操作场景
在日常开发与运维中,通过查看 Memory 详情,您可以排查记忆效果或获取应用集成所需的连接信息。Memory 详情页提供了当前实例的核心配置与运行状态,主要包括:
基础信息:确认 Memory 实例的当前运行状态,确保服务在线可用。
使用情况:监控当前 Memory 的记忆条数、Credit 消耗量等核心指标。
访问地址:获取与该 Memory 进行交互的 API 端点、凭据与 SDK 接入指南,用于应用集成鉴权与调用。
监控数据:实时观测记忆请求量(Count)、Credit 消耗速率(Count/s)以及记忆条数(Count)的历史曲线,量化评估业务负载与资源走势。
前提条件
当前账号已登录腾讯云控制台,且具备查看 Memory 实例的权限。
至少已经创建一个 Memory 实例。
操作步骤
步骤1:进入实例详情
1. 使用腾讯云账号登录 Agent Memory 控制台页面。
2. 页面以卡片形式展示当前账号在该地域下的全部 Memory 实例。每张卡片上展示实例的关键标识信息:实例名称、实例 ID、运行状态、创建时间等。

3. 单击目标实例卡片,即可进入该实例的详情页,作为实例运维与 API 调用的关键参考信息。
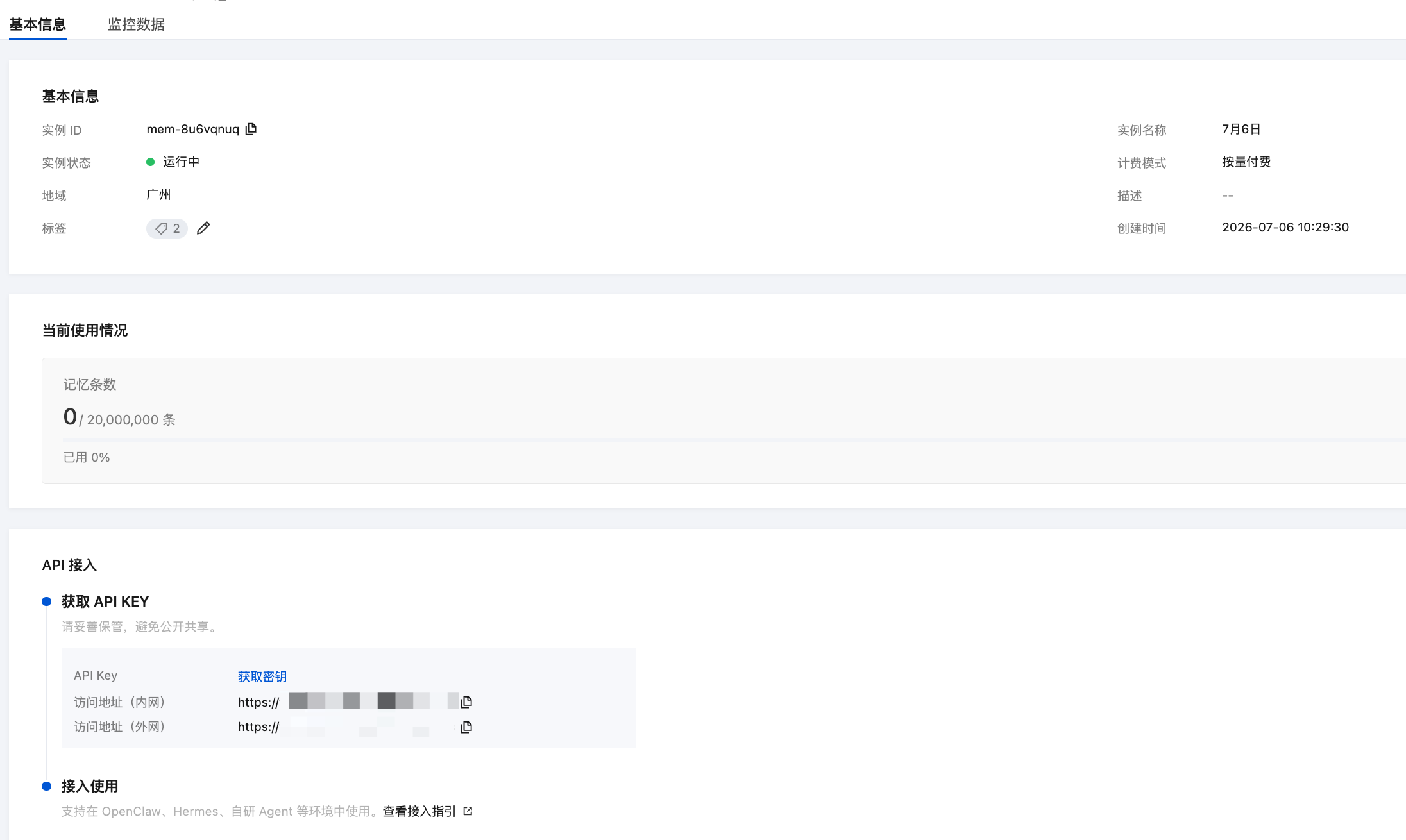
基本信息:展示实例的 ID、名称、标签及创建时间等基本信息。
字段 | 示例值 | 说明 |
实例 ID | mem-rpyrra07 | 系统自动生成的实例唯一标识,是 SDK 与 API 调用时的关键参数。支持一键复制。 |
实例名称 | Initial_Test-1 | 创建实例时填写的名称,用于在控制台列表中区分不同实例。 |
实例状态 | 运行中 | 实例当前的运行状态。 |
计费模式 | 按量付费 | |
地域 | 成都 | 实例所部署的地域。 |
描述 | -- | 创建实例时填写的实例描述说明。 |
标签 | 0 | 实例当前关联的标签数量。 |
创建时间 | 2026-05-21 11:48:37 | 实例创建的时间。 |
当前使用情况:实时展示实例的核心配额用量,单击 查看完整监控 可跳转至完整的监控页面,查看更丰富的指标与历史曲线。
指标 | 指标含义 | 配额上限 |
记忆条数 | 反映当前实例已沉淀的记忆总数,达到配额上限后将无法继续写入新记忆。 | 20,000,000 条 |
API 接入信息:承载 API 调用所需的鉴权凭据与访问地址,是自研 Agent 通过 API 接入 Memory 的入口。
说明:
请妥善保管您的 API Key,避免公开共享。一旦发生泄露,当前实例将无法更换密钥,请务必注意安全。
字段 | 操作说明 | |
获取 API KEY | API Key | 单击获取密钥,系统自动生成 API 调用的鉴权凭据。当前版本暂不支持在控制台自主重置密钥(该功能将在后续迭代中开放)。 |
| 访问地址(内网) | 实例在云系统内部网络下的连接地址。内网传输延迟更低、安全性更高,推荐在云服务器上部署业务时使用。 |
| 访问地址(外网) | 实例开通公网访问后的连接地址。支持通过互联网进行远程调试,使用时需注意网络安全防护。 |
接入使用 | | 提供 SDK 接入示例代码与完整调用指南入口。复制示例代码,粘贴至业务端即可完成 SDK 接入。如需查看完整接入流程与各语言 SDK 的详细用法,单击 完整调用指南 跳转至接入文档。 |
步骤2:查看监控数据
切换监控数据页面,可实时观测记忆请求量(Count)、Credit 消耗速率(Count/s)以及记忆条数(Count)的监控指标的变化趋势。在图表上方,您可以利用控制组件调整数据的呈现方式:
时间范围选择器:支持自定义查询特定时间段(如过去一周、指定日期内)的历史监控数据。
时间粒度:支持调整图表的时间轴聚合粒度(如 1小时、5分钟等)。粒度越小,曲线越精细,便于捕捉瞬时突发流量。
自动刷新:支持设置图表数据的自动刷新频率(如 30s),实现控制台数据的动态盯盘。

监控图表 | 指标含义 | 场景应用 |
记忆请求量 (Count) | 统计在选定时间粒度内,业务端向该 Memory 实例发起请求的总次数。 | 评估调用活跃度:反映业务系统的动态并发情况。请求量暴涨需排查业务侧是否存在循环调用或异常重试。 |
Credit 消耗速率 (Count/s) | 反映每秒钟平均消耗的 Credit 数量(即算力与数据吞吐的消耗速度)。 | 监控负载强度与预测计费:当大模型进行深度记忆加工或长文本读写时,该速率会明显上升。通过此指标可以量化业务负载,并预测当月 Credit 配额是否充足。 |
记忆条数 (Count) | 展示当前实例中已沉淀的记忆总条数(静态存储量)的历史走势。 | 容量规划与预警:反映存储空间的占用趋势。该曲线通常呈平稳上升或阶梯式增长;当曲线趋于水平直线且接近配额上限时,说明存储即将写满,需注意新记忆可能无法继续写入。 |



