背景
在日志类业务、埋点收集等高并发小批量写入场景中,系统往往面临写入请求频繁、单次数据量较小的问题。传统“请求即落盘”的写入路径会为每个独立的 bulk 请求生成一个数据 Part 并立即写入磁盘,进而导致:
Part 文件数量激增,系统在短时间内生成大量细小的碎片文件;
后台合并(Merge)压力上升,频繁的小文件合并严重消耗 I/O 和 CPU;
写入性能抖动,前台写入受后台 Merge 任务拖累;
存储资源浪费,过多小文件占用 inode,压缩比下降;
系统稳定性下降,Merge 队列堆积时易产生请求排队和延迟波动。
为解决以上结构性瓶颈,我们引入了写入攒批能力,在引擎层新增写入缓冲逻辑,实现在内存中对数据进行按需积累、统一提交的策略。
写入攒批能力主要面向以下场景:
高并发、小批量写入频繁的在线日志接入
多分区散写场景,如设备 ID、用户 ID 为分区键
对写入性能、Merge 成本、稳定性有更高要求的业务系统
该能力通过在内核中延迟生成 Part,控制写入节奏,主动将多个小写入合并为一个紧凑的落盘操作,有效提升系统在高并发接入下的整体写入质量和资源效率。
方案
写入缓冲(攒批)机制详解
写入攒批的核心思路是在内存中暂存批量数据,满足特定条件后再统一生成 Part 落盘,从而以更少、更大、更紧凑的 Part 替代大量零散小 Part。该机制包括以下几个关键阶段:
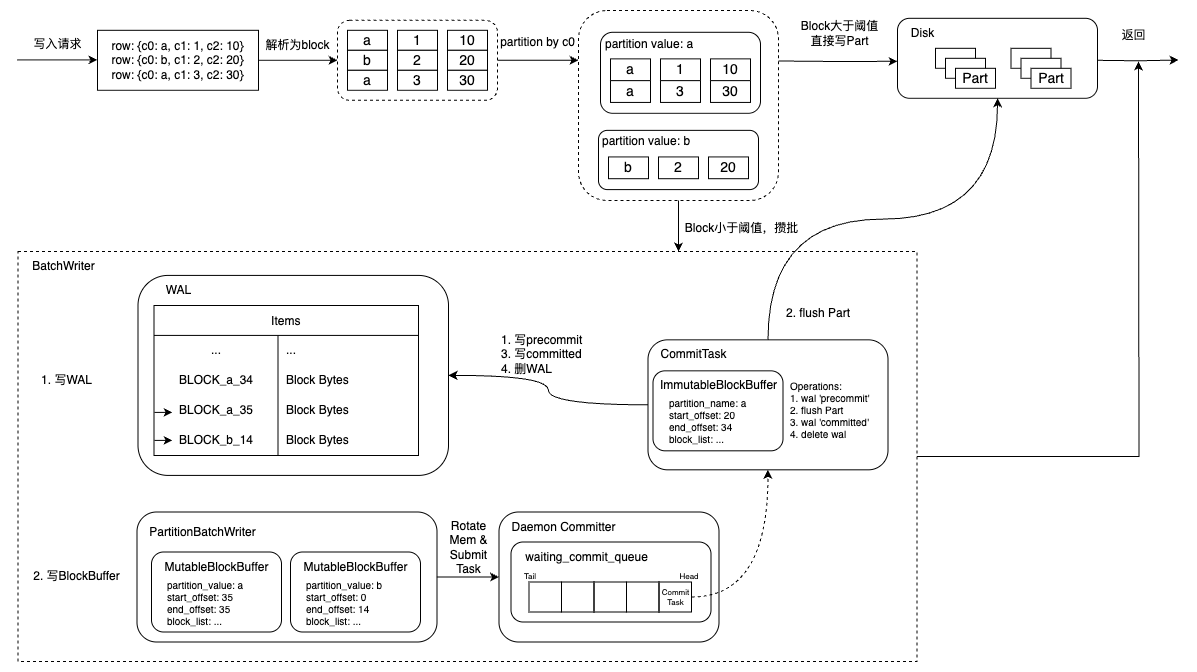
1. 请求解析为 Block(延迟生成 Part)
当接收到一个 bulk 请求后,系统会对其中的文档进行解析,构造成内部的 Block 数据结构。每个 Block 相当于一个逻辑上的写入批次,但此时不会立即生成 Part 文件,即不会触发磁盘写入。此步骤的意义在于打破“请求即落盘”的链路,将写入节奏从请求驱动转为数据积累驱动,为后续缓冲与合并创造条件。
2. 写入 WAL(保证数据可靠性)
解析后的 Block 会首先写入到 WAL(Write-Ahead Log),这是一个顺序写入的日志文件,确保数据在内存攒批期间即使发生故障也不会丢失。WAL 写入具有以下特性:
支持快速追加写,性能高
后续落盘成功后即可被安全清理
在系统异常恢复时可重放
该步骤确保攒批过程在保证性能的同时不牺牲可靠性。
3. 写入内存缓冲区(攒批)
Block 会写入引擎中的 MutableBuffer(可变缓冲区),这是内存中的临时数据结构,用于对多个请求的数据进行聚合缓冲。多个 bulk 请求的数据可以持续累积到这个缓冲区中,直到触发条件满足。这一步是核心的“攒批”行为,通过有序缓存数据,为后续生成更大、更连续的 Part 打下基础。
4. 提交触发机制(可配置)
为了控制攒批时长与写入时机,系统提供了灵活的触发策略,满足任一条件即可触发 Commit:
数量阈值触发:缓冲区内数据达到预设的行数或字节数,
时间阈值触发:距离本轮攒批的第一次写入时间已超过一定时长,可保证低频写入不会长时间滞留
该机制在写入吞吐与写入延迟之间实现动态平衡:高频写入以数据量触发,低频写入以时间触发,确保既能合并批次,又能保障响应性。
5. 批量生成 Part(统一落盘)
一旦触发条件满足,系统将当前缓冲区中的所有数据一次性转为一个或多个 紧凑型 Part 文件 并写入磁盘。这些 Part 比原始单个请求生成的小 Part 更大、更稠密、更适于后续合并和扫描。生成 Part 时的优化包括:
对同一分区的多条数据批量处理,避免分散写入多个文件
更好的数据局部性和列压缩比
降低文件数量、目录层级与 inode 占用
6. 清理 WAL 与内存缓存(释放资源)
在 Part 落盘完成后,系统会:
清理对应的 WAL 段,释放磁盘空间
回收已写入的 MutableBuffer 区域
为下一批次写入腾出空间
整个攒批流程至此完成一个闭环。整体设计图如下:
机制总结与优势对照
对应问题 | 传统写入 | 攒批写入 |
小文件碎片 | 每请求一个小 Part | 多请求合并生成大 Part |
Merge 压力 | Merge 次数频繁 | Merge 次数减少,合并效率更高 |
IO 效率 | 频繁小写,压缩差 | 批量写入,压缩更优 |
系统稳定性 | Merge 队列堆积风险高 | 写入平稳,资源利用更均衡 |
写入延迟 | 每次落盘受 Merge 干扰 | Merge 异步,前台更流畅 |
通过在引擎层引入攒批机制,不仅优化了写入链路的结构与节奏,更显著提升了系统对高并发、高频次、小体量数据写入的处理能力,是日志型、埋点型等写密集型场景的重要内核能力升级。
配置参数
索引级配置
参数 | 说明 | 默认值 |
index.tsearch.engine.batch_commit.enable | 是否开启攒批写入 | false |
index.tsearch.engine.batch_commit.refresh_buffer_size | Cache 在内存中的 Blocks commit 为 Part 的阈值。配置范围[4MB, 64MB] | 8MB |
index.tsearch.engine.batch_commit.refresh_interval | 一批 Blocks 如果在 refresh_interval 时间范围内未达到 refresh_buffer_size 指定的阈值,则也 commit 为 Part | 30s |
index.tsearch.engine.batch_commit.refresh_rows_count | Cache 在内存中的 Blocks commit 为 Part 的阈值。为0时,此参数不生效 | 0 |
index.tsearch.engine.batch_commit.allow_back_off_native_write | 如果达到了内存限制(全局2GB),是否允许回退到直接写 Part 到逻辑 | true |
配置示例
PUT /http_logs{"settings": {"number_of_shards": 1,"number_of_replicas": 1,"index.tsearch.engine.batch_commit.enable": true,"index.tsearch.engine.batch_commit.refresh_buffer_size": "16MB","index.tsearch.engine.batch_commit.refresh_interval": "30s","index.tsearch.engine.batch_commit.refresh_rows_count": 0,"index.tsearch.engine.batch_commit.allow_back_off_native_write": true},"mappings": {"properties": {"foo": {"type": "text"},"myint": {"type": "long"}}}}
集群级配置
参数 | 说明 | 默认值 |
cluster.tsearch.engine.batch_commit.enable | 集群内的索引是否默认开启 BatchCommit,即创建索引时,如果用户没有配置`index.tsearch.engine.batch_commit.enable`,则会使用`cluster.tsearch.engine.batch_commit.enable` | false |
配置示例
PUT /_cluster/settings{"persistent": {"cluster.tsearch.engine.batch_commit.enable": true}}
使用限制
目前用于 Batch Commit 的全局内存限制为2GB。如果超过这个上限,则退化为直接写 Part 的逻辑或者返回错误,通过 allow_back_off_native_write 配置。



