实践背景
通常来说,监控系统的四个黄金指标(Four Golden Signals,参考 Google 运维解密)是错误类指标、延迟类指标、流量指标和饱和度指标,可以在服务级别衡量终端用户体验、服务质量、业务影响等层面的问题。以一个典型的电商服务关键路径(登录 > 产品浏览详情页 > 下单)举例。

针对图中三个服务,需要设定成功率等监控指标。传统的以实例(例如 IP )为监控对象的场景下,通常会对每个服务的实例都配置告警策略,用于满足最细粒度的告警对象质量监测,但也会带来一系列痛点:
需要针对每个实例都配置一条告警策略,告警策略太多,维护成本高。
缺乏整个业务层面的监控(监控对象是3个业务,而不是每个实例)。
业务异常时,多个实例同时触发告警,容易引起告警风暴。
对于其他维度的业务质量监控能力不足,例如业务分区部署,需要看某个区的质量情况等。
针对上述痛点,Prometheus 监控服务可以提供“优雅”的解决方案。通过将监控对象从实例扩展为不同标签(label),利用Prometheus 监控服务的多维能力,可以聚合出服务层面的宏观监控指标。详见下文。
监控场景
服务指标的宏观维度监控&告警场景
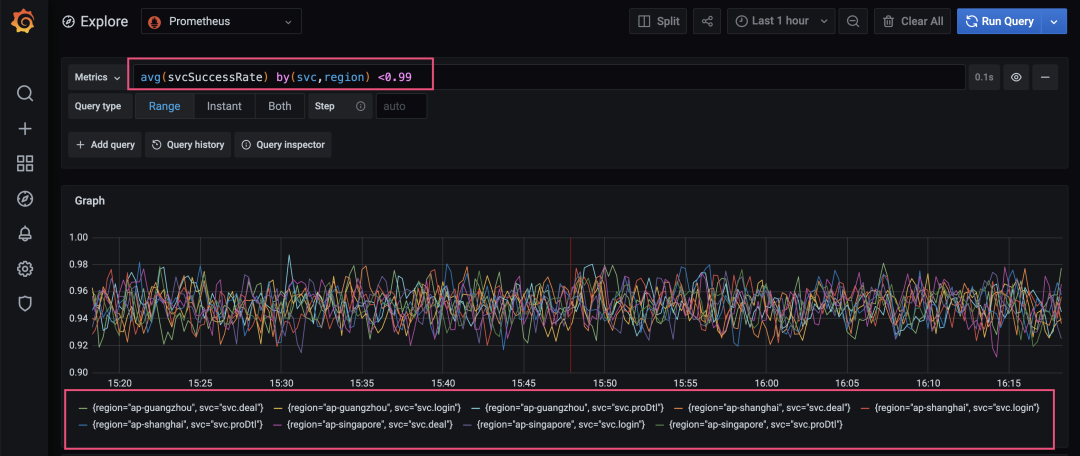
以上述电商服务关键路径举例。服务上报指标为成功率,上报标签为:服务名、IP 和区域。

相比传统只上报实例(IP)的单一标签,这里还扩展了服务名等其他标签。
在设置告警策略时,通过不同标签聚合,来解决上述提到的传统实例监控中碰到的痛点。具体步骤如下:
1. 按服务维度的成功率看整体情况。
2. 按服务&地区维度聚合,查看某个更细维度的质量 情况。
3. 利用 PromQL 可以大幅降低告警策略数量(对比传统实例监控)。
实践步骤
步骤1:指标定义&服务部署
1. 指标定义
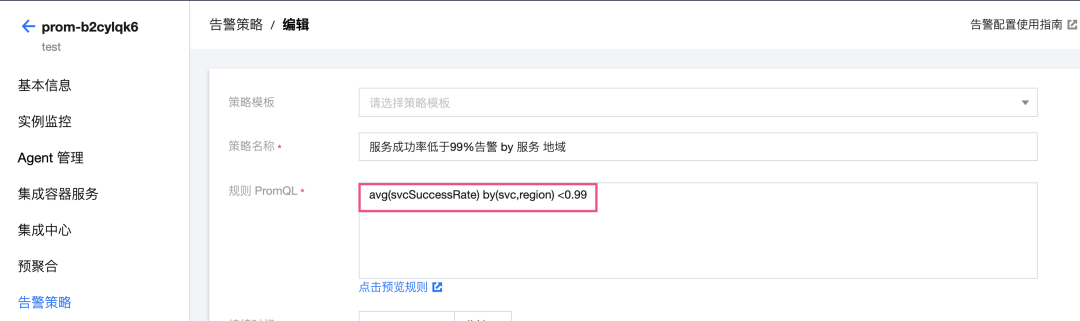
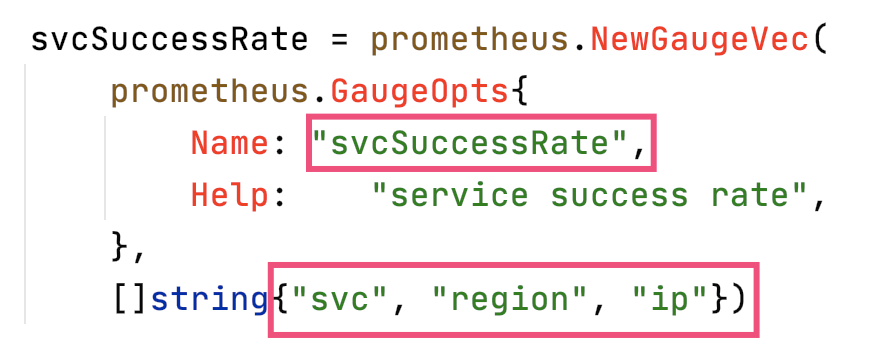
定义服务需要上报的指标和标签。举例,这里上报指标为:成功率(svcSuccessRate)。标签为:服务名(svc),IP(ip),区域(region)。
2. 服务部署
服务可以通过云服务器(CVM)的形式部署在云上(本文采用 CVM 的部署形式),也可以通过容器(TKE)的形式部署。
部署到 CVM 上,并检查是否正常暴露指标(示例中通过8581端口暴露指标)。

步骤2:配置抓取任务
1. 登录 Prometheus 监控服务控制台,点击新建,创建 Prometheus 实例。
2. 点击新建的 Prometheus 实例,进入实例详情页,点击数据采集 > 集成中心,搜索“抓取任务”,再点击一键安装,如下图:
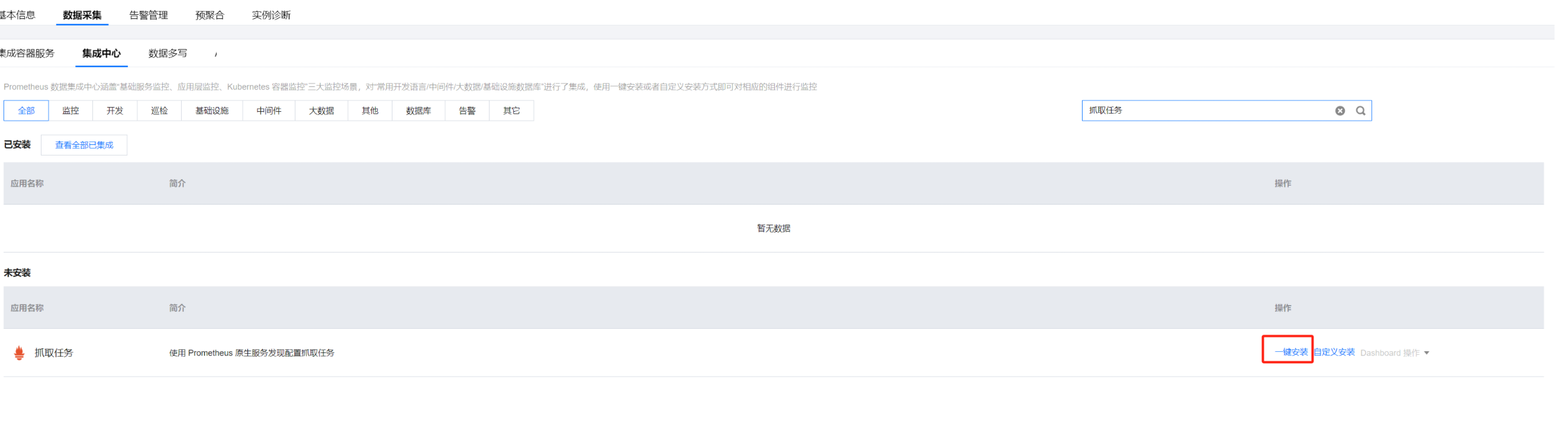
3. 安装成功后再进行配置,详细配置信息请参考 cvm_sd_config 配置。
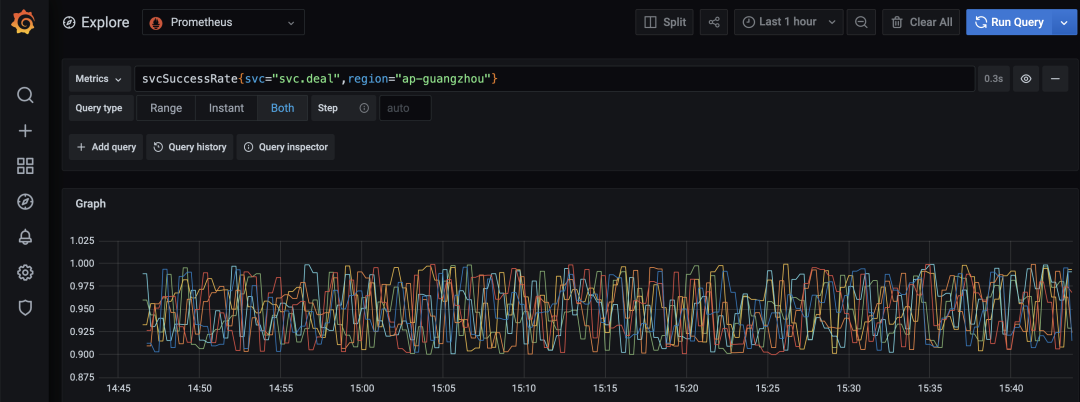
4. 验证数据是否抓取成功。通过 Grafana 查询对应的指标和标签。
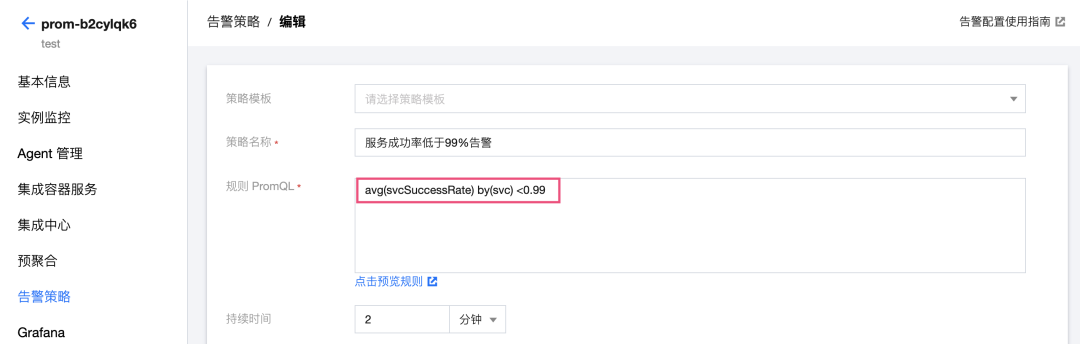
步骤3:配置告警策略
1. 配置服务宏观层面的告警:当服务的成功率低于两个9(0.99)时告警。
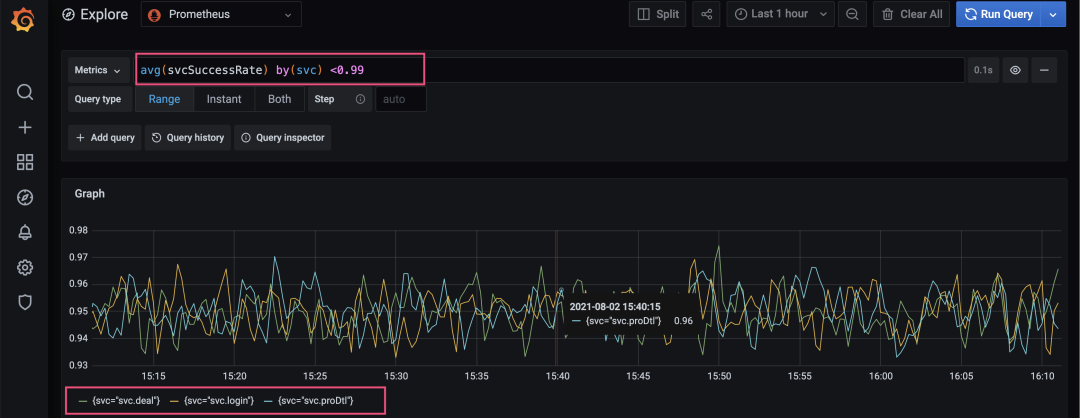
2. 配置服务更细维度的告警:当服务某个区域的成功率低于0.99时,触发告警。