监控与告警是保证高性能计算集群 GPU 型实例高可靠性、高可用性和高性能运行的重要部分。创建实例时,默认免费开通腾讯云可观测平台。您可以通过 云服务器控制台 查看监控指标,详细说明请参见 云服务器监控内容。NVIDIA GPU 系列实例另外提供了监控 GPU 使用率,显存使用量,功耗以及温度等参数的能力。
说明:
监控功能是通过在 GPU 型实例上部署安装相关 GPU 驱动、nvidia-fabricmanager 服务和 云服务器监控组件 来实现的,公共镜像默认包含云服务器监控组件,只需安装 GPU 驱动。如果您使用自定义镜像,需手动安装云服务器监控组件和 GPU 驱动。
在控制台查看 GPU 监控指标
单击 GPU 列表中的 
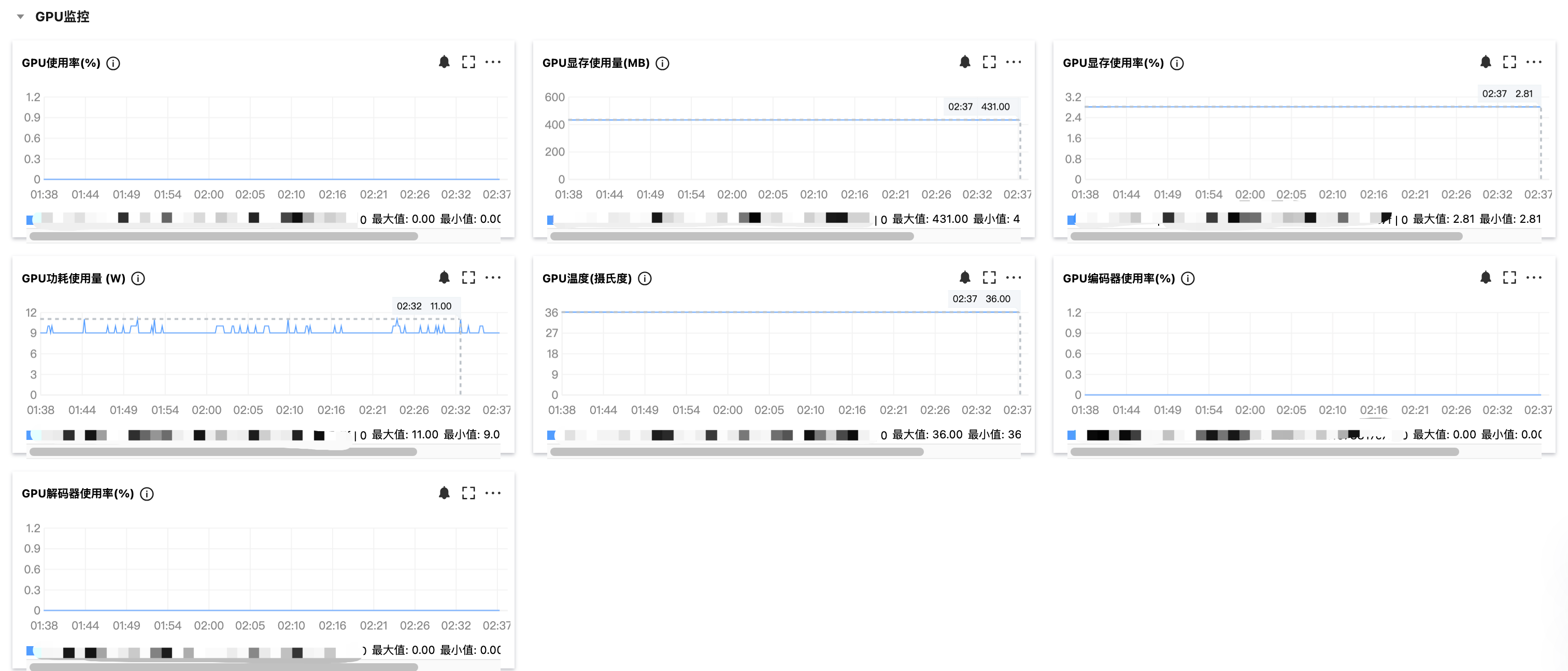
参数说明:
指标名称 | 含义 | 单位 | 维度 |
GPU 使用率 | 评估负载所消耗的计算能力,非空闲状态百分比 | % | per-GPU |
GPU 显存使用量 | 评估负载对显存占用 | MB | per-GPU |
GPU 显存使用率 | 评估负载对显存占用百分比 | % | per-GPU |
GPU 功耗使用量 | 评估 GPU 耗电情况 | W | per-GPU |
GPU 温度 | 评估 GPU 散热状态 | 摄氏度 | per-GPU |
GPU 编码器使用率 | 评估编码器使用百分比 | % | per-GPU |
GPU 解码器使用率 | 评估解码器使用百分比 | % | per-GPU |
在控制台查看 RDMA 监控指标
1. 在 高性能计算集群 中选择单击集群 ID 或查看详情,可看到集群的 GPU 服务器实例详情。
2. 单击 GPU 实例 列表中的 
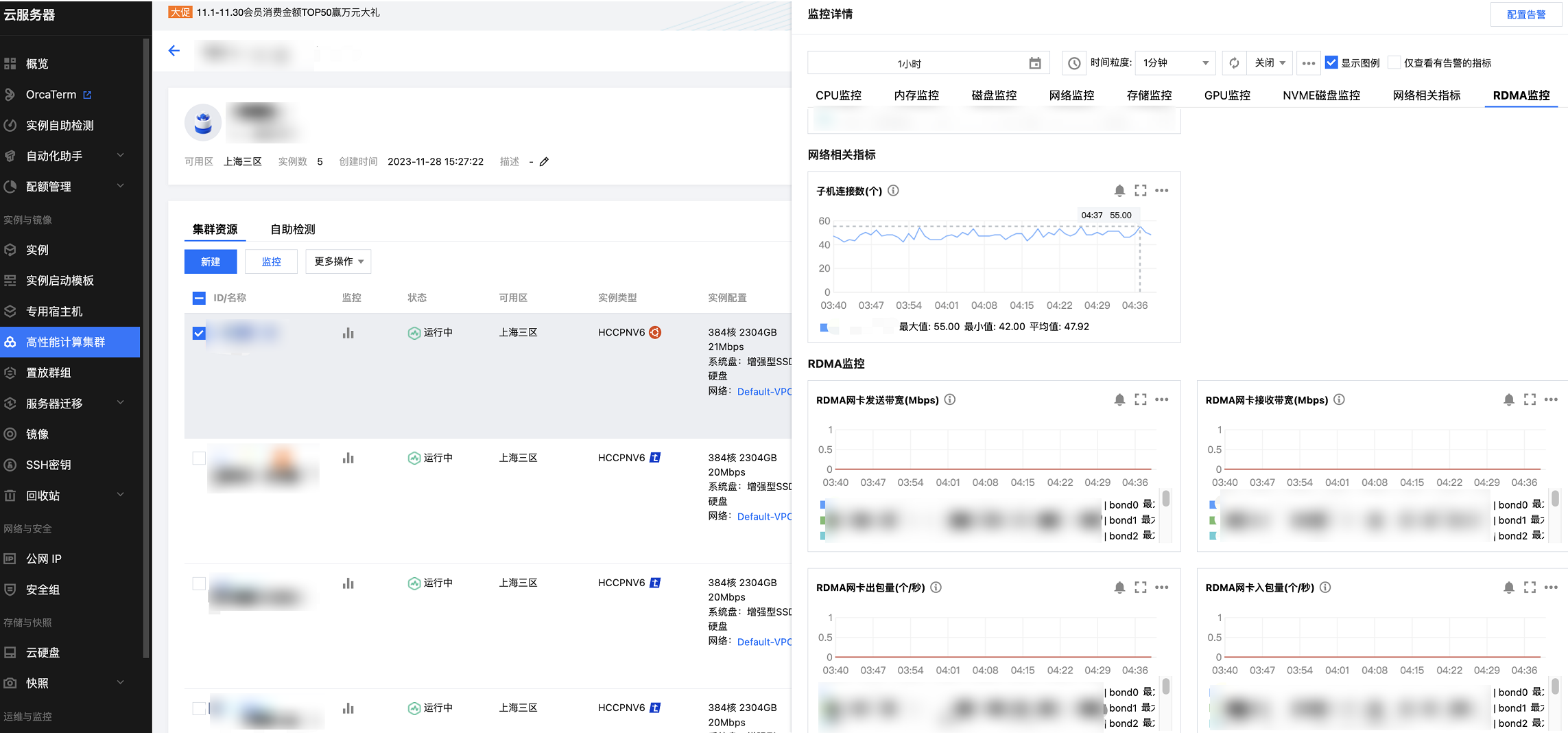
参数说明:
指标中文名 | 含义 | 单位 | 维度 |
RDMA 网卡接收带宽 | RDMA 网卡接收带宽 | MBit/s | InstanceId |
RDMA 网卡发送带宽 | RDMA 网卡发送带宽 | MBit/s | InstanceId |
RDMA 网卡入包量 | RDMA 网卡入包量 | 个/秒 | InstanceId |
RDMA 网卡出包量 | RDMA 网卡出包量 | 个/秒 | InstanceId |
说明:
在腾讯云可观测平台查看监控指标
1. 登录 腾讯云可观测平台,左侧导航栏中选择 Dashboard ,进入 Dashboard 列表页。
2. 在 Dashboard 列表中,单击 新建 Dashboard,在新的 Dashboard 选择新建图表。
在指标处选择 GPU / 云服务器 / GPU 监控,单击您关注的指标,自定义监控面板进行多实例展示,如下图所示:
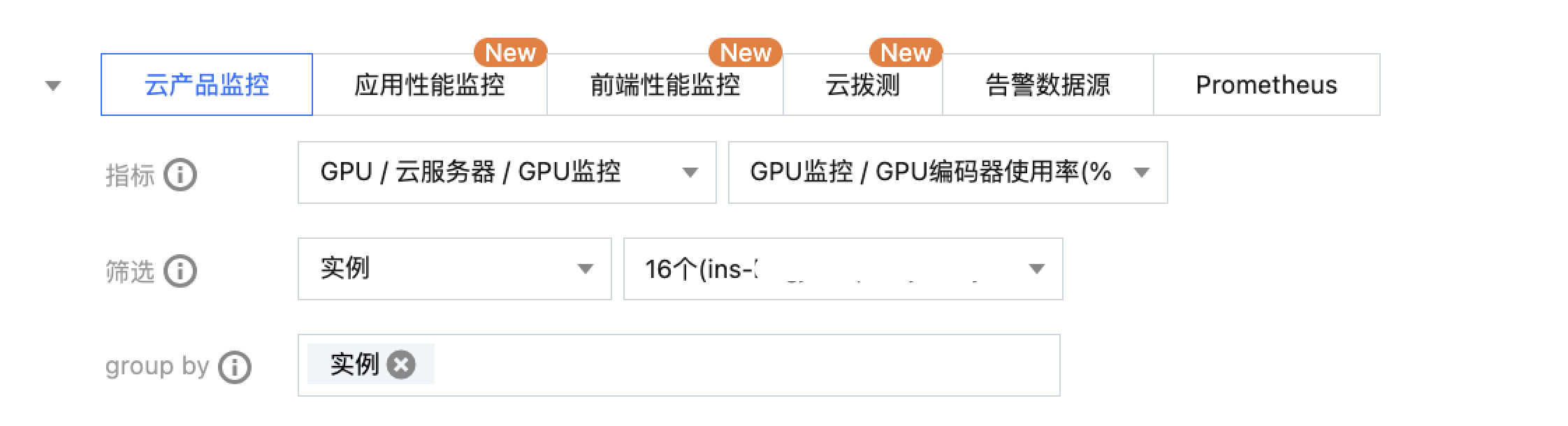
指标英文名 | 指标中文名 | 指标说明 | 单位 | 维度 |
Gpumemusage | GPU 显存使用率 | GPU 显存使用率 | % | per-GPU |
GpuMemUsed | GPU 显存使用量 | 评估负载对显存占用 | MB | per-GPU |
Gpupowdraw | GPU 功耗使用量 | GPU 功耗使用量 | W | per-GPU |
Gpupowusage | GPU 功耗使用率 | GPU 功耗使用率 | % | per-GPU |
Gputemp | GPU 温度 | 评估 GPU 散热状态 | 摄氏度 | per-GPU |
Gpuutil | GPU 使用率 | 评估负载所消耗的计算能力,非空闲状态百分比 | % | per-GPU |
GpuEncUtil | GPU 编码器使用率 | GPU 编码器使用率 | % | per-GPU |
GpuDecUtil | GPU 解码器使用率 | GPU 解码器使用率 | % | per-GPU |
在指标处选择 云服务器 / RDMA 监控,单击您关注的指标,自定义监控面板进行多实例展示,如下图所示:
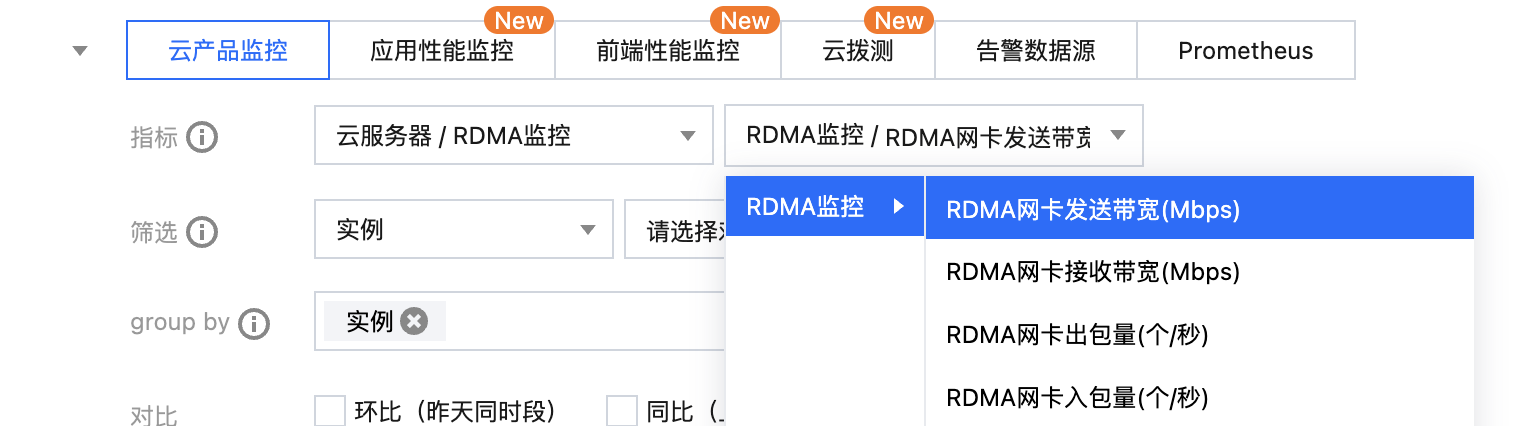
指标英文名 | 指标中文名 | 指标说明 | 单位 | 维度 |
RdmaIntraffic | RDMA 网卡接收带宽 | RDMA 网卡接收带宽 | MBit/s | InstanceId |
RdmaOuttraffic | RDMA 网卡发送带宽 | RDMA 网卡发送带宽 | MBit/s | InstanceId |
RdmaInpkt | RDMA 网卡入包量 | RDMA 网卡入包量 | 个/秒 | InstanceId |
RdmaOutpkt | RDMA 网卡出包量 | RDMA 网卡出包量 | 个/秒 | InstanceId |
CnpCount | CNP 统计量 | 拥塞通知报文统计 | 个/秒 | InstanceId |
EcnCount | ECN 统计量 | 显示拥塞通知统计 | 个/秒 | InstanceId |
RdmaPktDiscard | 端测丢包量 | 端测丢包量 | 个/秒 | InstanceId |
RdmaOutOfSequence | 接收方乱序错误量 | 接收方乱序错误量 | 个/秒 | InstanceId |
RdmaTimeoutCount | 发送方超时错误量 | 发送方超时错误量 | 个/秒 | InstanceId |
TxPfcCount | TX PFC 统计量 | TX PFC 统计量 | 个/秒 | InstanceId |
RxPfcCount | RX PFC 统计量 | RX PFC 统计量 | 个/秒 | InstanceId |
监控指标告警配置
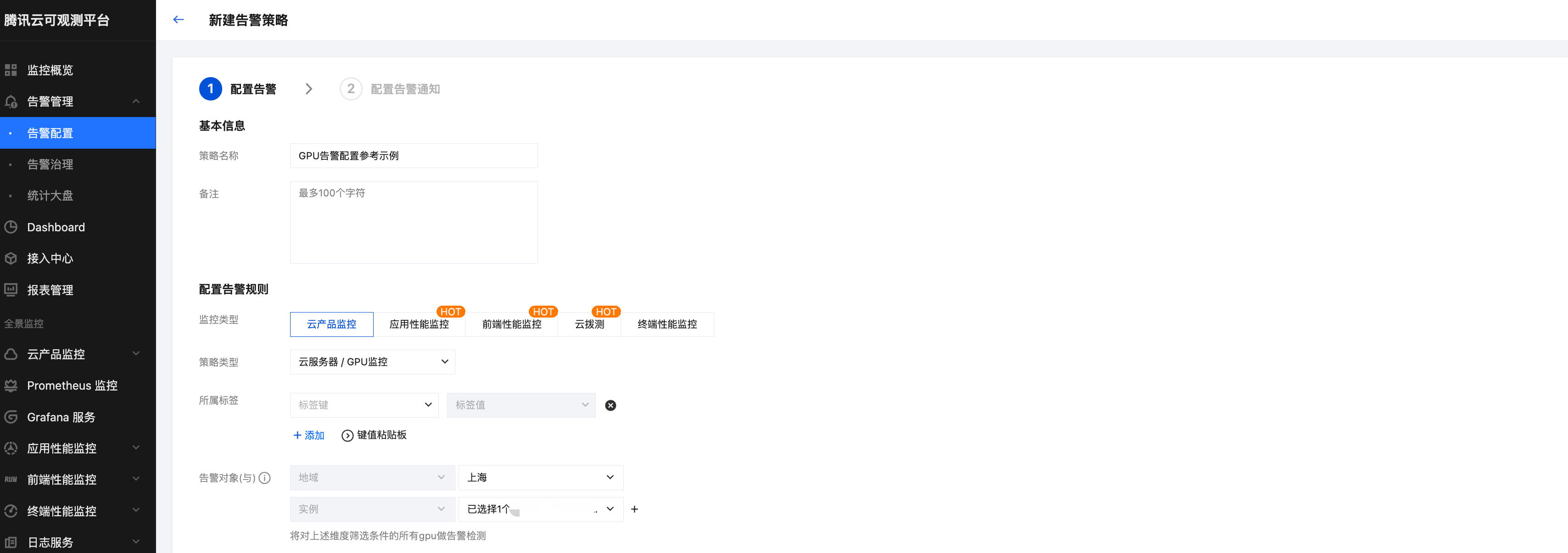
1. 登录 腾讯云可观测平台,在左侧导航栏中,选择告警管理 > 告警配置。
2. 单击 新建告警策略,在监控类型选择云产品监控,策略类型中选择云服务器 / GPU 监控,选择您希望接收告警的 GPU 实例对象,触发条件选择手动配置。
3. GPU 云服务器监控支持以下指标告警:GPU 内存使用率、GPU 功耗使用率、GPU 使用率、GPU 温度、GPU 是否存在显存页需隔离、GPU 显存是否发生 UCE 等。您可以参考下图进行配置告警。告警通知的配置可参见 新建通知模板,支持通过多种渠道进行通知。
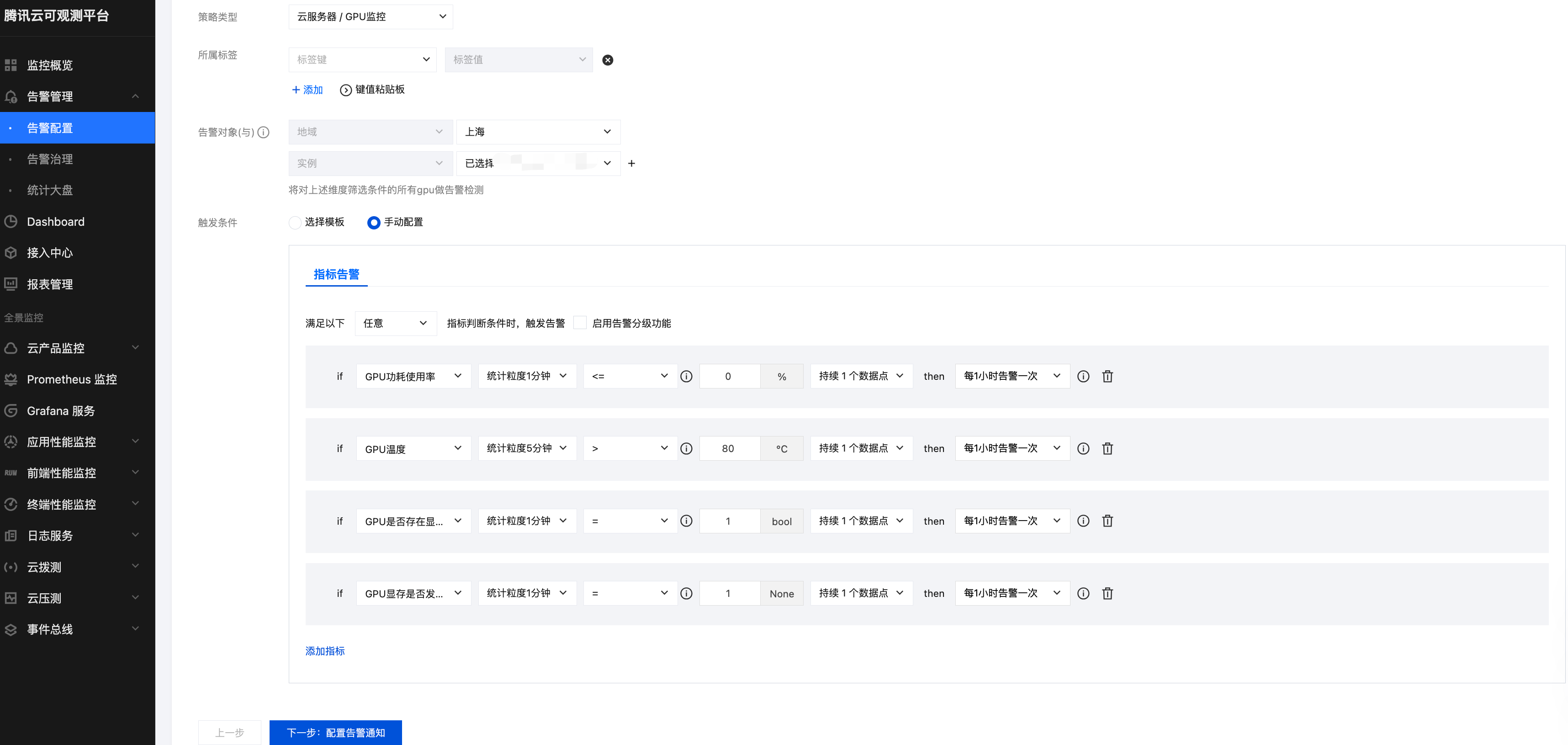
常用告警指标参考如下:
指标名称 | 建议告警阈值 | 描述 | 处理建议 |
GPU 功耗使用率 | <=0 | 功耗小于0时可能功率出现Unknown Error 了,会影响 GPU 的正常使用。 | 执行 nvidia-smi 命令查看 GPU 的功率是否有 ERR 或 nvidia-smi -i <target gpu> -q |grep "Power Draw" 是否为 Unknown Error,若存在该现象则尝试重启机器恢复及更新驱动观察。若重启无法恢复 提交工单 联系腾讯云支持。 |
GPU 温度 | 持续5分钟>80 | 当 GPU 温度过高时可能会导致 GPU SlowDown,影响业务性能。 | |
GPU 是否存在显存页需隔离 | =1 | 安培以下架构 GPU 出现了 ECC ERROR,应用进程被 kill,GPU卡处于pending 状态。 | 执行 nvidia-smi -i <target gpu> -q -d PAGE_RETIREMENT 命令查看是否有 GPU 卡处于 pending 状态,重置 GPU 卡或重启实例恢复。若重启无法恢复 提交工单 联系腾讯云支持。 |
GPU 显存是否发生 UCE | =1 | 安培及以上架构 GPU 出现了 ECC ERROR,应用进程被 kill,GPU卡处于pending 状态。 | 执行 nvidia-smi -i <target gpu> -q -d ROW_REMAPPER 命令查看是否有 GPU 卡处于 Pending 状态,重置 GPU 卡或重启实例恢复。若重启无法恢复 提交工单 联系腾讯云支持。 |
GPU 内存使用率 | 仅保持观察 | - | 评估负载对显存占用。 |
GPU 使用率 | 仅保持观察 | - | 评估负载对 GPU 流处理器占用。 |
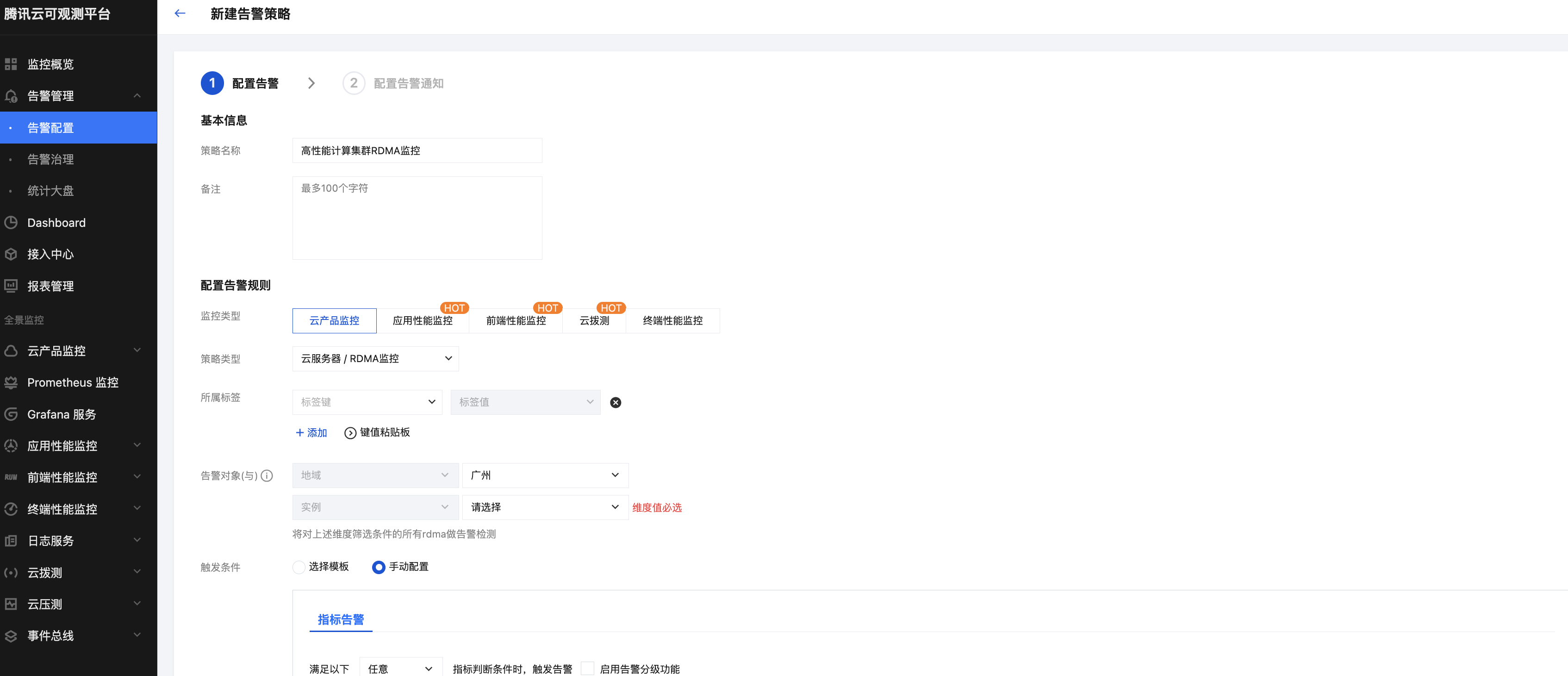
指标告警参考如下配置:
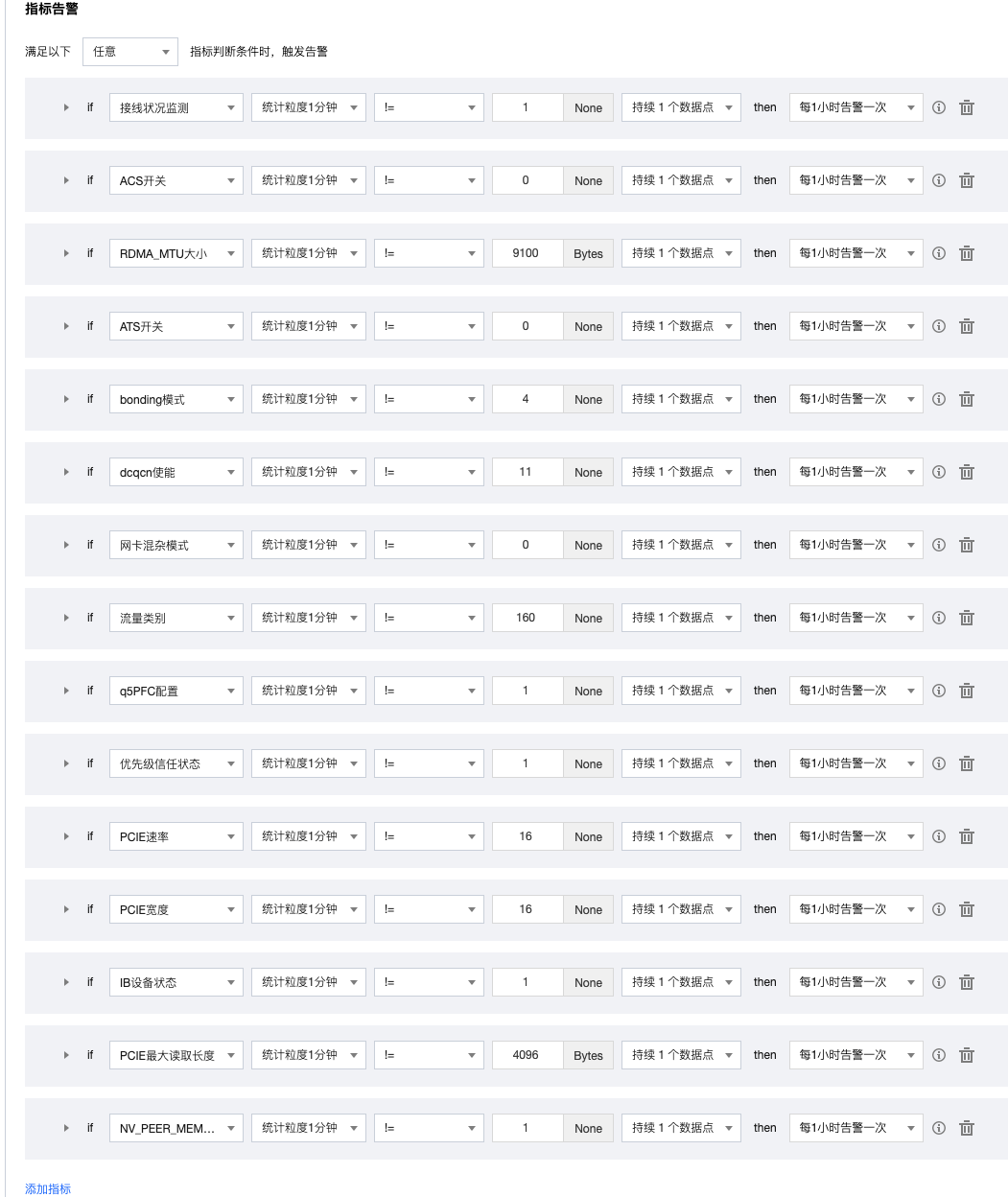
2. 告警通知可参见 新建通知模板 配置,支持多渠道通知。
配置完成后策略查看截图如下:
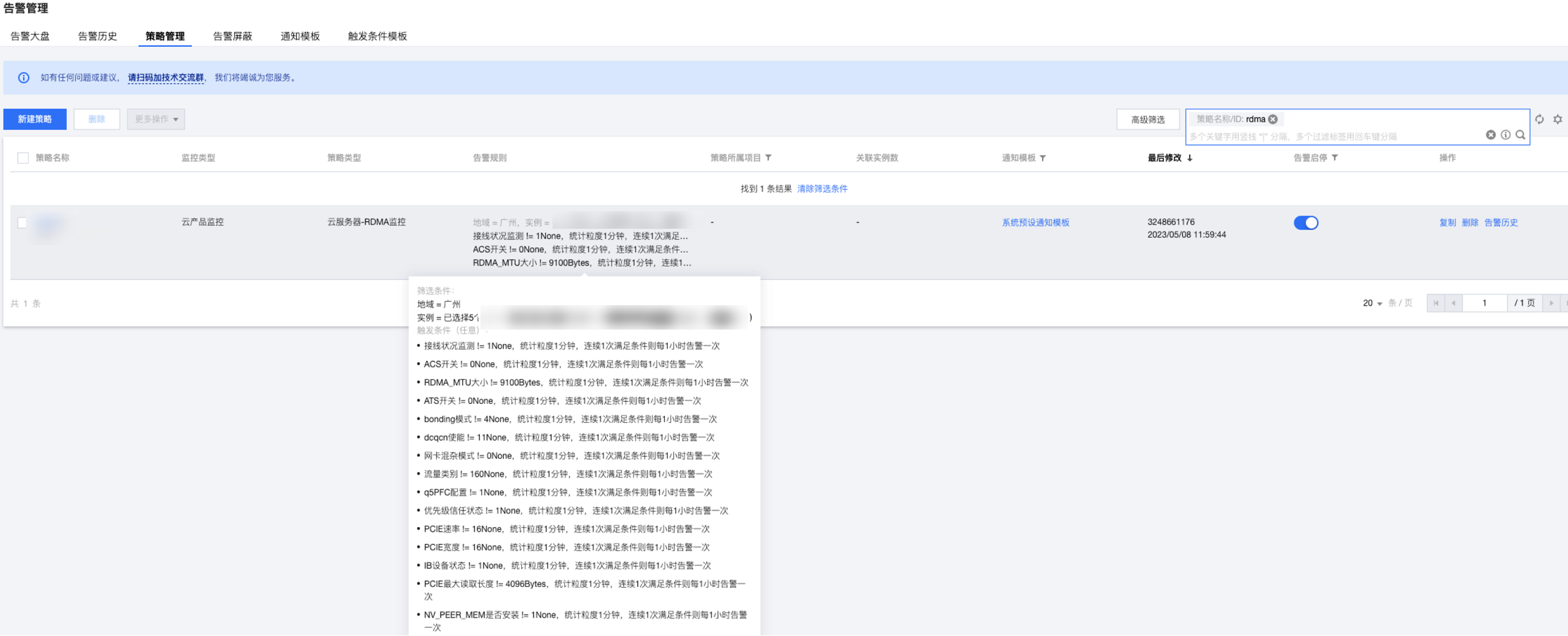
告警示例截图如下:

高性能计算集群 GPU 型实例 RDMA 告警处理建议如下:
监测指标 | 指标名 | 错误描述 | 正确配置值 | 处理策略 | 客户更正方式 | 设备 |
接线状况监测 | link_detected | 链路 down | 1(1代表端口 up) | 客户尝试软件恢复,如无法恢复,授权运维维修 | ifconfig $ethname up | eth |
ACS 开关 | acs | ACS 开关配置错误 | 0(0代表关闭 ACS) | 客户改正配置(需要重启机器) | bash /etc/acsctl_online.sh disable_acsctl | eth |
RDMA_MTU 大小 | active_mtu | RDMA 卡的 MTU配置错误(影响性能) | 9100 | 客户更正配置即可 | ifconfig $ethname mtu 9100 | bond |
ATS 开关 | ats_enabled | ATS 开关配置错误 | 0(0代表关闭 ATS) | 客户改正配置(需要重启机器) | // 关闭 ATS for i in `lspci -d 15b3: | awk '{print $1}'`; do echo $i; mlxconfig -d $i -y s ATS_ENABLED=0; done // 重启之后确认状态 for i in `lspci -d 15b3: | awk '{print $1}'`; do echo $i; mlxconfig -d $i q | grep ATS_ENABLED; done | eth |
bonding 模式 | bonding_mode | bonding 模式配置错误 | 4(4代表双发模式) | 客户更正配置即可 | cd /usr/local/qcloud/rdma/; sh set_bonding.sh; sh dscp.sh | bond |
dcqcn 使能 | dcqcn_enable | dcqcn 未使能 | 11(两个1分别代表 rp和 np 的状态) | 客户更正配置即可 | echo 1 > /sys/class/net/$ethname/ecn/roce_rp/enable/5 echo 1 > /sys/class/net/$ethname/ecn/roce_np/enable/5 | eth |
网卡混杂模式 | eth_promisc | 网卡误配为混杂模式 | 0(0代表非混杂模式) | 客户更正配置即可 | ifconfig $ethname -promisc | eth |
流量类别 | traffic_class | 流量类别配置错误 | 160 | 客户更正配置即可 | echo 160 > /sys/class/infiniband/$RDMA_name/tc/1/traffic_class | bond |
q5 PFC 配置 | q5_pfc_enabled | PFC 未使能,存在QOS ERROR | 1(1代表 PFC 使能) | 客户更正配置即可 | mlnx_qos -i $ethname -f 0,0,0,0,0,1,0,0 | eth |
优先级信任状态 | prio_trust_state | 优先级信任状态配置错误 | 1(1代表 dscp) | 客户更正配置即可 | mlnx_qos -i $ethname --trust=dscp | eth |
pcie 速率 | max_link_speed | PCIE GEN 配置错误 | 16 | 客户更正配置即可 | eth | |
pcie 宽度 | max_link_width | PCIE width 配置错误 | 16 | 客户更正配置即可 | eth | |
IB 设备状态 | link_state | bond 口下两个 eth口全部 down | 1(1代表 bond 口up) | 客户尝试软件恢复,如无法恢复,授权运维维修 | ifconfig $ethname up | bond |
MRSS PCIE 最大读取长度 | mrss | MRSS 配置错误 | 4096 | 客户更正配置即可 | lspci -D -nn | grep 15b3 |awk -F' ' '{print $1}' |xargs -I {} setpci -s {} 68.w=5936 | eth |
NV_MEM_PEER 是否安装 | nv_peer_mem_state | nvidia_peermem 模块未加载 | 1(1代表模块已加载) | 客户加载模块即可 | modprobe nvidia_peermem | 整机 |



