实践背景
云数据库 Redis(TencentDB for Redis)是基于腾讯云在分布式缓存领域多年技术沉淀,提供的兼容 Redis 协议、高可用、高可靠、高弹性的数据库服务。针对这类敏感的纯内存、高并发和低延时的服务,配置监控告警可有效提高问题排查定位效率。
完善的监控告警可以做到故障快速通知,快速定位,缩短故障时间。
良好的监控数据能够实时反映 Redis 对资源的利用占比,帮助用户做好 Redis 容量规划和性能管理。
Redis 的性能监控,可以帮助用户及时发现性能瓶颈。
对于 Redis 而言,监控告警是十分重要且必要的,而腾讯云可观测平台为用户提供了统一监控云数据库 Redis 的平台,可以通过使用腾讯云可观测平台全面了解云数据库 Redis 的资源使用、性能和运行状况,帮助用户更轻松地理解云数据库 Redis 的指标,更方便、快捷的掌控云数据库 Redis 出现的突发情况,提升运维效率,减少运维成本。
为云数据库 Redis 配置告警
1. 登录 腾讯云可观测平台。
2. 单击告警管理 > 告警配置 > 告警策略 > 新建策略。
3. 进入新建告警策略页,填写如下信息,详情可参考 新建告警:
配置项 | 说明 |
策略名称 | 输入策略名称,最多60个字符 |
备注 | 输入备注,最多100个字符 |
监控类型 | 选择云产品监控 |
策略类型 | 选择云数据库 > Redis > 内存版(5秒粒度)/CKV 版本 |
策略所属项目 | 选择策略所属项目。所属项目用于告警策略的分类和权限管理,与云产品实例的项目没有强绑定关系 |
所属标签 | 选择策略所属标签 |
告警对象 | 选择具体实例作为告警对象 |
触发条件 | 支持手动配置触发告警的条件,如已有触发条件模板满足需求,也可以直接选择模板 |
| 支持添加事件进行事件告警配置 |
配置告警通知 | 支持新建或需选择已有的告警通知模板 |
4. 设置完成后,单击完成。
监控实例分析
为进一步提升 Redis 的监控能力,腾讯云可观测平台配合业务侧对 Redis 的监控进行了全面的升级,监控粒度升级到 5 秒,监控数据延迟缩短到 20 秒以内,新增副本节点监控采集和告警,新增 Proxy 节点监控采集和告警,提供给用户更完善的监控告警和更良好的监控数据,并对云数据库 Redis 的每一部分进行相应指标的监控,并将指标进行分类,以便用户理解和使用,详细指标请参见 CKV 版监控指标 和 内存版监控指标(5秒粒度)。
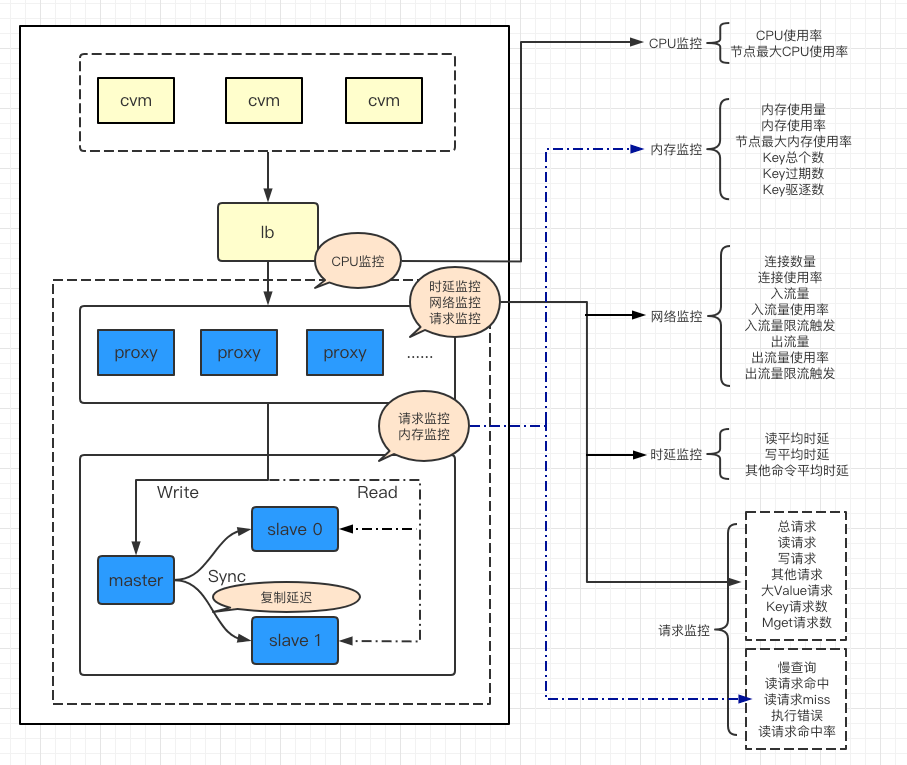
CPU 监控:Redis 是单进程实例,默认只使用单个核心,当某个实例出现 CPU 性能瓶颈,会导致性能故障,因此除整体 CPU 使用率外,还应关注节点最大 CPU 使用率。
内存监控:Redis 是内存型数据库,因此对于内存的监控就尤为重要。一般内存满了之后会导致一系列的问题,例如逐出了不该逐出的 key、写不进数据、 超时阻塞等问题,因此需关注内存使用量、内存使用率、节点最大内存使用率、Key 总个数、Key 过期数、Key 驱逐数。
内存使用量:Redis 真实使用内存,不包含内存碎片。
内存使用率:实际使用内存和申请总内存之比
Key 总个数:Redis 实例包含的键个数,单实例键个数过大,可能导致过期键的回收不及时。
Key 过期数:时间窗内被淘汰的 Key 个数,对应 info 命令输出的 expired_keys。
Key 驱逐数:时间窗内被驱逐的 Key 个数,对应 info 命令输出的 evicted_keys。
内存倾斜率:统计每个分片主节点的内存使用量与所有分片主节点内存占用的平均值的比值,当指标大于100%时,说明该节点存在倾斜。
网络监控:网络吞吐量关系到 Redis 的整体服务质量。需要关注连接数量和连接使用率,如果连接数过高,会影响 Redis 吞吐量。此外,入流量使用率和出流量使用率也是网络监控的核心指标。
时延监控:响应时间是衡量一个服务组件性能和质量的重要指标。使用 Redis 的服务通常对响应时间都十分敏感,例如要求 99% 的响应时间达 10ms 以内。
响应监控:通过此监控来度量 Redis 缓存的质量,如果未命中或错误的次数较高,可能因热点数据大于 Redis 的内存限制,导致请求落到后端存储组件,需要扩容 Redis 缓存集群的内存容量。
读请求命中:读请求 Key 存在的个数,对应 info 命令输出的 keyspace_hits 指标。
读请求 Miss:读请求 Key 不存在的个数,对应 info 命令输出的 keyspace_misses 指标。
读请求命中率:Key 命中 / (Key 命中 + KeyMiss),该指标可以反映 Cache Miss 的情况。
注意:
在 Proxy 层,会更加关注时延、请求、网络类监控;在节点层,会更加关注请求、内存类监控。
预设专家建议核心告警指标
腾讯云可观测平台与云数据库 Redis 业务侧经过讨论,根据多年运维经验,推荐用户对内存版-实例汇总/Redis节点(多维)/Proxy节点(多维)策略配置告警指标,其中,对实例汇总策略提供了常用告警指标和阈值的专家建议。用户配置告警时,页面将默认显示预设的指标及阈值建议,支持修改,方便用户快速配置告警策略。
“云数据库 - Redis - 内存版 (5 秒粒度)- 实例汇总”策略建议核心告警指标
告警指标 | 统计粒度 | 判断条件 | 阈值 | 持续周期 | 告警方式 |
CPU使用率 | 统计粒度5秒 | > | 80 | 5个数据点 | 每5分钟告警一次 |
内存使用率 | 统计粒度5秒 | > | 80 | 5个数据点 | 每5分钟告警一次 |
节点最大CPU使用率 | 统计粒度5秒 | > | 80 | 5个数据点 | 每5分钟告警一次 |
节点最大内存使用率 | 统计粒度5秒 | > | 80 | 5个数据点 | 每5分钟告警一次 |
连接使用率 | 统计粒度5秒 | > | 80 | 5个数据点 | 每5分钟告警一次 |
入流量使用率 | 统计粒度5秒 | > | 80 | 5个数据点 | 每5分钟告警一次 |
出流量使用率 | 统计粒度5秒 | > | 80 | 5个数据点 | 每5分钟告警一次 |
CPU 使用率 > 80%、节点最大 CPU 使用率 > 80%
如果 Redis 的 CPU 整体资源饱和,会导致 Redis 性能下降,请求堆积。而 Redis 是单进程实例,默认只使用单个核心,但当某个实例出现 CPU 性能瓶颈,会导致性能故障,所以 Redis 对 CPU 资源的监控还要监控到单个核心的资源使用率。建议设置 CPU 使用率 > 80%、节点最大 CPU 使用率 > 80%,当接收到告警后,请参考 CPU使用率过高 相关文档进行处理。
内存使用率 > 80%、节点最大内存使用率 > 80%
Redis 是纯内存系统,如果 Redis 使用的内存超出了可用的物理内存大小,那么 Redis 很可能系统会被 OOM killer 杀掉,所以必须要保证系统有足够的内存余量,以免出现 OOM 导致 Redis 进程被杀,同时 Redis 一旦使用 swap,会导致性能骤降。针对这一点,建议设置内存使用率 > 80%、节点最大内存使用率 > 80% 告警,当接收到告警后,建议清除一些没用的冷数据或者升级 Redis 规格,请参考 内存使用率过高 相关文档进行处理。
连接数使用率 > 80%
由于对 Redis 的访问通常由应用程序发起(用户通常不直接访问数据库),因此对于大多数场景,连接客户端的数量将有合理的上限和下限。连接数使用率如果达到 1,Redis 会开始拒绝新连接创建,影响业务程序运行。当接收到告警后,请参考 连接使用率过高 相关文档进行处理。
入流量使用率 > 80%、出流量使用率 > 80%
Redis 一般是单机多实例部署,当服务器网络流量增长很大,需快速定位是网络流量被哪个 Redis 实例所消耗了,另外 Redis 如果入流量过大,可能导致 slave 线程 “客户端输出缓冲区” 堆积,达到限制后被 Master 强制断开连接,出现复制中断故障。所以建议设置入流量使用率 > 80%,出流量使用率 > 80%,当接收到告警后,请参考 出流量过高 相关文档进行处理。