1. 接入流程
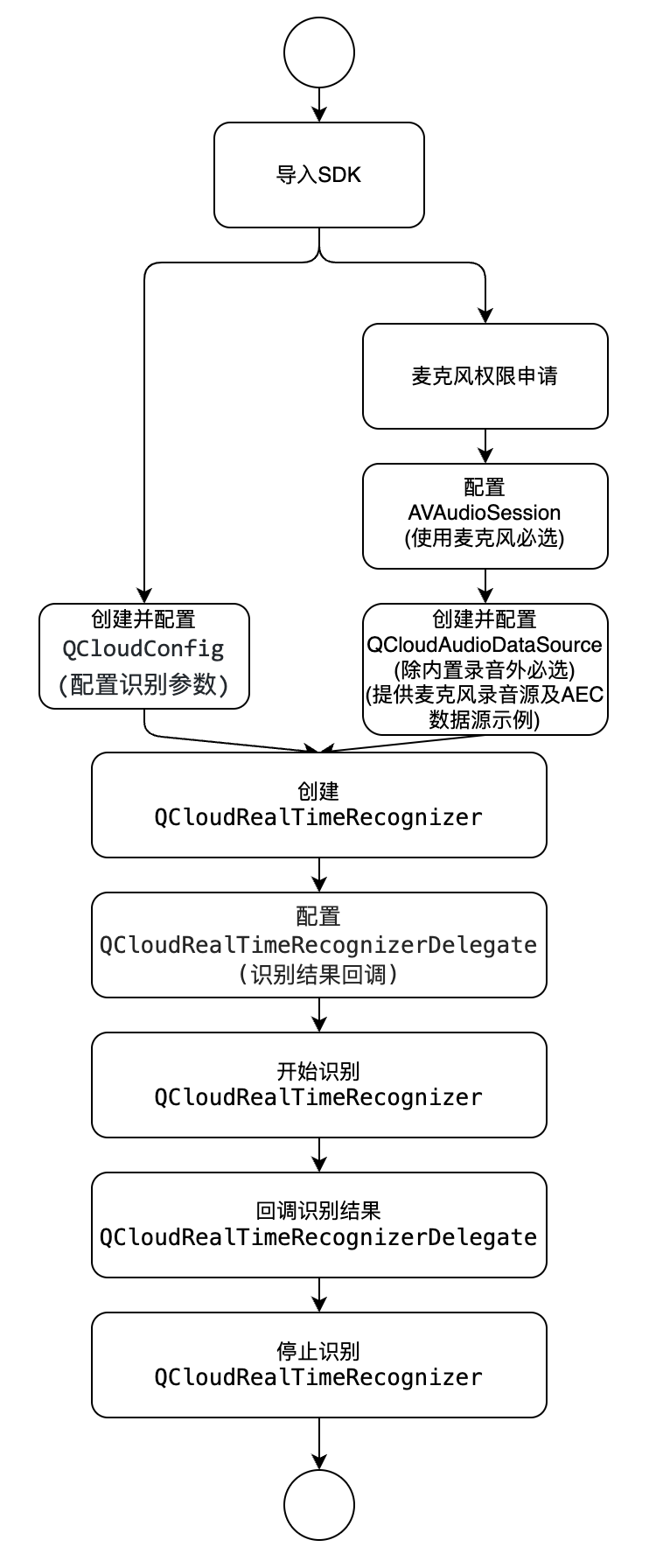
2. 接入准备
2.1 SDK 获取
2.2 接入须知
开发者在调用前请先查看实时语音识别的 接口说明,了解接口的使用要求和使用步骤。
该接口需要手机能够连接网络(3G、4G、5G 或 Wi-Fi 网络等),且系统为 iOS 9.0 及以上版本。
运行 Demo 必须设置 AppID、SecretID、SecretKey,可在 API 密钥管理 中获取。
2.3 SDK 导入
2.3.1 直接导入
1. 下载并解压 iOS SDK 压缩包,压缩包中包含 Demo 和 SDK,其中 QCloudRealTime.xcframework 为实时语音识别 framework 包。
2. XcodeFile > Add Files to "Your Project",在弹出 Panel 选中所下载 SDK 包 QCloudRealTime.xcframework > Add(选中“Copy items if needed”)。
2.3.2 CocoaPods 导入
使用 CocoaPods 导入时,需将以下内容添加到 Podfile 中。
pod 'QCloudRealTime'
2.4 工程配置
在工程
info.plist申请系统麦克风权限,添加如下内容:<key>NSMicrophoneUsageDescription</key><string>需要使用您的麦克风采集音频</string>
在工程中添加依赖库,在 build Phases Link Binary With Libraries 中添加以下库:
QCloudRealTime.framework
libc++.tbd
AVFoundation.framework
AudioToolbox.framework
3. 快速接入
下面分别介绍使用内置录音器采集语音识别和调用者提供语音数据接入流程和示例。
3.1 使用内置录音器采集语音识别示例
1. 引入SDK 的头文件:
#import <QCloudRealTime/QCloudRealTimeRecognizer.h>#import <QCloudRealTime/QCloudConfig.h>#import <QCloudRealTime/QCloudRealTimeResult.h>#import <QCloudRealTime/QCloudAudioDataSource.h>
2. 创建 QCloudConfig 实例:
//1.创建 QCloudConfig 实例QCloudConfig *config = [[QCloudConfig alloc] initWithAppId:kQDAppIdsecretId:kQDSecretIdsecretKey:kQDSecretKeyprojectId:0];//以下为可选配置参数config.requestTimeout = 10; //请求超时时间(秒)//config.sliceTime = 40; //语音分片时长默认40ms(无特殊需求不建议更改)config.enableDetectVolume = YES; //是否检测音量config.endRecognizeWhenDetectSilence = YES; //是否检测到静音停止识别config.shouldSaveAsFile = YES; //仅限使用SDK内置录音器有效,是否保存录音文件到本地 默认关闭config.saveFilePath = [NSTemporaryDirectory() stringByAppendingPathComponent:@"recordaudio.wav"]; //开启shouldSaveAsFile后音频保存的路径,仅限使用SDK内置录音器有效,默认路径为[NSTemporaryDirectory() stringByAppendingPathComponent:@"recordaudio.wav"]//以下为API参数配置,参数描述见API文档:https://cloud.tencent.com/document/product/1093/48982config.engineType = @"16k_zh";//设置引擎,不设置默认16k_zhconfig.filterDirty = 0; //是否过滤脏词,具体的取值见API文档的filter_dirty参数config.filterModal = 0; //过滤语气词具体的取值见API文档的filter_modal参数config.filterPunc = 0; //过滤句末的句号具体的取值见API文档的filter_punc参数config.convertNumMode = 1; //是否进行阿拉伯数字智能转换。具体的取值见API文档的convert_num_mode参数//config.hotwordId = @""; //热词id。具体的取值见API文档的hotword_id参数//config.customizationId = @""; //自学习模型id,详情见API文档//config.vadSilenceTime = -1; //语音断句检测阈值,详情见API文档config.needvad = 1; //默认1 0:关闭 vad,1:开启 vad。 如果语音分片长度超过60秒,用户需开启 vad。config.wordInfo = 0; //是否显示词级别时间戳。,详情见API文档config.noiseThreshold = 0.5; // 噪音参数阈值,默认为0,取值范围:[-1,1],详情见API文档config.noiseThreshold = 0; // 噪音参数阈值,默认为0,取值范围:[-1,1]config.maxSpeakTime = 1000 * 5; // 强制断句功能,取值范围 5000-90000(单位:毫秒),默认值0(不开启)。 在连续说话不间断情况下,该参数将实现强制断句(此时结果变成稳态,slice_type=2)。如:游戏解说场景,解说员持续不间断解说,无法断句的情况下,将此参数设置为10000,则将在每10秒收到 slice_type=2的回调。[config setApiParam:@"noise_threshold" value:@(0.5)]; // 设置自定义请求参数,用于在请求中添加SDK尚未支持的参数
3. 创建 QCloudRealTimeRecognizer 实例:
QCloudRealTimeRecognizer *recognizer = [[QCloudRealTimeRecognizer alloc] initWithConfig:config];
4. 设置 delegate,实现 QCloudRealTimeRecognizerDelegate 方法:
recognizer.delegate = self;
5. 开始识别:
//使用内置录音器前需要先设置AVAudioSession状态为可录音的模式NSError *error = nil;[[AVAudioSession sharedInstance] setCategory:AVAudioSessionCategoryRecord error:&error];if (error) {//错误处理}[[AVAudioSession sharedInstance] setActive:YES error:nil];//启动识别[recognizer start];
6. 结束识别:
[recognizer stop];
3.2 调用者提供语音数据示例
1. 引入 SDK 的头文件:
#import <QCloudRealTime/QCloudRealTimeRecognizer.h>#import <QCloudRealTime/QCloudConfig.h>#import <QCloudRealTime/QCloudRealTimeResult.h>#import <QCloudRealTime/QCloudAudioDataSource.h>
2. 创建 QCloudConfig 实例:
//1.创建 QCloudConfig 实例QCloudConfig *config = [[QCloudConfig alloc] initWithAppId:kQDAppIdsecretId:kQDSecretIdsecretKey:kQDSecretKeyprojectId:0];//以下为可选配置参数config.requestTimeout = 10; //请求超时时间(秒)//config.sliceTime = 40; //语音分片时长默认40ms(无特殊需求不建议更改)config.enableDetectVolume = YES; //是否检测音量config.endRecognizeWhenDetectSilence = YES; //是否检测到静音停止识别config.shouldSaveAsFile = YES; //仅限使用SDK内置录音器有效,是否保存录音文件到本地 默认关闭config.saveFilePath = [NSTemporaryDirectory() stringByAppendingPathComponent:@"recordaudio.wav"]; //开启shouldSaveAsFile后音频保存的路径,仅限使用SDK内置录音器有效,默认路径为[NSTemporaryDirectory() stringByAppendingPathComponent:@"recordaudio.wav"]//以下为API参数配置,参数描述见API文档:https://cloud.tencent.com/document/product/1093/48982config.engineType = @"16k_zh";//设置引擎,不设置默认16k_zhconfig.filterDirty = 0; //是否过滤脏词,具体的取值见API文档的filter_dirty参数config.filterModal = 0; //过滤语气词具体的取值见API文档的filter_modal参数config.filterPunc = 0; //过滤句末的句号具体的取值见API文档的filter_punc参数config.convertNumMode = 1; //是否进行阿拉伯数字智能转换。具体的取值见API文档的convert_num_mode参数//config.hotwordId = @""; //热词id。具体的取值见API文档的hotword_id参数//config.customizationId = @""; //自学习模型id,详情见API文档//config.vadSilenceTime = -1; //语音断句检测阈值,详情见API文档config.needvad = 1; //默认1 0:关闭 vad,1:开启 vad。 如果语音分片长度超过60秒,用户需开启 vad。config.wordInfo = 0; //是否显示词级别时间戳。,详情见API文档config.noiseThreshold = 0.5; // 噪音参数阈值,默认为0,取值范围:[-1,1],详情见API文档config.noiseThreshold = 0; // 噪音参数阈值,默认为0,取值范围:[-1,1][config setApiParam:@"noise_threshold" value:@(0.5)]; // 设置自定义请求参数,用于在请求中添加SDK尚未支持的参数
3. 自定义 QCloudDemoAudioDataSource,QCloudDemoAudioDataSource 实现 QCloudAudioDataSource 协议:
//QCloudDemoAudioDataSource 具体源代码相见SDK demo目录QCloudDemoAudioDataSource *dataSource = [[QCloudDemoAudioDataSource alloc] init];
4. 创建 QCloudRealTimeRecognizer 实例:
QCloudRealTimeRecognizer *recognizer = [[QCloudRealTimeRecognizer alloc] initWithConfig:config dataSource:dataSource];
5. 设置 delegate,实现 QCloudRealTimeRecognizerDelegate 方法:
recognizer.delegate = self;
6. 开始识别:
[recognizer start];
7. 结束识别:
[recognizer stop];
4 主要接口类和方法说明说明
4.1 QCloudRealTimeRecognizer 识别类说明
QCloudRealTimeRecognizer 是实时语音识别类,提供两种初始化方法。
1. initWithConfig:(QCloudConfig *)config
初始化方法,调用者使用内置录音器采集音频。
名称 | 类型 | 描述 |
config | QCloudConfig* | 配置类,用于初始化QCloudRealTimeRecognizer |
2. initWithConfig:(QCloudConfig *)config dataSource:(id<QCloudAudioDataSource>)dataSource
初始化方法,调用者使用自定义数据源提供音频。
名称 | 类型 | 描述 |
config | QCloudConfig* | 配置类,用于初始化QCloudRealTimeRecognizer |
dataSource | id<QCloudAudioDataSource> | 自定义数据源 |
示例
QCloudConfig *config = [[QCloudConfig alloc] initWithAppId:kQDAppId secretId:kQDSecretId secretKey:kQDSecretKey projectId:[kQDProjectId integerValue]];QCloudDemoAudioDataSource *dataSource = [[QCloudDemoAudioDataSource alloc] init];_realTimeRecognizer = [[QCloudRealTimeRecognizer alloc] initWithConfig:config dataSource:dataSource];
4.2 QCloudConfig 配置说明
配置类,用于QCloudRealTimeRecognizer初始化。
1. initWithAppId:(NSString *)appid secretId:(NSString *)secretId secretKey:(NSString *)secretKey projectId:(NSInteger)projectId;
初始化方法-直接鉴权。
名称 | 类型 | 描述 |
appid | NSString * | 腾讯云appId |
secretId | NSString * | 腾讯云secretId |
secretKey | NSString * | 腾讯云 secretKey |
projectId | NSString * | 腾讯云 projectId |
2. initWithAppId:(NSString *)appid secretId:(NSString *)secretId secretKey:(NSString *)secretKey token:(NSString *)token projectId:(NSInteger)projectId;
名称 | 类型 | 描述 |
appid | NSString * | 腾讯云appId |
secretId | NSString * | 腾讯云临时secretId |
secretKey | NSString * | 腾讯云临时secretKey |
token | NSString * | 临时token |
projectId | NSString * | 腾讯云 projectId |
3. setApiParam:(NSString* _Nonnull)key value:(NSObject* _Nullable)value
设置自定义参数,该方法会在控制请求后端时的参数。
名称 | 类型 | 描述 |
key | NSString * | 腾讯云appId |
value | NSObject* _Nullable | nil会删除已添加参数,否则会在请求中添加参数 |
属性
属性名称 | 类型 | 描述 |
enableDetectVolume | BOOL | 是否检测录音音量的变化, 开启后sdk会实时回调音量变化 |
endRecognizeWhenDetectSilence | BOOL | 是否识别静音,默认YES |
endRecognizeWhenDetectSilenceAutoStop | BOOL | 识别到静音是否停止本次识别,默认YES |
silenceDetectDuration | float | 最大静音时间阈值, 超过silenceDetectDuration时间不说话则为静音, 单位:秒 |
sliceTime | NSInteger | 分片时间, 此参数影响语音分片长度, 单位:毫秒,必须为20的整倍数,如果不是,sdk内将自动调整为20的整倍数,例如77将被调整为60,如果您不了解此参数不建议更改 |
requestTimeout | NSInteger | 网络请求超时时间,单位:秒, 取值范围[5-60], 默认20 |
compression | BOOL | 是否压缩音频。默认压缩,压缩音频有助于优化弱网或网络不稳定时的识别速度及稳定性。SDK历史版本均默认压缩且不提供配置开关,如无特殊需求,建议使用默认值 |
engineType | NSString | 引擎识别类型,默认16k_zh |
filterDirty | NSInteger | 是否过滤脏词,具体的取值见API文档的filter_dirty参数 |
filterModal | NSInteger | 过滤语气词具体的取值见API文档的filter_modal参数 |
filterPunc | NSInteger | 过滤句末的句号具体的取值见API文档的filter_punc参数 |
convertNumMode | NSInteger | 是否进行阿拉伯数字智能转换。具体的取值见API文档的convert_num_mode参数 |
hotwordId | NSString | 热词id。具体的取值见API文档的hotword_id参数 |
customizationId | NSString | 自学习模型id,具体的取值见API文档的customization_id参数 |
vadSilenceTime | NSInteger | 语音断句检测阈值,静音时长超过该阈值会被认为断句(多用在智能客服场景,需配合 needvad = 1 使用),具体的取值见API文档vad_silence_time |
needvad | NSInteger | 默认1 0:关闭 vad,1:开启 vad。 如果语音分片长度超过60秒,用户需开启 vad。具体的取值见API文档 |
wordInfo | NSInteger | 是否显示词级别时间戳。0:不显示;1:显示,不包含标点时间戳,2:显示,包含标点时间戳。默认为0。具体的取值见API文档 |
noiseThreshold | float | 噪音参数阈值,默认为0,取值范围:[-1,1],具体的取值见API文档 |
maxSpeakTime | NSInteger | 强制断句功能,取值范围 5000-90000(单位:毫秒),默认值0(不开启)。 在连续说话不间断情况下,该参数将实现强制断句(此时结果变成稳态,slice_type=2)。如:游戏解说场景,解说员持续不间断解说,无法断句的情况下,将此参数设置为10000,则将在每10秒收到 slice_type=2的回调。具体的取值见API文档 |
keepMicrophoneRecording | BOOL | 默认关闭 开启后 需要调用 stopMicrophone 停止麦克风。使用场景:在停止识别后 需要麦克风继续录音一段时间 (录音不会上传服务器 不会识别 也不会保存)只支持内置录音设置 |
shouldSaveAsFile | BOOL | shouldSaveAsFile:仅限使用SDK内置录音器有效,是否保存录音文件到本地 默认关闭 |
saveFilePath | NSString | SaveFilePath:开启shouldSaveAsFile后音频保存的路径,仅限使用SDK内置录音器有效,默认路径为[NSTemporaryDirectory() stringByAppendingPathComponent:@"recordaudio.wav"] |
示例
QCloudConfig *config = [[QCloudConfig alloc] initWithAppId:kQDAppId secretId:kQDSecretId secretKey:kQDSecretKey projectId:[kQDProjectId integerValue]];config.sliceTime = 40; //语音分片时长40msconfig.enableDetectVolume = _volumeDetectSwitch.on; //是否检测音量config.endRecognizeWhenDetectSilence = _silenceDetectEndSwitch.on; //是否检测静音config.endRecognizeWhenDetectSilenceAutoStop = YES;//是否检测到静音停止识别,默认YESconfig.silenceDetectDuration = 3.0;config.requestTimeout = 10;
4.3 QCloudRealTimeRecognizerDelegate 回调说明
用于接收识别过程中的识别结果和相关状态回调。
1. (void)realTimeRecognizerOnSliceRecognize:(QCloudRealTimeRecognizer *)recognizer result:(QCloudRealTimeResult *)result;
每个语音包分片识别结果。
名称 | 类型 | 描述 |
recognizer | QCloudRealTimeRecognizer * | QCloudRealTimeRecognizer实例 |
result | QCloudRealTimeResult * | 语音分片的识别结果(非稳态结果,会持续修正) |
2. (void)realTimeRecognizerOnSegmentSuccessRecognize:(QCloudRealTimeRecognizer *)recognizer result:(QCloudRealTimeResult *)result
语音流的识别结果,一次识别中可以包括多句话,这里持续返回的每句话的识别结果。
名称 | 类型 | 描述 |
recognizer | QCloudRealTimeRecognizer * | QCloudRealTimeRecognizer实例 |
result | QCloudRealTimeResult * | 语音分片的识别结果 (稳态结果) |
3. (void)realTimeRecognizerDidFinish:(QCloudRealTimeRecognizer *)recognizer result:(NSString *)result
一次识别任务成功完成后的成功回调。
名称 | 类型 | 描述 |
recognizer | QCloudRealTimeRecognizer * | QCloudRealTimeRecognizer实例 |
result | QCloudRealTimeResult * | 一次识别出的总文本, 实际是由SDK本地处理,将本次识别的realTimeRecognizerOnSegmentSuccessRecognize 识别结果拼接后一次性返回 |
4. (void)realTimeRecognizerDidError:(QCloudRealTimeRecognizer *)recognizer result:(QCloudRealTimeResult *)result;
一次识别任务失败回调。
名称 | 类型 | 描述 |
recognizer | QCloudRealTimeRecognizer * | QCloudRealTimeRecognizer实例 |
result | QCloudRealTimeResult * | 识别结果信息,错误信息详情看QCloudRealTimeResponse内错误码 |
5. (void)realTimeRecognizerDidStartRecord:(QCloudRealTimeRecognizer *)recognizer error:(NSError * _Nullable )error
开始录音回调。
名称 | 类型 | 描述 |
recognizer | QCloudRealTimeRecognizer * | QCloudRealTimeRecognizer实例 |
error | NSError * | 开启录音失败,错误信息 |
6. (void)realTimeRecognizerDidStopRecord:(QCloudRealTimeRecognizer *)recognizer;
结束录音回调。
名称 | 类型 | 描述 |
recognizer | QCloudRealTimeRecognizer * | QCloudRealTimeRecognizer实例 |
7. (void)realTimeRecognizerDidUpdateVolumeDB:(QCloudRealTimeRecognizer *)recognizer volume:(float)volume;
录音音量(单位为分贝)实时回调,此回调计算音量的分贝值。
名称 | 类型 | 描述 |
recognizer | QCloudRealTimeRecognizer * | QCloudRealTimeRecognizer实例 |
volume | float | 音量分贝,取值范围(0~100),集中分布在40~80 |
8. (void)realTimeRecognizerDidSaveAudioDataAsFile:(QCloudRealTimeRecognizer *)recognizer audioFilePath:(NSString *)audioFilePath;
录音停止后回调一次,再次开始录音会清空上一次保存的文件。
名称 | 类型 | 描述 |
recognizer | QCloudRealTimeRecognizer * | QCloudRealTimeRecognizer实例 |
audioFilePath | NSString * | 音频文件路径 |
9. (void)realTimeRecgnizerLogOutPutWithLog:(NSString *)log;
日志输出回调。
名称 | 类型 | 描述 |
recognizer | QCloudRealTimeRecognizer * | QCloudRealTimeRecognizer实例 |
log | NSString * | 日志信息 |
4.4 QCloudAudioDataSource 协议说明
调用者不使用 SDK 内置录音器进行语音数据采集,自己提供语音数据需要实现此协议所有方法,可见 Demo 工程中的 QDAudioDataSource 实现。
1. (void)start:(void(^)(BOOL didStart, NSError *error))completion;
SDK会调用start方法,实现此协议的类需要初始化数据源。SDK会根据didStart值判断是否开始 ,YES 往下执行,NO不会往下执行。
运行后需将 running 属性设置为 YES。
2. (void)stop;
SDK 会调用 stop 方法,实现此协议的类需要停止提供数据。
运行后需将 running 属性设置为 NO。
3. (nullable NSData *)readData:(NSInteger)expectLength;
SDK 会调用实现此协议的对象的此方法读取语音数据, 如果语音数据不足 expectLength,read 线程进入休眠。
5. 错误码
后端错误码,详情请参见 API 文档。
客户端错误码如下:
错误码 | 名称 | 描述 |
-100 | QCloudRealTimeClientErrCode_NetworkError | 无网络 |
-101 | QCloudRealTimeClientErrCode_Timeout | 手机网络存在问题,请求超时 |
-102 | QCloudRealTimeClientErrCode_MicError | 录音过程音频通道被占用,录音失败,例如电话 |
-103 | QCloudRealTimeClientErrCode_AudioInitError | 音频源初始化失败(麦克风启动失败,权限拒绝等,如果使用自定义音频源start方法返回错误也会触发) |
6. 常见问题指引
6.1 回音消除指引
本小节主要介绍如何通过 iOS 原生 API 实现回音消除,下面将介绍实现方案(完整代码参考 Demo 工程中的 QCloudAECDataSource 类的实现方法)。
6.1.1 回声消除方案介绍
1. 设置 AVAudioSession 支持边播放边录音的模式:
AVAudioSession* session = [AVAudioSession sharedInstance];[session setCategory:AVAudioSessionCategoryPlayAndRecord mode:AVAudioSessionModeDefault options:AVAudioSessionCategoryOptionDefaultToSpeaker error:&error];
2. 通过 AVAudioEngine 添加播放节点构建音频处理图:
self.engine = [[AVAudioEngine alloc] init];self.play_node = [[AVAudioPlayerNode alloc] init];[self.engine attachNode:self.play_node];[self.engine connect:self.play_node to:self.engine.outputNode format:nil];
3. 通过调用输入节点的 setVoiceProcessingEnabled 开启回声消除:
[self.engine.inputNode setVoiceProcessingEnabled:YES error:&error];
4. 启动音频处理图:
[self.engine startAndReturnError:&error];







