操作场景
腾讯云高性能应用服务 HAI 是为开发者量身打造的澎湃算力平台。HAI 的 ChatGLM3-6B 应用,预装了支持 ChatGLM3-6B 模型运行的全部环境依赖。应用实例启动时,默认启动了 Gradio WebUI 服务,该服务对显存有一定的占用。
除了使用 HAI 官方的 Gradio WebUI 外,用户也可以手动中断 Gradio WebUI 服务对显存的占用,以利用 HAI 的预装环境依赖,部署自定义的代码项目。
中断 Gradio WebUI 服务
步骤1:打开终端
通过 JupyterLab 打开终端
1. 在 腾讯云控制台的页面,找到 ChatGLM3-6B 应用实例,进入实例管理页面,单击红框所示的 JupyterLab 连接算力。
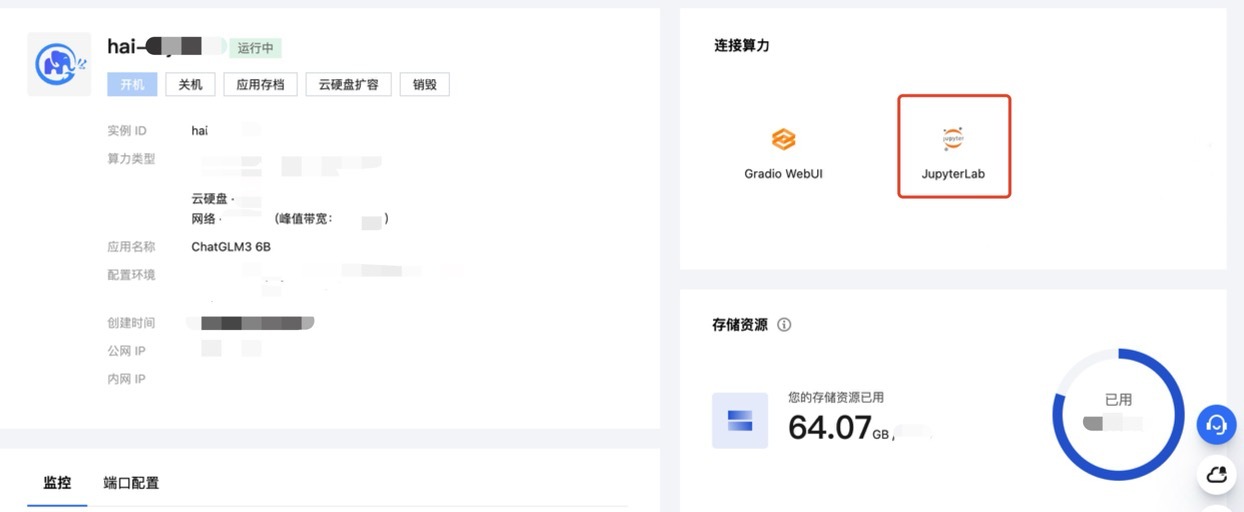
2. 在弹出的 JupyterLab 页面中,选择 Terminal。
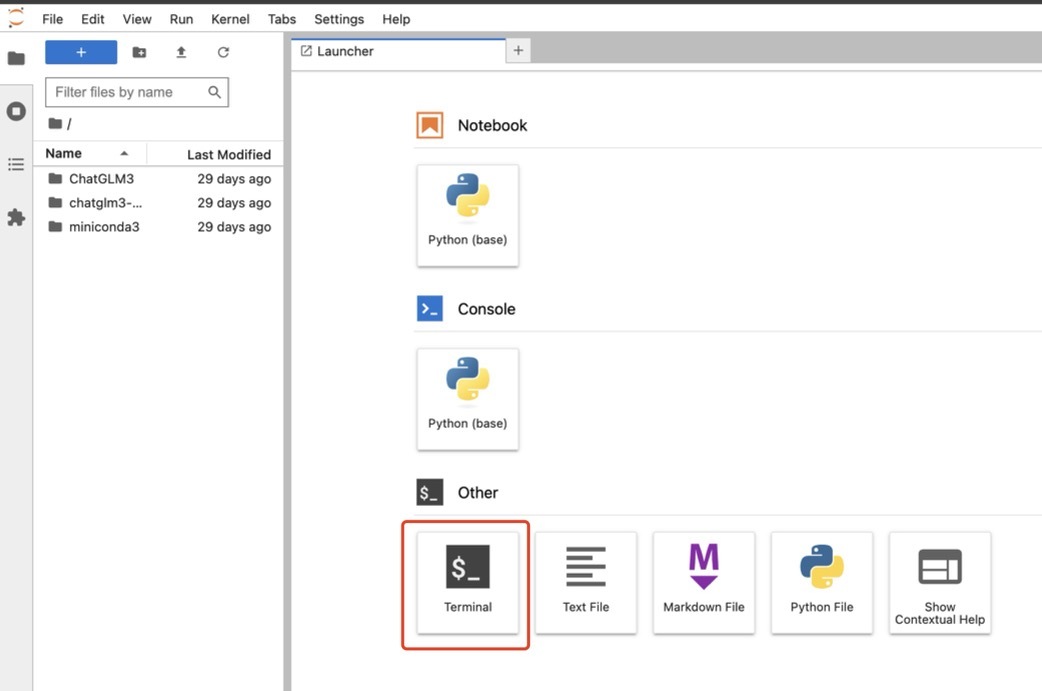
成功进入终端。
通过 SSH 客户端程序使用终端
步骤2:查找 Gradio WebUI 对应的进程
1. 在终端输入如下命令,查看活动进程:
ps aux
得到的活动进程信息展示如下:
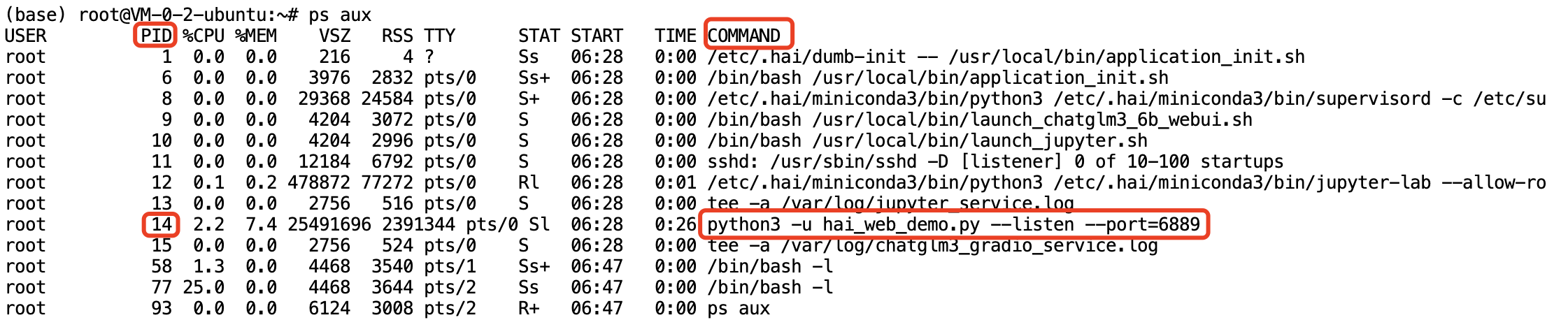
2. 找到 COMMAND 列中,涉及
hai_web_demo.py 字样的进程,记录其进程 PID,本例中进程 PID 为14。步骤3:终止 Gradio WebUI 对应的进程
在终端输入如下命令,终止 Gradio WebUI 对应的进程。请将命令中的
xxx 替换为上一步查找到的进程 PID。kill -9 xxx
注意:
终止错误的进程 PID 可能影响系统稳定性,请务必确认进程 PID 序号后再执行终止命令。
步骤4:查看显存占用情况
在终端输入如下命令,查看 GPU 使用情况。
nvidia-smi
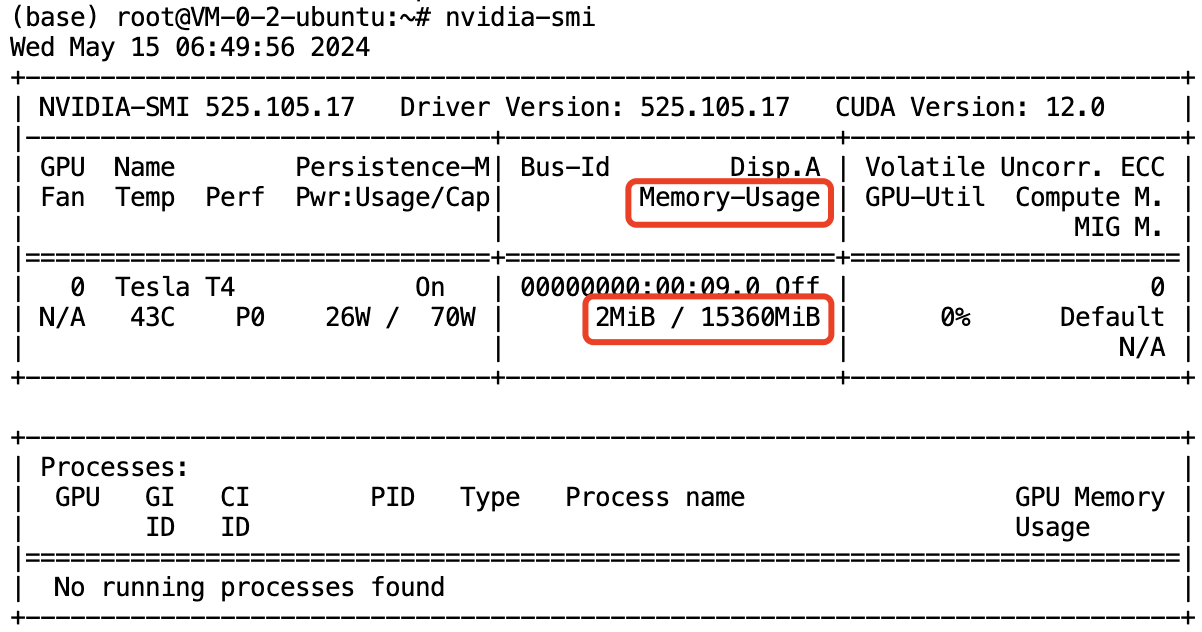
得到的 GPU 使用情况展示如下,如果成功终止 Gradio WebUI 对应的进程,Memory-Usage 一项对应的显存占用会变得很小,本示例中仅为 2M。
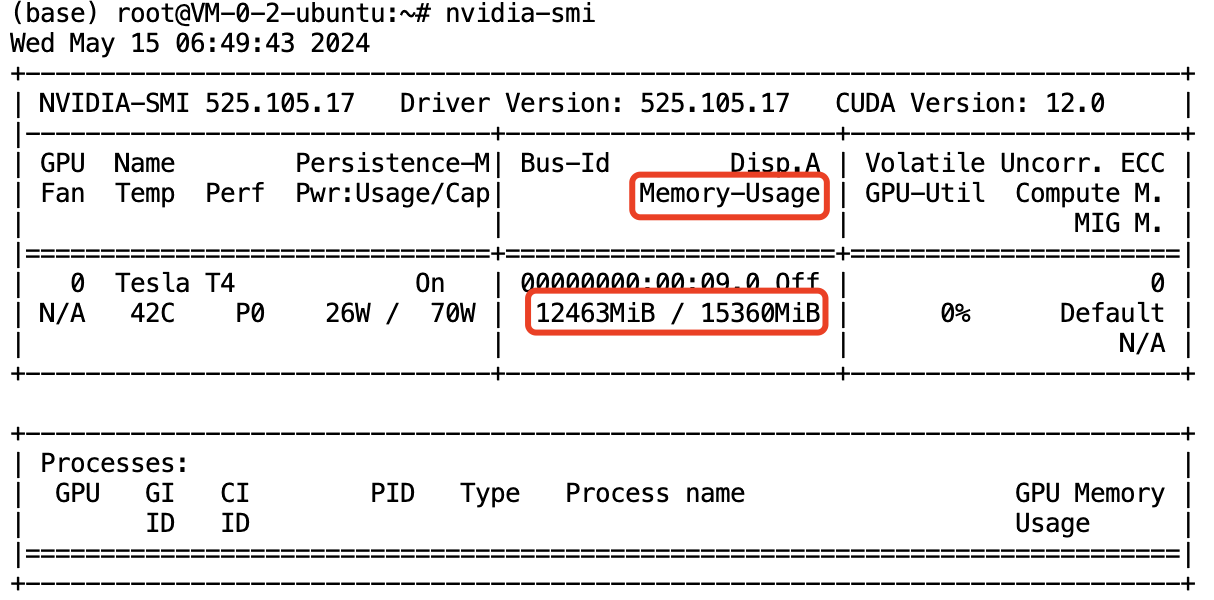
如果没有终止 Gradio WebUI 对应的进程,Memory-Usage 一项对应的显存占用为下图所示,作为对比。
重启 Gradio WebUI 服务
中断 Gradio WebUI 服务后,您将不能在 HAI 实例的算力管理页面使用 Gradio WebUI。遵循如下流程可以重启该服务。请确保重启服务前,该 HAI 实例拥有充足的空余显存容量。
步骤1:服务重启
1. 在终端输入如下命令:
export MODEL_PATH='/root/chatglm3-6b-model' && export TOKENIZER_PATH='/root/chatglm3-6b-model' && cd /root/ChatGLM3/basic_demo/ && (python3 -u hai_web_demo.py --listen --port=6889 >> /var/log/chatglm3_gradio_service.log 2>&1 &) && tail -f /var/log/chatglm3_gradio_service.log
2. 以上命令实现了模型部署、指定端口监听、将控制台输出重定向到指定 log 文档等步骤,最终实现了 Gradio WebUI 服务重启。执行后,如果终端输出类似如下的字样,说明服务重启成功。

步骤2:验证重启
通过终端命令验证
说明:
上一步启动服务的操作可能占据终端的输入输出流。可以同时按下
control 键和 C 键,取得终端的控制权。在终端输入如下命令,查看显存占用情况。
nvidia-smi
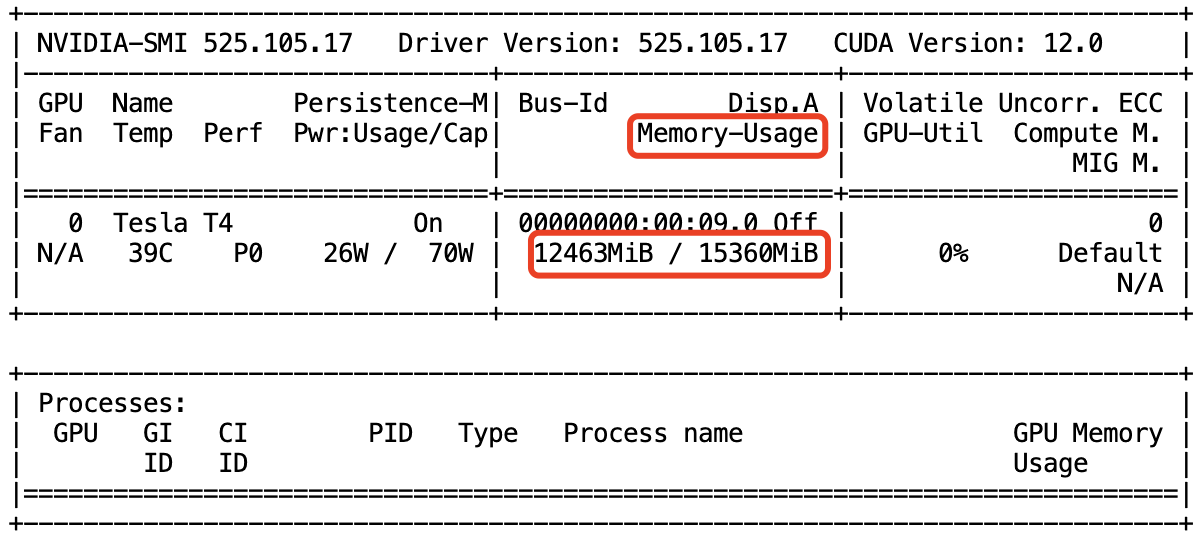
得到如下终端输出,显示显存占用量有 12G 以上,说明 Gradio WebUI 服务已经重启。
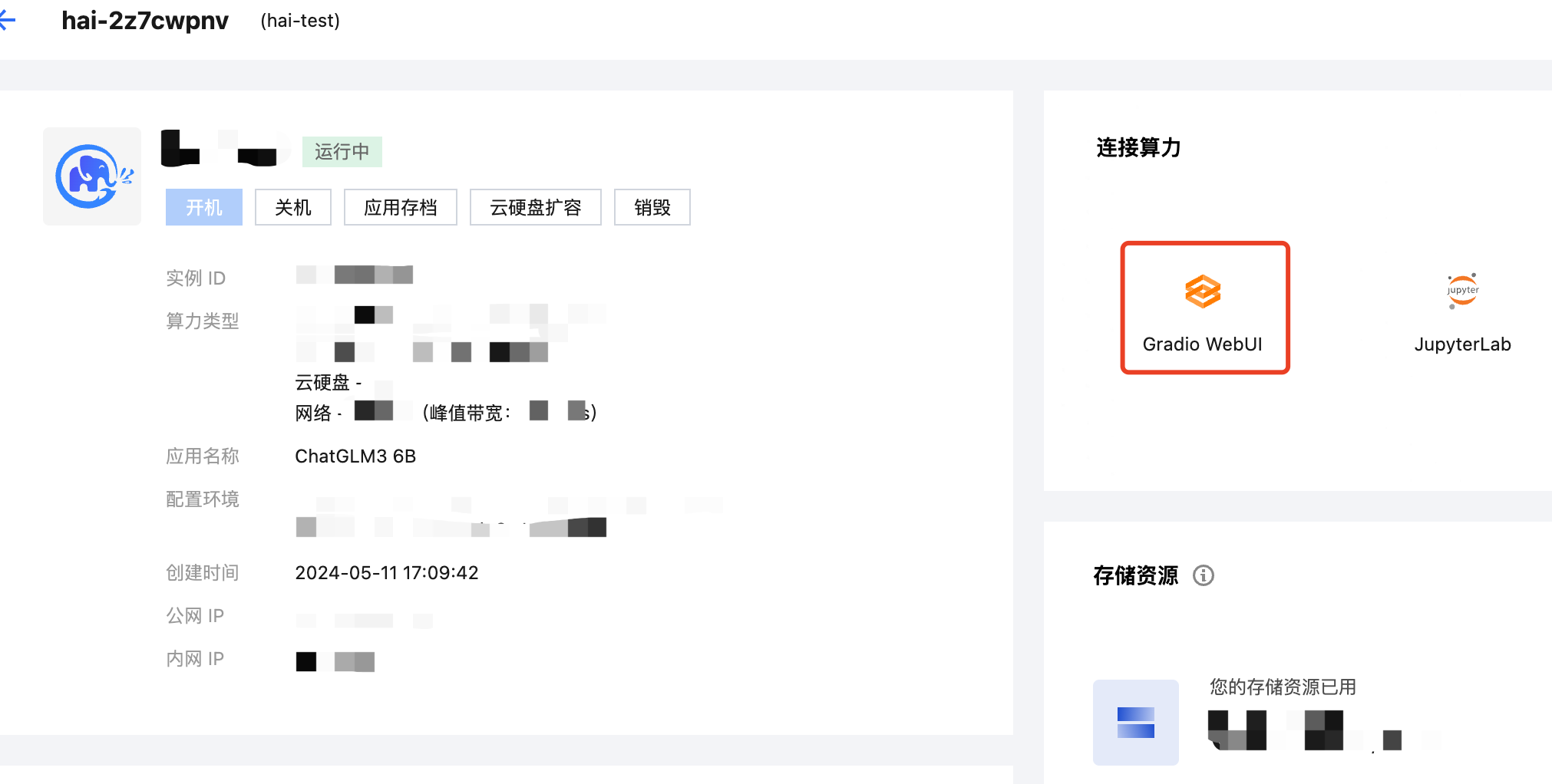
通过访问腾讯云控制台该实例的 Gradio WebUI 功能验证
进入腾讯云控制台,找到该 HAI 实例的管理页面,单击红框所示的 Gradio WebUI。
JupyterLab 页面正常弹出,可以正常对话,证明 Gradio WebUI 服务重启成功。
