概述
传统的对象管理页面一般都是通过列表形式展开的,例如 TKE 集群里现有的资源对象列表,但列表的展示方式具备如下缺点:每一行都是一些抽象的数字,可读性不高;对象之间没有明确的标识区分;无法支持某种形态的排序。为此,腾讯云容器服务的 TKE Insight 的能力,通过可视化的形式,将用户所有的资源对象进行展示。该模块具备丰富的过滤查询、类型聚合、状态展示能力,可以帮助用户快速定位目标对象。
Workload Map 主要通过可视化的页面展示工作负载的各项状态和指标,帮助用户了解当前工作负载的配置量和实际使用情况,辅助用户分析工作负载可能存在的问题。
注意事项
Workload Map 不支持提供超级节点上的 Pod 推荐值的监控数据。在聚合监控指标时,如果有 Workload 的 Pod 在超级节点上,则在统计 Workload 和 Cluster 级别的推荐值时,会缺少部分数据。
使用方式
1. 登录 容器服务控制台。
2. 在左侧选择 TKE Insight > Workload Map。
3. 在 Workload Map 页面中,选择地域、集群类型和集群后,进行查看。
4. 右上角可选24小时、7天和30天数据,如下图所示:

Workload Map 功能说明
Workload Map 分为概览和资源对象热图,如下图所示:
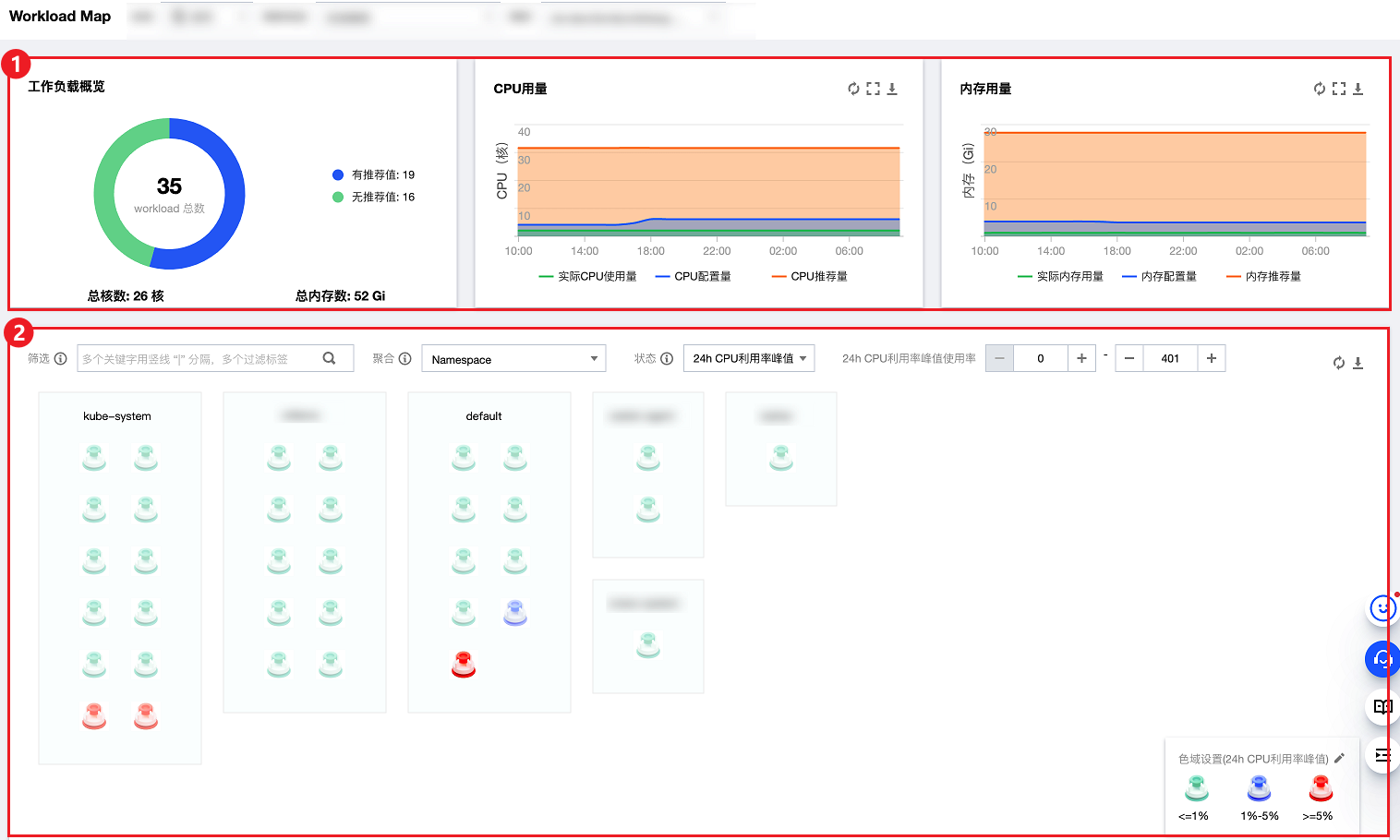
1. 上半区域是集群里的 Workload 概览。
2. 下半区域是集群里的每一个 Workload 资源对象。
工作负载概览
工作负载概览如下图所示:

工作负载概览:展示当前集群中是有推荐 Request 的工作负载的数量和所占比例;展示当前集群节点的总核数和总内存数。
注意:
CPU 用量:集群中工作负载的 CPU 用量情况。(统计了集群中原生节点、普通节点、注册节点上 Pod 的用量;只有均值)
配置量:集群中所有工作负载中所有 Pod 的 Request 的 CPU 之和。
实际用量:集群中所有工作负载中所有 Pod 实际的 CPU 用量之和。
推荐量:集群中所有工作负载中所有 Pod 推荐的 CPU 用量之和。需要提前开启 Request 推荐。
内存用量:集群中工作负载的内存用量情况。(统计了集群中原生节点、普通节点、注册节点上 Pod 的用量;只有均值)
配置量:集群中所有工作负载中所有 Pod 的 Request 的内存之和。
实际用量:集群中所有工作负载中所有 Pod 实际的内存用量之和。
推荐量:集群中所有工作负载中所有 Pod 推荐的内存用量之和。需要提前开启 Request 推荐。
工作负载对象查看和操作
默认展示热力图示图,单击右上角切换列表可展示列表视图:

列表视图里,单击切换图示可切换热力图视图:

热力图视图
工作负载对象查看
工作负载对象如下图所示,您可以通过工作负载的筛选、聚合、状态进行 Workload 的过滤和聚合展示。(此处统计了集群中所有节点上的工作负载,包含了原生节点、普通节点、注册节点、超级节点。)
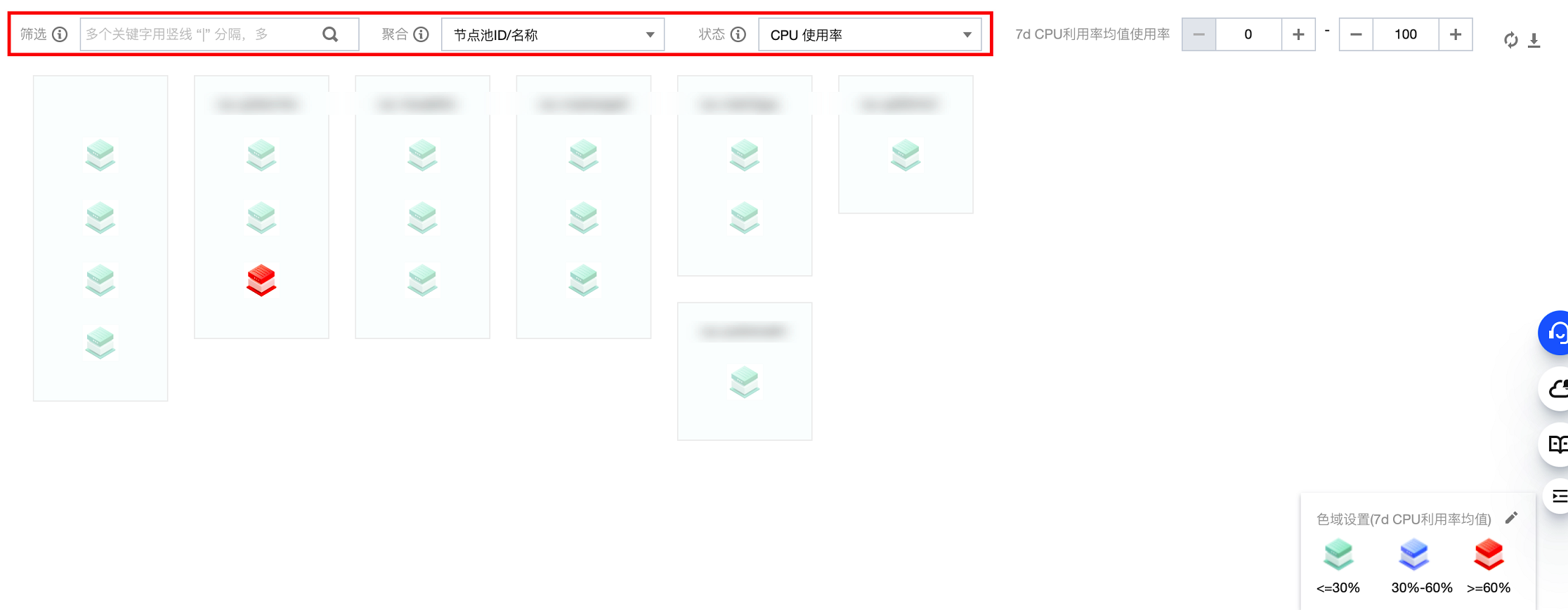
筛选:根据相关指标筛选得到目标 Workload,若您不选择,则是默认选择了所有的 Workload。支持过滤多个属性,取交集。
聚合:对筛选出来的 Workload 进行分组,每一组节点在同一个浅色框内,一个框内的每个 Workload 具有相同的属性值。
状态:您可以通过状态进行筛选,支持选择 CPU 使用率和内存使用率。
CPU 使用率:Workload CPU 利用率(CPU 实际使用量/配置Request用量)均值,根据页面右上角选择,分24小时、7天、30天数据。
内存 使用率:Workload 内存 利用率(内存 实际使用量/配置Request用量)均值,根据页面右上角选择,分24小时、7天、30天数据。
注意:
在工作负载对象热图里的节点,默认按照当前选择的“状态”属性值进行升序排列。例如,您选择的工作负载状态是 “CPU 使用率”,则工作负载对象热图里的工作负载默认是按照工作负载CPU 利用率均值升序排列。
筛选后的 Workload 由绿、蓝、红三色区分。您可以单击页面右下角的

下载:您可以单击工作负载概览右侧的下载标识
下载列表的字段说明:
名称:工作负载的名称
命名空间:工作负载所属的命名空间
工作负载类型:工作负载所属的 K8s 类型
24h CPU 利用率均值:工作负载近24小时 CPU 利用率的均值。单位:%
7d CPU 利用率均值:工作负载近7天 CPU 利用率的均值。单位:%
30d CPU 利用率均值:工作负载近30天 CPU 利用率的均值。单位:%
24h CPU 利用率峰值:工作负载近24小时 CPU 利用率的峰值。单位:%
7d CPU 利用率峰值:工作负载近7天 CPU 利用率的峰值。单位:%
30d CPU 利用率峰值:工作负载近30天 CPU 利用率的峰值。单位:%
24h 内存利用率均值:工作负载近24小时内存利用率的均值。单位:%
7d 内存利用率均值:工作负载近7天内存利用率的均值。单位:%
30d 内存利用率均值:工作负载近30天内存利用率的均值。单位:%
24h 内存利用率峰值:工作负载近24小时内存利用率的峰值。单位:%
7d 内存利用率峰值:工作负载近7天内存利用率的峰值。单位:%
30d 内存利用率峰值:工作负载近30天内存利用率的峰值。单位:%
工作负载操作
当您的鼠标悬浮在工作负载对象上后,您可以查看当前工作负载的详情信息,并进行如下操作:
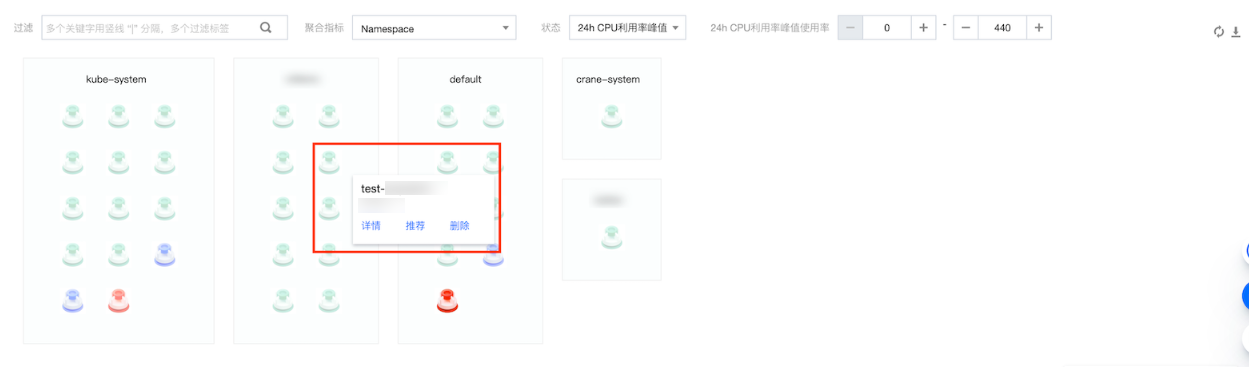
1. 单击详情,查看当前工作负载的详情信息。
功能开关
Request 推荐:集群级别的功能开关。开启后,可以根据 Workload 的使用情况,给 Workload 推荐合适的 Request。详情请参见 Request 推荐。
推荐值(蓝色字体):标识当前工作负载的 Request 推荐值,单击后支持更新(仅在开启 Request 推荐且有推荐值的情况下展示)。
工作负载信息
24h 利用率均值:工作负载 CPU 和内存24小时均值利用率。
24h 利用率峰值:工作负载 CPU 和内存24小时峰值利用率。
工作负载走势图信息
CPU 用量:当前工作负载的 CPU 用量情况。
申请量:当前工作负载中所有 Pod 的 Request 的 CPU 数值之和。
实际用量:当前工作负载中所有 Pod 实际的 CPU 用量之和。
推荐量:当前工作负载中所有 Pod 推荐的 CPU 用量之和。需要提前开启 Request 推荐。
内存用量:当前工作负载的内存用量情况。
申请量:当前工作负载中所有 Pod 的 Request 的内存数值之和。
实际用量:当前工作负载中所有 Pod 实际的内存用量之和。
推荐量:当前工作负载中所有 Pod 推荐的内存用量之和。需要提前开启 Request 推荐。
CPU 用量走势图
申请量:Pod 的 Request 数值。
实际用量:Pod 实际的用量。
推荐量:Pod 推荐的用量。
Pod 详情
Pod 名称:Pod 的名字。
Pod 状态:Pod 的状态。
所在节点:当前 Pod 所属的节点。
节点类型:当前 Pod 所属节点的节点类型。
2. 单击推荐,展示当前工作负载的 Request 推荐值(仅开启 Request 推荐且有推荐值的情况下,支持单击)。
3. 单击删除,将删除该工作负载。
列表示图
以列表展示某一类型的 Workload 在某些 namespace 下的详情信息:

1. 单击下载,下载列表展示的 csv 格式数据。
2. 单击名称,展示该 Workload 的详情信息。
3. 单击推荐资源量,可按照推荐资源量更新 Workload 的 Request 配置。
4. 针对工作负载副本数为0、首次运行时间不超过24小时情况,资源推荐量可能为空,更多信息可参见 Request 智能推荐。



