简介
弹性伸缩 AS 支持根据监控的指标动态扩展伸缩组中的实例数量,您需定义告警触发策略,即触发扩展的监控指标状态以及如何按照需求变化进行扩展。告警触发策略包括简单策略和目标跟踪策略。
简单策略
创建告警策略需指定条件和动作,如下图所示:
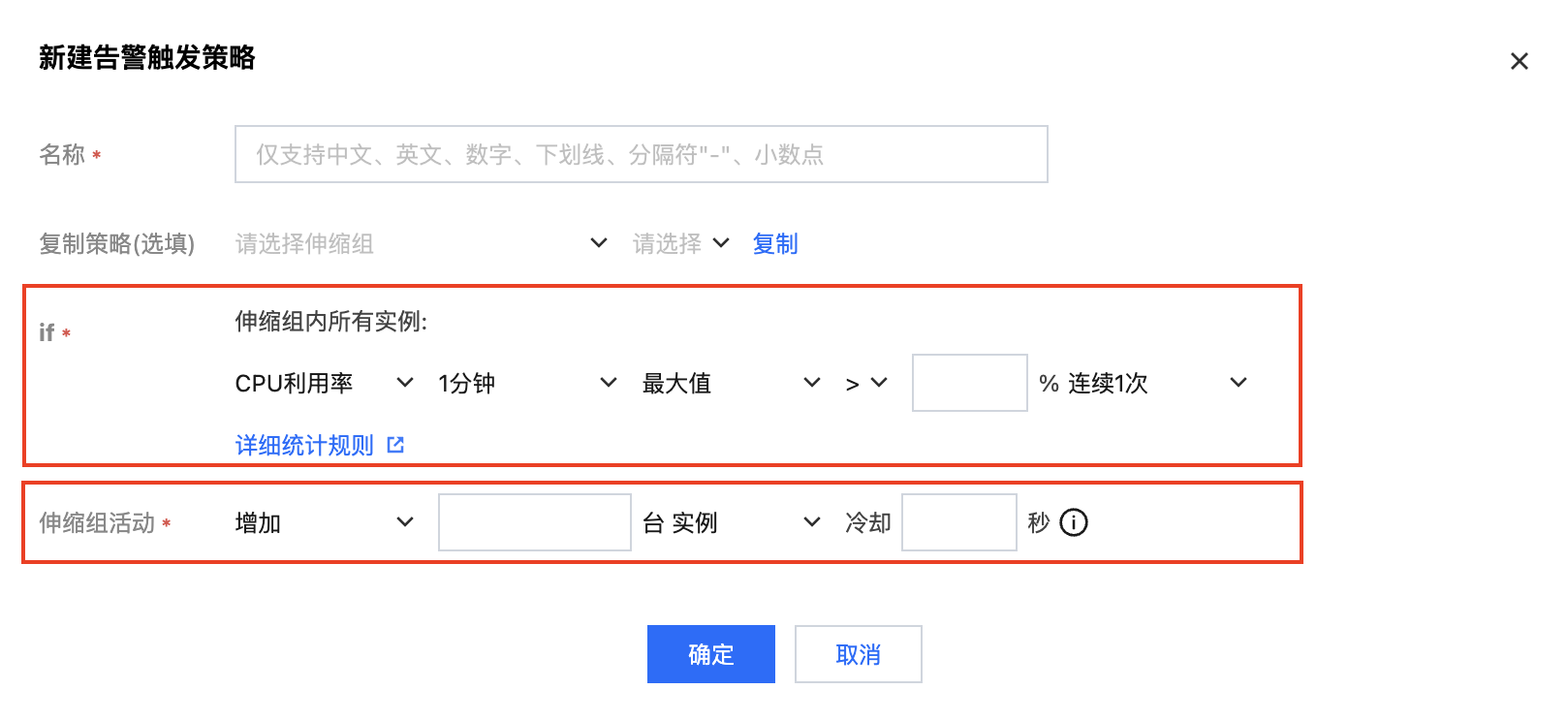
条件格式为:某个指标 + 周期 + 最大值/最小值/平均值 + 阈值 + 连续达到阈值的周期数。即指标在连续 N 个周期都达到了阈值。
执行动作为:增加/减少/调整至 + 目标数量的实例 + 冷却时间。
您可以为每个伸缩组各创建两个简单策略:一个策略用于扩展,另一个策略用于收缩。当业务量达到了告警策略指定的条件后, AS 将执行关联的策略对伸缩组进行收缩(通过终止实例)或扩展(通过启动实例)。
目标追踪策略
每个伸缩组支持创建一个目标追踪策略。目标追踪策略会根据选择的监控指标的告警值,以及设置的目标值,结合伸缩组内的实例数,自动计算所需的实例数量并进行扩容或缩容,从而将监控指标保持在目标值附近。创建目标跟踪策略,需要指定预定义指标、目标值、预热时间以及是否禁用缩容。
选择指标
目标追踪策略对适用的监控指标有一定限制。适用目标追踪策略的监控指标必须是有效的使用率指标,能够准确反映实例的繁忙程度,并且指标值需要与伸缩组实例数量成比例的增加或者减少。满足上述条件的监控指标,目标追踪策略才能使用指标值进行按比例扩展或缩减实例数量。创建目标追踪策略必须指定监控指标类型,支持的监控指标包括:
伸缩组平均 CPU 利用率
伸缩组平均内网出带宽
伸缩组平均内网入带宽
伸缩组平均外网出带宽
伸缩组平均外网入带宽
目标值
创建目标追踪策略必须指定目标值。目标值表示伸缩组最优的利用率或者吞吐量。一般来说,在满足腾讯云可观测平台告警条件下,当监控指标告警值大于目标值时,会触发伸缩组扩容;当监控指标告警值小于目标值的 80% 时,会触发伸缩组缩容。扩缩容的实例数量按照告警值与目标值(缩容时为目标值的 80%)的比例,对伸缩组内实例按比例进行扩展或缩减。对按比例计算得到的实例数(可能为小数),按照扩容实例数向上取整,缩容实例数向下取整进行调整,最终的扩缩容实例数还受限于伸缩组的最小和最大实例数。例如,伸缩组的最小实例数为0,最大实例数为10,伸缩组内现有实例9台。此时目标追踪策略触发,按比例计算需要扩容 1.5 台实例,向上取整后为 2 台,由于受限于伸缩组最大实例数,最终实际扩容 1 台。
实例预热时间
创建目标追踪策略可以指定实例预热所需的时间。由目标追踪策略触发扩容创建的新实例,将会进入预热,在指定的预热时间到期前,该实例不会影响伸缩组的监控指标。新实例加入伸缩组后,通常需要经历业务部署、负载均衡健康检查、数据采集等过程,才能上报稳定的监控数据,此过程中不适合触发新的伸缩活动。为了限制扩缩容过程执行的频率,当伸缩组内存在正在预热的实例时,目标追踪策略触发产生的扩缩容活动会被取消。
禁用缩容
开启禁用缩容,目标追踪策略仅触发扩容活动,不会触发缩容活动。
目标追踪策略触发扩容的条件为,指定类型指标连续 3 个周期高于阈值(目标值),每个周期 1 分钟;触发缩容的条件为,指定类型指标连续 15 个周期低于阈值(目标值的80%),每个周期 1 分钟。
场景示例
例如,您有一个电商网站应用程序,当前使用了5个实例。您做了一个运营活动,担心访问量远大于您的预估,您可以设置当前实例上的负载上升到70%时额外启动2个新的实例,然后在负载下降到40%时终止多余的实例。您可以为伸缩组配置两条简单策略,分别根据负载高于70%进行扩容,负载低于40%进行缩容。如下图所示:
或者,可能您希望整个伸缩组的负载水平维持在 60% 附近,并且根据实际的负载水平,进行按比例的扩容和缩容,您可以为伸缩组配置一条目标追踪策略,用于实例数量根据实际负载水平动态变化,以达到目标的负载水平接近期望值。
操作步骤
1. 登录弹性伸缩控制台,选择左侧导航栏中的 伸缩组。
2. 选择需修改的伸缩组,单击伸缩组 ID 进入伸缩组基本信息页面。如下图所示:

3. 在该伸缩组详情页面,选择告警触发策略页签,在该页面管理与伸缩组相关联的告警触发策略。如下图所示:
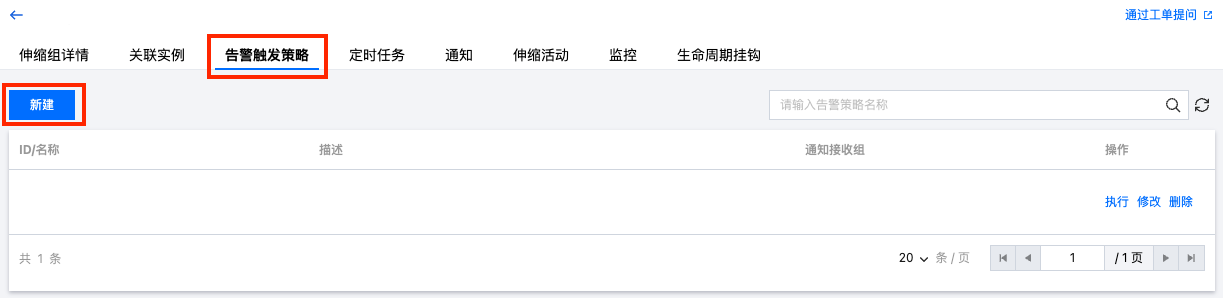
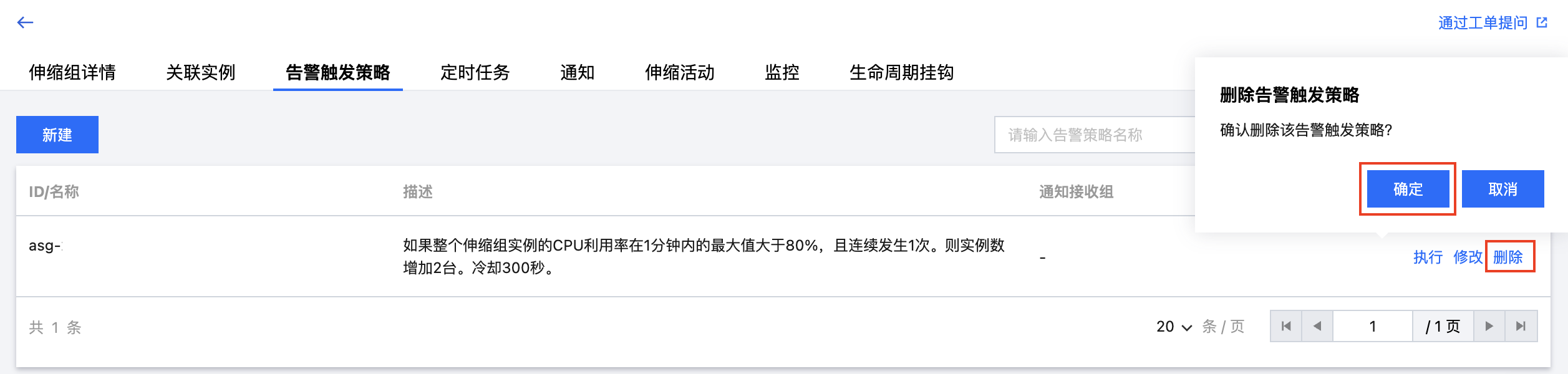
单击新建,填写名称、触发条件、和具体伸缩活动可添加新的告警触发策略。
单击某一告警策略右侧删除并点击确定,可删除该条告警触发策略。
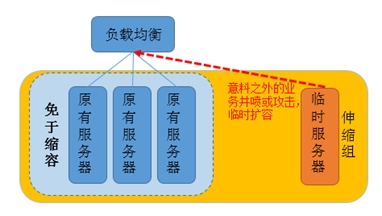
指定某台服务器不受告警伸缩策略影响
使用 auto scaling 前,也许您的系统已经有常用的服务器,您出于以下考虑,不希望机器被告警伸缩策略移出:
一机多用:集群中某台服务器除了做集群所做的事情外,还兼做其他用途。例如网站建设初期,您的某台服务器既作为缓存服务器使用,又作为文件服务器。在缓存服务器集群放入伸缩组时,您不希望它被告警伸缩策略移出。
存放数据:该服务器是有状态的或自带其他服务器没有的数据。例如集群中其他服务器运行中产生的增量数据,都统一保存到该服务器里。
更新镜像/快照:固定使用该服务器定期做镜像和快照
设置方法:
1. 您可以在伸缩组列表里单击服务器所在的伸缩组,进入管理页面。
2. 选择管理页面中的关联实例页签,对所要设置的实例单击“设置移出保护”,而后在设置移出保护弹窗中单击确定。




