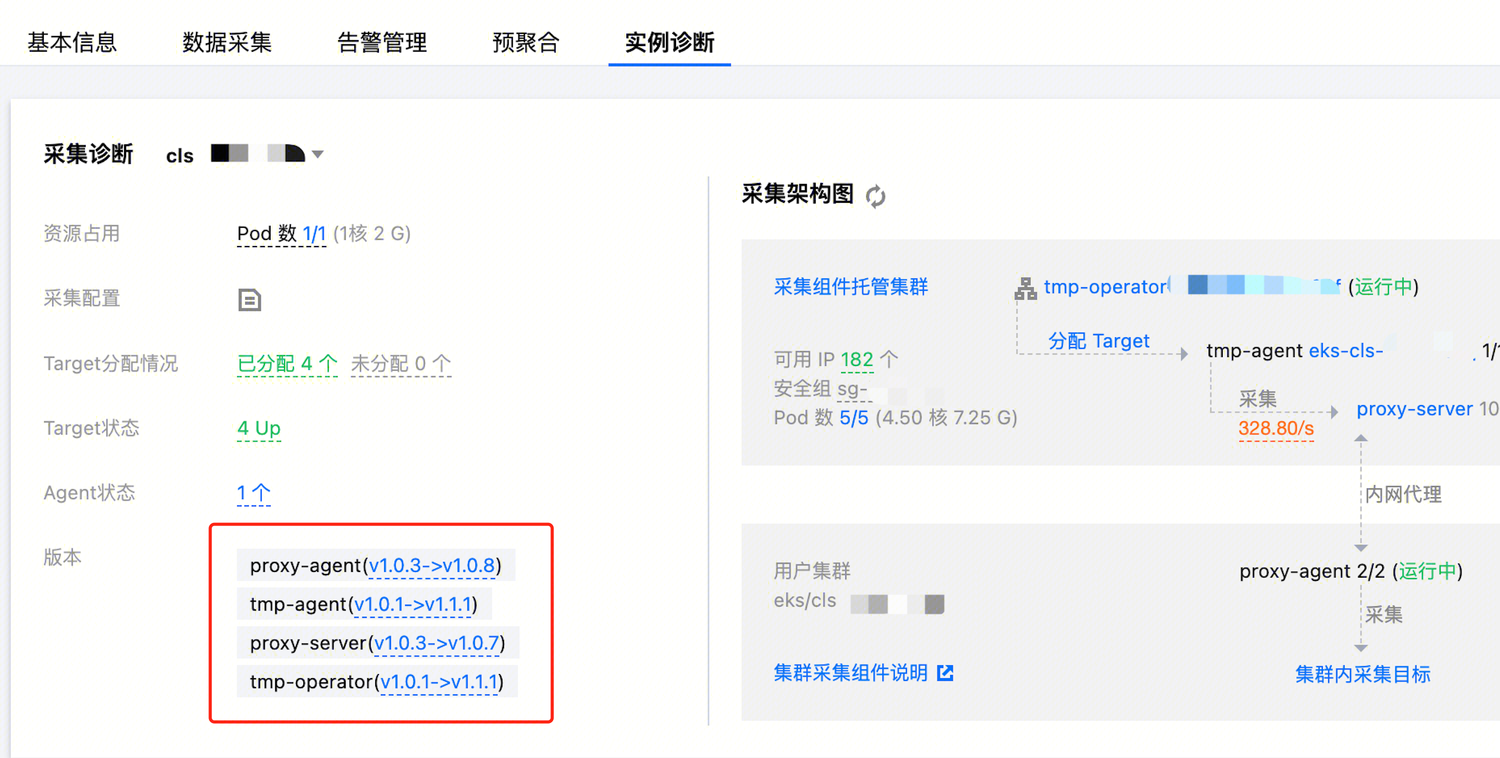
实例诊断页面中,提示采集组件有新版本可升级。
解释和处理
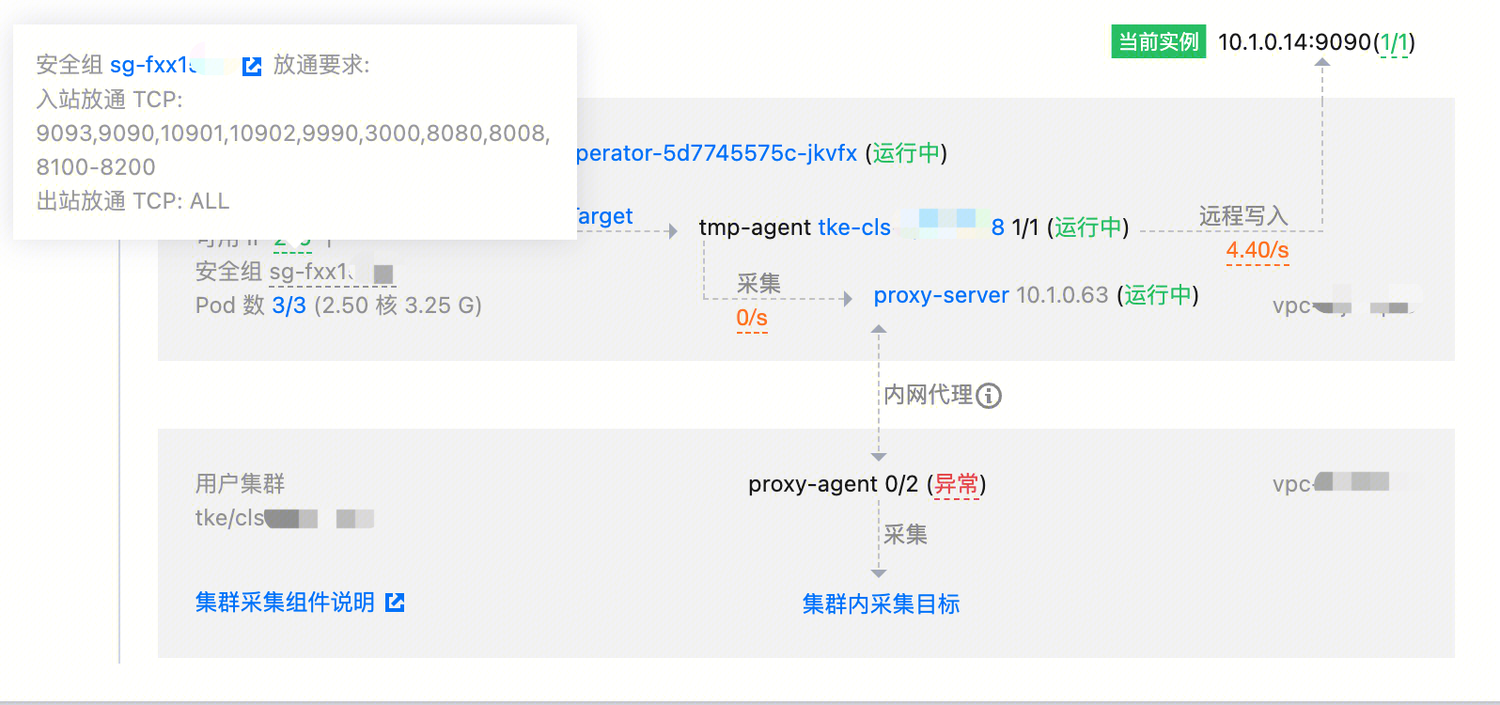
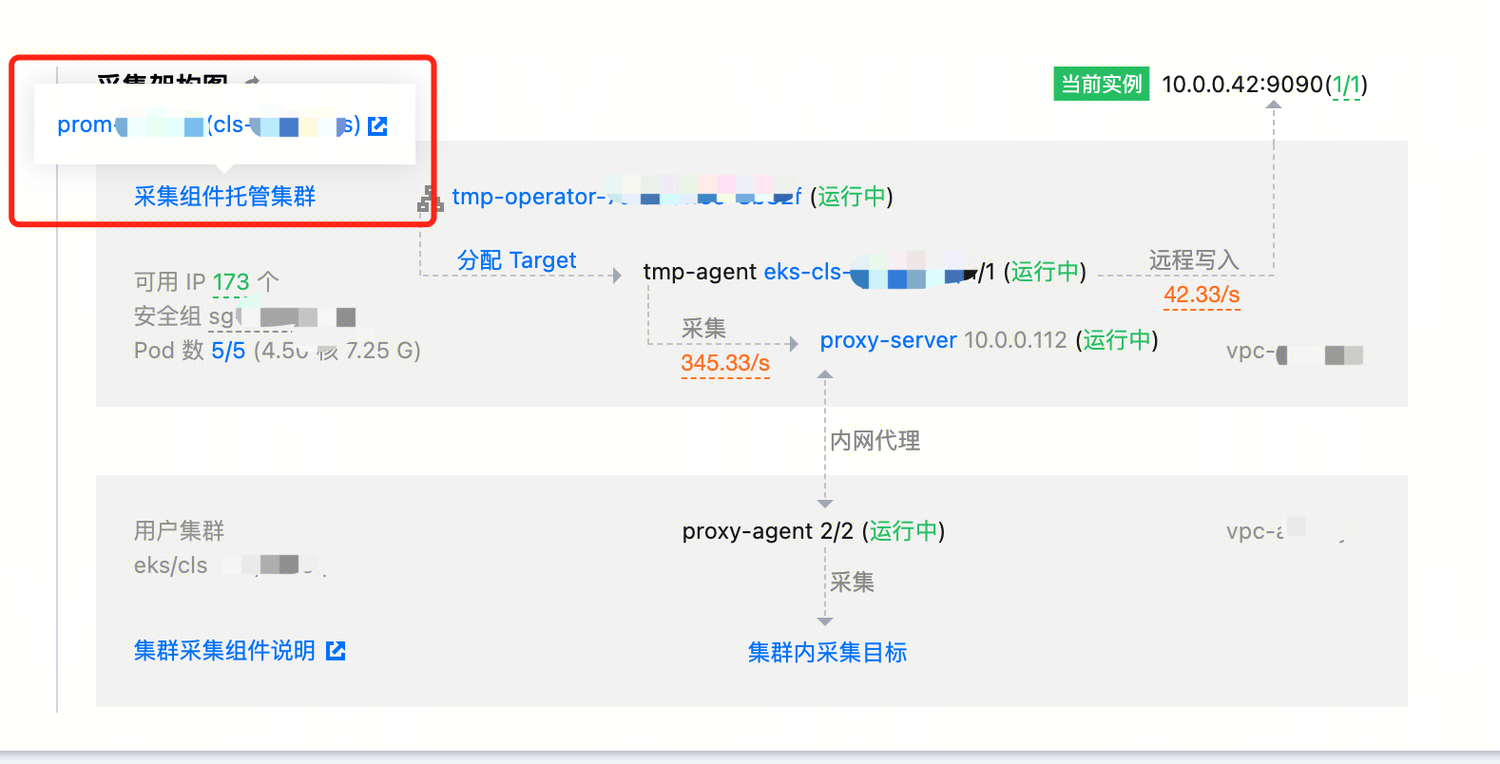
Prometheus 采集端主要包含四个组件,用来实现采集目标的发现和调度、采集操作的进行、采集集群和用户集群之间的通信等功能:
tmp-operator: 负责采集目标的发现和调度,以及采集分片 tmp-agent 的安装和配置生成,并以集群化的形式管理所有采集分片。
tmp-agent: 负责实施实际的采集操作,并将处理后的指标推送到指定的远端地址。
proxy-server: 为采集组件访问用户集群提供代理功能,是通过多个端口实现多路代理的七层代理器,支持多个 agent 连接同一个 server。
proxy-agent: 与 proxy-server 共同提供完整的代理功能,该组件安装在用户集群中。
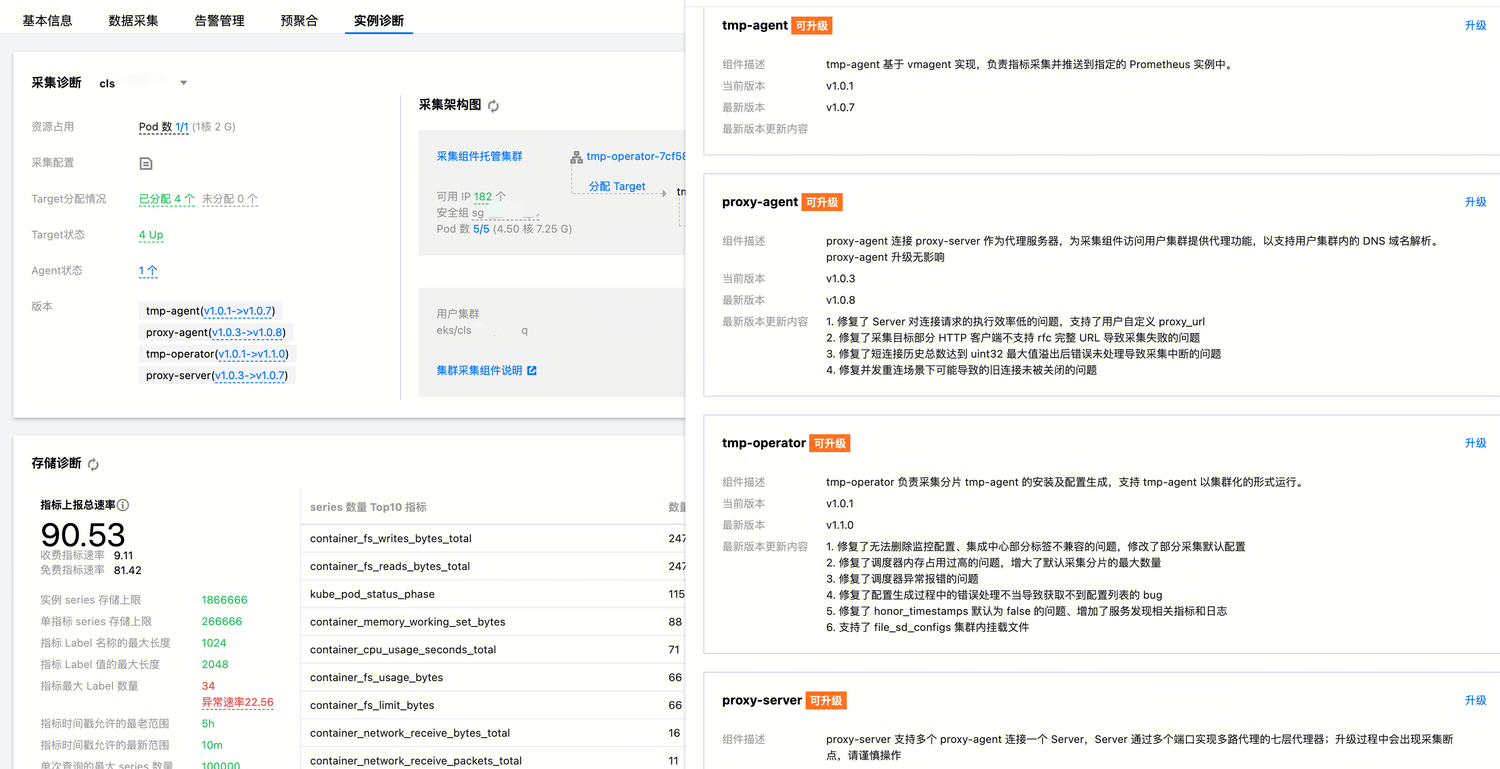
可以在实例诊断页面查看各个组件的当前版本、功能描述以及不同版本的更新信息。在版本的更新中,会对组件可能存在的问题进行处理修复。因此,用户使用的过程中可以尽量保持组件升级到最新的版本。当实例诊断中有新版本提示时,可根据自身需要对采集组件进行升级。其中 tmp-operator、tmp-agent 和 proxy-agent 的升级不会影响数据采集,即不会产生数据断点;而 proxy-server 的升级则可能会出现数据断点,具体的恢复时间和底层集群 Pod 的调度时间有关,需要谨慎升级。
问题二:网络异常
现象
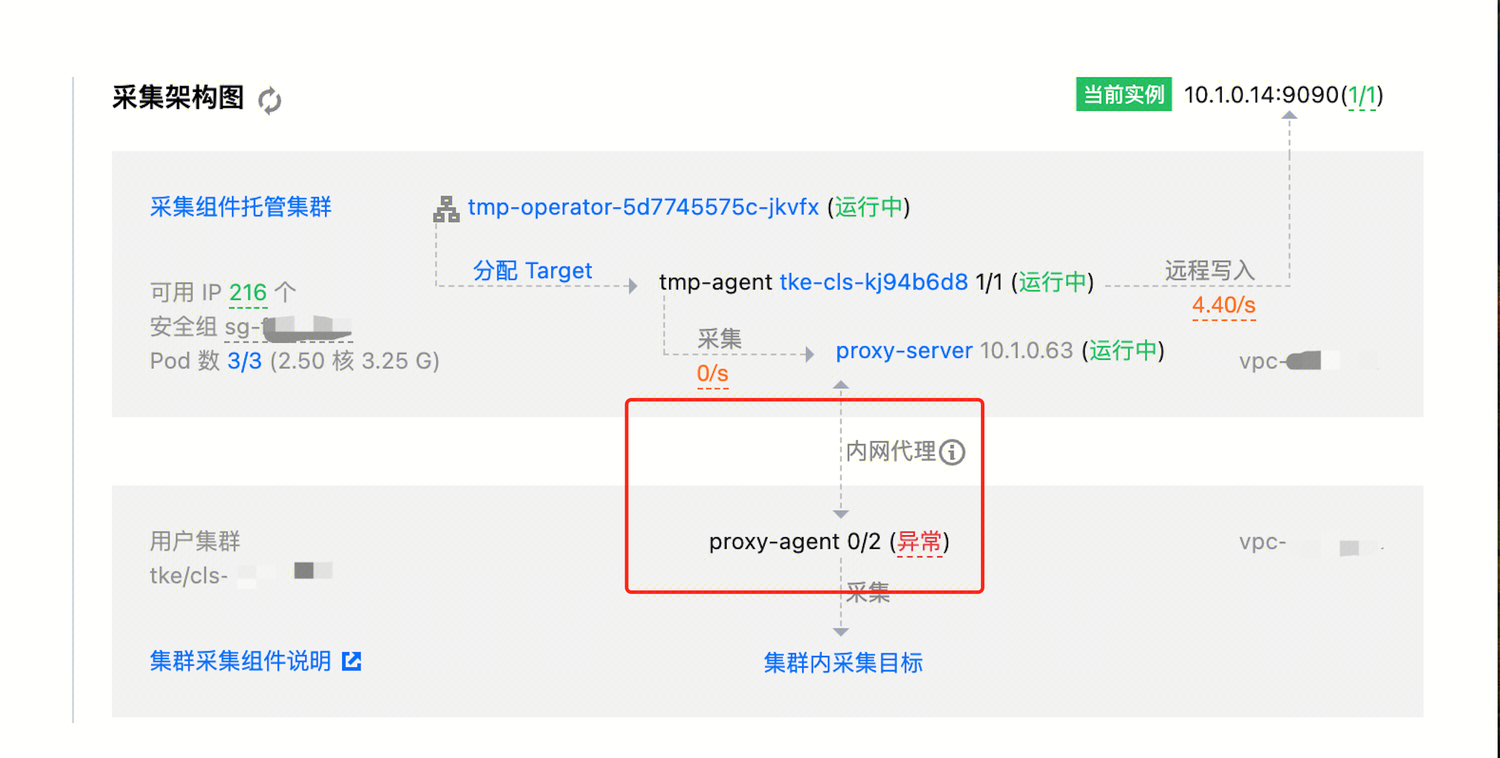
在查询 Prometheus 指标时陆续出现断点;
在控制台上显示采集目标一直因为 timeout 而处于 down 的状态;
在实例诊断页面则可能会显示 proxy-server 和 proxy-agent 的连接异常。
解释和处理
Prometheus 采集涉及到集群内、跨集群、跨 VPC 的通信,不同对象之间的网络异常可能会导致通信异常,使得表现出来采集功能也存在异常。
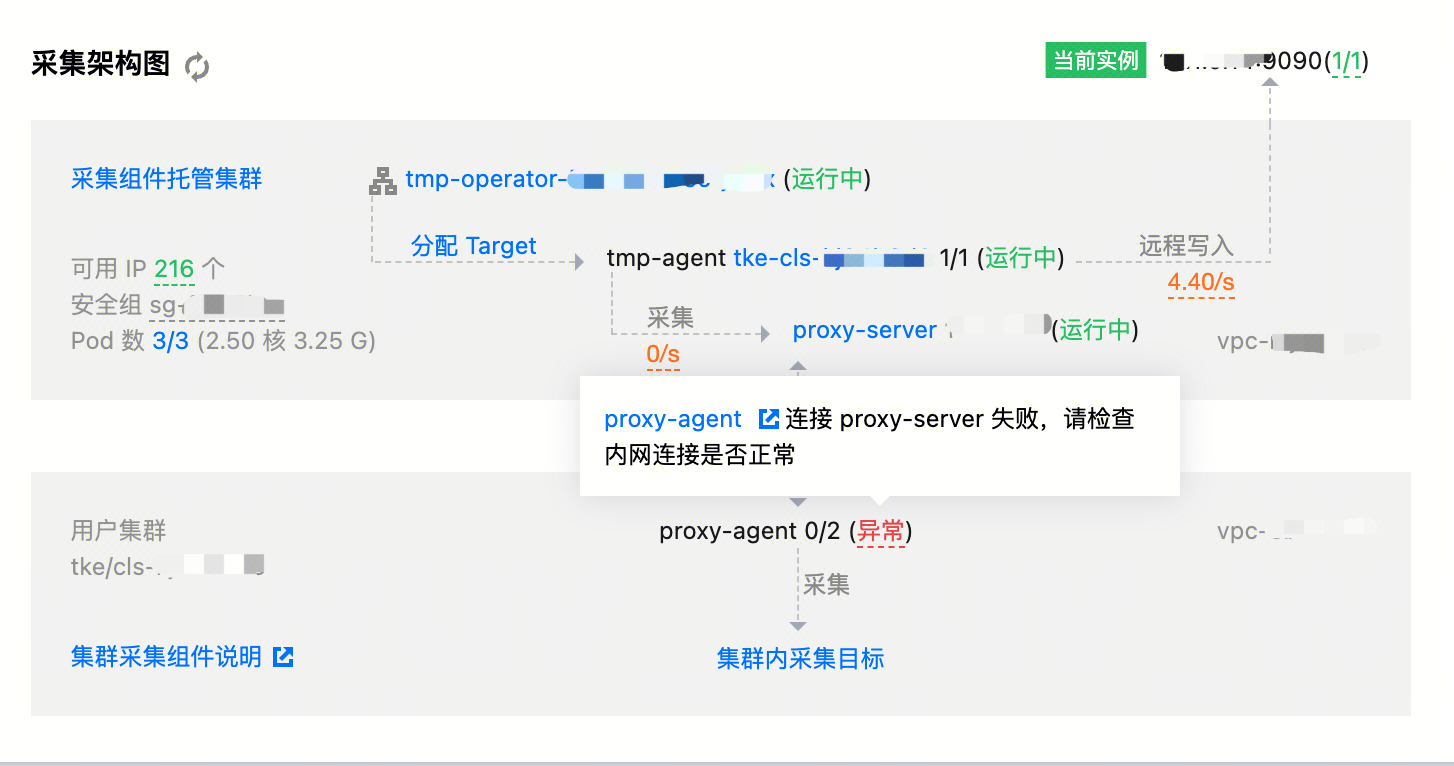
这种情况,通常是带宽问题或安全组问题,特别是带宽问题。当链路上某一节点的带宽占满之后,请求或响应在该节点被阻塞,最终导致请求或响应超时。
1. 在跨 VPC 采集的情况下,如果使用的是公网 CLB,那么可以优先排查公网 CLB 的链路是否通畅、带宽是否占满;如果使用的是云联网连接两个集群,那么可以优先排查云联网的链路是否通畅、带宽是否占满。

2. 在排除跨 VPC 通信的问题后,可以对采集组件 proxy-server 的带宽是否占满进行排查(进入采集集群,并在 Pod 中查看监控即可)。
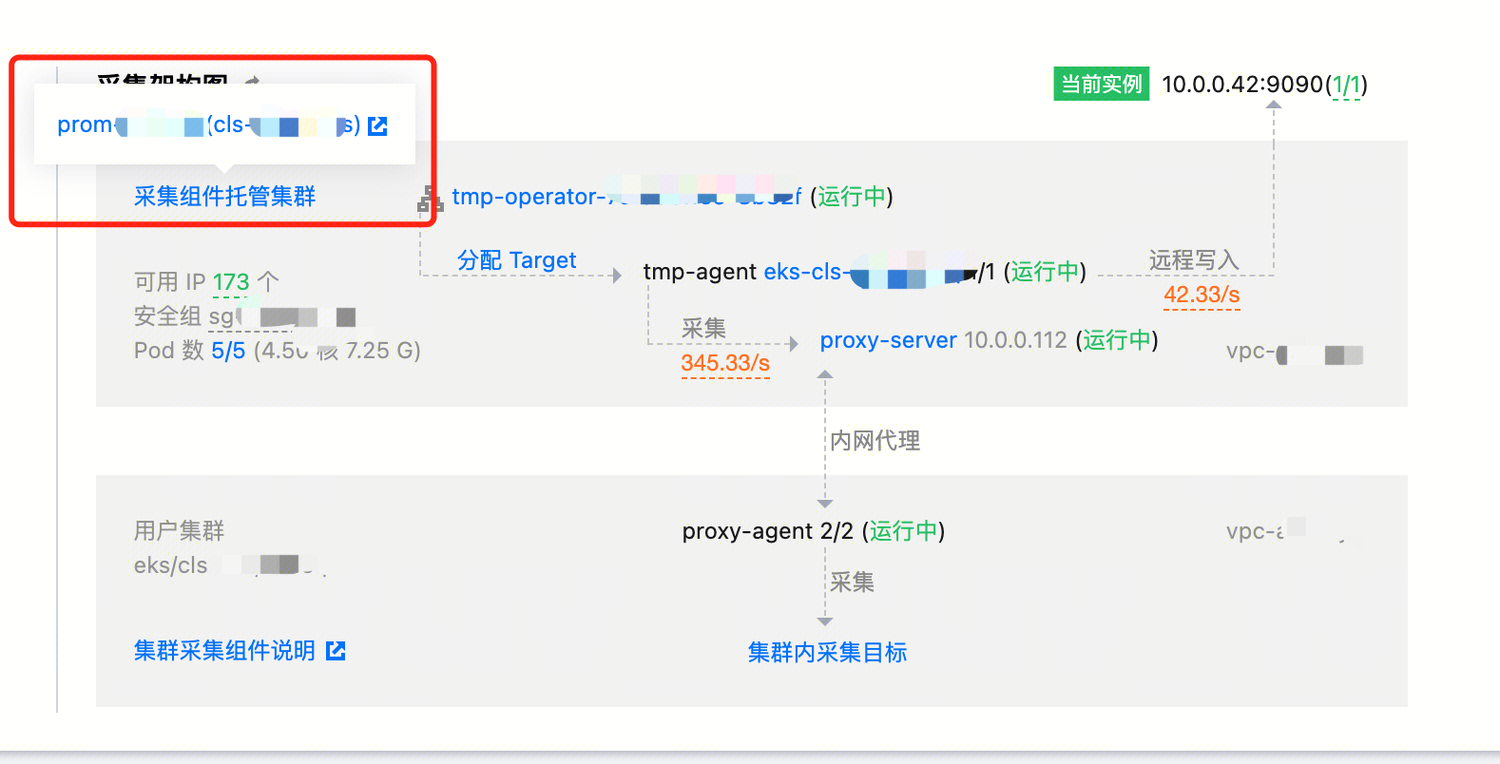
3. 如果已排除带宽的问题,那么可能是安全组的问题。安全组未放通一般在集群关联时就会暴露出来,但不排除后续被修改的可能,被安全组阻挡的请求就无法到达目标 Pod,需要按照实例诊断中的安全组要求进行配置。
问题三 :数据多写堆积
现象
用户短信、站内信等收到数据多写配置异常的告警;
在实例诊断页面显示数据多写异常堆积。
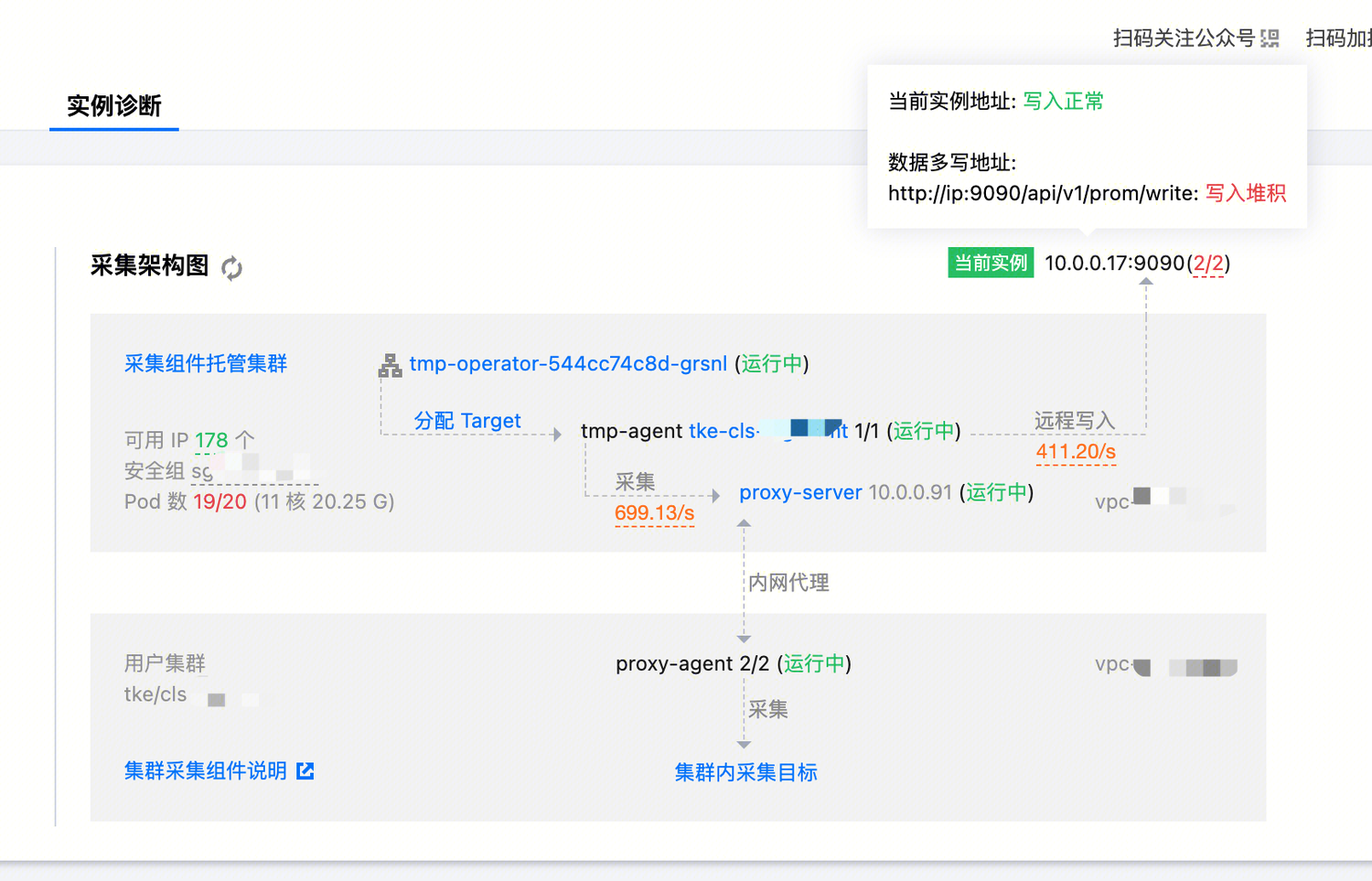
解释和处理
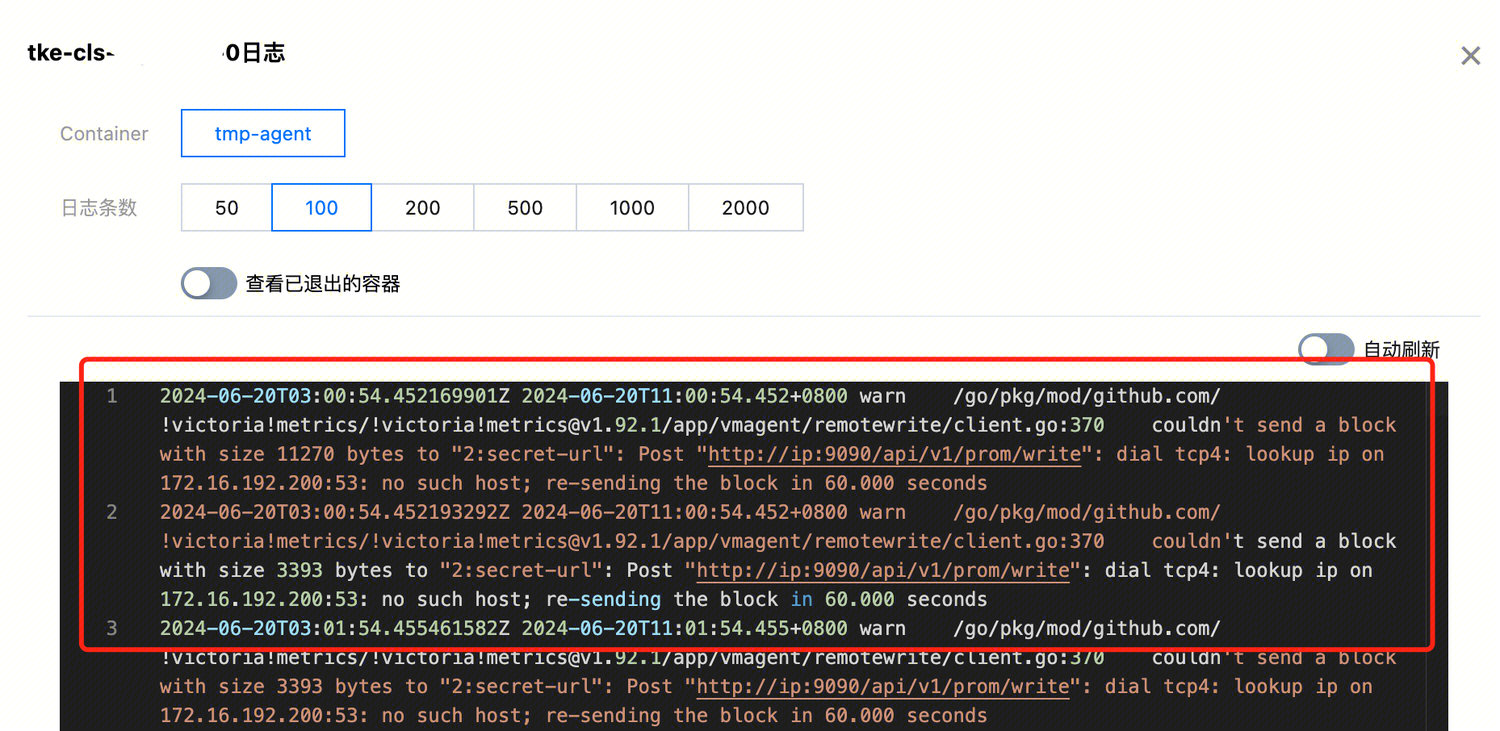
数据多写功能支持将集成容器服务和集成中心的数据写到自建 Prometheus 或其他 Prometheus 监控实例中。如果多写异常,说明采集分片在向目标地址推送指标的时候出现了问题;采集分片如果推送失败,会将指标保存在本地进行重试,如果数据堆积量过大,还可能导致 Pod 异常影响指标采集。
当出现这样的问题,可参考如下步骤排查:
1. 在实例诊断中确认具体的目标地址,短信告警中没有具体的地址;
2. 查看对应的 Prometheus 是否可以正常写入、是否有异常的日志,以排除目标 Prometheus 的问题;
3. 可以查看采集分片的日志,是否存在报错,以及分析具体报错的信息。
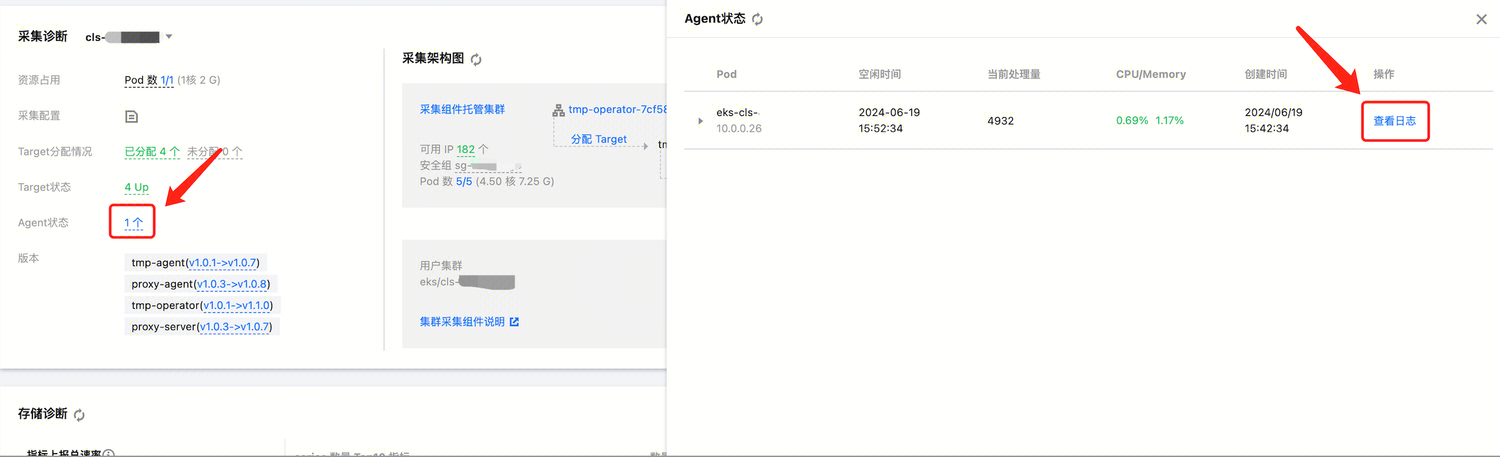
问题四:可用 IP 数量不足
现象
实例诊断页面提示 IP 数量不足(红色并闪烁)。

解释和处理
采集组件托管集群所关联的子网可用 IP 数量不足,可能会导致如下问题:
当采集规模不断增大,达到单个采集分片无法承受时,调度器会对采集群片进行扩容,扩容出来的新分片 Pod 会占用子网内部的 IP;如果可用 IP 数量不足,会出现无法扩容的情况,已有的采集分片持续超负荷运转,会影响采集的稳定性。
当进行采集组件升级时,部分组件会先产生新的正常运行的副本,再替换旧的副本;如果可用 IP 数量不足,会出现新的副本无法调度成功,导致组件升级异常。
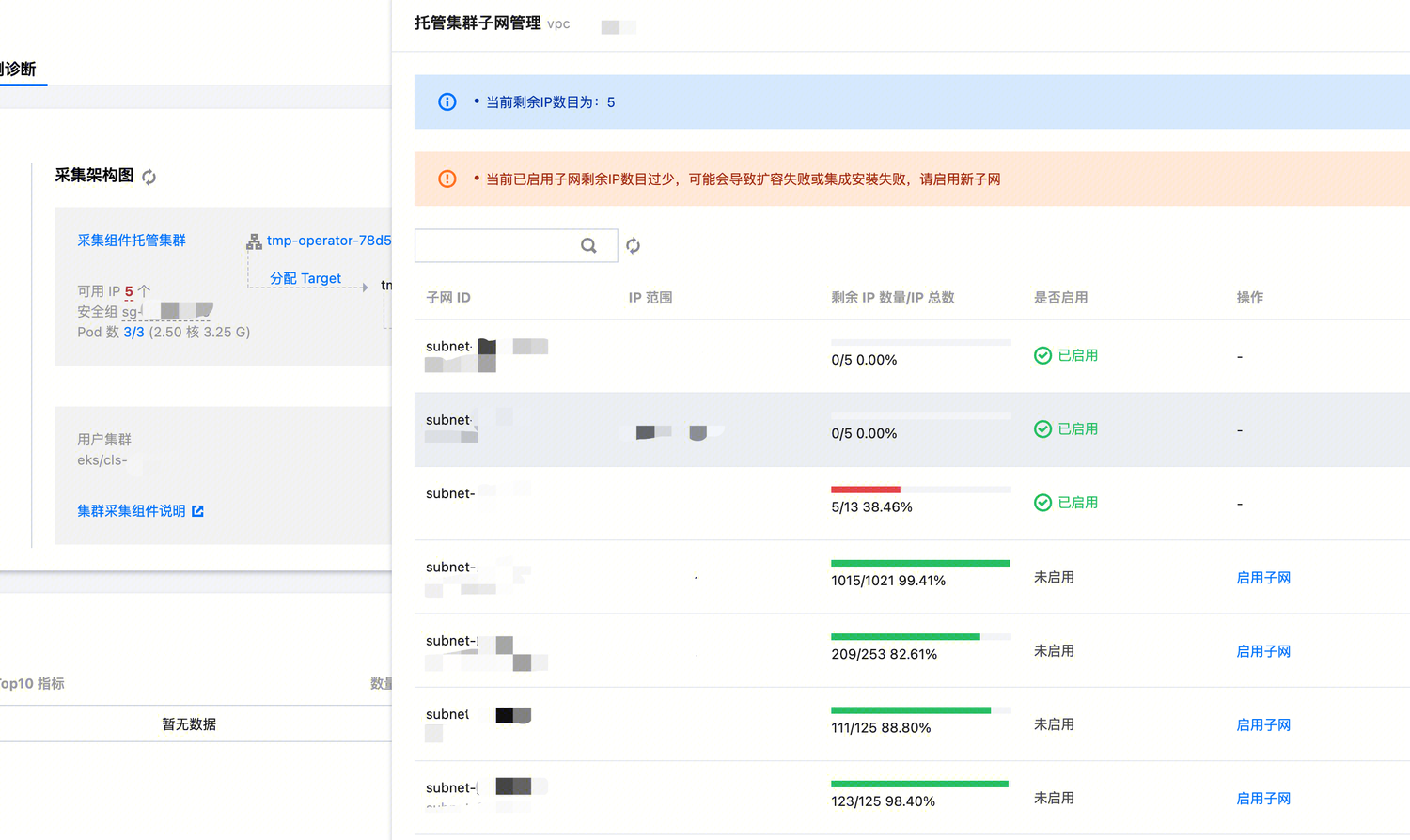
因此,建议始终保持一定数量的可用 IP。当出现上述实例诊断页面显示可用 IP 数量较少时,可以在页面中直接添加子网,具体操作如下:
1. 点击子网数字,进入托管集群子网管理页面;
2. 显示当前 VPC 内已添加到托管集群的子网和未添加的子网,可根据规划点击启用子网启用新的子网;
3. 若没有可用子网,可以先 添加子网 后再在当前页面中启用。
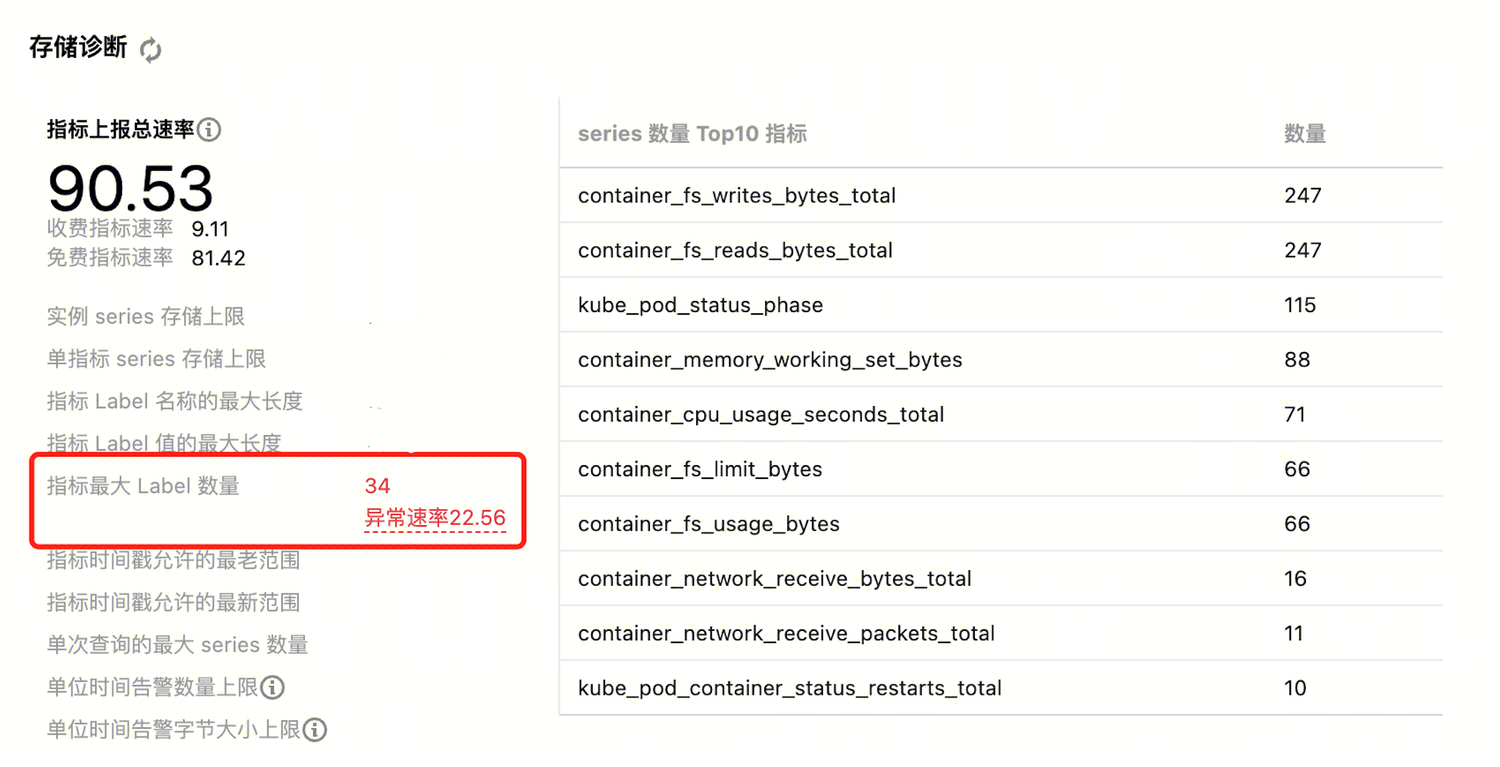
问题五:指标标签数量过大导致写入异常
现象
存储诊断中,指标最大 Label 数量显示异常速率;
同时,Prometheus 实例基本信息页面的实例监控中,“因不合法被丢弃的 Samples”图标中显示有数据被丢弃;
在查询时有部分预期的指标查不出来。
解释和处理
在存储诊断中点击异常速率弹出窗口时,可以看到对应目标集群内尝试写入存储的最大 Label 数量,以及对应不同采集任务 Job 的详细信息。
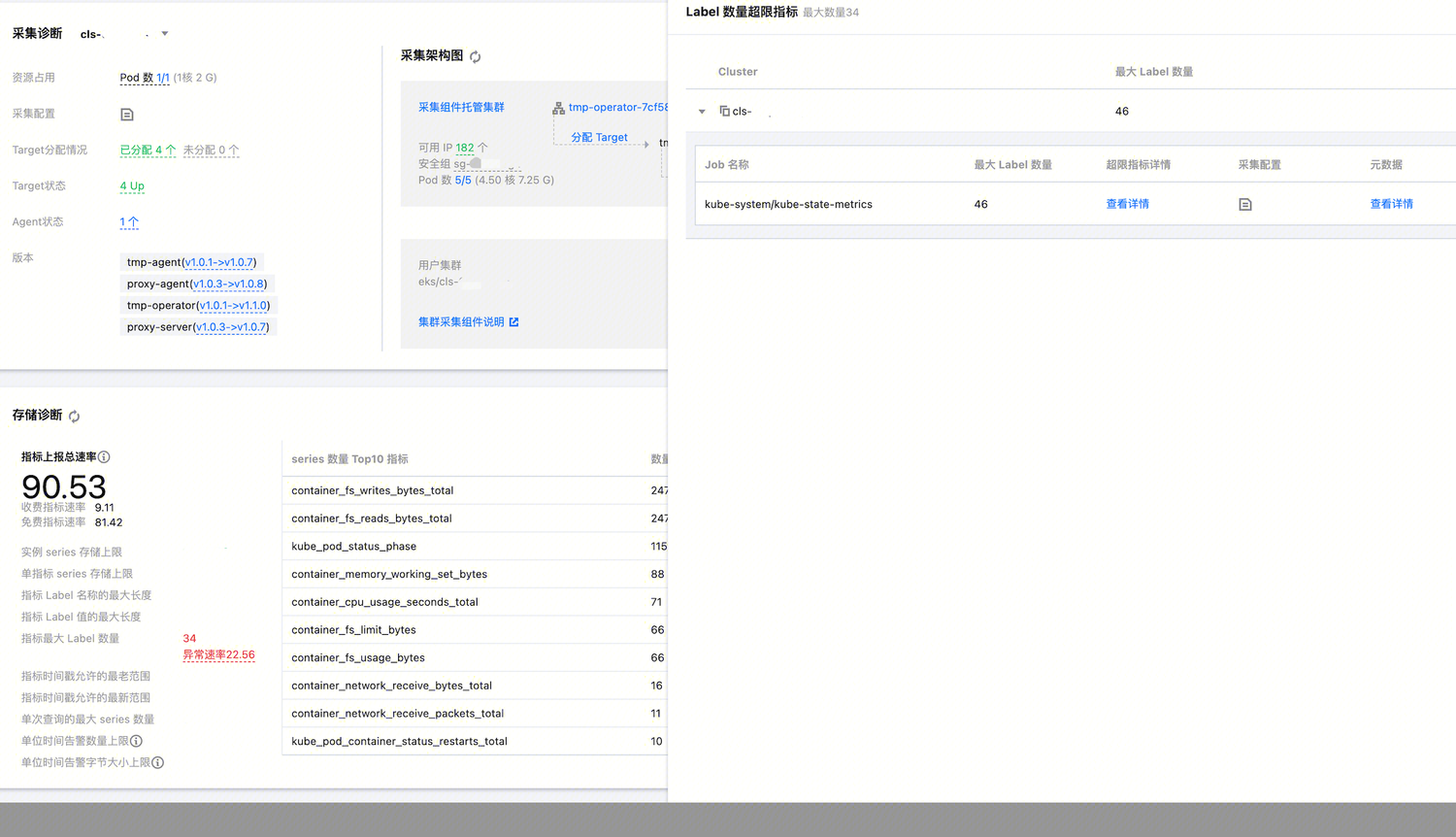
在 Label 数量超限指标详情中,可以看到对应指标的总 Label 数量,以及采集 Label 数、全局标记和存储附加 Label 的信息。
采集 Label 数:根据采集配置,对采集目标服务发现的标签进行 relabel 之后的标签,加上指标本身的标签之后的标签数量,不包括全局标记以及存储附加标签。
全局标记:用户额外配置的,在当前集群所有采集任务上都会添加的标签;默认情况下会在关联集群的时候,添加包含集群信息的“cluster_type”和“cluster”全局标记;
存储附加 Label:由存储侧默认写入的标签,无法修改,用于表示存储本身的信息。
因此,要解决指标标签超限的问题,可以从采集 Label 数和全局标记两个方面处理。处理之前,可以通过查看日志了解被丢弃的指标在写入之前包含的标签信息,在采集分片的日志中进行查看,并确认需要丢弃哪些标签。
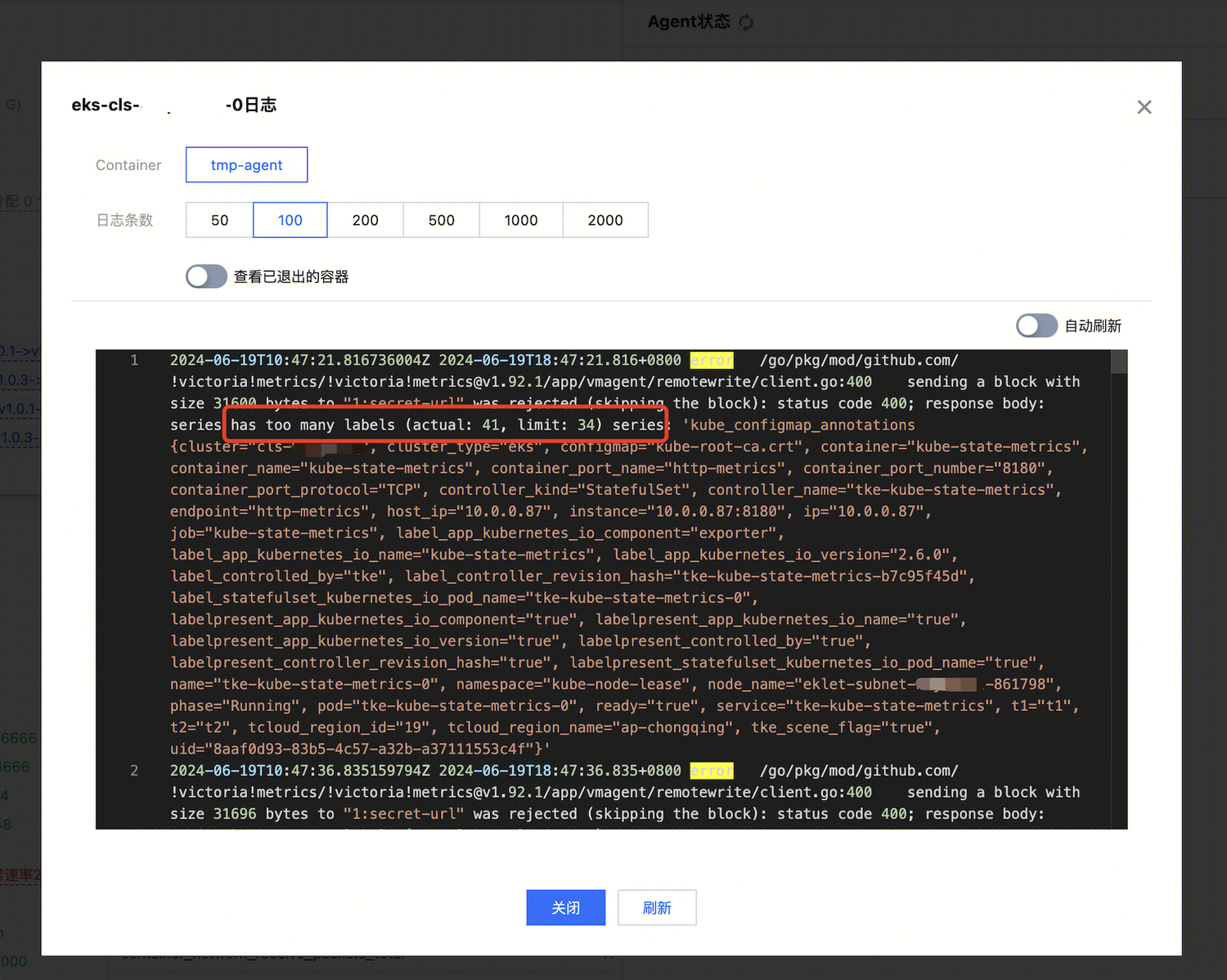
对于采集 Label 数,可以在在采集配置中的 metric_relabel_configs 或 metricRelabelings 中增加 labeldrop 配置来丢弃掉。
metricRelabelings:- action: labeldropregex: label_(.+) # 正则匹配需要去掉的标签
对于全局标记,可以在控制台的数据采集中进行编辑,有不需要的全局标记可以在这里去掉,不过需要注意的是,全局标记的变更会影响到整个集群的采集。
问题六:指标数量达到存储上限导致写入异常
现象
存储诊断中,“实例 series 存储上限”或“单指标 series 存储上限”显示“异常速率”。
同时,Prometheus 实例基本信息页面的实例监控中,“因限流丢弃的 samples”图表中显示有 Samples 被丢弃;在查询时有部分预期的指标查不出来。
解释和处理
在存储诊断中,series 存储上限分别代表了整个 Prometheus 实例和单个指标的 series 存储 上限,当存储中的 series 达到上限之后,会出现新的 series 无法写入的问题,详情如下。(图中的存储上限仅供演示)

单指标存储上限
通常,单个指标 series 数量庞大,是因为某些标签值变化过于频繁,例如将用户的 id、时间戳等作为标签值,或许这在日志收集中很常见,但对于 Prometheus 来说,这种使用方式造成的高基数问题,会严重影响 Prometheus 系统的性能。
解决该问题,即解决标签值频繁变化的情况。在存储诊断中,可以看到“series 数量 Top10 指标”,当出现异常的时候,这里的数值和“单指标 series 存储上限”是对应的。
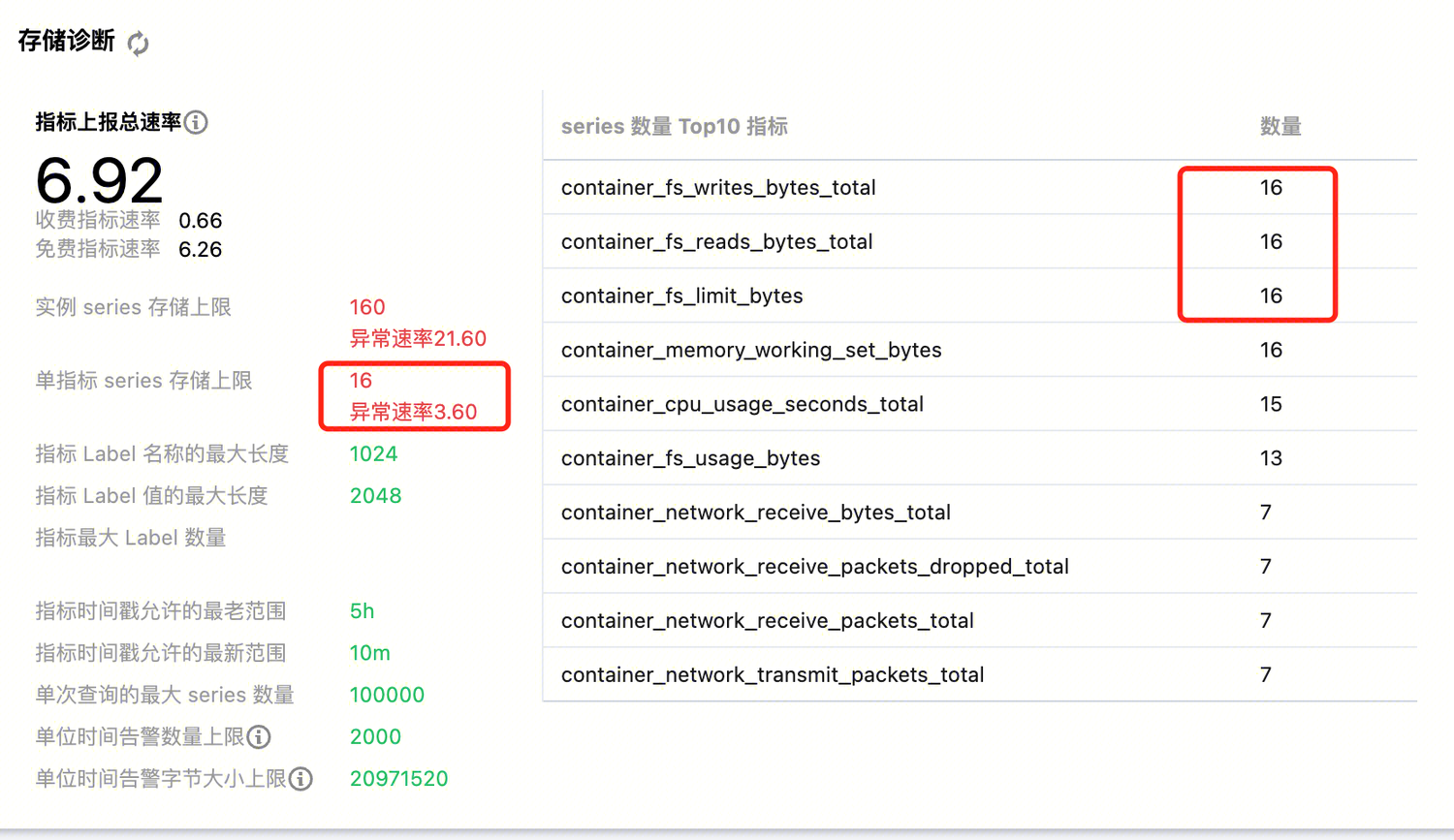
只要找到了对应指标,看是具体哪个标签有问题,在业务暴露指标中去掉这个标签,或是在采集配置的 metric_relabel_configs(原生 Job 配置) 或 metricRelabelings(servicemonitor、podmonitor 等 crd,以及集成中心的云监控集成) 将该标签 labeldrop 即可。
metricRelabelings:- action: labeldropregex: label_(.+) # 正则匹配需要去掉的标签metric_relabel_configs:- action: labeldropregex: label_(.+) # 正则匹配需要去掉的标签
实例存储上限
在该处显示异常,说明预期写入的 series 数量超过了单实例可以存储的数量;而绝大部分情况下,该限制已经满足普通业务量的需要了。您可从如下方面考虑:
1. 确认是否因为某些标签值变化过于频繁导致的整体存储 series 数量过多,毕竟 series 数量和费用关联紧密,如果是因为不需要的标签值变化导致 series 数量较大,最好将该标签去除;
2. 根据业务需要,去掉不需要写入的 series,精简指标体系;
3. 如果业务真的需要上报如此大量的 series,请 联系我们。
问题七:关联失败
现象
在 Prometheus 控制台 > 点击实例 ID/名称 > 数据采集 > 集成容器服务中关联集群时,偶尔会出现“状态异常”关联失败的情况;在实例诊断中也会显示“采集组件关联异常”,这个异常出现的时候采集功能是没有正常发挥作用的。
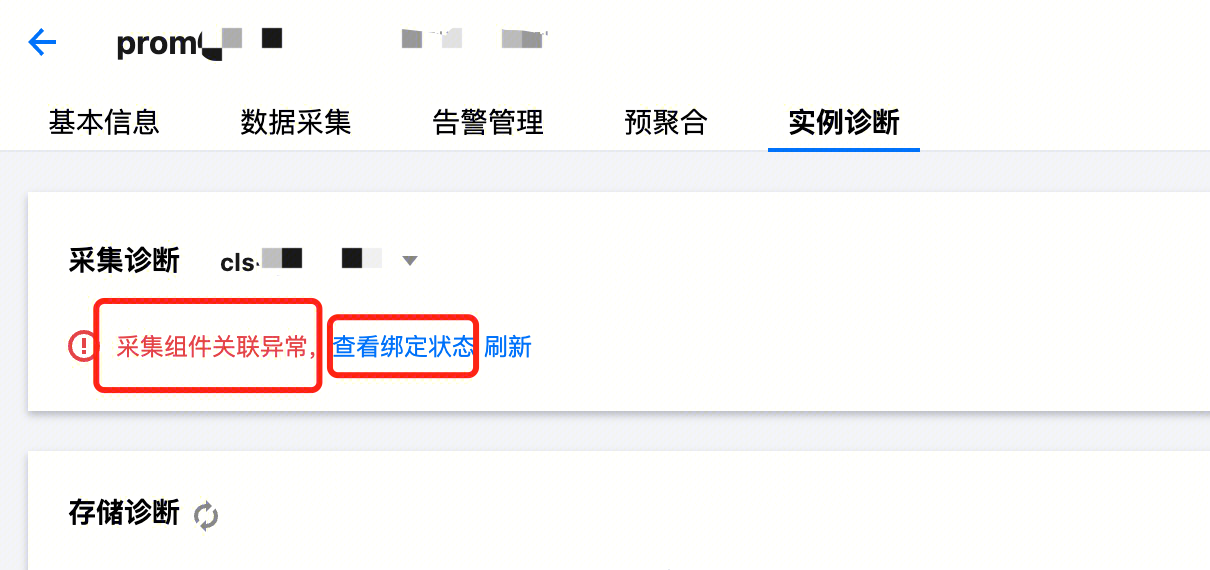
解释和处理
关联成功是正常使用采集容器指标的必要条件,出现关联失败问题的暴露时间点位于实际采集和存储发生之前。您可在集成容器服务或实例诊断中,查看整个关联过程的详情,包含具体出现异常的环节。
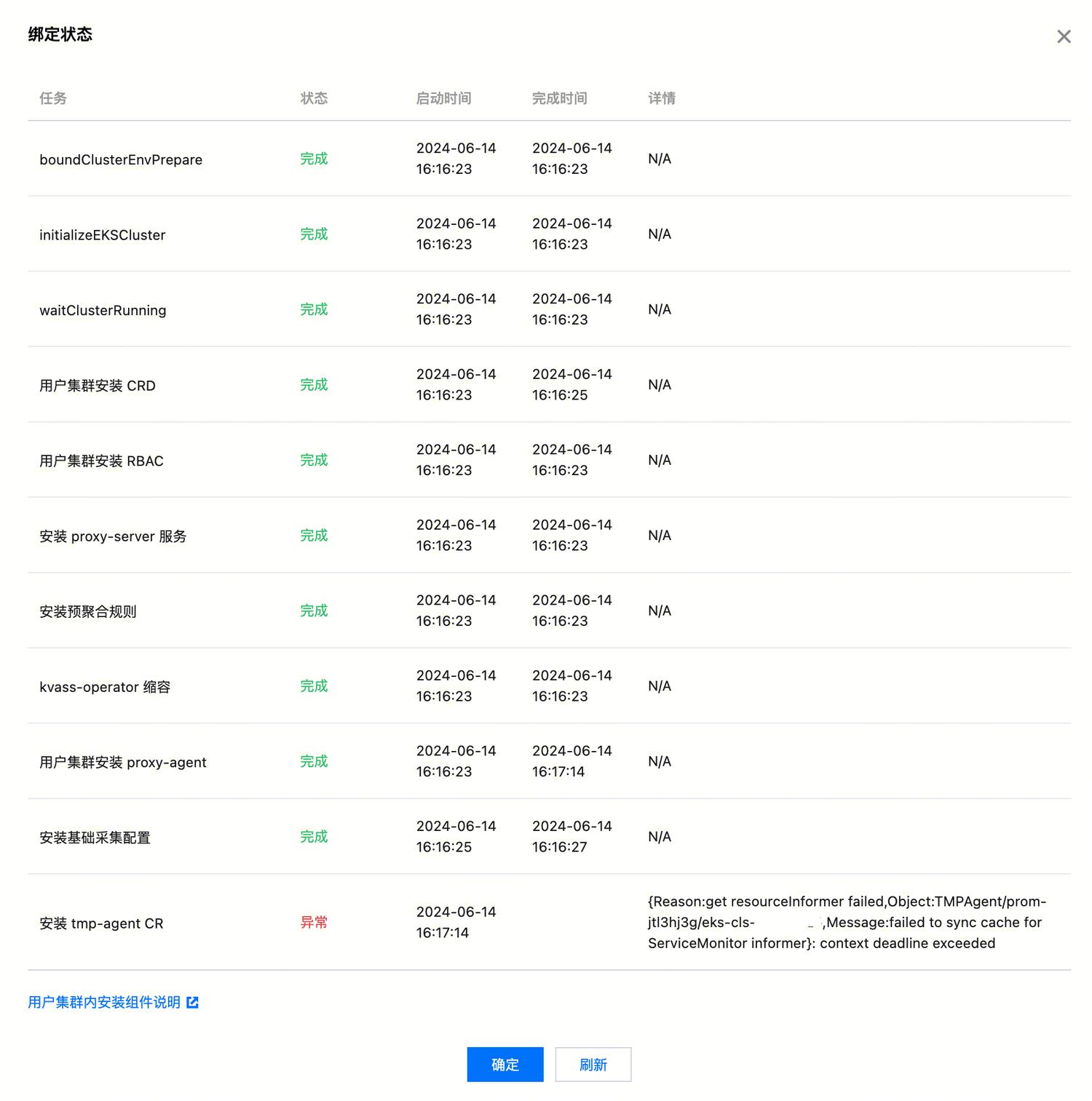
常见的异常及原因通常包括:
集群内剩余可用 IP 不足
这在异常消息中通常会以以下形式出现:
“network-unavailable” 的 taint 提示,是 IP 不足时 EKS 集群自动给 node 添加的标记;
“insufficient IP available” 提示可用 IP 不足;
其他与 IP 不足相关的提示。
解决方法:
如果出现异常的是 initializeEKSCluster 或安装 proxy-server 阶段,需要给采集集群(即同地域下名称为 Prom 实例 ID 的 Serverless 集群)添加有足够 IP 的子网对应的超级节点。
如果出现异常的是安装 proxy-agent 阶段,则需要给被关联的用户集群添加可用的 IP。
集群内资源不足:
提示“nodes are available”,没有足够的 CPU 或内存;
提示“max node group size reached”,节点池无法再扩充节点。
解决方法:这通常发生在目标集群内,需要您增加集群内资源后重试关联。
网络不通:
一般异常消息会包含“failed to sync cache”,由于网络问题导致采集集群无法 watch 目标集群。
解决方法:可进入目标集群以当前 Prom 实例 ID 为名称的命名空间下,查看 proxy-agent 的日志,通常会有无法和对端连接的日志,如“connect to server failed”。
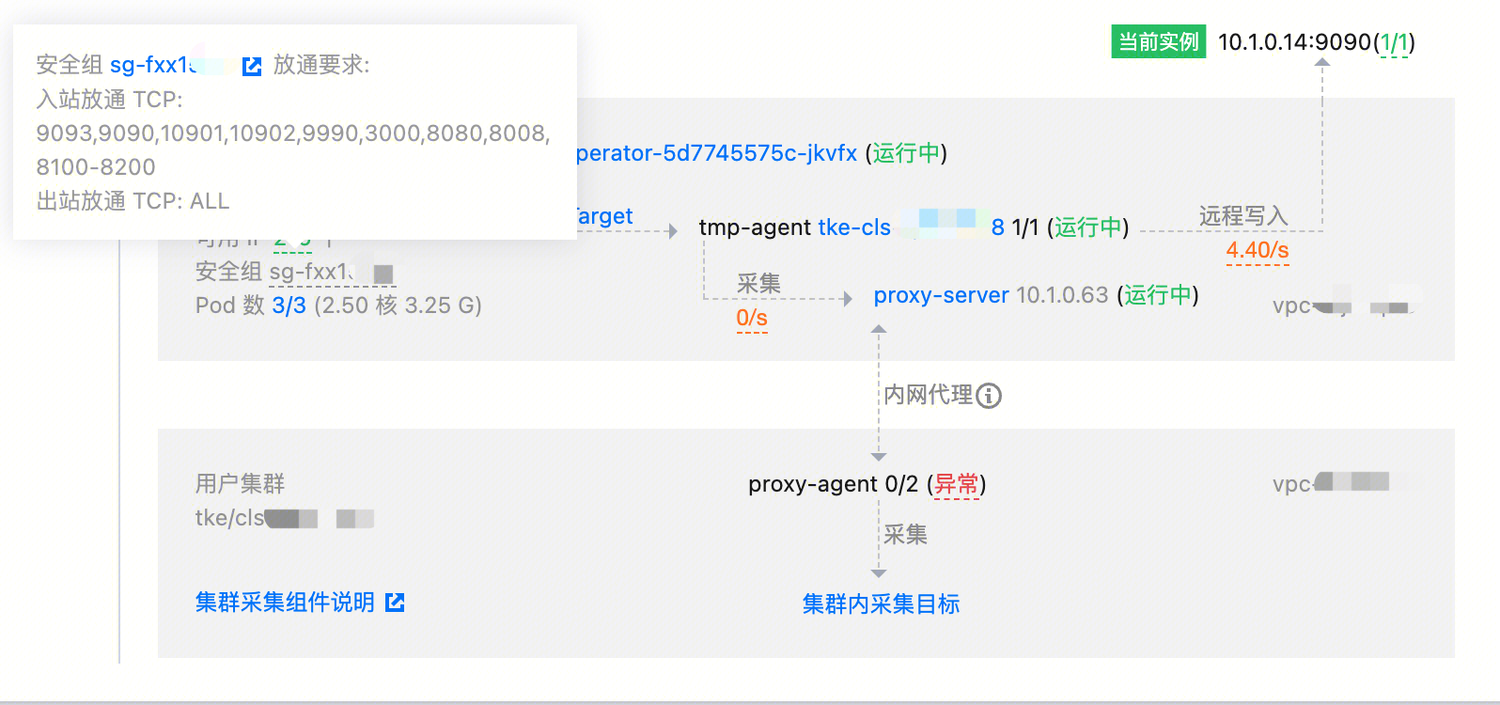
如果是同 VPC ,可能是 proxy-agent 的安全组限制,具体放通要求可以参考如下:
入站放通 TCP:9093,9090,10901,10902,9990,3000,8080,8008,8100-8200。
出站放通 TCP:ALL