Service 提供公网或内网服务无法访问
提供公网服务或者内网服务的 Service,如果出现无法访问或者 CLB 端口状态异常的情况,建议您进行如下检查:
1. 参考 查看节点安全组配置 检查集群中节点的安全组是否正确放通30000-32768端口区间。
2. 如果是公网服务,则进一步检查节点是否有公网带宽(仅针对 传统账户类型)。
3. 如果 Service 的 type 为 LoadBalancer 类型,可忽略 CLB,直接检查 NodeIP + NodePort 是否可以访问。
4. 检查 Service 是否可以在集群中正常访问。
Ingress 提供公网服务无法访问
提供公网服务的 Ingress 如果出现无法访问的情况,建议您进行如下检查:
1. 若请求返回504,请参考 查看节点安全组配置 检查集群中节点的安全组是否正确放通30000-32768端口区间。
2. 检查 Ingress 绑定的 CLB 是否设置了未放通443端口的安全组。
3. 检查 Ingress 后端服务 Service 是否可以在集群中正常访问。
4. 若请求返回404,请检查 Ingress 转发规则是否正确设置。
集群内 Service 无法访问
在 TKE 集群内,Pod 之间一般是通过 Service 的 DNS 名称
my-svc.my-namespace.svc.cluster.local 来进行互访,如果在 Pod 内发生 Service 无法访问的情况,建议您进行如下检查:1. 检查 Service 的
spec.ports 字段是否正确。2. 测试 Service 的 ClusterIP 是否可通。若可通,则说明集群内 DNS 解析存在问题,可参考 集群 DNS 解析异常排障处理 进一步检查。
3. 测试 Service 的 Endpoint 是否可通。若不通,可参考 集群中不同节点上的容器(Pod)无法互访 进一步检查。
4. 检查当前 Pod 所在节点上的 iptables 或者 ipvs 转发规则是否完整。
因 CLB 回环现象导致服务访问不通或访问 Ingress 存在延时
背景信息
为了使集群内的业务通过 CLB 访问 LoadBalancer 类型的 Service 时链路更短,性能更好,社区版本的 kube-proxy 在 IPVS 模式下会将 CLB IP 绑定到本地 dummy 网卡,使得该流量在节点发生短路,不再经过 CLB,直接在本地转发到 Endpoint。但这种优化行为和腾讯云 CLB 的健康检查机制会产生冲突,下面将做具体分析,并给出对应解法。同样,用户使用容器服务 TKE 时,会遇到因 CLB 回环问题导致服务访问不通或访问 Ingress 存在几秒延时的现象。
现象描述
CLB 回环问题可能导致存在以下现象:
iptables 或 IPVS 模式下,访问本集群内网 Ingress 会出现4秒延时或不通。
IPVS 模式下,集群内访问本集群 LoadBalancer 类型的内网 Service 出现完全不通,或者连通不稳定。
规避方法
解决使用 Service 时可能遇到的回环问题,步骤如下:
1. 检查 kube-proxy 的版本是否是最新版本,如果不是请参照如下步骤升级:
1.1 解决该问题需要 kube-proxy 支持把 LB 地址绑定到 IPVS 网卡,可以在 TKE Kubernetes Revision 版本历史 里找到支持该能力的版本号,例如:v1.24.4-tke.6、v1.22.5-tke.13、v1.20.6-tke.12、v1.18.4-tke.20、v1.16.3-tke.25、v1.14.3-tke.24、v1.12.4-tke.30。后续更高的版本默认包含该能力:
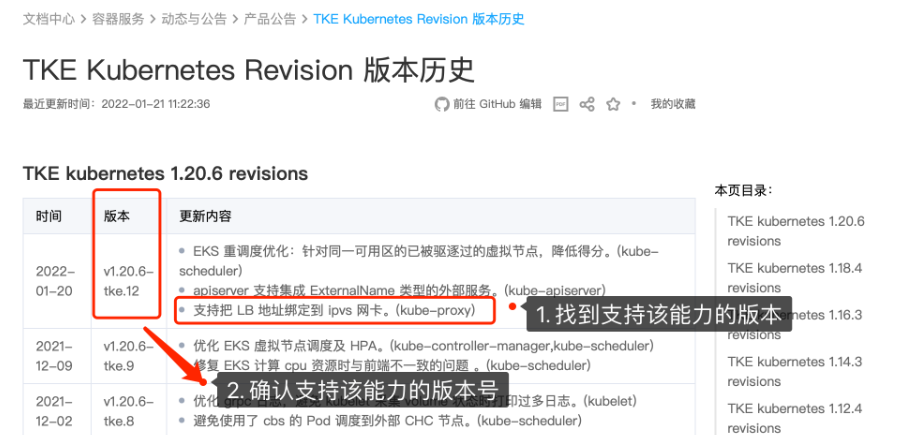
1.2 确定集群的版本:您可以登录 容器服务控制台,在集群的基本信息页查看到当前集群的版本号,如下图所示的集群是1.22.5的版本:

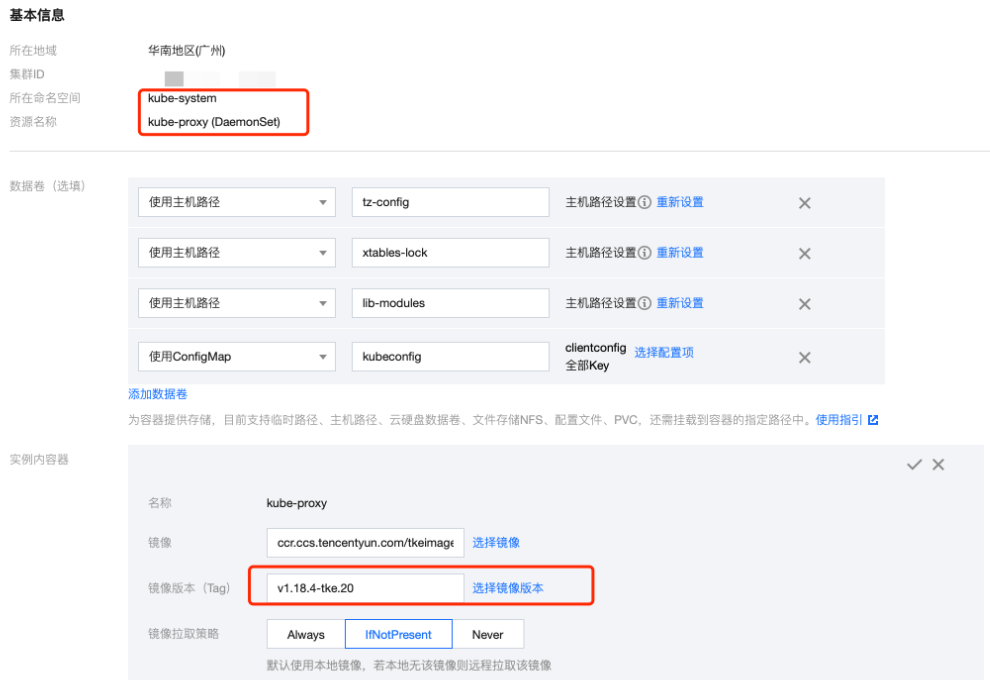
1.3 找到 kube-system 命名空间下面名为 kube-proxy 的 DaemonSet,更新其镜像的版本号,选择支持该能力的版本号,或者大于该版本号的版本。例如,1.18 版本的集群要选择的镜像版本号要大于 v1.18.4-tke.20。如下图所示:
2. 为所有的 Service 添加注解:
service.cloud.tencent.com/prevent-loopback: "true"
效果如下:kube-proxy 将据此信息将 CLB VIP 绑定到本地,可解决回环问题。
service-controller 将调用 CLB 接口,将其健康探测 IP 改为 100.64 网段 IP,可解决健康检查问题。
解决使用 Ingress 时可能遇到的回环问题,步骤如下:
1. 提交工单 申请开通 CLB 7层 SNAT 和 Keep Alive 能力的白名单。
注意:
该能力将启用长连接,CLB 与后端服务之间使用长连接,CLB 不再透传源 IP,请从 XFF 中获取源 IP。为保证正常转发,请在 CLB 上打开安全组默认放通或者在 CVM 的安全组上放通 100.127.0.0/16。更多请参考 配置监听器。
2. 利用 TkeServiceConfig 的能力增强 Ingress 的配置能力,对于存量的 Ingress,需要添加一个 annotation:
ingress.cloud.tencent.com/tke-service-config-auto: "true",详情见 Ingress Annotation 说明。目的:为该 Ingress 自动生成对应的 TkeServiceConfig,提供 Ingress 额外的配置。
效果:该 Ingress 会生成一个名为:<IngressName>-auto-ingress-config 的 TkeServiceConfig 类型资源。
3. 在生成名为:<IngressName>-auto-ingress-config 的 TkeServiceConfig 里面添加一个字段,字段名为 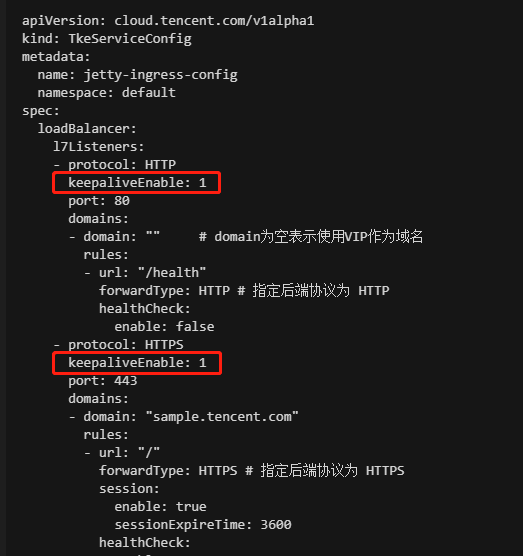
spec.loadBalancer.l7Listeners[].keepaliveEnable,字段值为1。注意每一个端口都需要添加该字段,如下图所示:
问题原因
问题根本原因在于 CLB 将请求转发到后端 RS 时,报文的源目的 IP 都在同一节点内,而 Linux 默认忽略收到源 IP 是本机 IP 的报文,导致数据包在子机内部回环,如下图所示:
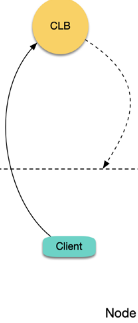
使用 TKE CLB 类型的 Ingress,会为每个 Ingress 资源创建一个 CLB 以及80、443的7层监听器规则(HTTP/HTTPS),并为 Ingress 每个 location 绑定对应 TKE 各个节点某个相同的 NodePort 作为 RS(每个 location 对应一个 Service,每个 Service 都通过各个节点的某个相同 NodePort 暴露流量),CLB 根据请求匹配 location 转发到相应的 RS(即 NodePort),流量经过 NodePort 后会再经过 Kubernetes 的 iptables 或 ipvs 转发给对应的后端 Pod。集群中的 Pod 访问本集群的内网 Ingress,CLB 将请求转发给其中一台节点的对应 NodePort:
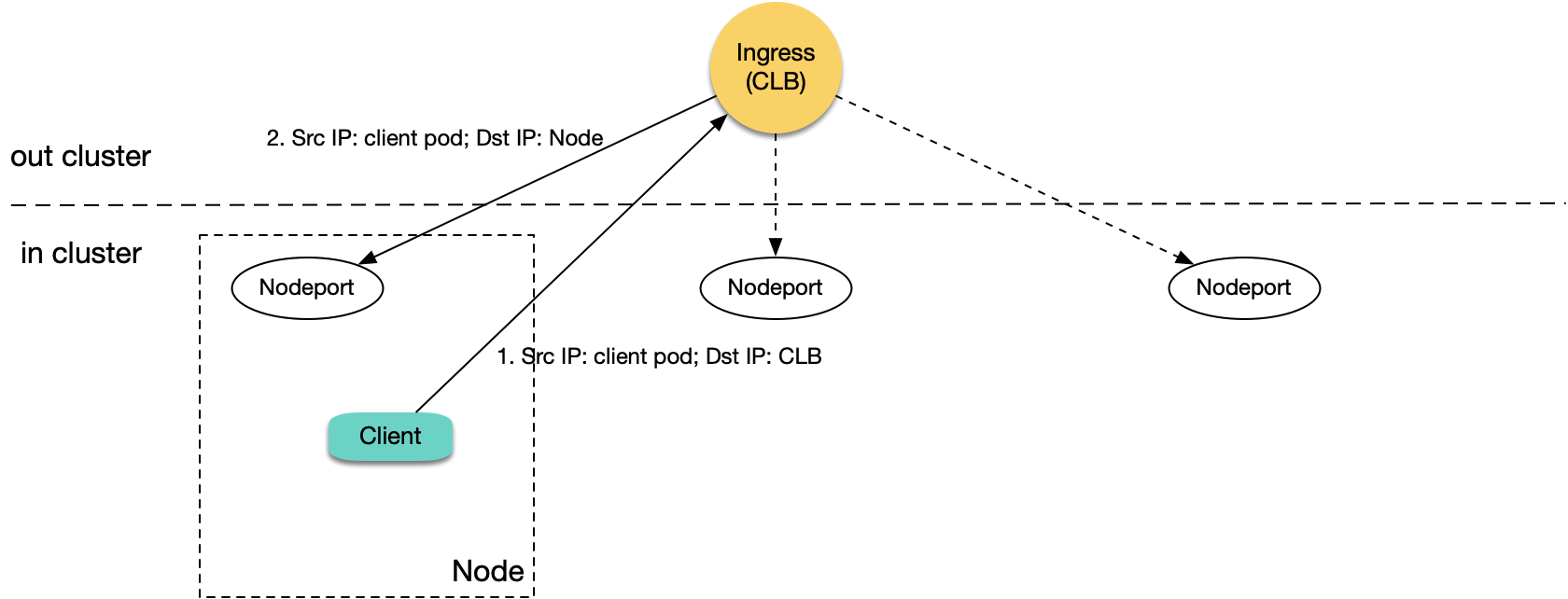
如上图,当被转发的这台节点恰好也是发请求的 Client 所在节点时:
1. 集群中的 Pod 访问 CLB,CLB 将请求转发到任意一台节点的对应 NodePort。
2. 报文到达 NodePort 时,目的 IP 是节点 IP,源 IP 是 Client Pod 的真实 IP, 因为 CLB 不进行 SNAT,会将真实源 IP 透传过去。
3. 由于源 IP 与目的 IP 都在这台机器内,因此将导致回环,CLB 将收不到来自 RS 的响应。
访问集群内 Ingress 的故障现象大多为几秒延时,原因是7层 CLB 如果请求 RS 后端超时(大概4s),会重试下一个 RS,所以如果 Client 设置的超时时间较长,出现回环问题的现象就是请求响应慢,有几秒的延时。如果集群只有一个节点,CLB 没有可以重试的 RS,则现象为访问不通。
当使用 LoadBalancer 类型的内网 Service 暴露服务时,会创建内网 CLB 并创建对应的4层监听器(TCP/UDP)。当集群内 Pod 访问 LoadBalancer 类型 Service 的 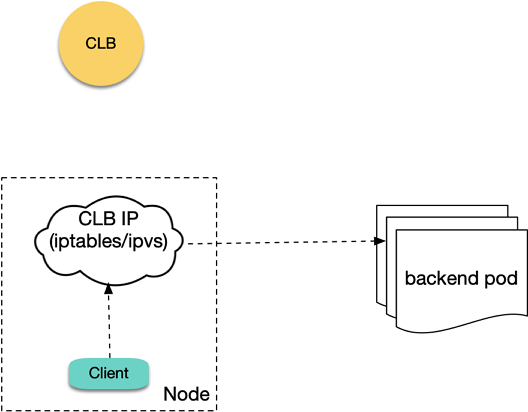
EXTERNAL-IP 时(即 CLB IP),原生 Kubernetes 实际上不会去真正访问 LB,而是直接通过 iptables 或 ipvs 转发到后端 Pod (不经过 CLB),如下图所示:
因此原生 Kubernetes 的逻辑不存在回环问题。但在 TKE 的 ipvs 模式下,Client 访问 CLB IP 的包会真正到 CLB,如果在 ipvs 模式下,Pod 访问本集群 LoadBalancer 类型 Service 的 CLB IP 将存在回环问题,情况跟上述内网 Ingress 回环类似,如下图所示:
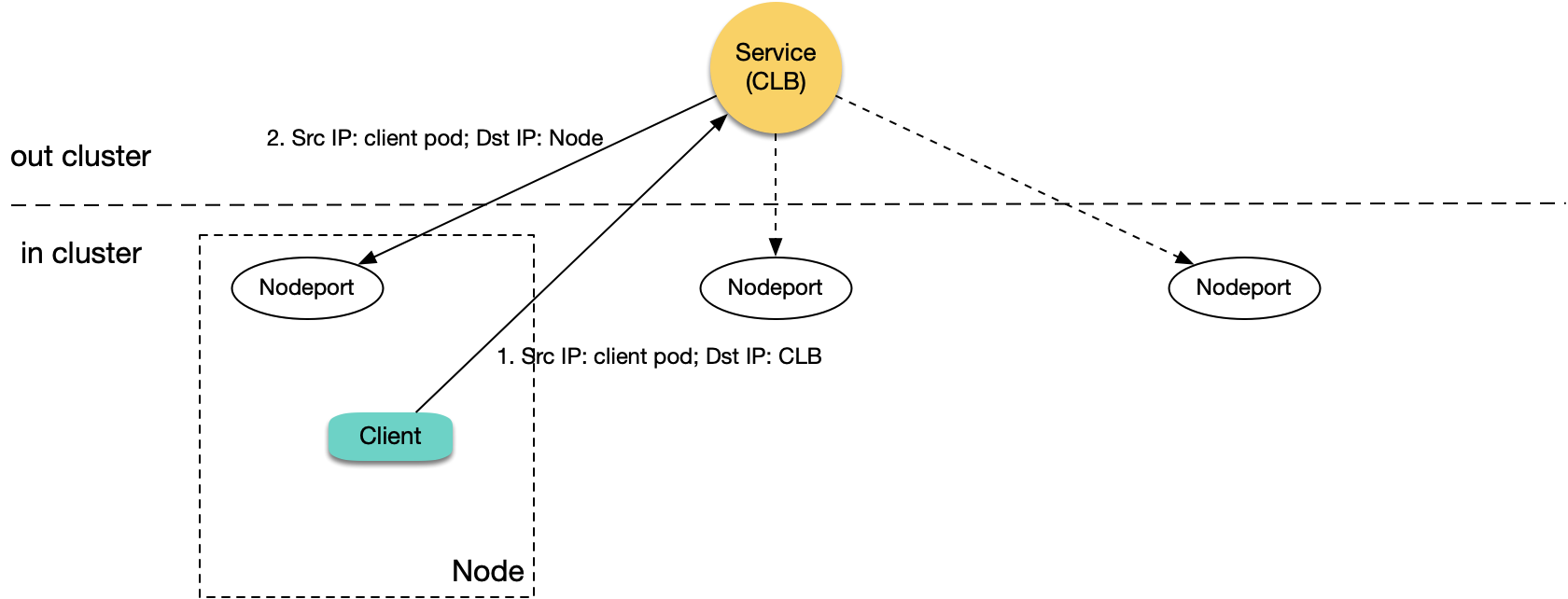
不同的是,四层 CLB 不会重试下一个 RS,当遇到回环时,现象通常是连通不稳定。如果集群只有一个节点,那将导致完全不通。
为什么 TKE 的 ipvs 模式不用原生 Kubernetes 类似的转发逻辑(不经过 LB,直接转发到后端 Pod)?
背景是因为以前 TKE 的 ipvs 模式集群使用 LoadBalancer 内网 Service 暴露服务,内网 CLB 对后端 NodePort 的健康探测会全部失败,原因如下:
ipvs 主要工作在 INPUT 链,需要将要转发的 VIP(Service 的 Cluster IP 和 EXTERNAL-IP)当成本机 IP,才好让报文进入 INPUT 链交给 ipvs 处理。
kube-proxy 的做法是将 Cluster IP 和 EXTERNAL-IP 都绑到名称为
kube-ipvs0 的 dummy 网卡,该网卡仅仅用来绑定 VIP (内核自动为其生成 local 路由),不用于接收流量。内网 CLB 对 NodePort 的探测报文源 IP 是 CLB 自身的 VIP,目的 IP 是 Node IP。当探测报文到达节点时,节点发现源 IP 为本机 IP (因为其被绑定到了
kube-ipvs0),就将其丢弃掉。所以 CLB 的探测报文永远无法收到响应,也就全部探测失败,虽然 CLB 有全死全活逻辑(全部探测失败视为全部可以被转发),但也相当于探测未起到任何作用,在某些情况下将造成一些异常。为解决上述问题,TKE 的修复策略是:ipvs 模式不绑定 EXTERNAL-IP 到
kube-ipvs0 。也就是集群内 Pod 访问 CLB IP 的报文不会进入 INPUT 链,而是直接出节点网卡,真正到达 CLB,这样健康探测的报文进入节点时将不会被当成本机 IP 而丢弃,同时探测响应报文也不会进入 INPUT 链导致出不去。虽然这种方法修复了 CLB 健康探测失败的问题,但也导致集群内 Pod 访问 CLB 的包真正到了 CLB,由于访问集群内的服务,报文又会被转发回其中一台节点,也就存在了回环的可能性。
说明:
常见问题
为什么公网 CLB 不存在回环问题?
使用公网 Ingress 和 LoadBalancer 类型公网 Service 不存在回环问题,主要是公网 CLB 收到的报文源 IP 是子机的出口公网 IP,而子机内部无法感知自己的公网 IP,当报文转发回子机时,不认为公网源 IP 是本机 IP,也就不存在回环。
CLB 是否有避免回环机制?
有。CLB 会判断源 IP,如果发现后端 RS 也有相同 IP,就不考虑转发给这个 RS,而是选择其他 RS。但是源 Pod IP 跟后端 RS IP 并不相同,CLB 也不知道这两个 IP 是在同一节点,所以同样可能会转发过去,也就可能发生回环。
Client 与 Server 反亲和部署能否规避?
如果将 Client 与 Server 通过反亲和性部署,避免 Client 跟 Server 部署在同一节点,能否规避 CLB 回环问题?
默认情况下,LB 通过节点 NodePort 绑定 RS,可能转发给任意节点 NodePort,此时 Client 与 Server 是否在同一节点都可能发生回环。但如果为 Service 设置
externalTrafficPolicy: Local, LB 就只会转发到有 Server Pod 的节点,如果 Client 与 Server 通过反亲和调度在不同节点,则此时不会发生回环,所以反亲和 + externalTrafficPolicy: Local 可以规避回环问题(包括内网 Ingress 和 LoadBalancer 类型内网 Service)。VPC-CNI 的 LB 直通 Pod 是否也存在 CLB 回环问题?
TKE 通常用的 Global Router 网络模式(网桥方案),还有一种是 VPC-CNI(弹性网卡方案)。目前 LB 直通 Pod 只支持 VPC-CNI 的 Pod,即 LB 不绑 NodePort 作为 RS,而是直接绑定后端 Pod 作为 RS,如下图所示:
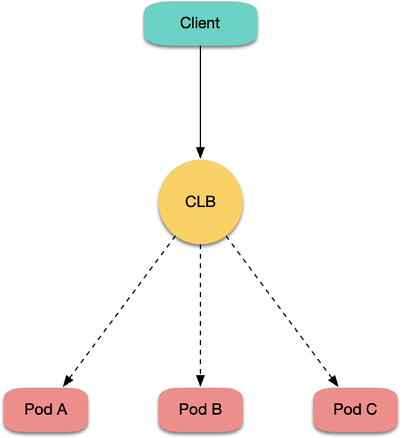
这样即可绕过 NodePort,不再像之前一样可能会转发给任意节点。但如果 Client 与 Server 在同一节点,同样可能会发生回环问题,通过反亲和可以规避。
有什么建议?
反亲和与
externalTrafficPolicy: Local 的规避方式不太优雅。一般来讲,访问集群内的服务避免访问本集群的 CLB,因为服务本身在集群内部,从 CLB 绕一圈不仅会增加网络链路的长度,还会引发回环问题。访问集群内服务尽量使用 Service 名称,例如
server.prod.svc.cluster.local ,通过这样的配置将不会经过 CLB,也不会导致回环问题。如果业务有耦合域名,不能使用 Service 名称,可以使用 coredns 的 rewrite 插件,将域名指向集群内的 Service,coredns 配置示例如下:
apiVersion: v1kind: ConfigMapmetadata:name: corednsnamespace: kube-systemdata:Corefile: |2-.:53 {rewrite name roc.example.com server.prod.svc.cluster.local...
如果多个 Service 共用一个域名,可以自行部署 Ingress Controller (例如 nginx-ingress):
1. 用上述 rewrite 的方法将域名指向自建的 Ingress Controller。
2. 将自建的 Ingress 根据请求 location (域名+路径) 匹配 Service,再转发给后端 Pod。整段链路不经过 CLB,同样能规避回环问题。



