背景信息
随着数据智能技术的不断发展,图像搜索技术在各行各业中的应用越来越广泛。传统的图像搜索技术往往依赖于图像的元数据或标签,存在信息更新不及时、垂直领域知识匮乏、搜索精度不高等问题。如何推进图像搜索技术在各行业、各业务场景的落地,成为各方普遍关注的问题。目前,基于向量检索的图像搜索技术正成为解决这些问题的有效方法,并逐渐成为数据智能时代的一个主要趋势。
图片向量检索技术通过将图片转换为高维向量,并在向量空间内计算相似度,实现高效、精准的图像搜索。本文将探讨如何结合腾讯云向量数据库和 CLIP(Contrastive Language-Image Pre-Training)图像处理模型,构建一站式的图搜应用解决方案。腾讯云向量数据库以其高性能、高可用性、大规模数据处理能力、低成本和简单易用性等优势,为用户提供了强大的向量数据存储和检索能力。结合 CLIP 模型,可实现通过向量相似性检索的方式搜索图片,并提升图像搜索的准确性和效率,适用于电商推荐、内容审核、智能相册等多种图像处理任务。
准备工作
1. 选型并购买向量数据库实例。具体操作,请参见 购买实例。
2. 客户端运行环境准备。
3. 下载 graph_emb_demo1030.zip 压缩包,并将其上传于运行环境。
4. 下载图像文件 vdb_test_graphs.zip,存放于本地环境。
快速搭建
1. 登录客户端运行环境,执行
pip3 install tcvectordb,安装向量数据库最新的 Python SDK。2. 使用
unzip 命令,解压 graph_emb_demo1030.zip 压缩包。3. 进入压缩包解压后的文件夹,执行
pip3 install -r requirements.txt 命令,安装 SDK 通用依赖,模型 SDK 以及相关依赖组件。4. 使用
vim conf/config.ini 命令,根据参数注释修改相关配置并保存,如下所示。[vector_db]# 腾讯云向量数据库访问地址。address=http://xxx:xxx# 向量数据库实例密钥key=xxxxxxxx# AI类向量数据库ai_db=test_ai_db# 向量数据库集合名ai_collection=test_ai_graph_collection# CLIP 模型以及存放路径[download_model]local_model_path=models/model_name=openai/clip-vit-base-patch32[graph_upload]local_graph_path=graphs/[server]# 启动服务的地址和端口name=127.0.0.1port=8080
配置项 | 参数名 | 参数含义 | 配置说明 |
[vector_db] | address | 向量数据库实例的内网地址或外网地址。建议使用内网方式。 | |
| key | 向量数据库实例 API 密钥,用于进行身份认证。 | |
| ai_db | AI 类数据库名。 | Database 命名要求如下: 只能使用英文字母,数字,下划线_、中划线-,并以英文字母开头。 长度要求:[1,128]。 |
| ai_collection | AI 数据库集合视图名。 | CollectionView 命名要求如下: 只能使用英文字母,数字,下划线_、中划线-,并以英文字母开头。 长度要求:[1,128]。 |
[download_model] | local_model_path | CLIP 模型存放路径。 | 脚本运行将下载 CLIP 模型,需指定其客户端存放路径。本示例使用相对路径,指定于压缩包所在文件夹 models下。 |
| model_name | CLIP 模型名称。 | 默认为 openai/clip-vit-base-patch32模型。如需更换为其他 CLIP 模型,请参见 Huggingface Models。注意格式:Hugging face 仓库名/模型名称。 |
[graph_upload] | local_graph_path | 图像文件压缩包存放路径。 | 本示例使用相对路径,指定于压缩包所在文件夹 graph下。 |
[server] | name | 客户端运行环境 IP 地址。 | - |
| port | 运行环境分配的端口。 | 注意避免端口冲突。 |
5. 执行
python3 main.py,运行脚本,生成图搜应用前端访问链接,如下图所示。
6. 复制
Running on local URL 后面的访问链接,在浏览器访问链接,显示 Tencent VectorDB AI Demo -- Graph search 配置向导页面,如下图所示。注意:
在浏览器访问图搜应用,切勿关闭后端运行环境正在运行的进程。
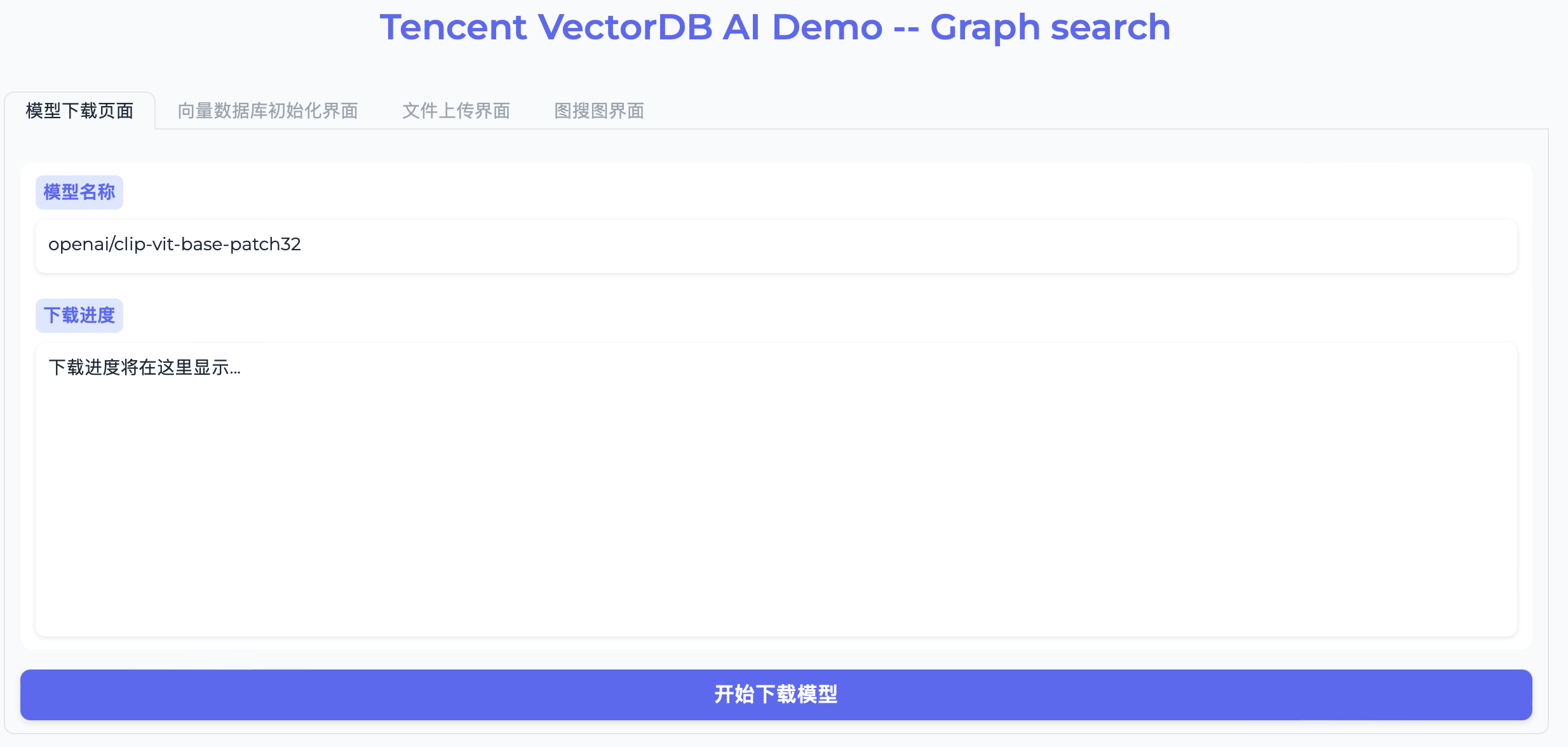
7. 在模型下载页面,单击开始下载模型,下载 CLIP 模型,模型文件将保存在配置文件中 local_model_path 指定的路径,默认下载至 `models/` 目录。
说明:
下载模型首次可能需要较长时间,可在后端运行环境查看下载进度,请耐心等待。之后再次下载时,系统会自动检测到模型已存在,可迅速完成操作。
如果在下载模型的过程中遇到网络连接错误,可能是因为服务器与 Hugging Face 网站之间的连接不稳定,可以重新点击下载按钮来继续之前的下载过程。
在模型名称输入框,也可以编辑更新为其他 CLIP 模型,配置文件也会同步更新。更多模型信息,请参见 Huggingface Models。注意格式:Hugging face 仓库名/模型名称。
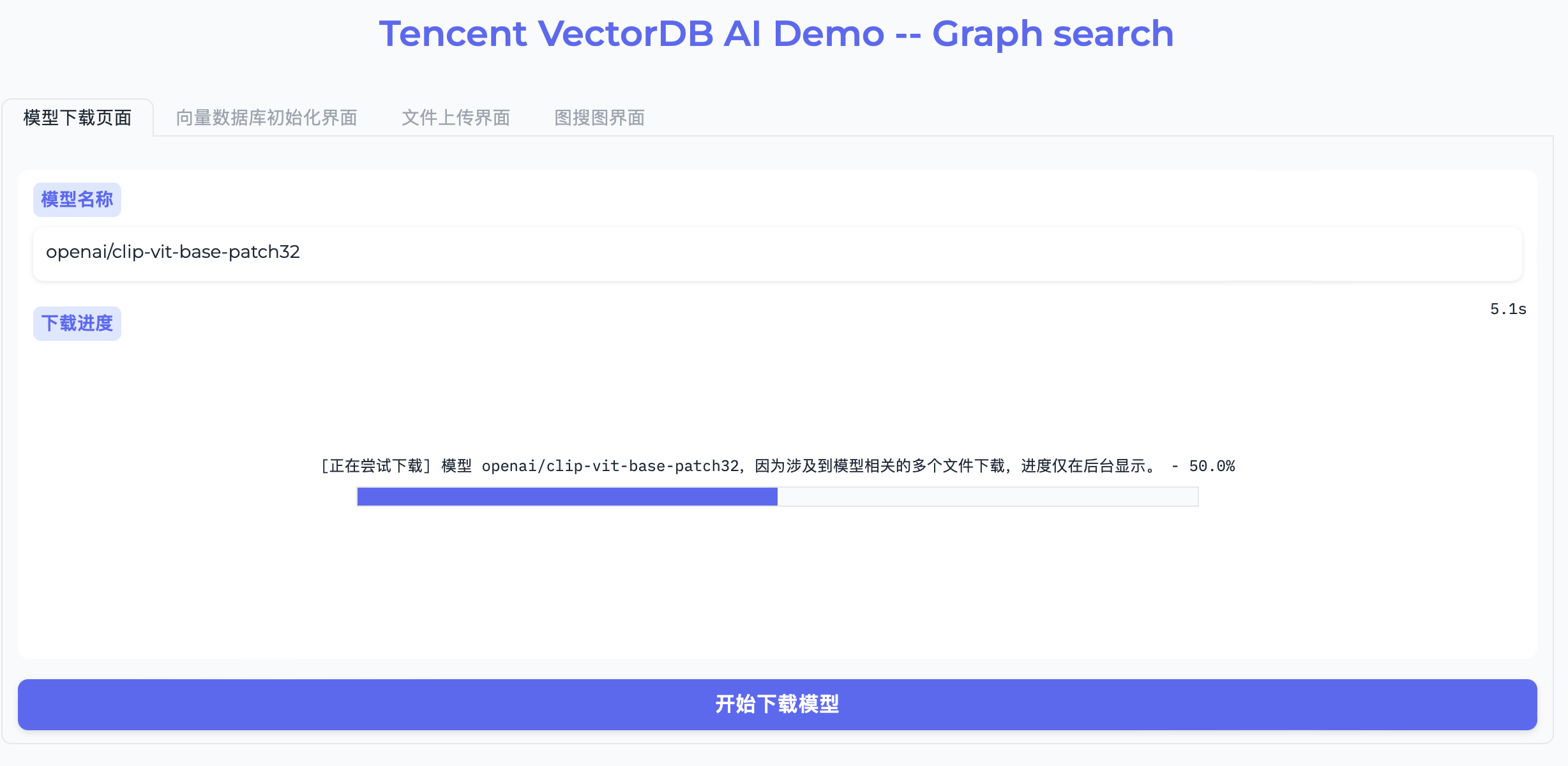
8. 切换至向量数据库初始化界面,单击初始化向量数据库,将自动在指定的实例创建向量数据库与集合,进行初始化,界面显示初始化进度,等待任务完成,如下图所示。
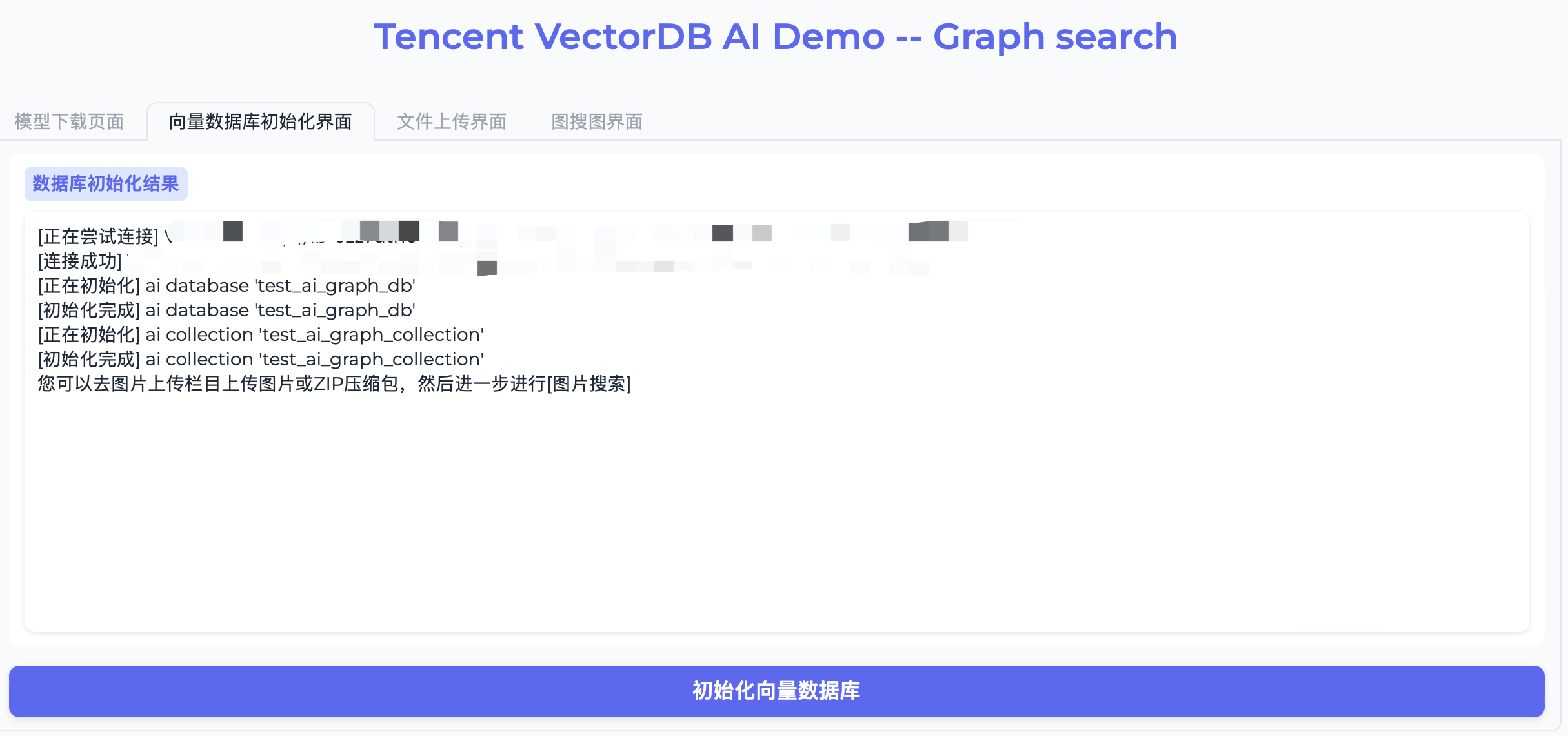
9. 切换至文件上传界面,在上传图片或ZIP压缩包区域,将已准备的图像文件 vdb_test_graphs.zip 直接拖放或者上传至应用程序,等待显示上传完成,单击下方的上传文件,程序将自动将图像文件上传于配置文件 config.ini 中 local_graph_path 指定的路径,并将图片向量化写入已创建的向量数据库中,如下图所示。
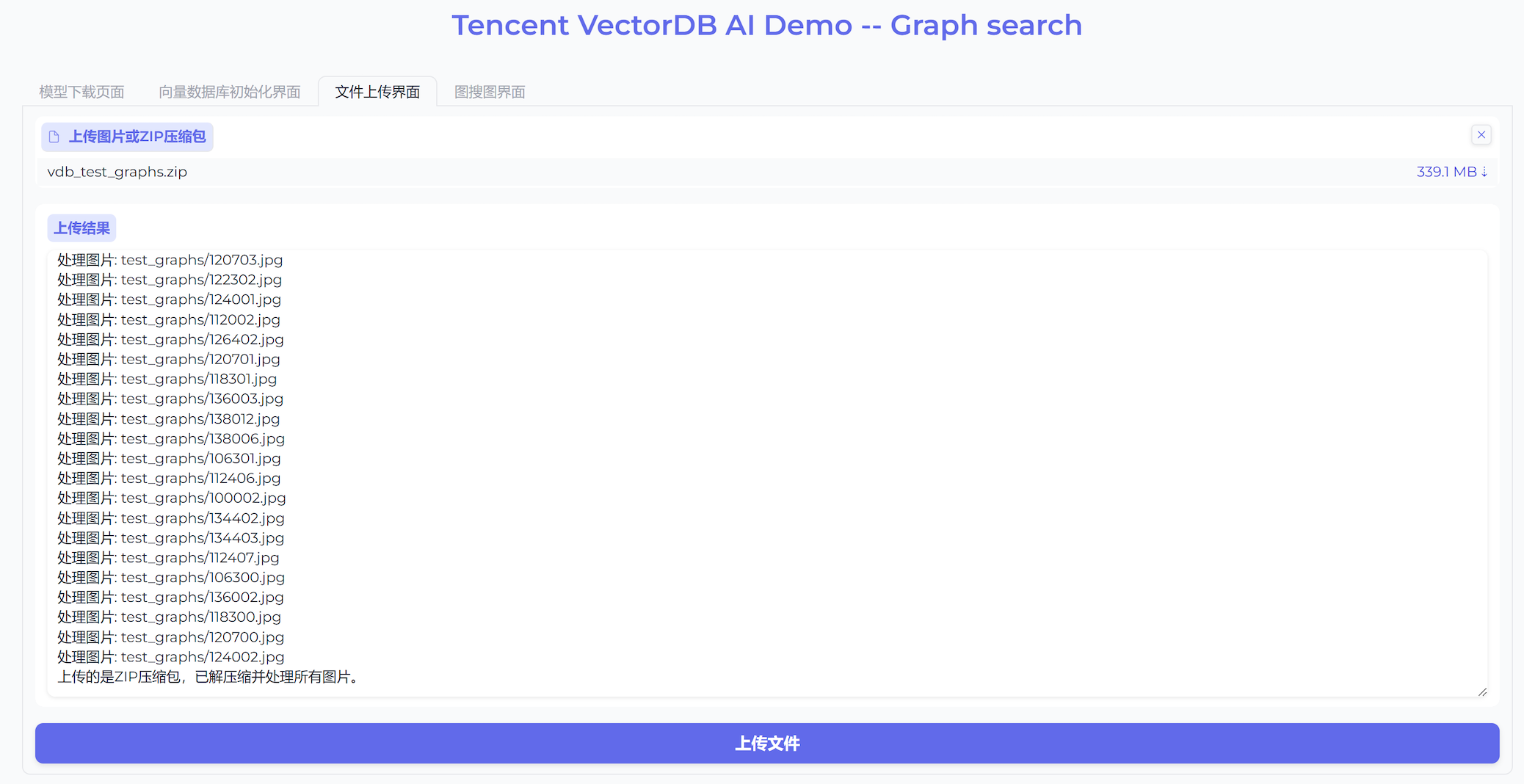
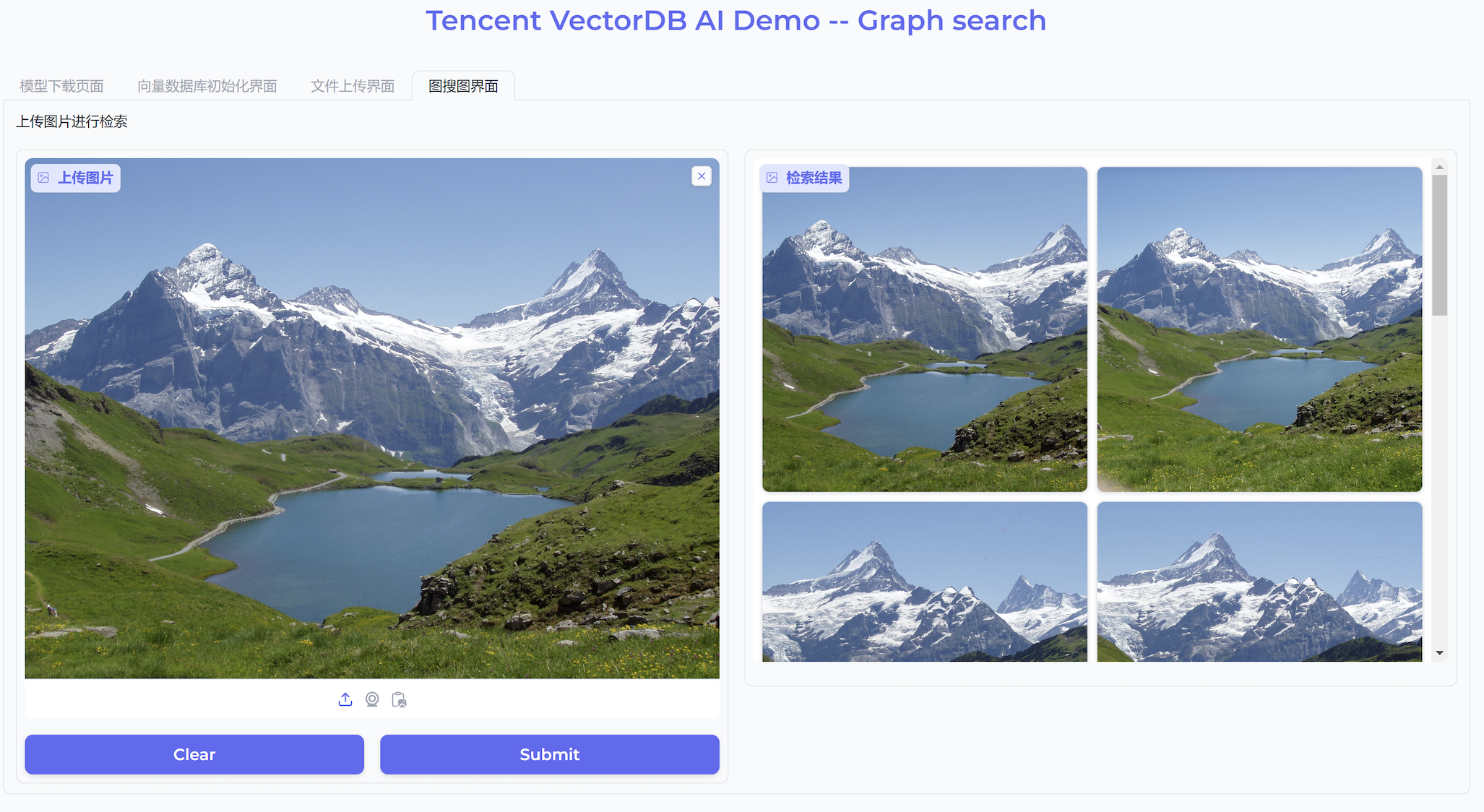
10. 切换至图搜图界面,在左侧上传图片进行检索区域,将需检索的图片拖放或上传于此处,单击 Submit,程序将自动检索,并在右侧检索结果区域显示其检索的结果,如下图所示。
遵循上述步骤,您将能够顺利运行图搜图 Demo 应用,上传图片集合,并利用图搜图功能查找相似图片。如果您有任何其他疑问,欢迎随时联系腾讯云向量数据库团队获取支持。
安装虚拟环境
如果您遇到环境之间依赖包冲突,可通过安装虚拟环境来解决。遵循以下步骤,确保虚拟环境安装所有必需的依赖。
使用 venv 创建虚拟环境
1. 创建虚拟环境。
python -m venv img_search_demo
2. 激活虚拟环境。
在 windows 操作系统
img_search_demo\\Scripts\\activate
在 macOS 或者 Linux 系统
source img_search_demo/bin/activate
3. 安装所需的依赖。
pip install -r requirements.txt
使用 conda 创建虚拟环境
1. 创建虚拟环境。
conda create --name img_search_demo python=3.9
2. 激活虚拟环境。
conda activate img_search_demo
3. 安装所需的依赖。
pip install -r requirements.txt



