概述
高性能计算集群的自助检测(即集群一致性检测)功能提供集群维度的实例检测,您可以检测集群中所有实例的硬件和软件状态。您可通过该功能及时发现并解决集群实例的相关问题。
操作场景
以下两种场景推荐使用集群自助检测:
集群故障排查:在日常运维过程中,您可以使用集群自助检测功能,检测集群中所有实例的硬件和软件状态,并根据相应建议对异常情况进行处理。
大规模 AI 模型训练环境检测:集群训练需要保障硬件、GPU 驱动、CUDA、NCCL 和 RDMA 等配置状态的可用性和一致性,自助检测功能提供集群维度的实例检测能力,保障训练正常运行。
检测项说明
集群自助检测功能支持诊断硬件和软件配置的一致性并提供诊断报告。
集群训练环境
检测项 | 检测说明 | 风险等级 | 解决方案 |
集群训练环境 GPU 型号 | 实例的 GPU 型号 | 异常 | 更换为同种型号 GPU 机型。 |
集群训练环境 CPU 型号 | 实例的 CPU 型号 | 异常 | 更换为同种型号 CPU 机型。 |
集群训练环境 GPU 卡数 | 实例的 GPU 卡总数 | 异常 | |
集群训练环境内核版本 | 实例的操作系统内核版本 | 警告 | 操作系统内核版本不一致,建议更换同操作系统保持内核一致。 |
集群训练环境 OS 版本 | 实例的操作系统版本 | 异常 | 建议更换操作系统保持版本一致。 |
集群训练环境 OFED 版本 | 实例的网卡驱动版本 | 异常 | 建议使用 HCC 公有镜像,已安装 OFED 驱动。 |
集群训练环境 GPU 驱动版本 | 实例的 GPU 驱动版本 | 异常 | |
集群训练环境 CUDA Runtime 版本 | 实例的 CUDA Runtime 版本 | 异常 | |
集群训练环境 CUDA Driver 版本 | 实例的 CUDA 驱动版本 | 异常 | |
集群训练环境 GDR 状态 | 实例是否加载 nvidia_peermem 模块。
nvidia_peermem 是 NVIDIA 提供的一个内核模块,通常用于支持设备间直接内存访问(peer-to-peer memory access),在高性能计算(HPC)和深度学习应用中用于优化 GPU 间的数据传输效率,对多机多卡训练性能有影响。 | 异常 | 默认自动安装驱动后自动加载 nvidia_peermem 模块,若检测未加载nvidia_peermem 模块,请确保 GDR 挂载状态,参考如下步骤处理 : modprobe nvidia_peermem && echo "modprobe nvidia_peermem" >>/etc/rc.local |
集群训练环境 NCCL 版本 | 实例的 NCCL 版本。NCCL(NVIDIA Collective Communications Library)是 一个 NVIDIA GPU 集合通信库,用于多 GPU 或多个节点通信,是 AI 分布式训练的必选软件。 | 异常 | |
集群训练环境 NCCL-plugin 版本 | 实例的 NCCL-plugin 版本。NCCL-plugin 是一款针对腾讯云星脉网络架构的高性能定制加速通信库插件,依托星脉网络硬件架构,为 AI 大模型训练提供更高效的网络通信性能,详情请参见 GPU 型实例安装 TCCL 说明。 | 异常 |
集群 RDMA
检测项 | 检测说明 | 风险等级 | 解决方案 |
集群 RDMA Bonding 状态 | 检查特定的网卡绑定接口(bonding interface)为 up 状态的网卡数量。 | 异常 | 若存在网卡绑定状态未开启,请执行 ifup bondX ( bondX 是要重启的网卡的名称,例如 bond0)将网卡开启,以便 RDMA 网络正常使用。 |
集群 RDMA MTU 配置 | 当前网络接口的最大传输单元(MTU)。MTU 是指在一个网络数据包中,数据部分的最大字节数。不同的网络接口和网络环境可能有不同的最佳 MTU 值。 | 异常 | 若检测 MTU 值异常,建议调整 MTU 值为9100。 |
集群 RDMA 网卡速率 | 了解网络接口的速度,以确保网络设备和连接正常工作。 | 异常 | |
集群 RDMA rp_filter 状态 | 读取或设置 Linux 系统中某个网络接口的反向路径过滤(Reverse Path Filtering)。 | 异常 | 若检测到 rp_filter 配置异常,请联系腾讯云处理。 |
集群 RDMA QoS 配置 | 读取 QoS 配置信息,配置影响数据包的处理优先级和质量,可能具有 0 到 255 之间的数值,用来表示不同的优先级或服务质量,一般是 160。所有实例配置需要保持一致。 | 异常 | 若检测到您的端口 QoS 配置问题,请执行如下命令修复: bash /usr/local/qcloud/rdma/dscp.sh |
集群 RDMA CRC 异常 | 查询并过滤特定网络接口的统计信息,特别是接收数据包时的 CRC 错误统计。CRC 是一种用于检测错误的校验方法,如果一个数据包的 CRC 校验失败,表明该数据包在传输过程中可能被损坏。 | 警告 | 若该计数持续有增加,请联系腾讯云处理。 |
集群 RDMA ARP 双发检查 | 用于配置和管理网络接口绑定(bonding)设置中的广播 ARP(Address Resolution Protocol)检测功能。广播 ARP 检测是网络绑定中的一种链路监控方法。通过发送 ARP 请求并监听响应,来检测链路的可用性。 | 异常 | 若检测到 ARP 配置问题,请联系腾讯云处理。 |
集群 RDMA rpg_time_reset 拥塞控制参数 | RoCE(RDMA over Converged Ethernet)网络接口的 RPG(Rate-Parity Group)时间重置相关的设置。RPG 时间重置是 RoCE 网络接口的一种功能,用于在网络链路出现异常情况时执行重置操作,以确保网络的稳定性和可靠性。重置操作可能涉及重新初始化或重新同步网络接口的一些参数或状态。 | 警告 | 拥塞控制参数不一致,如观测到业务训练速度变慢,请联系腾讯云处理。 |
集群 RDMA rpg_ai_rate 拥塞控制参数 | 用于配置 RoCE(RDMA over Converged Ethernet)网络接口中 RPG(Rate-Parity Group)的自适应传输速率。自适应传输速率是 RoCE 网络接口的一种功能,允许在传输数据时动态调整传输速率,以根据网络负载和性能需求实现最佳的数据传输效率。 | 警告 | 拥塞控制参数不一致,如观测到业务训练速度变慢,请联系腾讯云处理。 |
集群 RDMA rpg_byte_reset 拥塞控制参数 | RoCE(RDMA over Converged Ethernet)网络接口的 Rate-Parity Group(RPG)的字节重置设置。 | 警告 | 拥塞控制参数不一致,如观测到业务训练速度变慢,请联系腾讯云处理。 |
集群 RDMA rate_reduce_monitor_period拥塞控制参数 | RoCE 网络接口的 Rate-Parity Group(RPG)的速率降低监控周期(Rate Reduce Monitor Period)。 | 警告 | 拥塞控制参数不一致,如观测到业务训练速度变慢,请联系腾讯云处理。 |
集群单机检测
检测项 | 检测说明 | 风险等级 | 解决方案 |
集群单机检测 GPU 硬件降速 | 检测硬件热量减速功能当前是否处于激活状态 | 异常 | |
集群单机检测 GPU 软件降速 | 检测软件热量减速功能当前是否处于激活状态 | 异常 | |
集群单机检测 GPU XID 异常 | GPU 是否存在 XID 报错 | 异常 | |
集群单机检测 NVLink 激活失败 | 检测 NVLink 激活失败个数 | 异常 | 若检测失败,请确认 nvidia-fabricmanager 服务是否正常。 若服务异常,请启动服务再验证是否正常;若服务正常,请重启实例再验证是否正常。 |
集群单机检测 NVSwitch 初始化失败 | 检测 NVSwitch 初始化失败 | 异常 | 请重启机器再检测是否可以恢复,若无法恢复请联系腾讯云处理。 |
集群单机检测 FabricManager 服务报错 | 检测 FabricManager 服务报错个数 | 异常 | |
集群单机检测 NVLink P2P 状态异常 | 检测 NVLink P2P 状态异常 | 异常 | |
集群单机检测 PCIe 链路故障 | 检测 PCIe 链路故障个数 | 异常 | |
集群单机检测 Row remapper 状态 | 检测 Row remapper 失败的GPU 故障的个数 | 异常 | |
集群单机检测 SRAM UCE 超标的 GPU 故障 | 检测 SRAM UCE 超标的 GPU故障个数 | 异常 | |
集群单机检测驱动状态 | 检测驱动状态 | 异常 | |
集群单机检测 GPU 初始化状态 | 检测 GPU 初始化状态 | 异常 | |
集群单机检测 InfoROM 状态 | 检测 InfoROM 状态 | 异常 |
前提条件
相关操作
集群自助检测功能支持诊断硬件和软件配置一致性并提供诊断报告。
启动检测
1. 登录 云服务器控制台,在左侧导航栏选择高性能计算集群。
2. 在高性能计算集群列表页面中,选择集群所在地域。
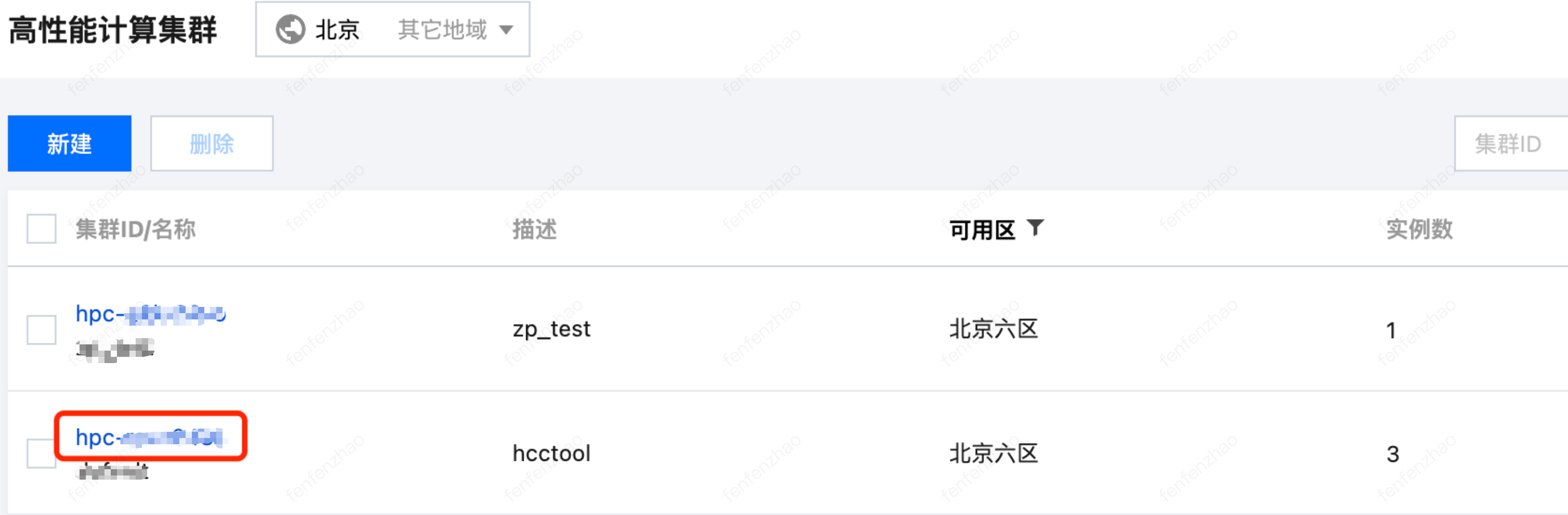
3. 单击集群 ID,进入集群详情页面。
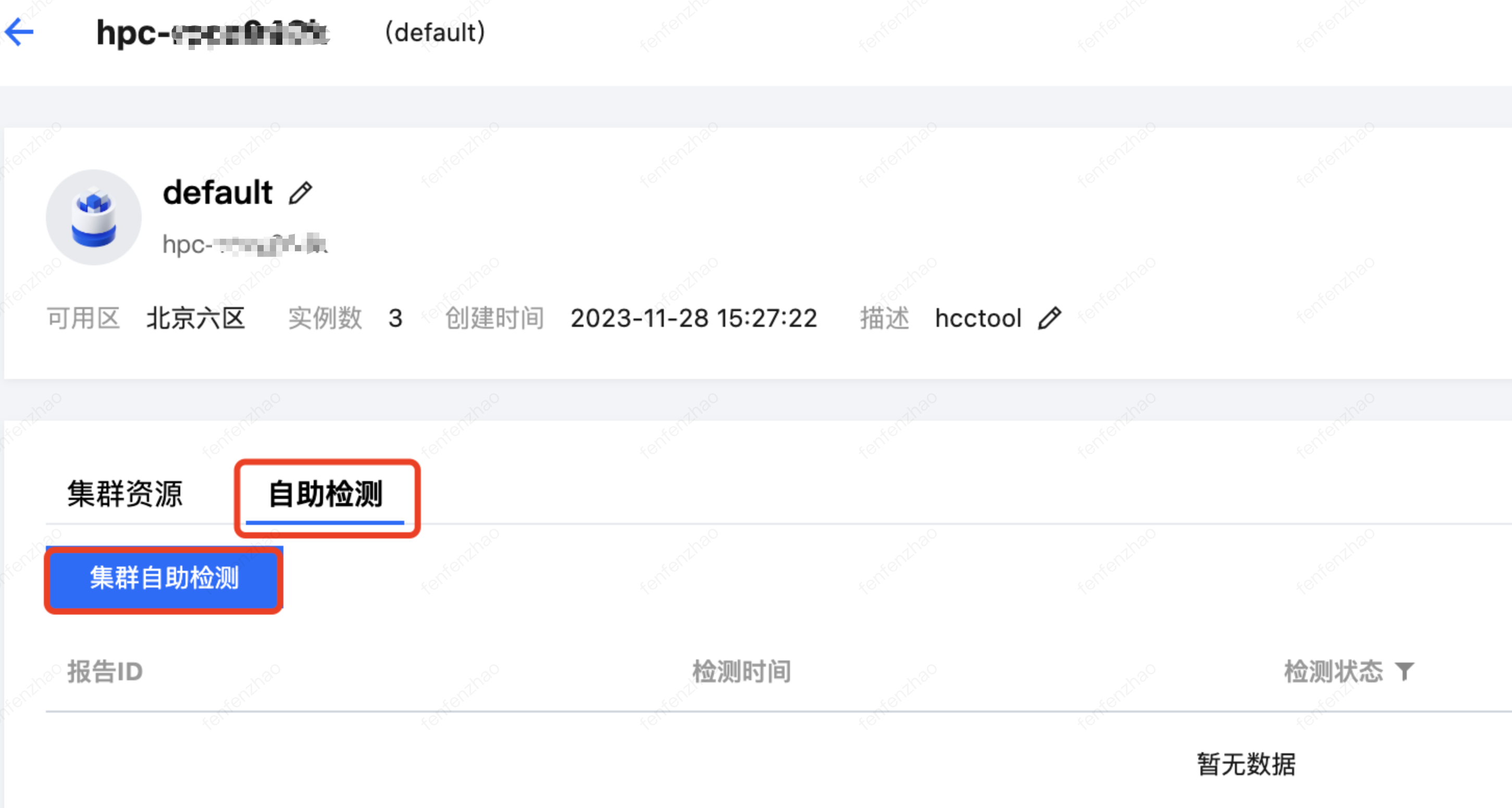
4. 在自助检测页签,单击集群自助检测。
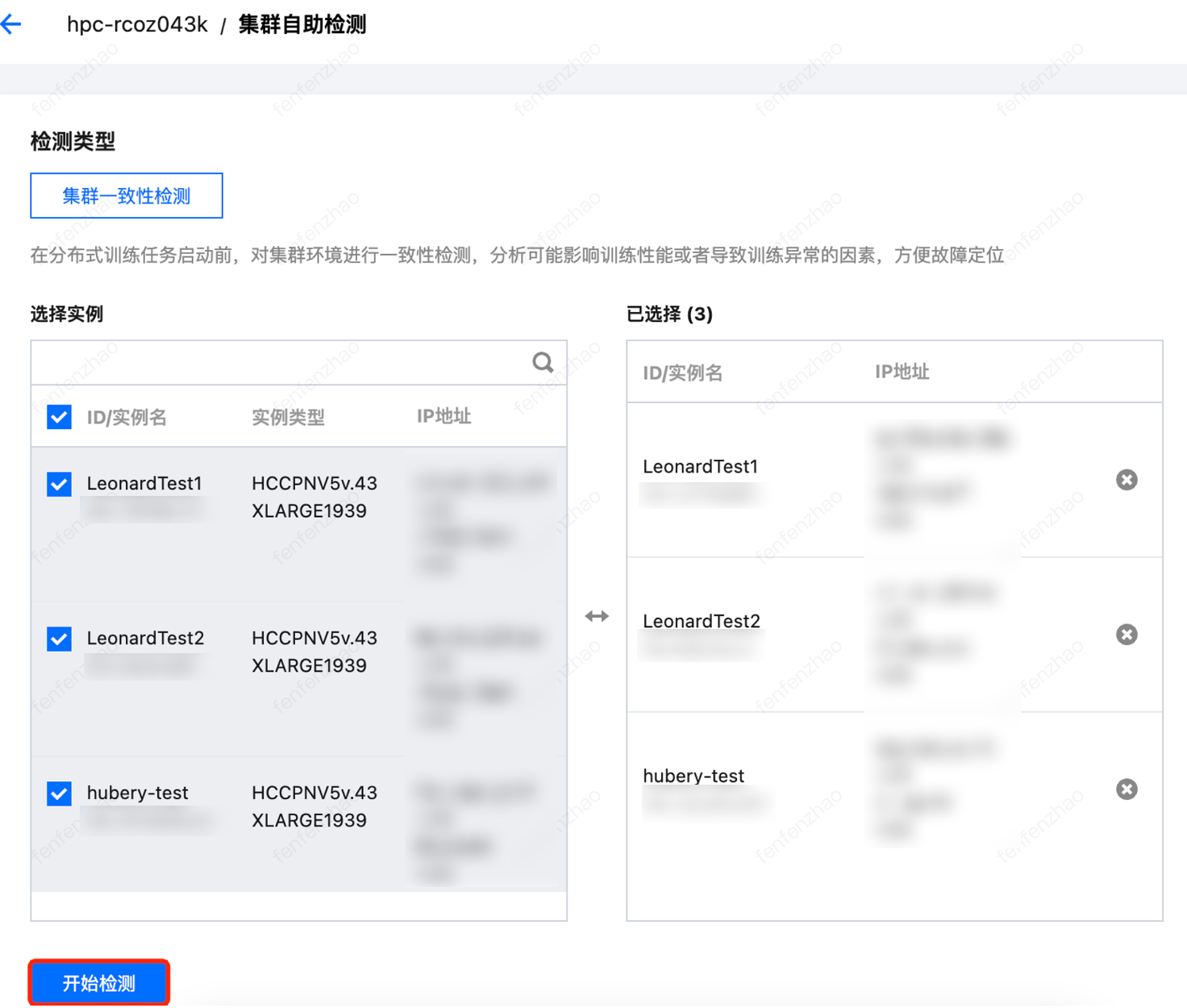
5. 选择本次检测的实例,单击开始检测。
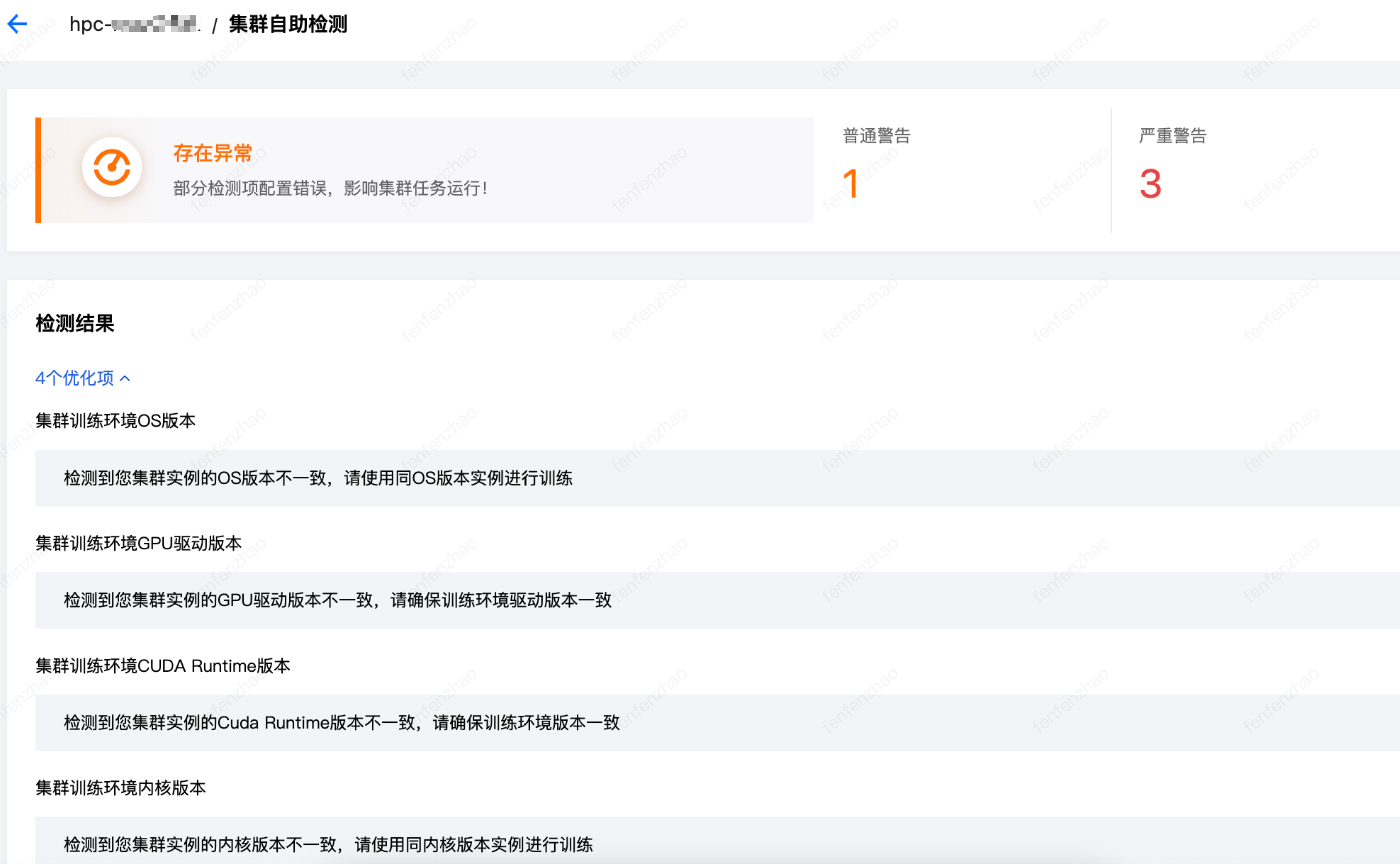
开始检测后,需要稍等几分钟。

检测完成,页面会显示检测结果。
查看历史报告
1. 登录 云服务器控制台,在左侧导航栏选择高性能计算集群。
2. 在高性能计算集群列表页面中,选择集群所在地域。
3. 单击集群 ID,进入集群详情页面。
4. 单击查看报告,即可查看历史检测报告。