kube-proxy 采集目标状态全部为 DOWN,该如何解决?
TKE 中 kube-proxy 未指定启动参数
--metrics-bind-address,而 metrics 服务默认监听地址为127.0.0.1:10249,因此 Agent 无法根据 pod IP 拉取到 metrics,可通过如下步骤指引进行解决:1. 登录 容器服务控制台,选择对应地域下的容器集群。
2. 在基本信息 > 集群 APIServer 信息 > 通过 kubectl 连接 Kubernetes 集群操作说明根据指引设置 kubectl。
3. 执行命令
kubectl edit ds kube-proxy -n kube-system,在 spec.template.spec.containers.args 中添加启动参数 --metrics-bind-address=0.0.0.0:10249。独立 TKE 集群 Master 节点上组件采集目标状态全部为 DOWN,该如何解决?
独立 TKE 集群 Master 节点的默认安全组入站规则不允许访问部分组件的 metrics 端口,可通过如下步骤指引进行解决:
1. 登录 安全组控制台,选择对应区域。
2. 在安全组搜索框中输入
tke-master-security-for-<tke cluster id>。例如集群 ID。kube-system/master-metrics-exporter 采集超时?
ServiceMonitor 采集目标为空,如何排查?
以下面采集配置为例排查:
apiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata:name: demo-exporternamespace: kube-systemspec:endpoints:- interval: 15sport: metricspath: /metricsnamespaceSelector:matchNames:- nsselector:matchLabels:app: demo
1. 根据 selector 和 namespaceSelector 查找对应 service 是否存在。
这里的 selector 匹配的是 service metadata.labels 中的信息,不是目标 pod 的。对于上面的采集配置,执行下面命令返回选中的 service。
kubectl get services -n ns -l app=demo
2. endpoints 中 port 是否和 service 中 ports.name 对上。
port 对应的是目标 service 中的配置的名字而不是实际端口值。
3. 判断找到 service 对应的 endpoints 或 endpointslices 是否为空。
endpoints 或 endpointslices 存储 service 选中 pod 列表,也是 ServiceMonitor 生成配置的实际采集目标。执行下面命令查看:
kubectl get endpoints <serviceName> -n <serviceNamespace>kubectl get endpointslices <serviceName> -n <serviceNamespace>
如果 endpoints 和 endpointslices 内容都是空,service 配置有问题或者所有 pod 都没有正常运行。如果 endpoints 为空且 endpointslices 不为空,需要把 tmp-agent 和 tmp-operator 两个组件升级到最新版本,新版本优先使用 endpointslices,具体操作见 文档。
ServiceMonitor 采集目标最多只有1000个?
老版本 tmp-operator 生成配置使用 endpoints 作为服务发现,endpoints 最多只能存储1000个 pod 信息。升级 tmp-agent 和 tmp-operator 到最新版本,新版本使用 endpointslices 作为服务发现,没有这个限制。
kube_<resource>_labels/kube_<resource>_annotations 指标缺少资源的 labels/annotations
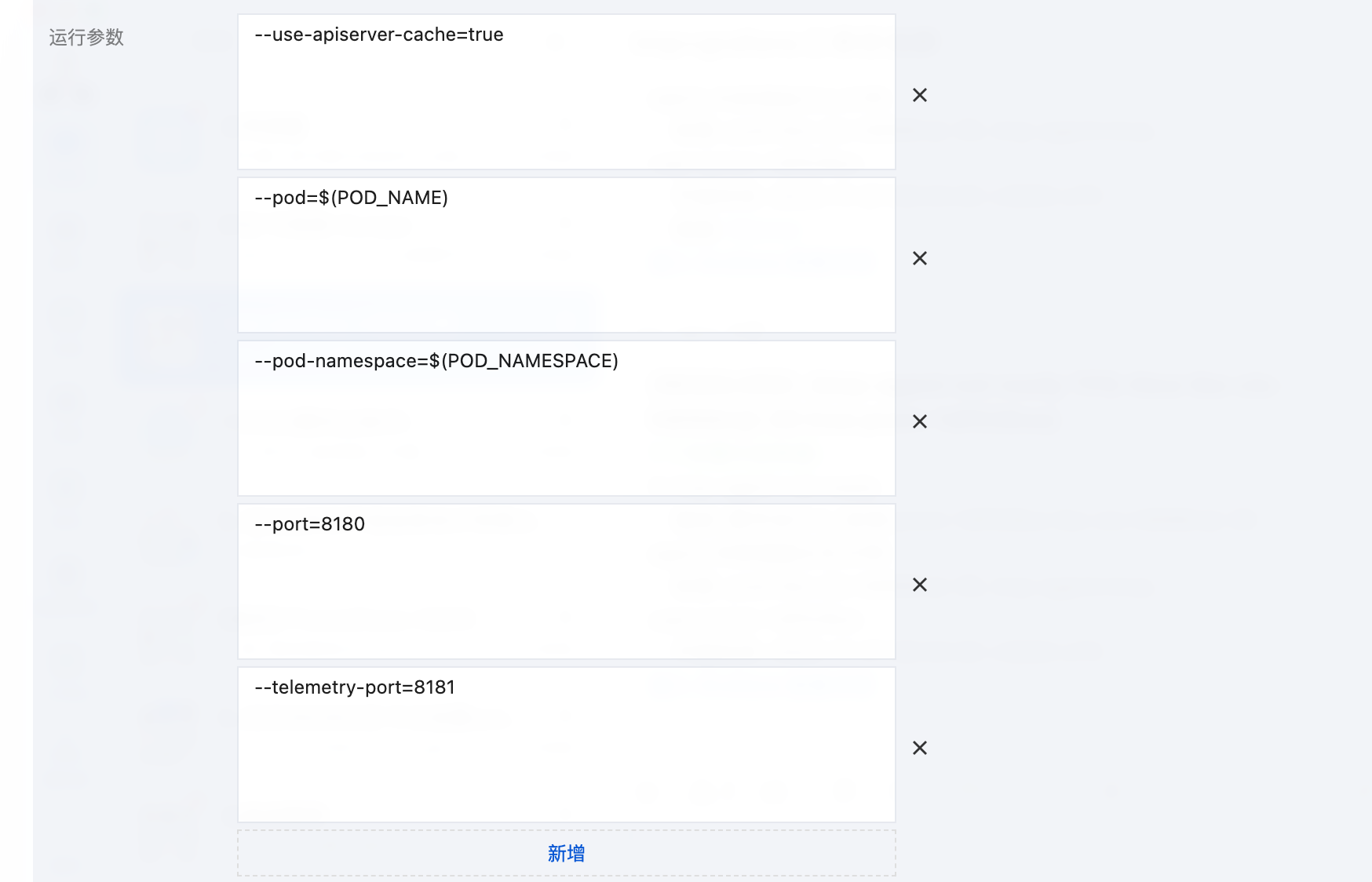
kube-state-metrics 在设计上采取了一种保守的默认策略,在未进行任何自定义配置的情况下,它不会采集 Kubernetes 资源的所有 labels 和 annotations。这种设计决策主要基于性能和资源消耗的考虑。用户可以添加 metric-labels-allowlist 和 metric-annotations-allowlist 选项,开启对资源 labels/annotations 的采集。
这两个白名单参数都支持相似的语法格式,允许用户针对不同资源类型分别指定要采集的 labels/annotations。基本语法结构如下:
--metric-labels-allowlist=<resource_type1>=[<label1>,<label2>],<resource_type2>=[*]--metric-annotations-allowlist=<resource_type1>=[<annotation1>,<annotation2>],<resource_type2>=[*]
既支持精确指定要采集的标签/注解键,也支持使用通配符 * 采集所有标签或注解。以下是几种常见的配置示例:
pods=[app-version,deployment-env]:只为 Pod 资源采集 app-version 和 deployment-env 这两个 labels/annotations。
pods=[*],nodes=[*]:采集所有 Pod 和 Node 的所有 labels/annotations。
pods=[region,zone],deployments=[app-team,priority]:为不同资源类型采集不同 labels/annotations。
*=[*]: 采集所有资源的所有 labels/annotations。
说明:
不建议使用通配符采集所有 labels/annotations,因为这可能导致指标长度和数量不可控增长。如果资源的 labels/annotations 过多,生成的指标很容易超过实例限制(默认最多34个标签)而写入失败。
Prometheus 监控服务绑定 TKE 集群会把 tke-kube-state-metrics 作为 Statefulset 部署在 kube-system 下。
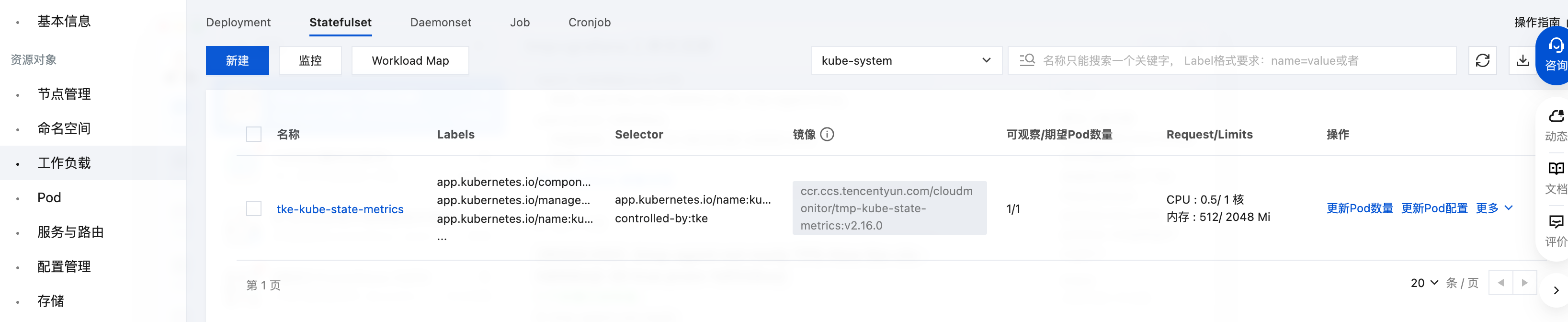
依次单击更新 Pod 配置 > 显示高级配置 > 新增,添加运行参数。