操作场景
NVIDIA Multi-Process Service(以下简称 MPS)是 NVIDIA CUDA 提供的多进程 GPU 共享机制,允许多个进程或容器同一时刻在同一块物理 GPU 上并行执行 CUDA Kernel,从而显著提升单卡 GPU 利用率。
腾讯云容器服务 TKE 通过 nvidia-gpu Addon(1.0.5及以上版本) 集成了 NVIDIA 官方 nvidia-device-plugin 的 MPS 能力,您可以一键开启 GPU 共享,无需自行部署 mps-control-daemon、ConfigMap 等组件。
适用业务场景
场景 | 说明 |
AI 推理服务 | 模型 batch 较小、单实例无法占满 GPU 时,多副本共享同卡可显著降本。 |
交互式开发 | Jupyter / VSCode Server 等长时间占卡但低算力消耗的场景。 |
CI/CD 流水线 | 短时编译、单元测试等碎片化 GPU 任务。 |
批处理任务 | Spark / Flink GPU 算子,每个 Executor 算力需求不高。 |
工作原理
整体架构
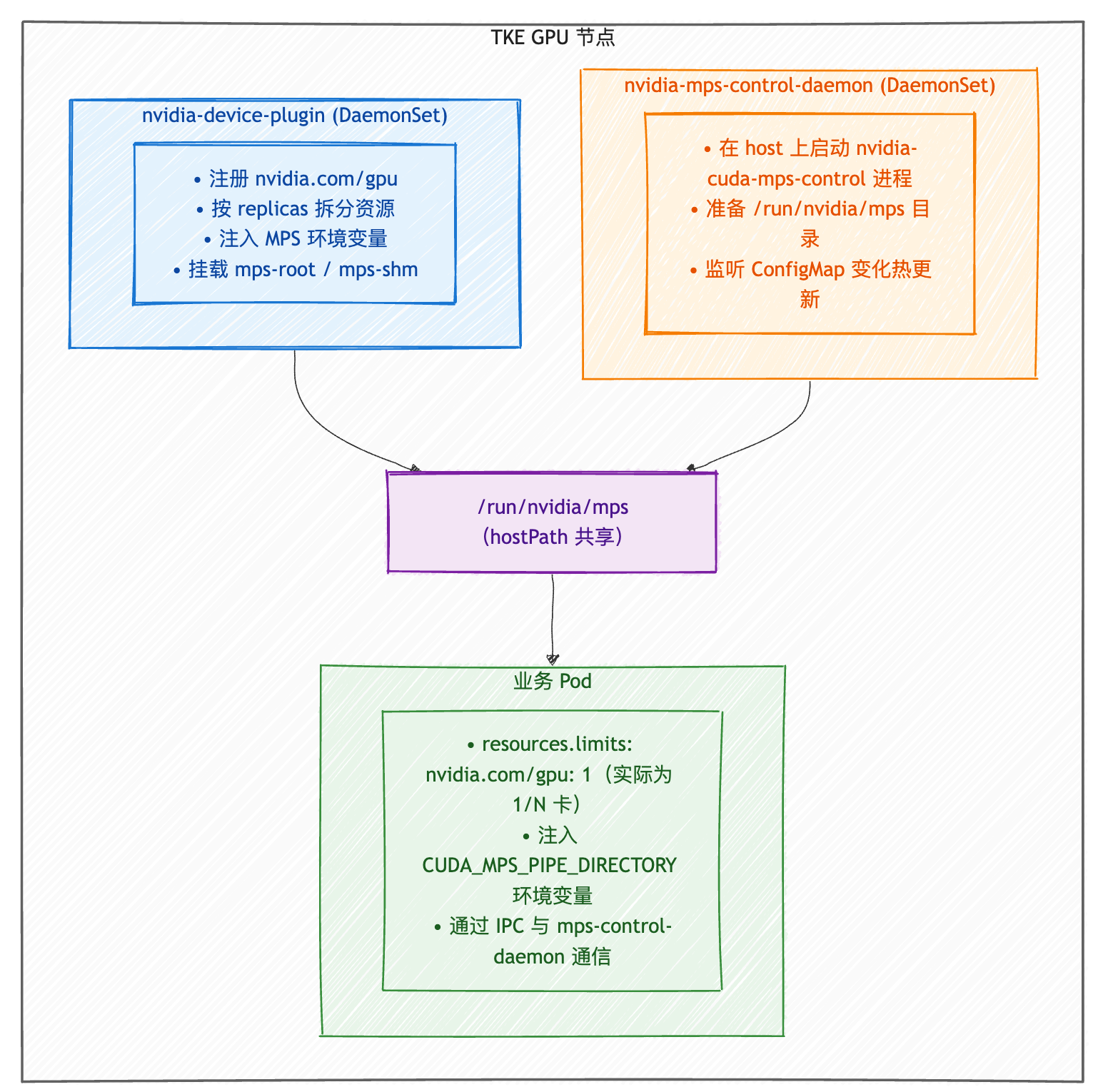
关键组件
组件 | 部署形态 | 职责 |
nvidia-device-plugin-daemonset | DaemonSet | 向 kubelet 注册 GPU 资源;按 ConfigMap 中的 replicas 将 1 张物理卡虚拟为 N 个 nvidia.com/gpu;为业务容器注入 MPS 环境变量与共享卷。 |
nvidia-mps-control-daemon | DaemonSet | 在节点 host 上常驻 MPS 控制进程;准备 /run/nvidia/mps 共享内存目录;按 ConfigMap 配置创建 per-resource 的 pipe/log 目录。 |
nvidia-device-plugin-configs | ConfigMap | 描述 GPU 共享策略;TKE 内置 mps-1x/mps-2x/mps-4x 三种预设。 |
MPS 资源隔离能力
资源 | 控制方式 | 是否硬限制 |
显存 | CUDA_MPS_PINNED_DEVICE_MEM_LIMIT 环境变量。 | Volta+ 硬限制(超限 OOM);Pre-Volta 仅地址空间分区。 |
算力 | CUDA_MPS_ACTIVE_THREAD_PERCENTAGE 环境变量(0–100)。 | 软限制(占比上限)。 |
客户端数 | MPS server 内置上限。 | Volta+ 最多 48;Pre-Volta 最多 16。 |
开启 MPS
版本要求:MPS 依赖 nvidia-gpu 组件版本 ≥ v1.0.5。低于该版本的集群请先在组件管理中将 nvidia-gpu 升级至 v1.0.5 或更高版本。
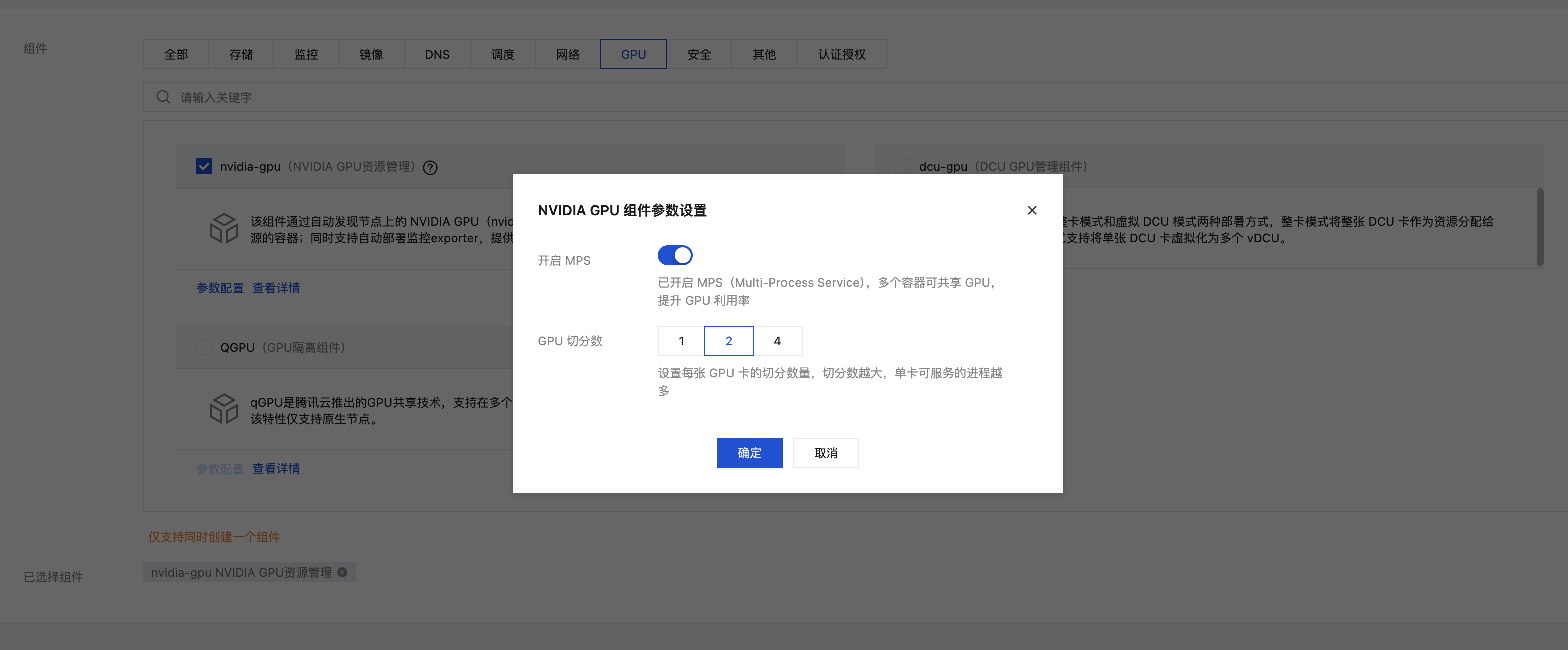
安装时开启
在集群页面左侧,运维中心 > 组件管理中单击新建,选择 nvidia-gpu 组件,单击参数配置,开启 MPS 并选择 GPU 切分数,单击确定。
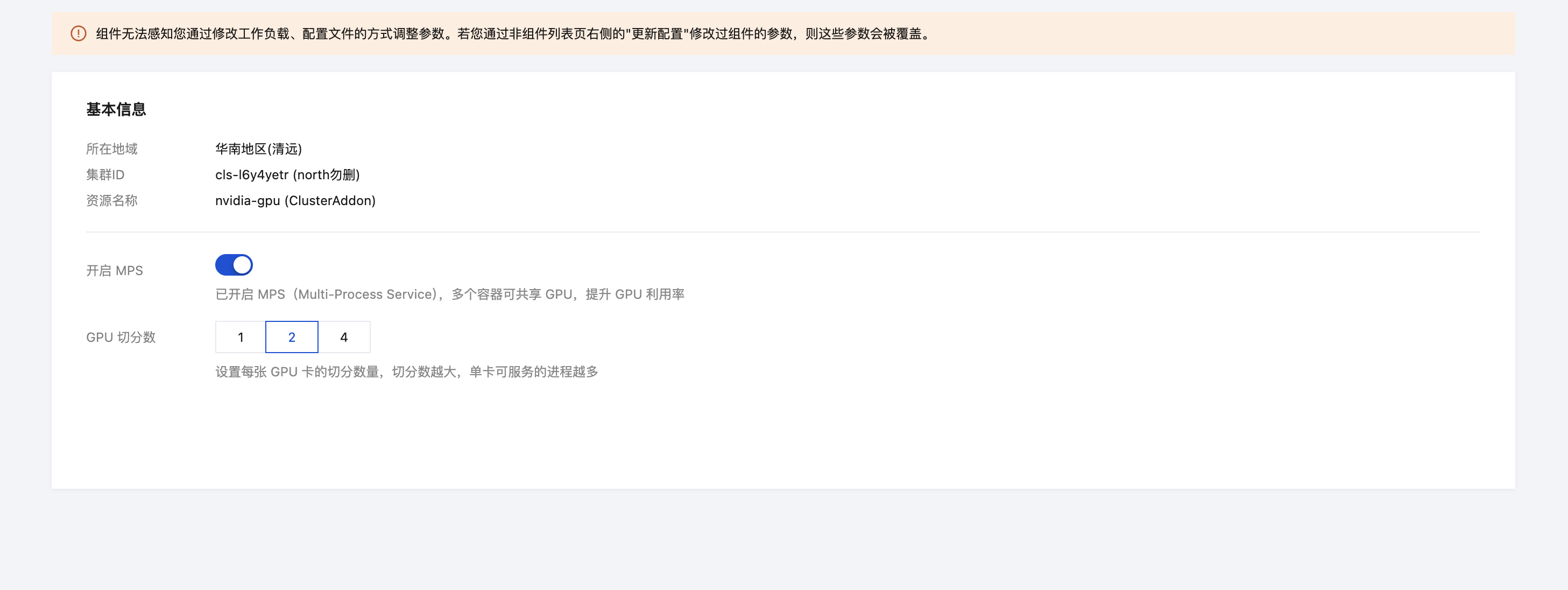
通过更新配置开启
在集群页面左侧,运维中心 > 组件管理中找到 nvidia-gpu 组件,单击更新配置开启 MPS。
节点级别精细化配置
若希望集群中部分节点开启共享、部分节点保持独占,可通过节点标签 nvidia.com/device-plugin.config 选择不同配置:
# 节点 A:独占模式kubectl label node <node-A> nvidia.com/device-plugin.config=mps-1x --overwrite# 节点 B:1 卡分 2 份kubectl label node <node-B> nvidia.com/device-plugin.config=mps-2x --overwrite# 节点 C:1 卡分 4 份kubectl label node <node-C> nvidia.com/device-plugin.config=mps-4x --overwrite# config-manager sidecar 会监听该标签变化并热更新本节点的 device-plugin 配置(无需重启 Pod)。
使用 MPS 共享 GPU
开启 MPS 后,业务 Pod 申请 GPU 的方式不变,只是获得的是逻辑卡而非物理卡。
### 示例 1:基础推理 Pod---apiVersion: v1kind: Podmetadata:name: mps-inference-demospec:containers:- name: cuda-appimage: nvidia/cuda:12.0-basecommand: ["sleep", "infinity"]resources:limits:nvidia.com/gpu: 1 # 申请 1 份 MPS 共享单元(在 mps-2x 配置下 = 1/2 卡)### 示例 2:限制显存与算力### 通过 CUDA 环境变量精细化控制单容器对 GPU 的使用:---apiVersion: v1kind: Podmetadata:name: mps-with-limitsspec:containers:- name: cuda-appimage: nvidia/cuda:12.0-baseresources:limits:nvidia.com/gpu: 1env:- name: CUDA_MPS_PINNED_DEVICE_MEM_LIMITvalue: "4294967296" # 显存硬限制 4GiB(单位:字节,仅 Volta+ 生效)- name: CUDA_MPS_ACTIVE_THREAD_PERCENTAGEvalue: "25" # 算力上限 25%### 示例 3:调度到特定节点配置---apiVersion: v1kind: Podmetadata:name: mps-on-4x-nodespec:nodeSelector:nvidia.com/device-plugin.config: mps-4xcontainers:- name: cuda-appimage: nvidia/cuda:12.0-baseresources:limits:nvidia.com/gpu: 1 # 在 mps-4x 节点上 = 1/4 卡
验证与运维
1. 检查节点 GPU 资源数量
# 在 mps-2x 配置下,1 张物理卡应展示为 2 个 nvidia.com/gpukubectl describe node <gpu-node> | grep -E "nvidia.com/gpu"# 期望输出:# nvidia.com/gpu: 2
2. 检查组件运行状态
# device-plugin DaemonSetkubectl get ds nvidia-device-plugin-daemonset -n kube-system# mps-control-daemon DaemonSetkubectl get ds nvidia-mps-control-daemon -n kube-system# 应有的 Podkubectl get pod -n kube-system -l qcloud-app=nvidia-device-plugin-daemonsetkubectl get pod -n kube-system -l qcloud-app=nvidia-mps-control-daemon
3. 日志排查
# device-plugin 日志kubectl logs -n kube-system <nvidia-device-plugin-daemonset pod> \\-c nvidia-device-plugin-ctr --tail=200# mps-control-daemon 日志kubectl logs -n kube-system <nvidia-mps-control-daemon pod> \\-c mps-control-daemon-ctr --tail=200# config-manager 热更新日志kubectl logs -n kube-system -l qcloud-app=nvidia-device-plugin-daemonset \\-c config-manager-sidecar --tail=200
常见问题
Q1:开启 MPS 后节点 GPU 资源数量没变?
1. 确认 mps.default 不是 mps-1x(mps-1x 即独占模式)。
2. 确认节点没有 nvidia.com/device-plugin.config 标签覆盖到 mps-1x。
3. 查看 config-manager-sidecar 日志确认 ConfigMap 已正确加载。
Q2:业务 Pod 报 CUDA_ERROR_OUT_OF_MEMORY?
多容器同时跑可能导致显存超额。请按 业务实际显存需求 × 副本数 ≤ 物理显存 规划。在 Volta+ GPU 上设置 CUDA_MPS_PINNED_DEVICE_MEM_LIMIT 加硬限制。
Q3:MPS 与 qGPU 能否同时使用?
不能。MPS 由 NVIDIA 上游 device-plugin 提供,qGPU 由腾讯云 elastic-gpu-agent 提供,两者各自管理 GPU 资源命名空间,节点维度互斥。
注意事项与限制
1. 架构限制:MPS 显存硬隔离仅在 Volta(V100、Tesla T4)及更新架构上可用。
2. 客户端上限:单 GPU MPS 同时连接客户端 ≤ 48(Volta+)或 ≤ 16(Pre-Volta)。
3. MIG 互斥:节点开启 MIG 时不能再用 MPS;同 GPU 上仅能选一种切分方案。
4. 错误传播:MPS 客户端的 GPU fatal error 可能波及其他客户端(弱错误隔离)。如对错误隔离要求高,请使用 MIG 或 qGPU。
5. 共享内存依赖:MPS 通过 /dev/shm 进行 IPC,业务 Pod 在某些场景下可能需要 hostIPC: true(典型如自实现 MPS client 的应用);多数 CUDA 应用走 device-plugin 自动注入的 pipe 目录即可。
相关文档
qGPU 概述



