TXRocks 概述
RocksDB 是一个非常流行的高性能持久化 KV(key-value)存储,TXRocks 是腾讯 TXSQL 团队基于此开发的事务型存储引擎。
为什么要使用 TXRocks 存储引擎
TXRocks 事务型存储引擎得益于 RocksDB LSM Tree 存储结构,既减少了 InnoDB 页面半满和碎片浪费,又可以使用紧凑格式存储,因此 TXRocks 在保持与 InnoDB 接近的性能前提下,存储空间相比 InnoDB 可以节省一半甚至更多,更适合对事务读写性能有要求,且数据存储量大的业务。
RocksDB 的 LSM Tree 架构
RocksDB 使用 LSM Tree 存储结构,数据组织为一组在内存中的 MemTable 和磁盘上若干层的 SST 文件。
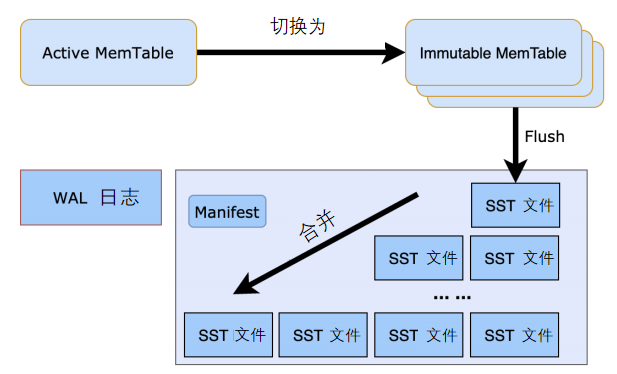
写入请求先将新版本记录写入 Active MemTable,同时写 WAL 日志持久化。写入请求写完 MemTable 和 WAL 就可以返回。
当 Active MemTable 写满到一定程度,将 Active MemTable 切换为冻结的 Immutable MemTable。后台线程将 Immutable MemTable 刷到硬盘,生成对应的 SST 文件。SST 按照刷新的次序分层,通常分为L0层 - L6层。L1层 - L6层,每层内的 SST 中的记录都是有序的,SST 文件之间不会有记录范围的交叠。L0为了支持尽快将 Immutable MemTable 占用的内存空间释放出来,允许 Flush 生成的L0层的 SST 出现记录范围交叠。
当读取一行记录时,按照新旧,依次从 Active MemTable、Immutable MemTable、L0、L1 - L6各个组件查找这一行,从任一组件找到,就表明找到了最新的版本,可以立刻返回。
当执行范围扫描时,对包含每层 MemTable 在内的各层数据,分别生成一个迭代器,这些迭代器归并查找下一条记录。从读的流程可以看到,如果 LSM Tree 层数太多,则读性能,尤其是范围扫描的性能会明显下降。所以,为了维持一个更好的 LSM Tree 形状,后台会不断地执行 compaction 操作,将低层数据合并到高层数据,减少层数。
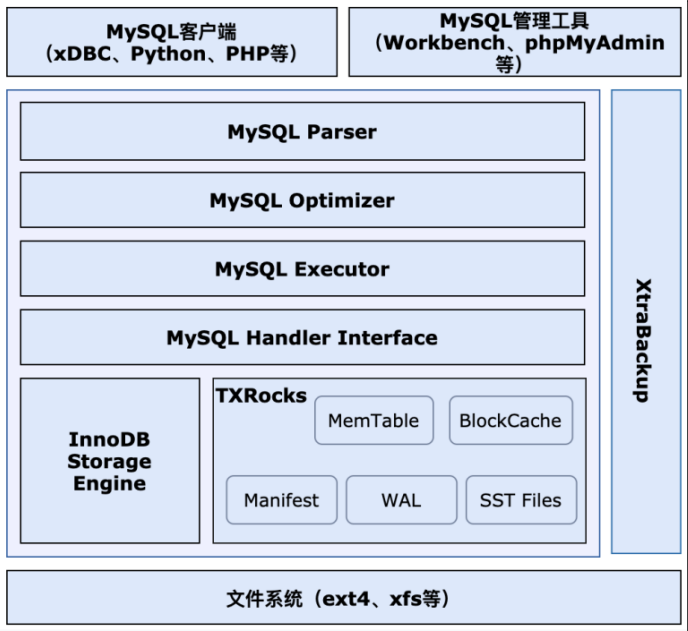
TXRocks 架构
TXRocks 存储引擎的优势
更节省存储空间
相比 InnoDB 使用的 B+Tree 索引结构,LSM Tree 可以节省相当比例的存储空间。
InnoDB 的 B+Tree 分裂通常会导致页面半满,页面内空闲、空间浪费,页面有效利用率比较低。
TXRocks 的 SST 文件一般设置为 MB 量级或者更大,文件要4K对齐产生的浪费比例很低,SST 内部虽然也划分为 Block,但 Block 是不需要对齐的。
另外,TXRocks 的 SST 文件采用前缀压缩,相同的前缀只会记录一份,同时 TXRocks 不同层的 SST 可以采用不同的压缩算法,进一步降低存储空间开销。事务 overhead 方面,InnoDB 的记录上要包含 trx id,roll_ptr 等字段信息,TXRocks 最底层的 SST 文件(包含绝大部分比例的数据)上,数据不需要存放其他事务开销,例如记录上的版本号在经过足够长的时间后就可以抹掉。
写放大更低
InnoDB 采用 In-Place 的修改方式,即使仅修改一行记录也可能要刷盘一整个页面,导致比较高的写入放大和随机写。
TXRocks 采用 Append-Only 方式,相比而言写入放大更低。因此 TXRocks 对于擦写次数有限的 SSD 等产品更友好。
适用场景
TXRocks 非常适合对存储成本比较敏感,写多读少但对事务读写性能有要求的,数据存储量大的业务场景。
如何使用 TXRocks 存储引擎
优化和后续发展
TXRocks 根据业务需求做了部分优化,例如优化 sum 算子下推优化,将 sum 查询性能优化了30多倍。同时 TXRocks 也在积极探索与新硬件结合,利用 AEP 做二级缓存,大幅提升性能,提升性价比。
TXRocks 作为 MySQL 的存储引擎,后续会针对在业务使用中遇到的问题逐渐优化和改进,并计划针对新硬件去做一些新的技术探索,作为 InnoDB 的重要补充,TXRocks 存储引擎会在更多重要业务中上线并平稳运行。



