功能介绍
自动规整的定位是作为重调度的一种策略,作为首次调度的一种补充,给用户提供了一种自动的、安全的、智能的规整集群资源的方法。帮助用户在集群使用过程中对抗时间带来的“资源碎片”,提升集群的资源使用效率,节省用户成本。
这里“资源碎片”是一种形象的比喻,代表 Kubernetes 集群中难以被利用的计算资源(CPU、内存、GPU 等)。这些资源在节点间分配不均衡,长期处于闲置或难以被有效利用的状态。
为什么会有“资源碎片”
1. 业务资源申请的多样化与节点资源配比的错配。集群中业务对于资源的申请并不总是与节点资源配置一致。例如,集群中部分节点的 CPU:内存比例可能为 1:4,而业务申请的比例为 1:8。这可能导致这些节点的内存比 CPU 更早被分配完,从而导致部分 CPU 资源无法被有效利用。
2. 业务负载的波动。业务可能会随着具体需求动态地进行扩缩容。即便在首次调度中尽可能紧凑的装箱策略,节点的实际装箱情况也可能随着业务 Pod 的波动逐渐劣化,导致部分碎片产生。
3. 节点规格多样化。集群中节点的资源规格、可用区或其他配置往往是多样化的,这无形中会加剧资源分配的碎片化。例如小卡数业务占用了大卡数节点,在资源分配上有重新优化空间但缺乏自动化手段。
功能收益
规整低装箱节点,将低装箱率节点的业务重调度到其他节点进而提升非空节点的装箱率。

用户痛点
随着集群运行时间的增长,集群中的资源装箱率可能稳定在一个不高效的区间,管理人员会遇到各种各样的资源治理痛点。用户梳理相关数据代价大,缺乏相关工具,手动操作风险高。
1. 节点资源装箱率低,集群中节点的资源利用不充分,其实可以更紧凑地部署,用更少的节点承载现有业务。
2. 集群中节点装箱率、利用率难以优化。集群中的装箱情况差异大,有些节点很满,有些节点很空。集群中有些节点 CPU 装满了,但是内存还有空余。集群管理人员遇到这些问题的时候往往需要大量的手动工作,缺乏合规可靠的自动化工具。
3. 集群中需要调整汰换部分节点时手动工作繁琐。集群中有些节点老旧、昂贵、或需要因其他原因需要替换的时候缺乏自动化手段。
4. 集群管理者与使用者视角的冲突差异。集群中应用的利用率可能已经达到不错的水平,但是集群整体利用率与装箱率并不理想。集群管理人员希望进行规整腾挪时有可能影响业务连续性,缺乏合规可靠的工具。
核心特征
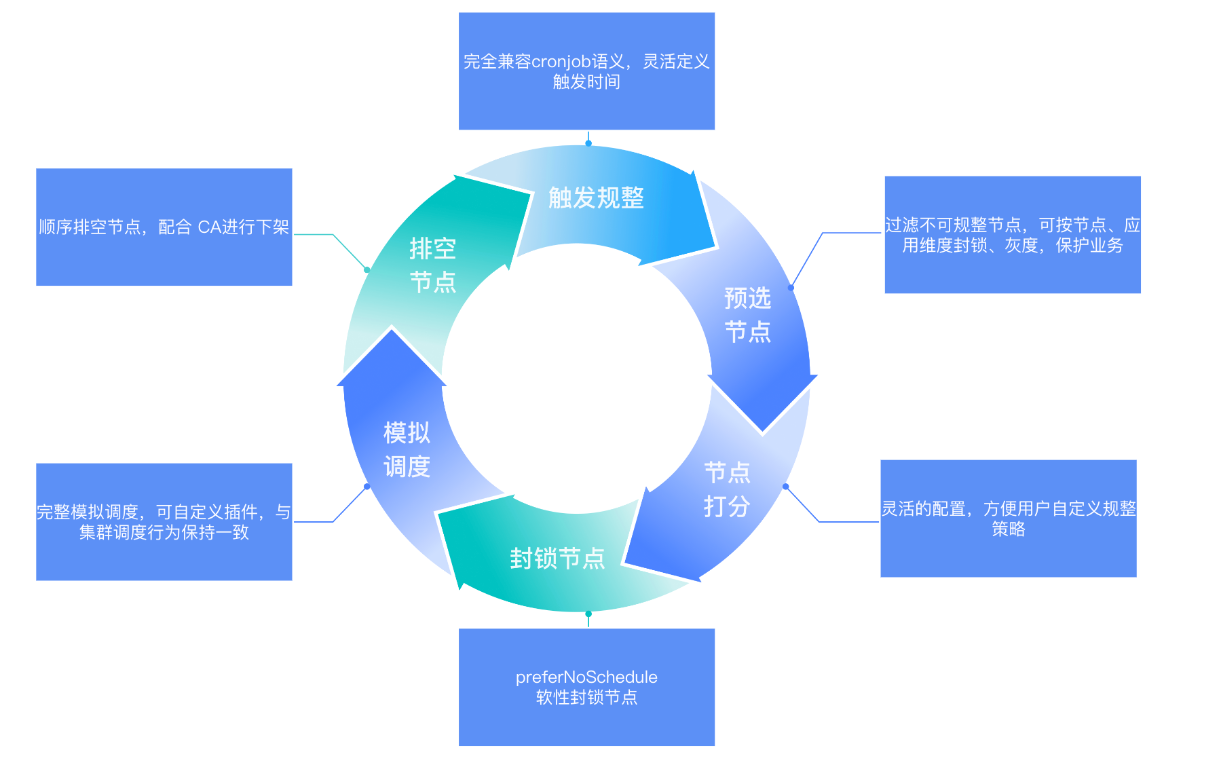
开启前:用户可感知可控制
1. 灵活可配的策略配置,用户可配置不同类型节点、资源进行不同策略的自动规整。
2. 灵活的灰度配置,用户可按照业务、节点级别进行灰度。
规整过程:平台保障碎片识别准确度、结合模拟调度保障规整稳定性
1. 近实时的碎片评估,综合评估节点装箱率、资源闲置数、业务类型、资源类型等因素,挑选最合适的节点贴合业务需求进行规整。
2. 完善的模拟调度、可配置规整速度、多级熔断策略保障业务安全。
3. 多资源类型的规整支持,支持 CPU、内存、带宽、GPU 等,用户可自定义对应权重与策略。
规整后:用户实时观测、随时中断
1. 自动规整全流程有对应 Metrics 暴露,易于监控。
2. 规整策略热加载,用户可随时调整,即时生效。
功能流程
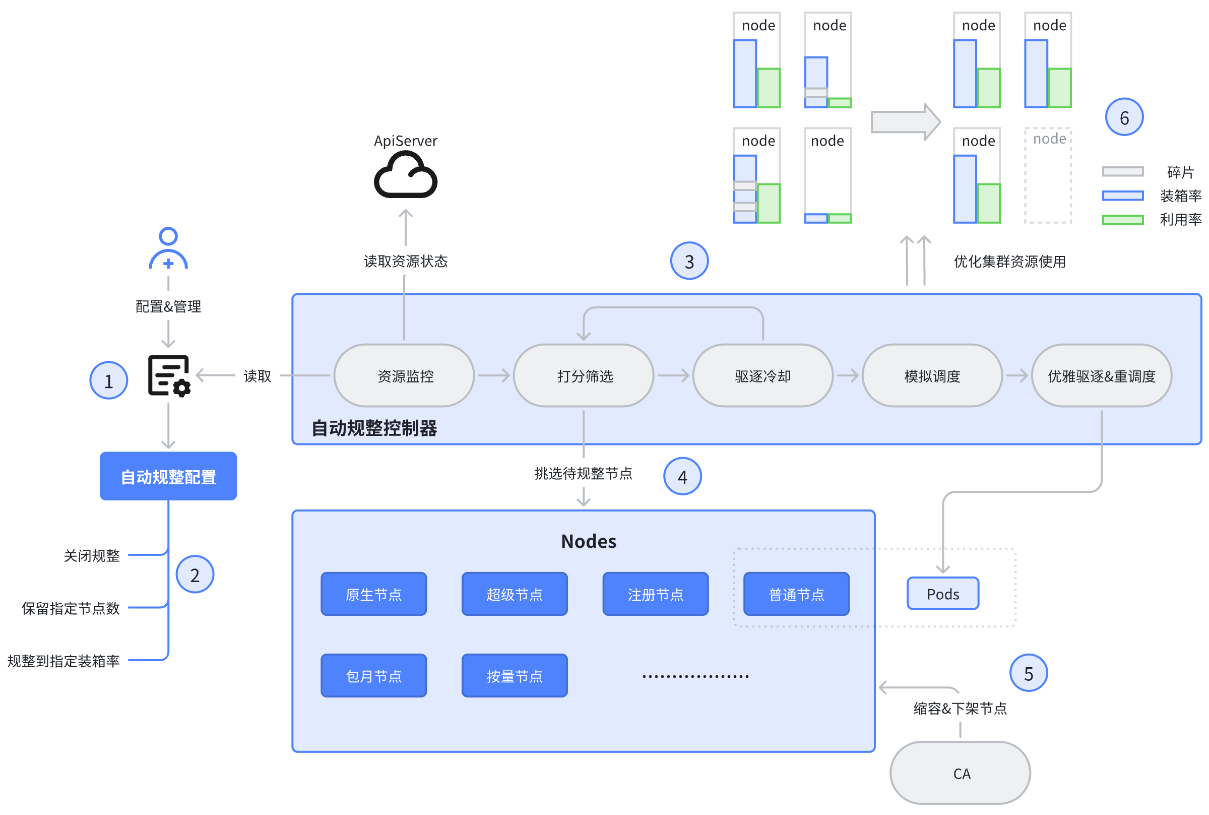
1. 配置并开启自动规整。
2. 自动规整策略分为三种 (枚举类型):
a. 关闭规整 (off),代表对某些节点关闭资源规整(如控制面节点)。
b. 保留指定节点数 (reserve),维持集群中满足选中条件的非空节点不大于某个数量,服务于节点替换腾退等场景。
c. 规整到指定装箱率 (ratio),代表对选中节点进行自动规整,控制相应节点的装箱率不低于配置比例。
3. 自动规整控制器读取配置并开始工作。控制器会 list-watch 集群中对象,动态对节点进行打分,将排序靠前的节点进行规整。规整前会进行节点与应用的操作冷却判断,防止频繁驱逐特定业务或节点。经过驱逐冷却判断后所有 Pod 会经过完整的模拟调度,模拟调度失败的 Pod 会被跳过驱逐,防止出现影响业务的情况。所有驱逐行为严格遵守 PDB(Pod Disruption Budget),没有被 PDB 保护的节点会被视同不可驱逐。
4. 节点打分面向装箱率,以装箱率为核心,综合考虑资源空置率、绝对浪费数量、业务冷却时间、节点冷却时间等。在保证提升资源效率的同时最大限度兼顾稳定性。所有相关变量灵活可配且带有符合经验判断的默认值。
5. 可配置 CA (Cluster Autoscaler)组件自动将空节点下架。
使用说明
前提条件
1. Kubernetes 版本 ≥ 1.22。
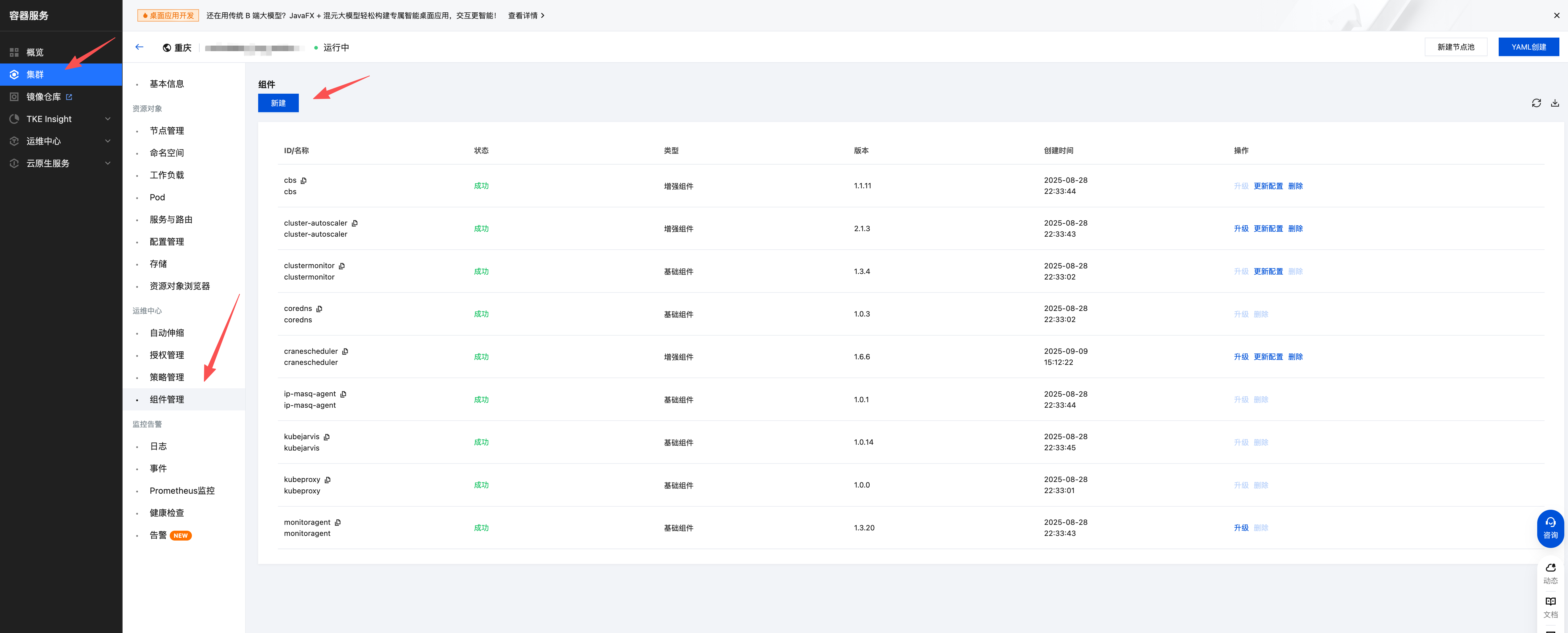
2. 集群安装并开启 crane-scheduler 套件且版本不低于 1.6.5。
2.1 您可以在 容器服务控制台 中找到集群,在集群的运维中心 > 组件管理中新建组件。
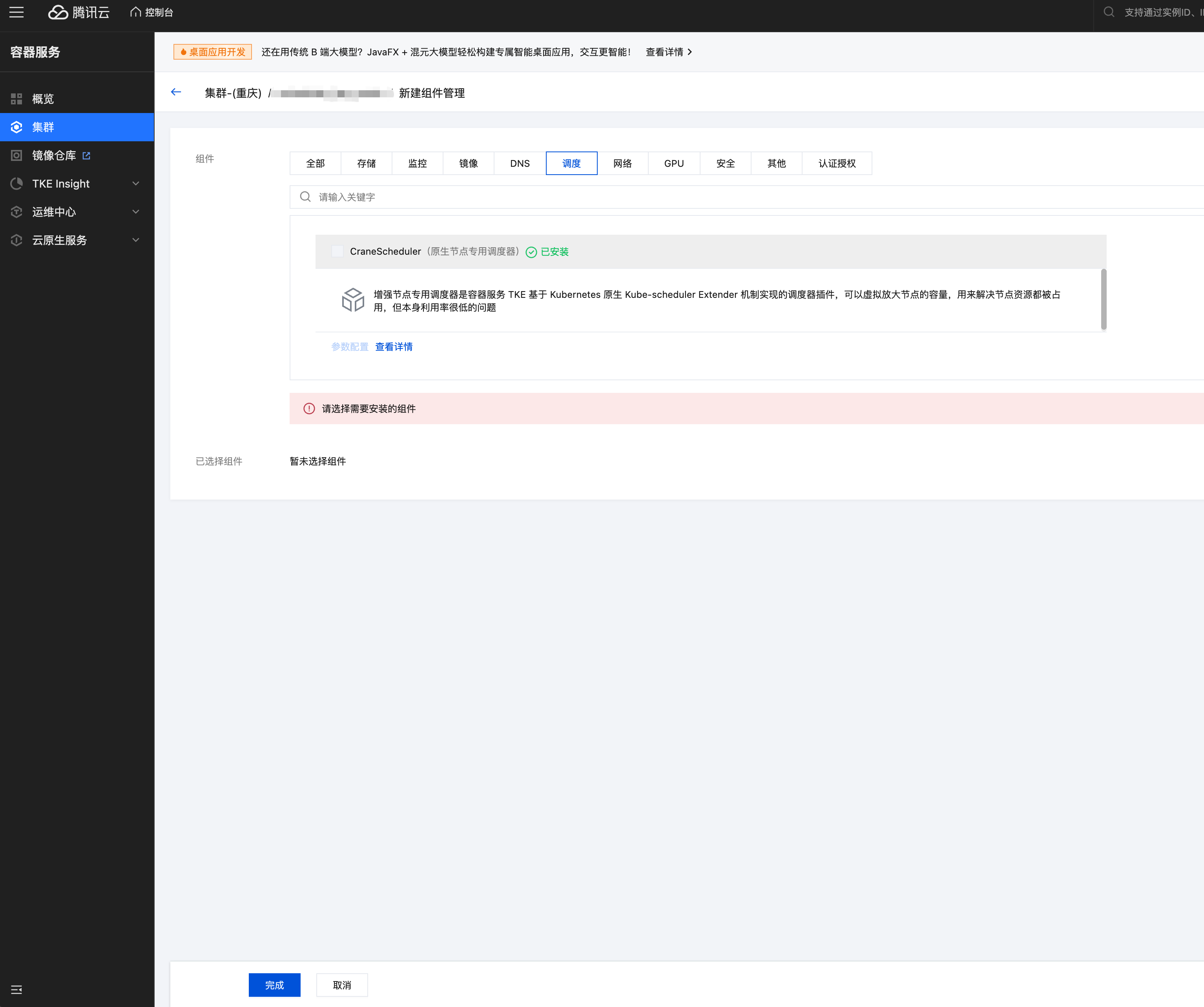
2.2 在新建组件管理页面选择调度 > CraneScheduler。
3. 用户业务需要尽可能按照实际需求开启 PDB (Pod Disruption Budget)并配置符合业务需求的可调度参数。
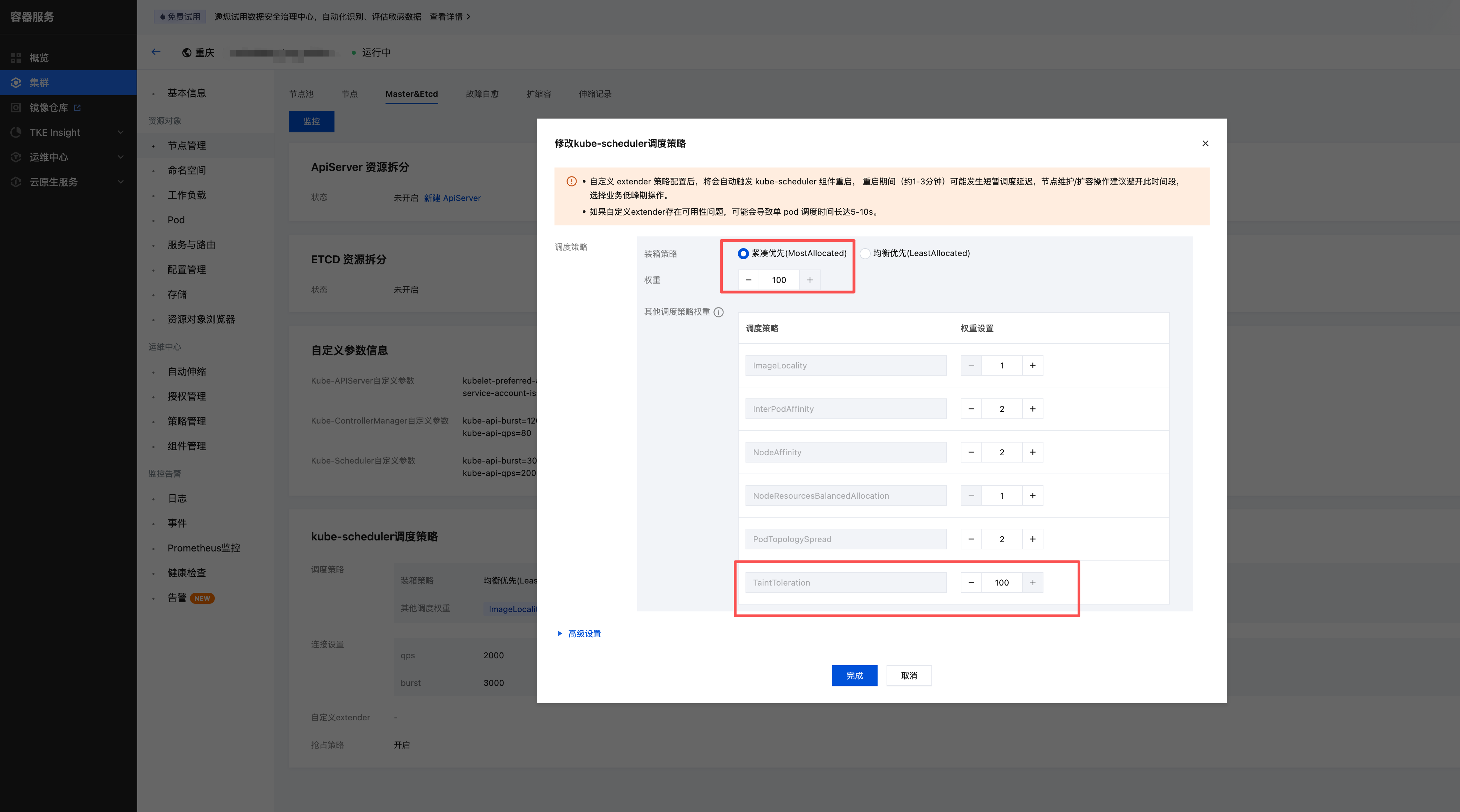
4. 集群开启紧凑调度并调高 TaintTolerationPriority 权重调整至 100。
4.1 在 容器服务控制台 中找到集群,在集群详情页选择节点管理 > Master&Etcd。
4.2 单击修改 kube-scheduler 调度策略右上角的编辑,修改紧凑优先调度及权重。(前端页面支持 Kubernetes 版本 ≤1.30,高版本请 提交工单 来与我们联系。)
使用限制
仅支持普通节点、原生节点。暂不支持超级节点。
使用方式
1. 重调度器中开启 AutoConsolidate 策略。
a. 策略开启位置 kube-system namespace下名为 crane-descheduler-policy 的 ConfigMap。
b. 参数说明。
apiVersion: "descheduler/v1alpha1"kind: "DeschedulerPolicy"strategies:"AutoConsolidate":enabled: true #开启自动规整params:configValues:"burst": "20" #kube-client qps burst"qps": "10" #kube-client qps"executeConsolidateCron": "0 * * * *" #执行自动规整定时配置"nodeCacheExpireTime": "240" #节点规整历史缓存过期时间,分钟单位"workloadCacheExpireTime": "720" #应用规整历史缓存过期时间,分钟单位"plugin-crane": "/data/crane/policy.yaml" #第三方插件配置挂载位置,需要以 “plugin-”开头"policyConfigPath": "/data/policy.json" #自动规整策略挂载路径
2. 配置自动规整策略。
a. 策略配置位置 kube-system namespace 下名为 auto-consolidate-policy 的 ConfigMap。
b. 参数说明。
{"globalTargetRatio": 70, #全局最低装箱率配置,可被策略组中的值覆盖。如果被选中节点在规整前发现装箱率高于 70%则会跳过"lowBinpackWatermark": 10, #全局低装箱定义水位线,低于此值则会被自动规整模拟调度检查资源时认为是不可用节点。"maxConsolidateCount": 3, #单个节点在缓存有效期内最大规整次数"maxPerBatch": 2,#单次最多规整节点数"cooldown": 60, #应用两次规整间强制等待时间"policies": [ #策略组配置{"consolidateType": "ratio", #代表规整策略为规整到指定装箱率。每个策略只能有一个类型属性,且只能在 ratio/reserve/off 中取值。"targetRatio": 70, #选中节点的规整目标最低装箱水位线,如缺省则继承 globalTargetRatio 值。"labelSelector": {"matchExpressions": [{"key": "kubernetes.io/hostname","operator": "Exists","values": []}],"matchLabels": {}},"name": "default" # 默认策略,对所有节点开启规整。策略名称不影响实际运行,但是有意义的名称有利于管理实际策略的配置。建议名称与策略的类型与作用域相关。 策略组中不可出现同名策略。},{"consolidateType": "off", #代表规整策略为关闭规整"labelSelector": {"matchExpressions": [{"key": "node-role.kubernetes.io/master","operator": "Exists","values": []}],"matchLabels": {}},"name": "turn-off-master" # 关闭对master节点的规整,如果一个节点被多个策略选中,排名靠后的策略会覆盖靠前的设置},{"consolidateType": "reserve", #代表规整策略为保留指定节点数量"shrinkWeight": 20, #规整权重,越高则对应节点越优先被规整。推荐不大于 100。"labelSelector": {"matchExpressions": [{"key": "machine-type","operator": "In","values": ["expensive-machine"]}],"matchLabels": {}},"name": "reserve-rules","minimumNodes": 10, #尽可能只保留 10 台此类节点。若此参数不配置或为 0,则会尽可能清空所有该类型节点。},# GPU 碎卡规整或任意资源规整场景的示例配置{"consolidateType": "ratio", #指定为ratio模式,即面向装箱率规整"labelSelector": {"matchExpressions": [{"key": "label-to-select-gpu-nodes", #可以选择到 gpu 节点或任意资源类型节点的 selector 配置"operator": "In","values": [" corresponding-values"]}],"matchLabels": {}},"name": "gpu-rules","resourceConfig": { #针对何种资源进行装箱计算。此字段若缺省且规整模式为 ratio,则默认按照 cpu 来计算装箱率"keyResource": "nvidia.com/gpu" #gpu的资源类型,此处可为任意资源类型,请和节点资源声明保持一致},"targetRatio": 100 #目标装箱率,会覆盖全局装箱水位线值}],"consolidateBucket": { # 日内规整节点数量限额"consolidateBucketEnabled": true, #开启限额"consolidateBucket": 5 # 限额次数,5代表日内最多5台节点可以被规整}}
作用范围
auto-consolidate-policy 中 policies 选中的节点。
使用场景
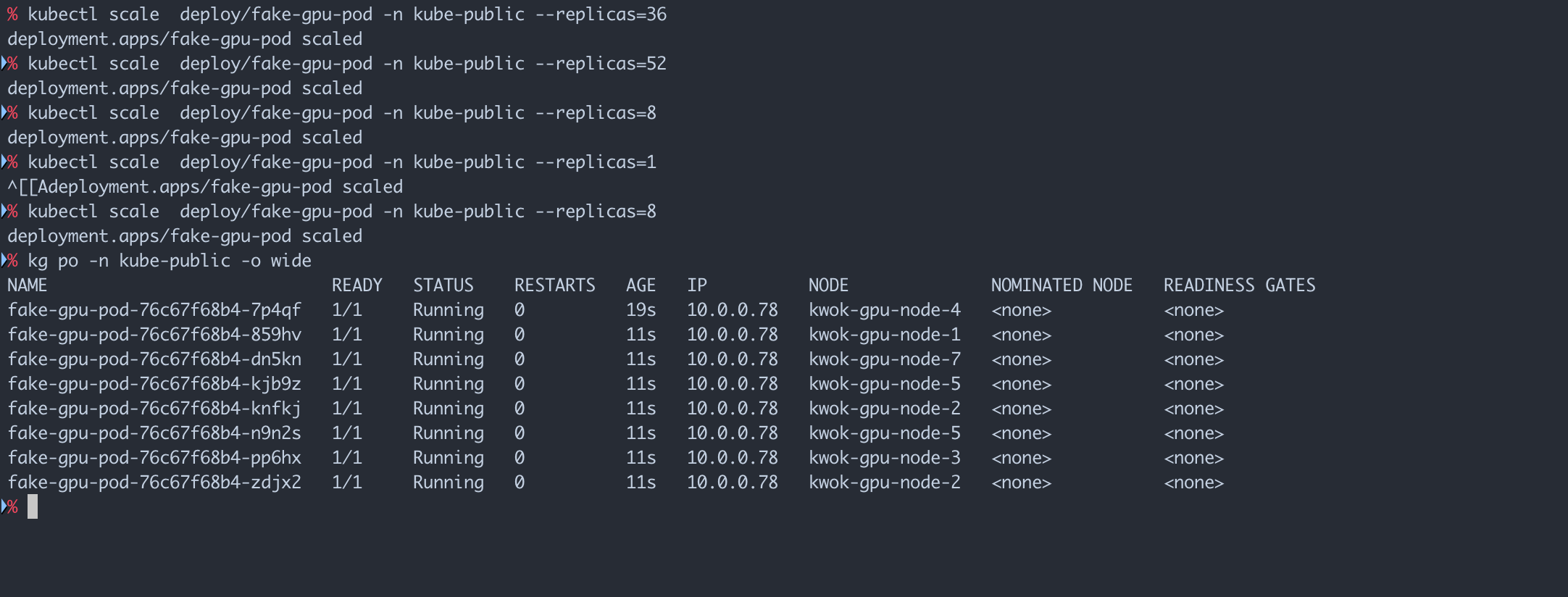
GPU 碎卡规整
连续调整8卡应用的 replica 数,模拟应用扩缩容,现象是本来应该聚拢在一台8卡机器上的 Pod 被打散到若干台节点。
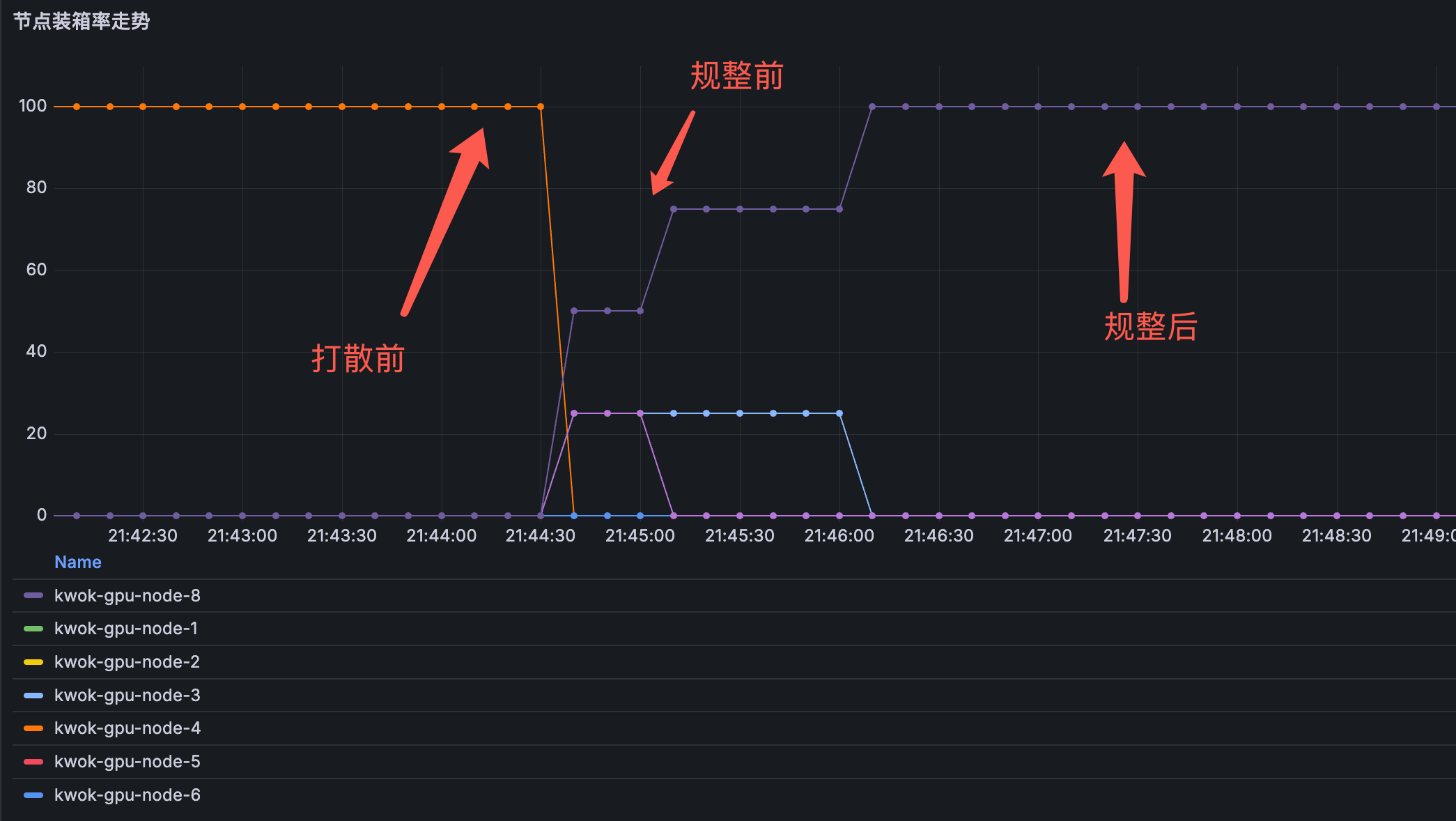
开启自动规整后,Pod 会被重调度,向一台节点上聚集。
排查方式
1. 检查重调度组件是否部署。
kubectl get deploy -n kube-system crane-descheduler
2. 检查自动规整策略是否开启。
kubectl get cm -n kube-system crane-descheduler-policy -o yaml
3. 检查自动规整策略是否符合预期。
kubectl get cm -n kube-system auto-consolidate-policy -o yaml
4. 检查组件日志。
kubectl logs -f<descheduler-Pod>-n kube-system



