本文档介绍如何在 TKE 上部署 Embedding 模型。
简介
Embedding 模型是将文本、图像等非结构化数据转化为低维稠密向量的 AI 模型,这些向量能精准捕捉数据的语义或特征关联,让机器可通过向量计算理解数据间的相似性,是语义检索、推荐系统、聚类分析等场景的核心基础,在文档检索中,可通过对比查询与文档的 Embedding 向量快速匹配相关内容。
环境准备
步骤1:创建 TKE 标准集群
1. 登录 腾讯云容器服务控制台,选择左侧导航栏中的集群。
2. 单击集群列表上方的新建。
3. 在集群类型中,选择标准集群。
4. 在创建集群 > 网络配置中,选择 VPC-CNI,其余参数保持默认即可。
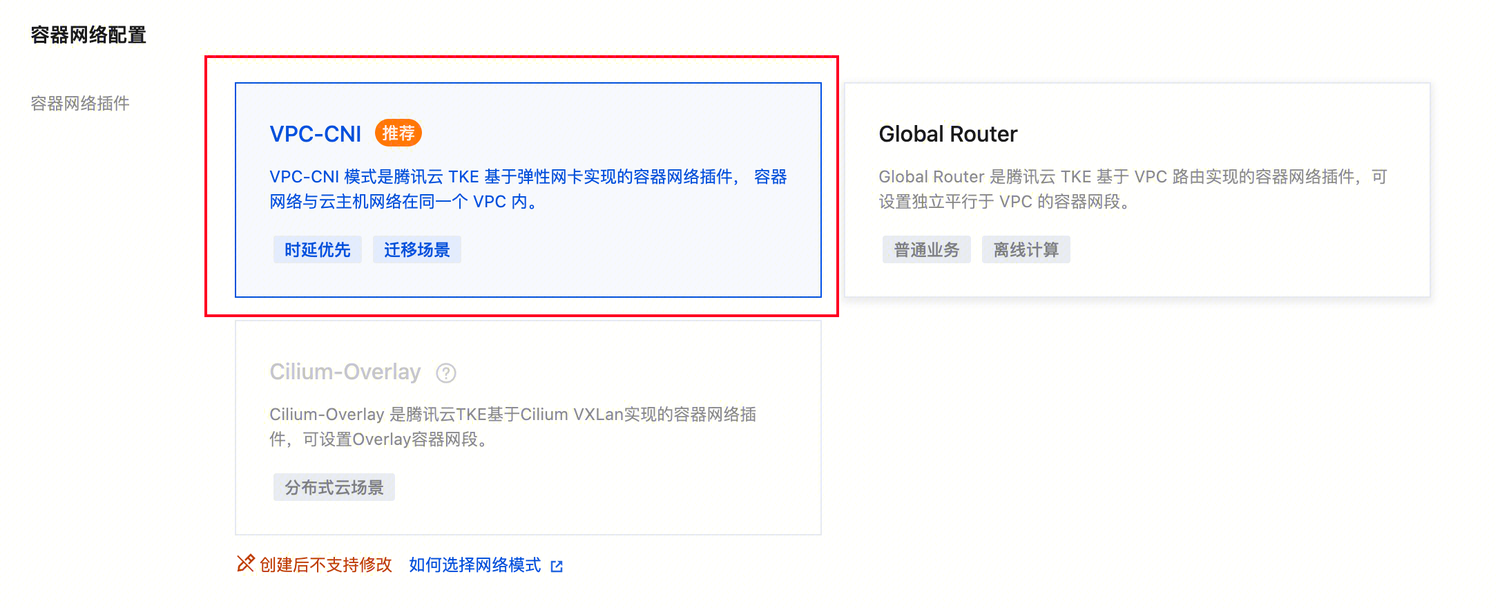
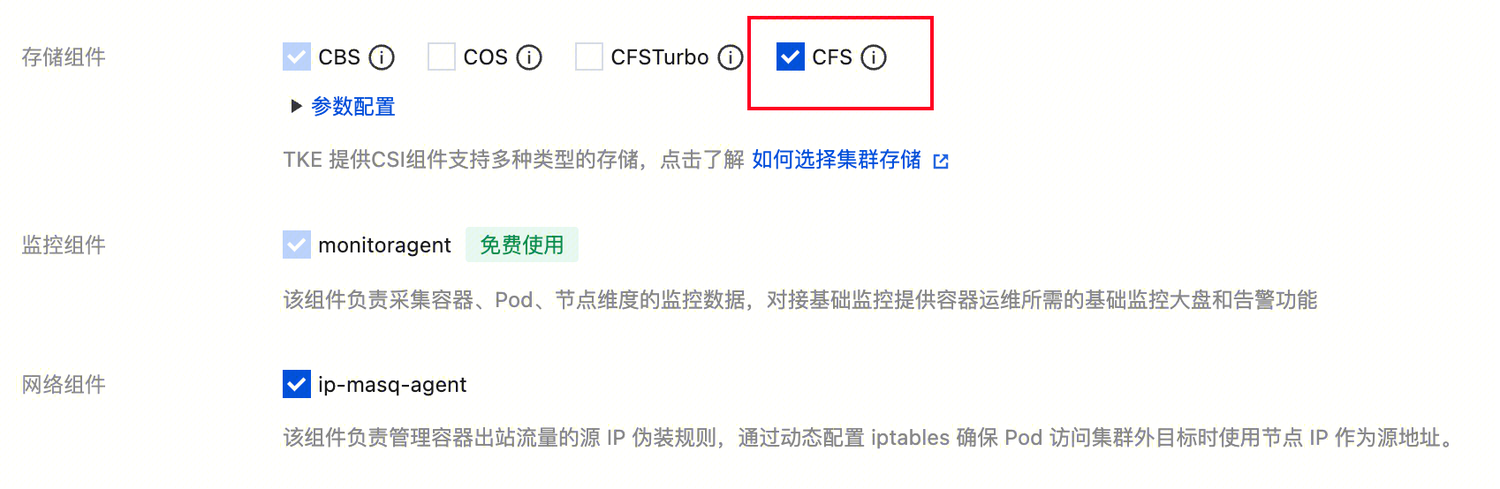
5. 在创建集群 > 组件配置中,存储组件勾选 CFS(用于持久化存储大模型权重文件;若创建时未勾选,后续可在 “集群 - 组件管理” 中安装,操作详情请参见 通过组件管理页安装)。
6. 创建下载节点池。
选择 3 个节点(用于后续 3 个并发下载任务),推荐机型 SA5.LARGE8(性价比高,满足下载需求),系统盘≥300GB,并分配 “免费公网 IP” 及带宽≥100Mbps(保障单节点下载速度,缩短整体耗时)。
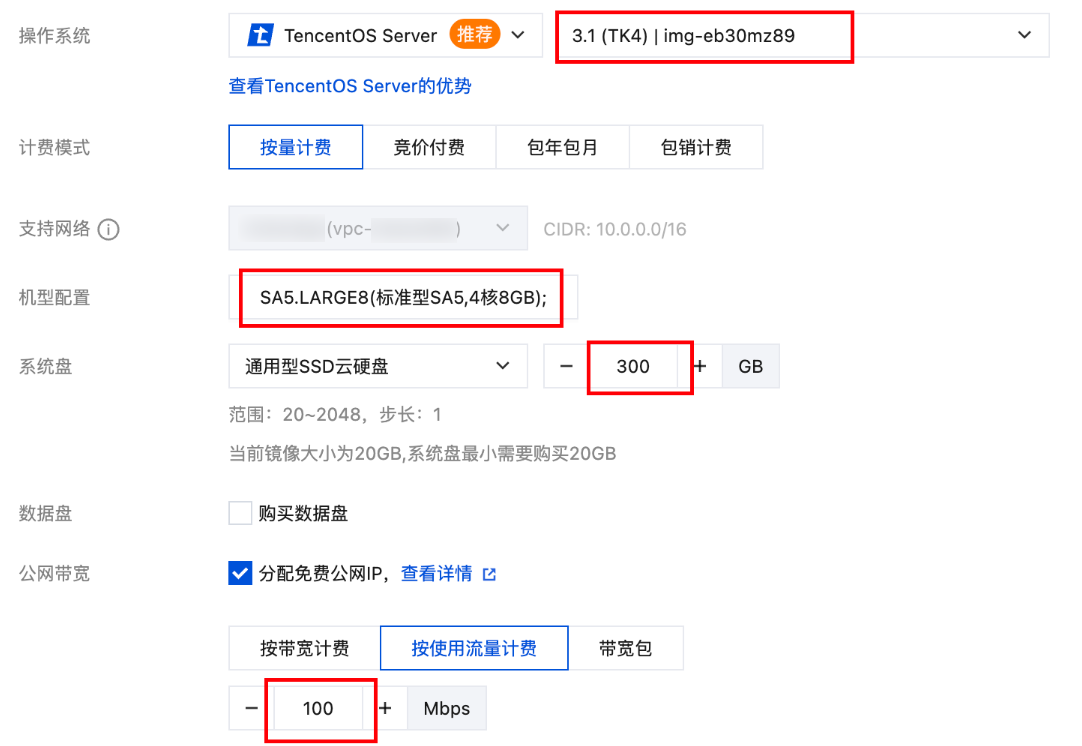
7. 创建推理节点:需 1 个 GPU 节点(大模型推理依赖高显存),推荐选择 PNV5b.8XLARGE96机型(单卡 48GB 显存,满足模型需求)。
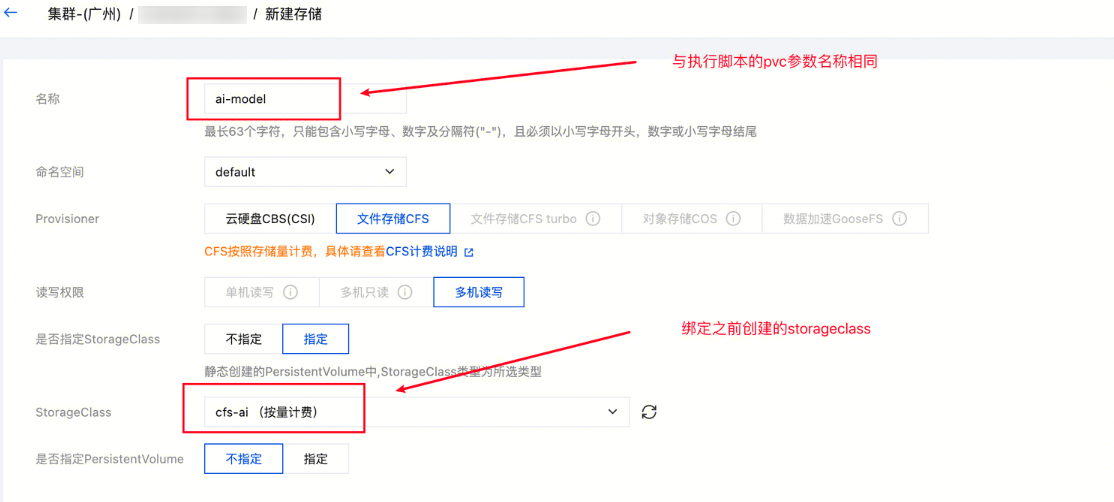
步骤2:创建存储组件
需创建 StorageClass(CFS 存储)和 PVC,确保模型下载后能被推理服务直接调用:
1. 进入集群的存储 > StorageClass 页面,单击新建,存储类型选 “文件存储 CFS”,可用区与推理节点一致(减少跨区访问延迟),其余参数默认;
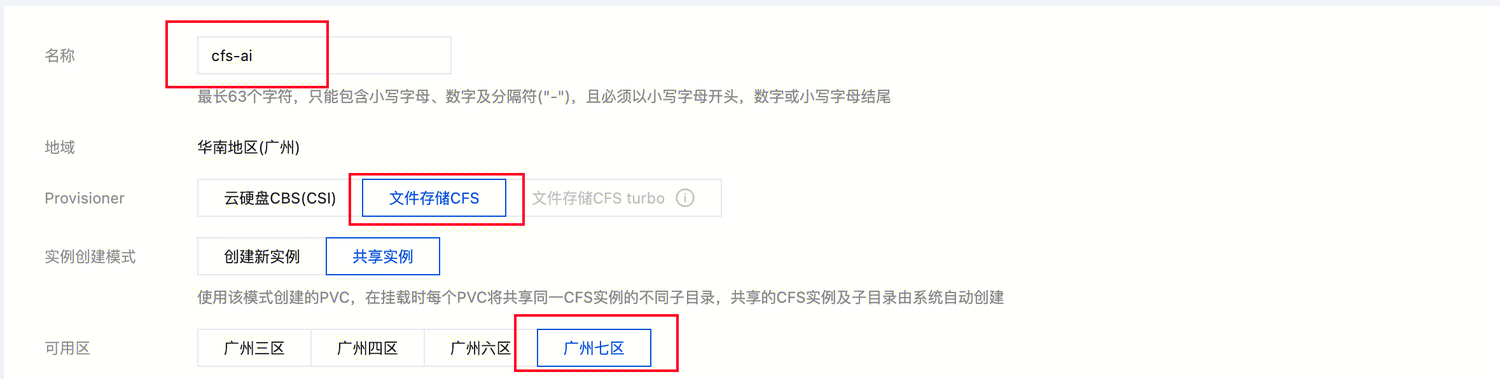
2. 进入存储 > PVC 页面,单击新建,名称为 ai-model(与后续下载脚本参数一致,避免手动修改配置),存储类选择上一步创建的 StorageClass 对象。
部署模型
本实践使用 vllm 推理框架,该框架支持的 embedding 模型主要有:BGE 系列模型和 E5-Mistral 系列模型,这两个系列的模型均可使用 vllm 框架进行模型推理,本文采用 E5-mistral-7b-instruct 模型完成验证。
E5-mistral-7b-instruct:基于 Mistral-7B 架构微调的指令遵循模型,融合了 E5 系列在检索增强领域的优势与 Mistral 的高效推理能力;在中文与多语言理解、长文本处理和检索增强生成(RAG)场景中表现突出,并且拥有较长的上下文长度,支持 vllm 框架下的推理服务。
步骤1:下载依赖
登录集群中的节点,节点镜像为 TencentOS 可以使用以下命令进行安装:
yum install -y jqcurl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
步骤2:下载模型
进入集群中,拉取 tke-ai-playbook,机器若提示安装 git,请先安装 git 后再拉取代码:
git clone https://github.com/tkestack/tke-ai-playbook.git
执行 playbook 中的下载脚本 tke-llm-downloader.sh,该脚本可以使用多个节点并发拉取模型,加快模型下载速度,PVC 名称需与前述一致,模型名称参数则选择目标模型名称,可前往 ModelScope 获取模型名称。
tke-llm-downloader.sh 是一个在 Kubernetes 集群中自动化下载大语言模型的工具脚本,主要功能包括:
模型下载管理:支持从 ModelScope 或 Hugging Face 下载大语言模型到 Kubernetes PVC 存储;
并发下载优化:通过 Kubernetes Job 的 completions 和 parallelism 参数实现多 Pod 并发下载,提升下载速度;
节点调度控制:避免多个下载 Pod 调度到同一节点。
bash scripts/tke-llm-downloader.sh --pvc ai-model --completions 3 --parallelism 3 --model intfloat/e5-mistral-7b-instruct
预期结果:三个 Pod 状态为 Completed 后,模型下载工作则执行完成。

步骤3:模型部署
vllm-inference-tke 是一个部署 vllm 推理框架并暴露服务的 Helm Chart 包,可支持单机单卡、单机多卡、多机多卡等多种部署模式,修改自定义参数即可部署自建大模型。
进入 vllm-inference-tke 目录,运行 vllm-inference-tke 的 Chart 包,该 Chart 可以在 TKE 上部署基于 vLLM 的 OpenAI 兼容 API 服务,APIKey 需要自行设置,默认无需 APIKey,修改 model name 为自己想要部署的模型,并且 PVC 修改为自己集群的 PVC 名称,具体参数修改参考下述,目前默认参数支持单机单卡部署。
cd tke-ai-playbook/helm-charts/vllm-inference-tkevim values.yamlhelm install vllm-service .
本文提供部署 E5-mistral-7b-instruct 模型的具体参数,具体的 values.yaml 文件内容如下:
model:name: "intfloat/e5-mistral-7b-instruct"pvc:enabled: truename: "ai-model"path: "intfloat/e5-mistral-7b-instruct"local:enabled: falsepath: "/data0/intfloat/e5-mistral-7b-instruct"server:replicas: 1lwsGroupSize: 1image: "ccr.ccs.tencentyun.com/tke-ai-playbook/vllm-openai:v0.10.1-20250801"imagePullPolicy: IfNotPresentapiKey: ""resources:requests:nvidia.com/gpu: 1limits:nvidia.com/gpu: 1args:tpSize: 1ppSize: 1epEnabled: falsemaxModelLen: 2048maxBatchSize: 32extraArgs:- --disable-log-requests- --cuda-graph-sizes 1 2 4 8 16 24 32env:- name: VLLM_WORKER_MULTIPROC_METHODvalue: "spawn"service:enabled: truetype: LoadBalancerport: 60000labels: {}podAnnotations: {}
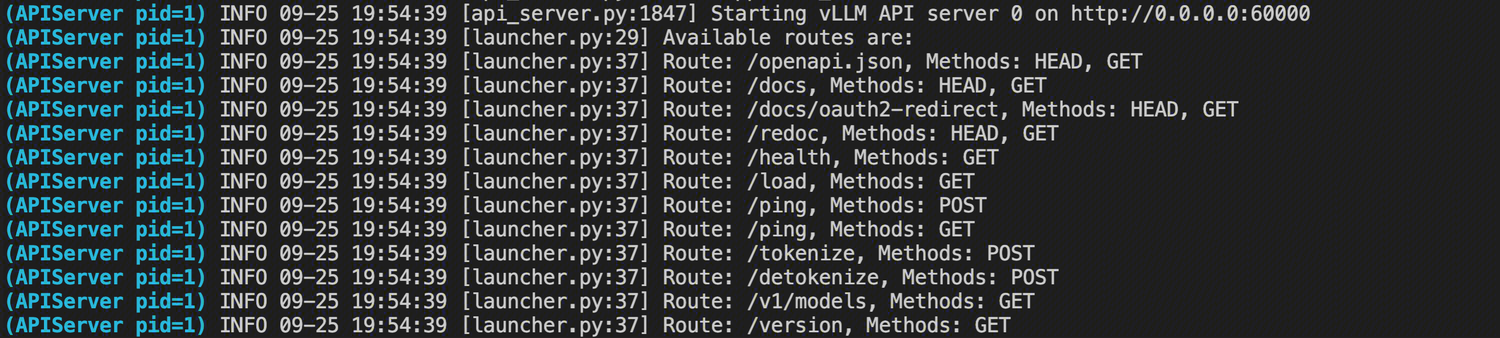
部署的模型会通过 service 暴露端点和端口,查看 Pod 日志看模型状态是否健康。
kubectl get svc | grep vllm-servicekubectl logs -f pod-name
预期结果:
步骤4:测试向量嵌入
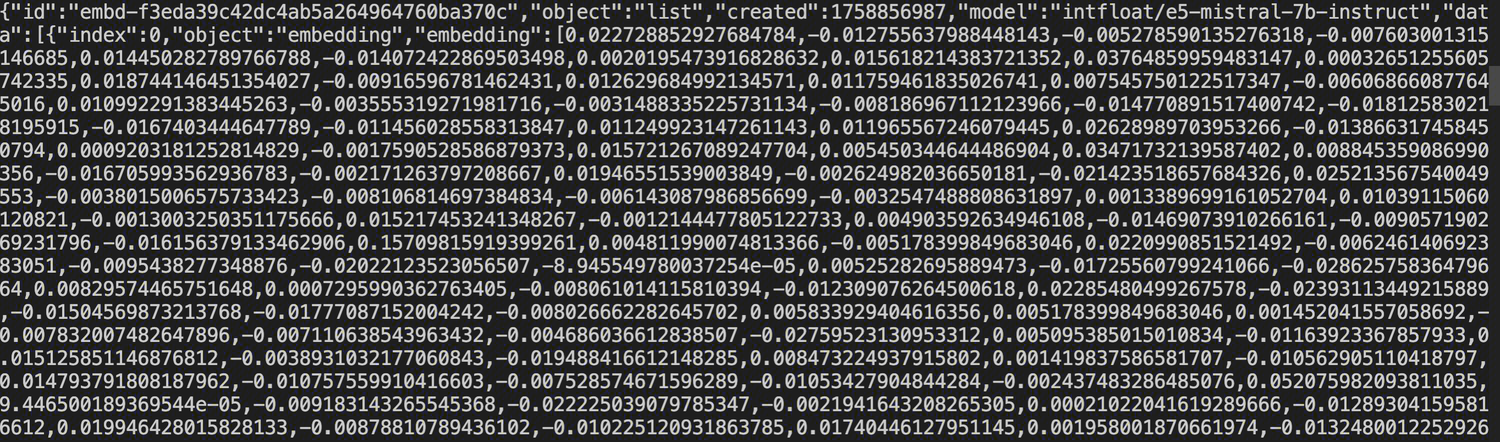
curl -X POST http://xx.xx.xx.xx:60000/v1/embeddings \\-H 'Content-Type: application/json' \\-H 'Authorization: Bearer 3bxxxxxxxxxxxxxx1a1d' \\-d '{"model": "intfloat/e5-mistral-7b-instruct","input": "用Python实现快速排序算法"}'
预期结果:
常见问题
部署 vllm-service 后日志显示未找到模型?
检查模型是否已下载完成,Pod 状态应为 Completed。如果模型下载的 Pod 还是 Running 状态,请等待下载结束后重启服务。
部署 vllm-service 后日志显示 CudaOutofMemory?
说明 GPU 显存不足,请选用更大显存的 GPU,部署本文模型需单卡 L20 及以上机型。



