操作场景
在使用 TKE GPU 资源过程中需要对资源使用状态进行监控,以便了解 GPU 服务是否运行正常,排查 GPU 资源故障。Prometheus 监控服务提供基于 Exporter 的方式来监控容器化 GPU 运行状态,并提供了开箱即用的 Grafana 监控大盘。本文为您介绍如何使用 Prometheus 监控服务部署 TKE GPU Exporter 以及实现 TKE GPU Exporter 告警接入等操作。
前提条件
操作步骤
1. 登录 Prometheus 控制台。
2. 在实例列表中,选择对应的 Prometheus 实例。
3. 进入实例详情页,选择数据采集 > 集成中心。
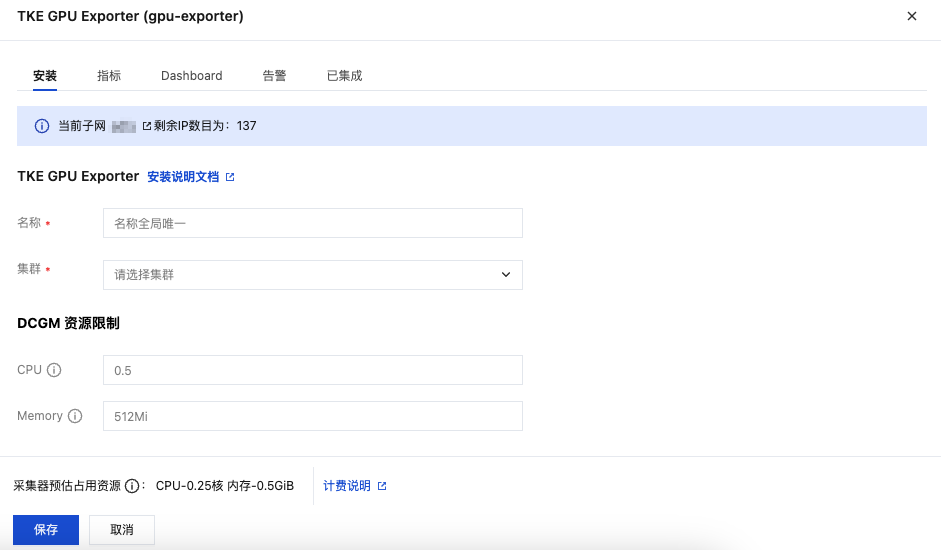
4. 在集成中心找到并单击 TKE GPU Exporter,即会弹出一个安装窗口,在安装页面填写集成名称,选取待监控的 GPU 所在的集群,然后单击保存。
配置说明
名称 | 描述 |
名称 | 集成名称,命名规范如下: 名称具有唯一性。 名称需要符合下面的正则:'^[a-z0-9]([-a-z0-9]*[a-z0-9])?(\\.[a-z0-9]([-a-z0-9]*[a-z0-9])?)*$'。 |
集群 | 选取待监控的 GPU 所在的集群。 |
CPU | DCGM Exporter 工作负载的 CPU 限制,以 CPU 核心数为单位,需符合 Kubernetes 资源限制格式,具体支持的格式如下: 小数或整数,例如0.5表示0.5个 CPU 核心。 毫核值,整数后加单位m,例如500m表示500毫核(等同于0.5核心)。 |
Memory | DCGM Exporter 工作负载的内存限制,以字节为单位,需符合 Kubernetes 资源限制格式,具体支持的格式如下: 纯整数,例如1048576表示1048576字节。 整数后加十进制单位,支持 P、T、G、M、k,例如100k表示100,000字节。 整数后加二进制单位,支持Pi、Ti、Gi、Mi、Ki,例如256Mi表示约268,435,456字节。 |
支持的额外标签
在通过节点池管理节点的场景下,除 DCGM-exporter 与 tke 组件 qgpu、nvidia-gpu 上报的标签之外,TKE GPU Exporter 支持自动采集以下几个标签:nodepool、nodepool_name、gpu_type。其中 nodepool 为 tke 侧自动生成的节点池 ID,如果用户想在指标中增加节点池名称和 gpu 类型标签,可在节点池中增加自定义标签 nodepool_name、gpu_type,具体步骤如下:
1. 进入 容器集群控制台,选择对应集群进入管理页面,选择节点管理 > 节点池。
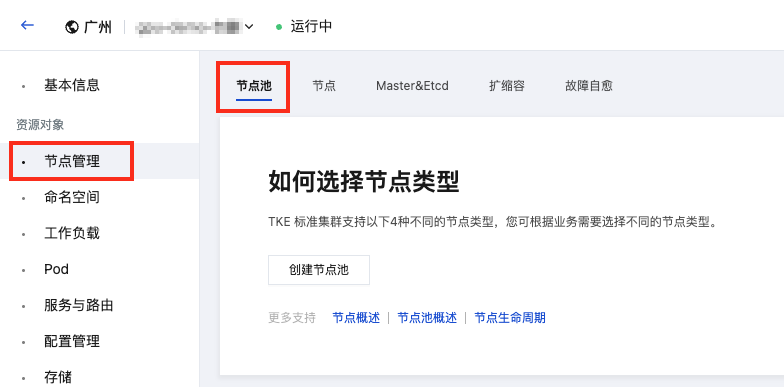
2. 找到 gpu 类型节点所在节点池,单击编辑。
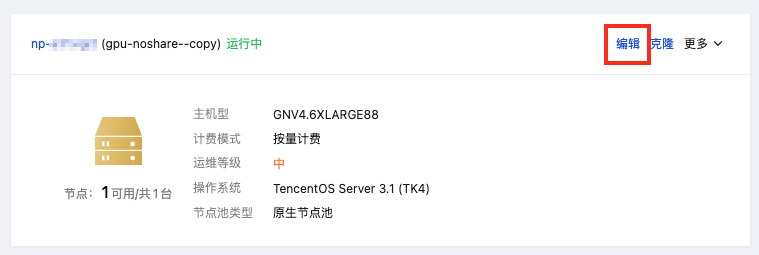
3. 在弹框中找到 Labels,单击新增,在左侧输入框中输入标签键名称 nodepool_name 或 gpu_type,在右侧输入框中输入对应的标签键值,标签键值需符合tke 的要求。
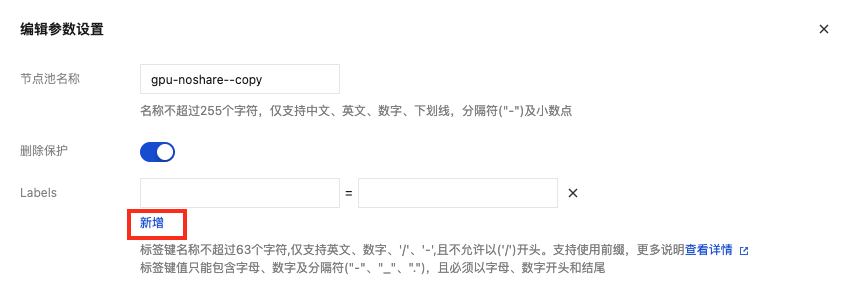
4. 输入完成后,确保下方的对存量节点应用本次 Label/Annotation/Taint 更新选项勾选框保持为勾选状态,单击确定即可完成当前节点池 nodepool_name、gpu_type 标签的设置。
5. 最新版 TKE GPU Exporter 集成支持自动采集以上标签,等待30s后观察指标是否增加了对应标签,如版本过低导致标签未增加,则需主动更新已安装 TKE GPU Exporter 集成。
5.1 登录 Prometheus 监控服务控制台,选择对应 Prometheus 实例进入管理页面,选择数据采集 > 集成中心,进入集成中心页面,找到 TKE GPU Exporter 集成,进入已集成列表。
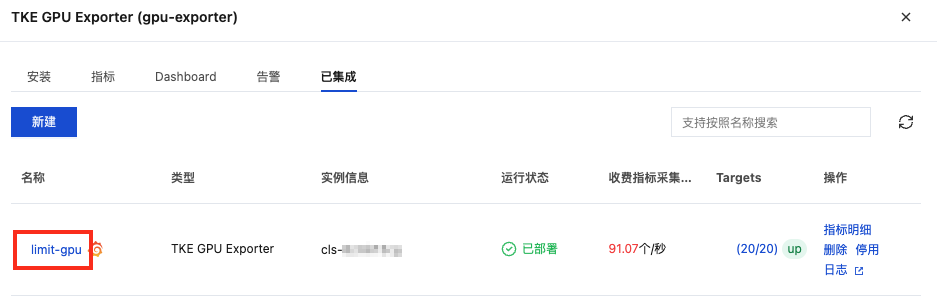
5.2 在已集成列表中找到目标集群对应的集成,单击集成名称进入编辑页面后,单击保存。
查看监控
前提条件
Prometheus 实例已绑定 Grafana 实例。
操作步骤
1. 选择数据采集 > 集成中心,进入集成中心页面。找到 TKE GPU Exporter 集成,选择 Dashboard > Dashboard 操作 > 安装/升级 Dashboard,单击安装/升级,安装对应的 Grafana Dashboard。
2. 选择查看已集成,在已集成列表中单击 Grafana 图标即可自动进入 GPU 监控大盘文件夹,查看实例相关的监控数据,如下图所示:
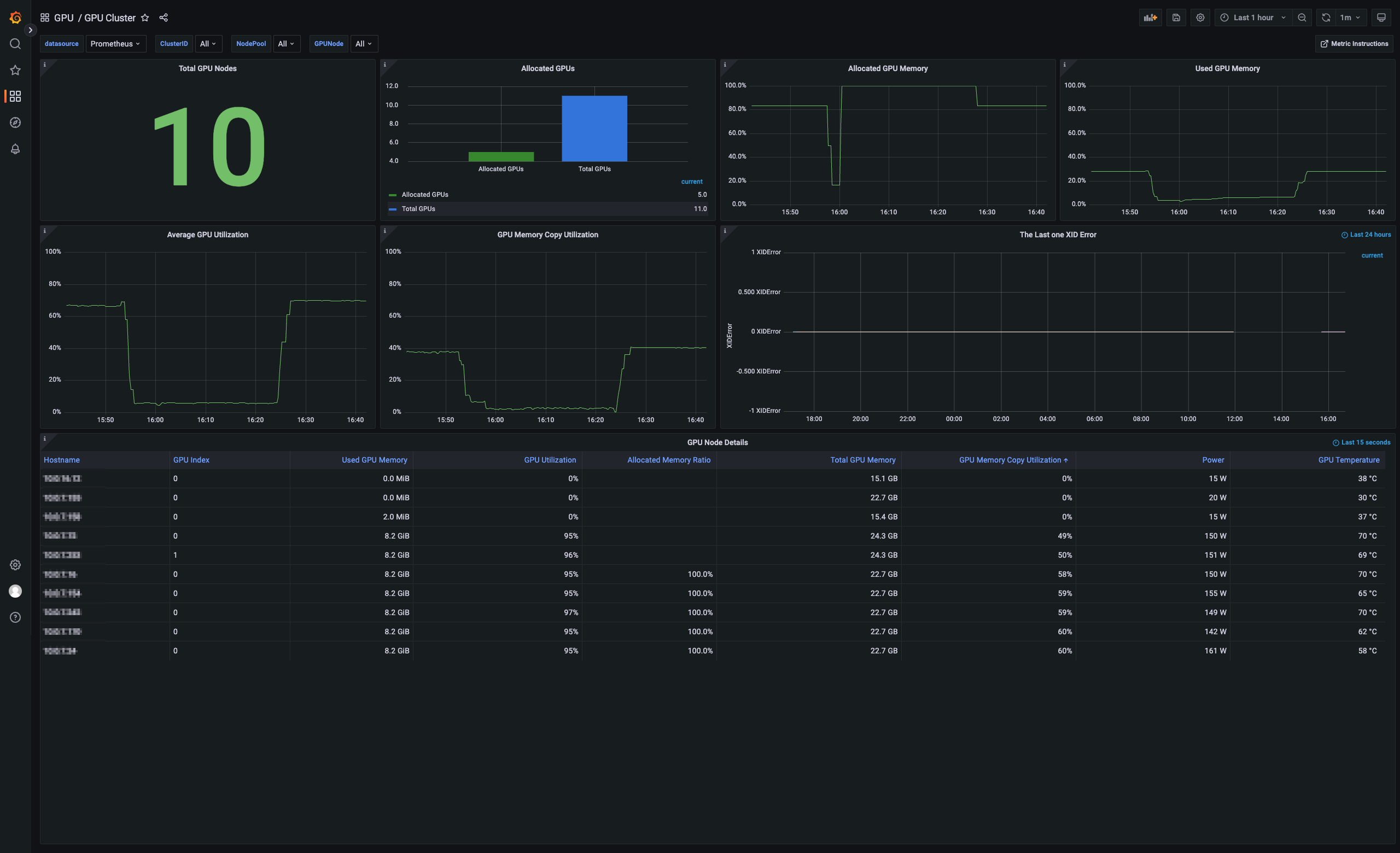
GPU Cluster:以集群的维度查看 GPU 节点状态,例如节点个数、GPU 使用率、GPU 内存、GPU 内存使用率等。
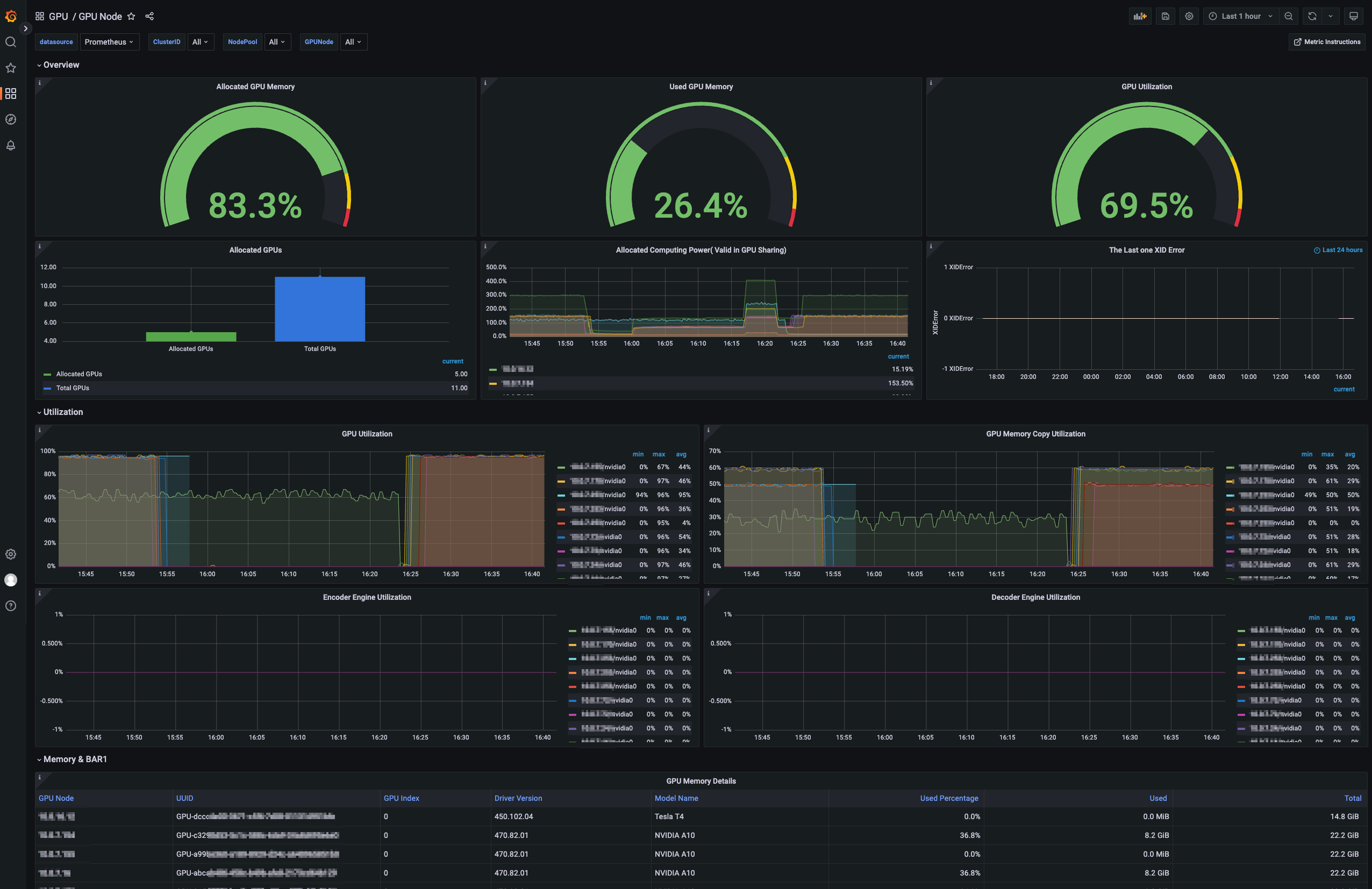
GPU Node:以节点池的维度查看 GPU 节点状态,例如节点状态概览、GPU 卡信息、内存使用率、温度与能耗信息等。
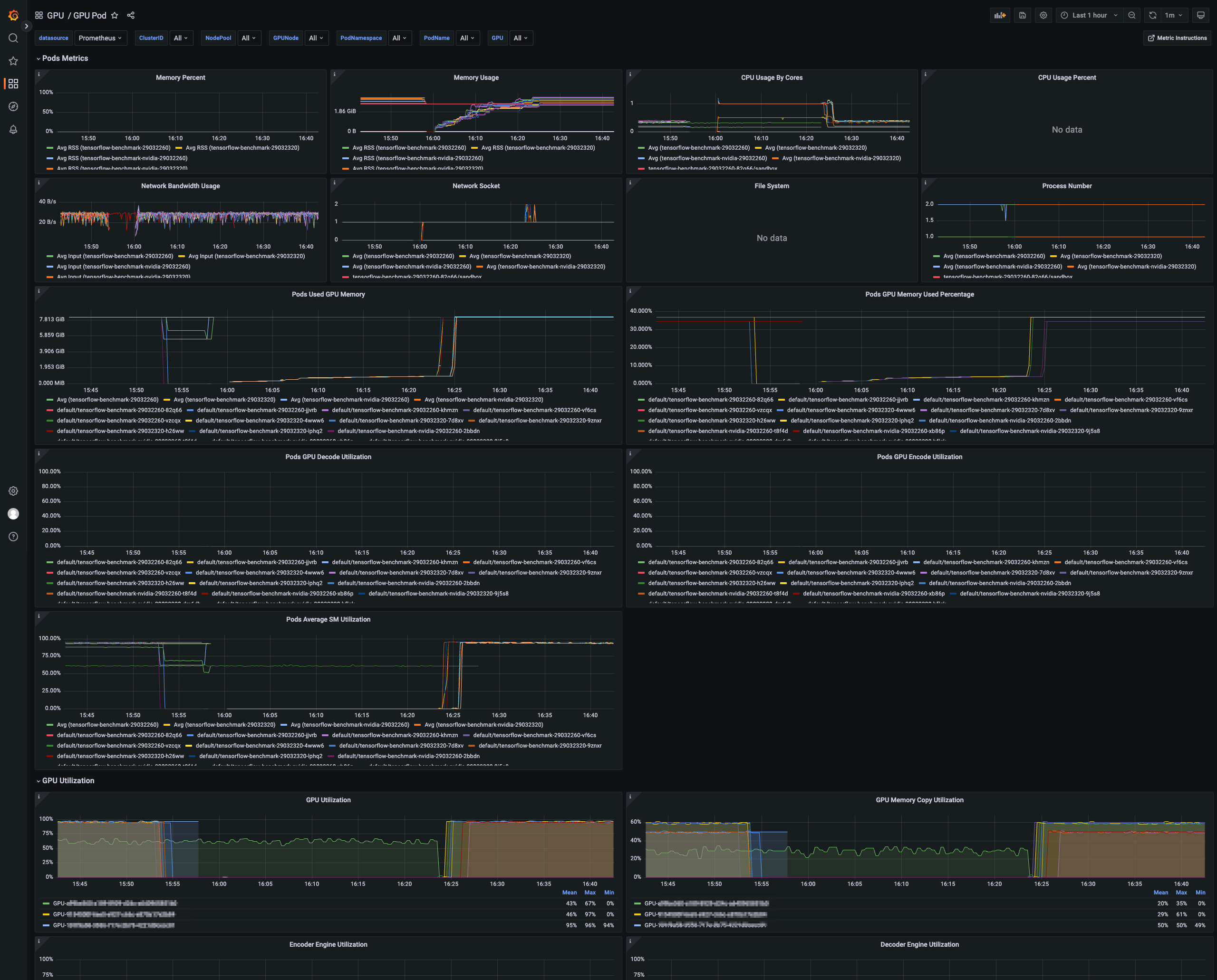
GPU Pod:以 pod 的维度查看 GPU 节点状态,例如使用 GPU 节点的 pod CPU 内存利用率、网络带宽与文件系统监控、GPU 使用率、GPU 内存使用率等。
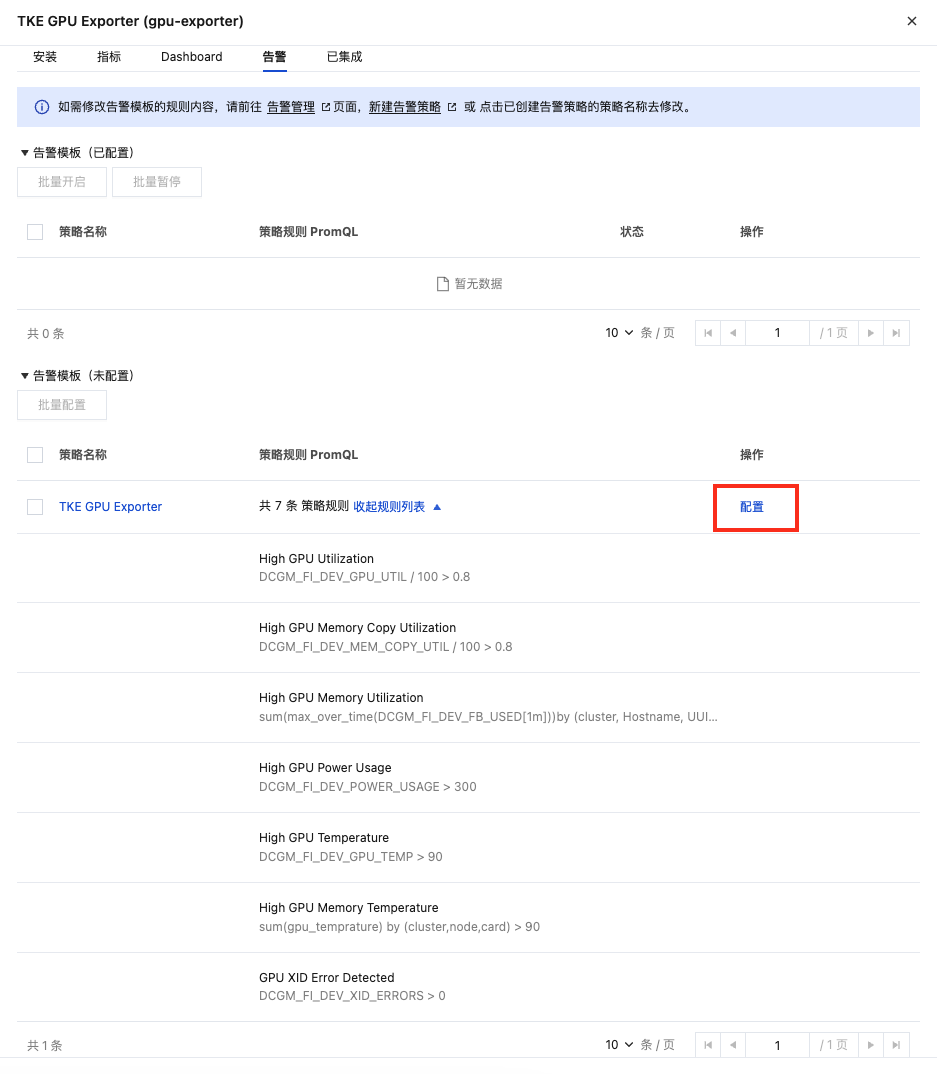
配置告警
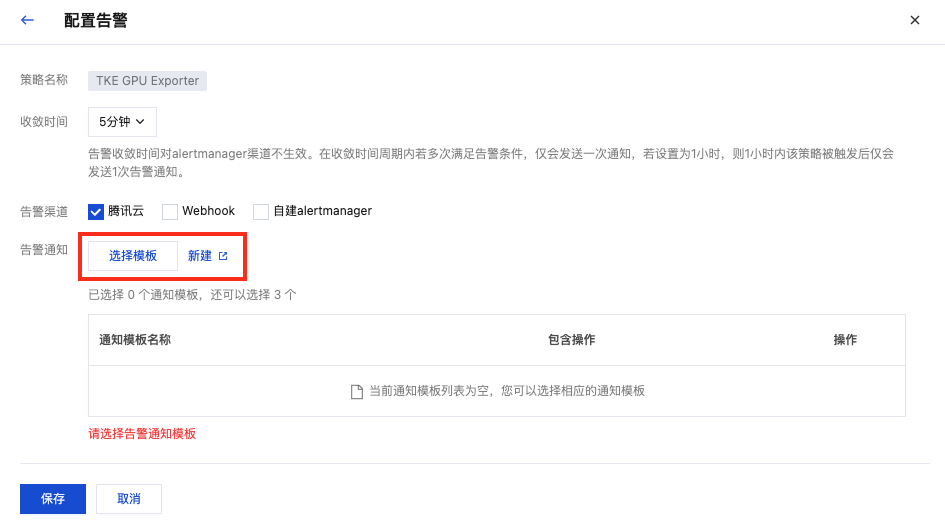
腾讯云 Prometheus 托管服务支持告警配置,在集成中心页面找到 TKE GPU Exporter 集成,选择告警 > 告警模板,单击展开规则列表,可查看 TKE GPU 预设告警策略。