录音单词评测
请求参数
voice_id 是音频的唯一标识,为了避免重复,推荐使用 uuid 作为唯一标识。
voice_id = "820993ae-fcfb-11ec-91fc-acde48001122"
eval_mode = 0
# 参数示例为websocket连接URL展开, 如:soe.cloud.tencent.com/soe/api/1306***?eval_mode=0&voice_format=1&..rec_mode = 1 # 开启录音评测voice_format = 3ref_text = "hello"score_coeff = 1.0server_engine_type = 16k_en
返回结果
所有评测模式都需要关注的字段。
SuggestedScore:作为总分使用PronAccuracy:准确度PronFluency:流利度PronCompletion:完整度Phone:音素DetectedStress:用户是否重音Stress:是否应该重音MatchTag:当前词匹配情况。评分为0情况下观察是否漏读,错读。
流式评测
使用英文句子演示流式评测。由于一次性评测不了过长的音频数据,所以需要使用流式评测,将音频数据分片传输。
句子模式可以支持30单词/单字以下的文本。
请求参数
句子模式支持实时,可以通过设置 sentence_info_enabled=1,获取实时中间结果。
sentence_info_enabled = 1
# 参数示例为websocket连接URL展开, 如:soe.cloud.tencent.com/soe/api/1306***?eval_mode=0&voice_format=1&..voice_id = "820993ae-fcfb-11ec-91fc-acde48001122"eval_mode = 1# 默认流式评测rec_mode = 0voice_format = 3ref_text = "hello world"score_coeff = 1.0server_engine_type = 16k_en
返回结果
实时评测需要关注参数。
final:中间结果为0,最终结果为1
指定单词发音
使用英文句子模式演示指定单词发音。
当需要使用音标评测或文本中出现不常见人名,地名,返回结果 MatchTag:4(不在字典)的时候,需要指定单词发音,否则会按照我们词库生成发音或报错。
请求参数
使用指定发音需要设置 text_mode = 1。使用 Wordlist 的结构来表示音素结构。音素结构 Word 需要填写指定的单词,Pron 需要填写智聆音素(可以参考音素映射表)。没有 Pron 则不指定发音,Pron 为空或非智聆音素会报错。
ref_text = "{\\"wordlist\\": [{\\"word\\": \\"english\\"},{\\"word\\": \\"tencent\\",\\"pron\\": [[\\"t\\",\\"ah\\",\\"n\\",\\"s\\",\\"ah\\",\\"n\\",\\"t\\"]]},{\\"word\\": \\"smart oral evaluation\\"}]}"text_mode = 1
音标评测
不指定音标的情况下一般发字母音或报错,所以需要对音标进行评测。
请求参数
文本参考
ref_text = "{\\"wordlist\\": [{\\"word\\": \\"e\\",\\"pron\\": [[\\"eh\\"]]}]}"text_mode = 1
Word 无法直接传入部分音标,所以需要做替换处理。例如 æ,可以使用 ae。
文本参考
ref_text = "{"wordlist": [{"word": "ae","pron": [["ae"]]}]}"text_mode = 1
多音词评测
当一个单词是多音词且发音都算正确时,可以使用多音词评测。
请求参数
文本参考
ref_text = "{\\"wordlist\\": [{\\"word\\": \\"bikeOrabout\\",\\"pron\\": [[\\"b\\",\\"ay\\",\\"k\\"],[\\"ah\\",\\"b\\",\\"ao\\",\\"t\\"]]}]}"text_mode = 1
指定汉字发音
使用中文段落模式演示指定汉字发音。
请求参数
指定汉字发音和指定单词发音类似,都是属于指定发音。Word 填入需要指定的汉字,Pron 填入拼音。
ref_text = "{\\"wordlist\\": [{\\"word\\": \\"靠山吃山,靠水吃水。仪\\"},{\\"word\\": \\"陇\\",\\"pron\\": [[\\"long2\\"]]},{\\"word\\": \\"是山区,有山林竹木,有山货药材,一定要根据山区特点,多搞副业,广开财路。除了粮食,还要抓好棉花、油料生产。多养猪,多喂鸡鸭牛羊,把改善老百姓的生活作为大事来抓。还要动员老百姓在田边地角、河坡路旁多种树,比如桑树、果树、茶树、白蜡树等。要搞好发展规划,定目标要切合实际,不要搞一刀切、瞎指挥。办事要老老实实,统计的数字要真实,遇事多和群众商量。\\"}]}"text_mode = 1
音素到字母映射
使用英文单词纠错模式做演示。
请求参数
音素纠错模式可以返回用户发音内容和文本标准内容,标明客户读错的具体内容。ref_text 与单词模式一致。
ref_text = "hello"eval_mode = 4
音素到字母的映射 ref_text 需要使用{::cmd{F_P2L=true}}+单词 开启音素到字母映射。
ref_text = "{::cmd{F_P2L=true}}hello"eval_mode = 4
返回结果
音素纠错模式需要关注字段。
Phone:音频对应音素ReferencePhone:文本对应标准音素
映射需要关注参数。
Phone:当前音素ReferenceLetter:当前音素对应字母
中文句子多分支模式
需要使用单选题的场景。
请求参数
ref_text 使用 | 来划分不同的句子,| 表示或。
ref_text = "苹果|香蕉|菠萝"eval_mode = 6
单词实时模式
使用单词实时模式,中间就能拿到单词的评测结果。
请求参数
ref_text 使用 | 来划分不同的单词,| 表示或。
ref_text = "apple | bagworm | first"eval_mode = 7
单词实时模式如果需要普通文本和指定发音混合评测,需要使用 单词+{::pron{智聆音素}} 来进行指定发音。
ref_text = "apple | bagworm | first | happy{::pron{hh,ae,p,iy}}"eval_mode = 7text_mode = 0
拼音模式
请求参数
拼音模式需要使用中文模式,ref_text 使用1,2,3,4,表示声调。
ref_text = "sh an1"eval_mode = 8server_engine_type = 16k_zh
声调检测
请求参数
ref_text需要使用 {::cmd{F_TDET=true}} + 拼音 开启声调检测。
ref_text = "{::cmd{F_TDET=true}}sh an1"eval_mode = 8server_engine_type = 16k_zh
返回结果
声调评测需要关注参数。
word:原始评测文本ReferenceWord:标准发音phone:真实发音音素ReferencePhone:标准发音音素,可依此判断声调是否正确。
中英文混合评测
中文评测下可以支持一些简单的英文,也可以通过音素结构来指定发音。
ref_text = "我有一座house"server_engine_type = 16k_zh
苛刻度
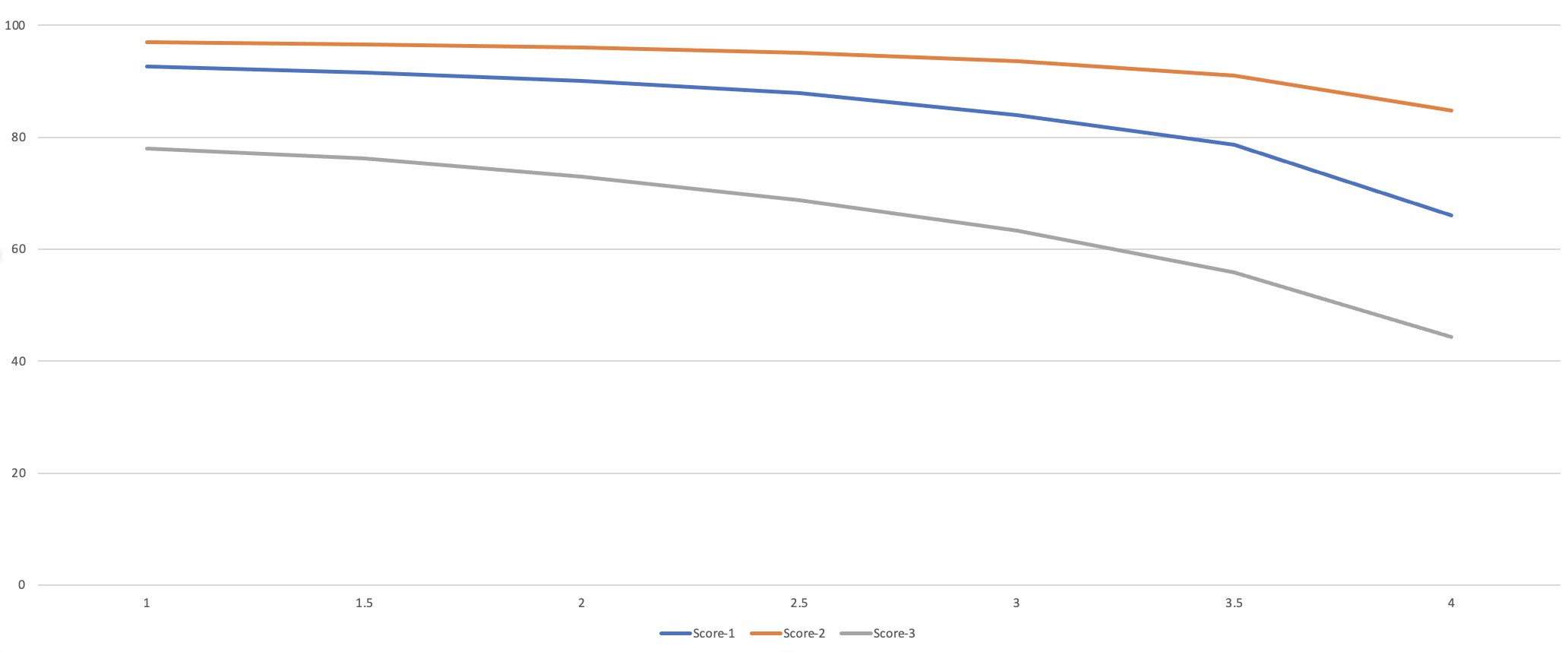
设置不同的苛刻度,对应不同年龄段。
影响范围
取三段不同的数据,苛刻度在1.0 - 4.0之间的变化曲线如下所示:
按需设值
具体需要设置值,可以根据反馈情况,收集音频数据进行打分对比,调整为更符合的苛刻度。
score_coeff = 1.0



