本文介绍如何在 Agent 执行引擎部署浏览器沙箱应用,提供安全、隔离的浏览器环境,让您能够与 Web 应用程序交互,同时最大限度地降低系统的潜在风险。它在 AI 运行时容器化环境中运行,并将 Web 活动与您的本地系统隔离。
说明:
该功能处于内测阶段,如需使用,请提交 内测申请。
该功能目前仅支持在香港地域使用。
浏览器沙箱应用镜像来源于社区开源软件镜像 steel-browser,本平台不参与维护。若您使用此镜像:
您有义务遵守相应的第三方规则,包括但不限于任何可能附随的开源软件许可协议。
在用于生产环境之前,您应当进行充分的验证和测试,并主动修复可能存在的缺陷。
如果使用过程中对 steel-browser 项目有更多需求,需要提交 issue 由社区支持 GitHub · Where software is built。
前置依赖
服务授权(如果您已授权,请跳过该步骤)
您需要为 Serverless Framework、CODING DevOps、云函数创建服务角色并授权。具体操作如下:
为预设策略授权:按界面提示,单击“同意授权”:

为非预设策略授权:
1.1 单击“前往关联”为角色绑定策略。
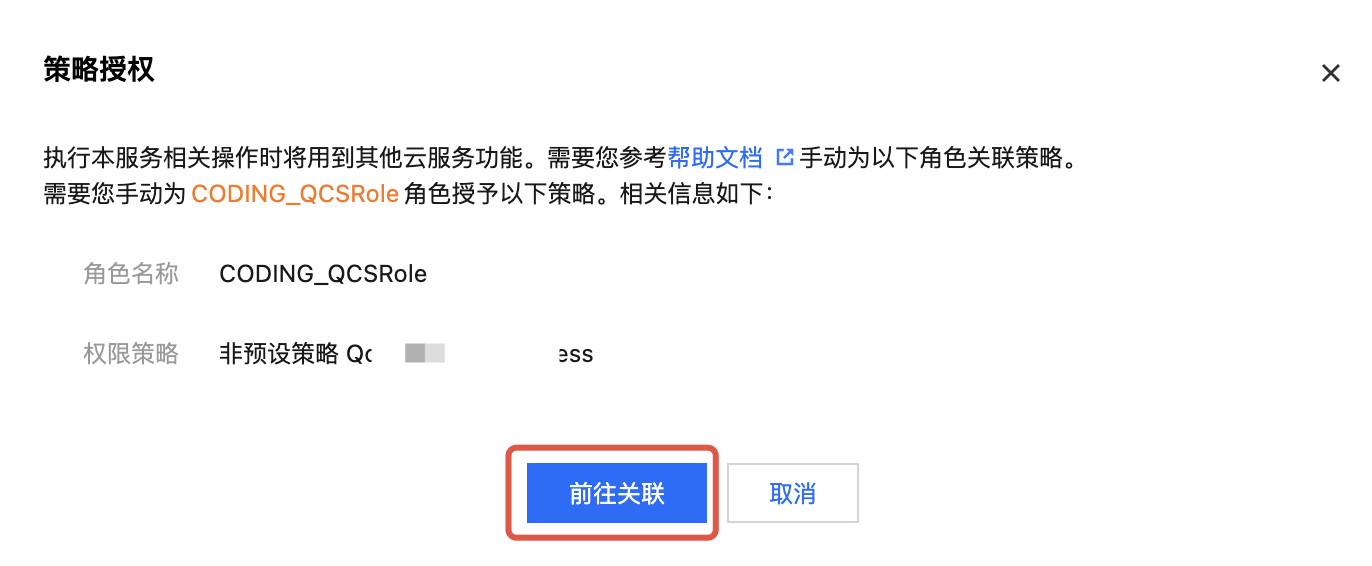
1.2 进入访问管理 > 角色控制台,单击对应的角色名称 CODING_QCSRole。
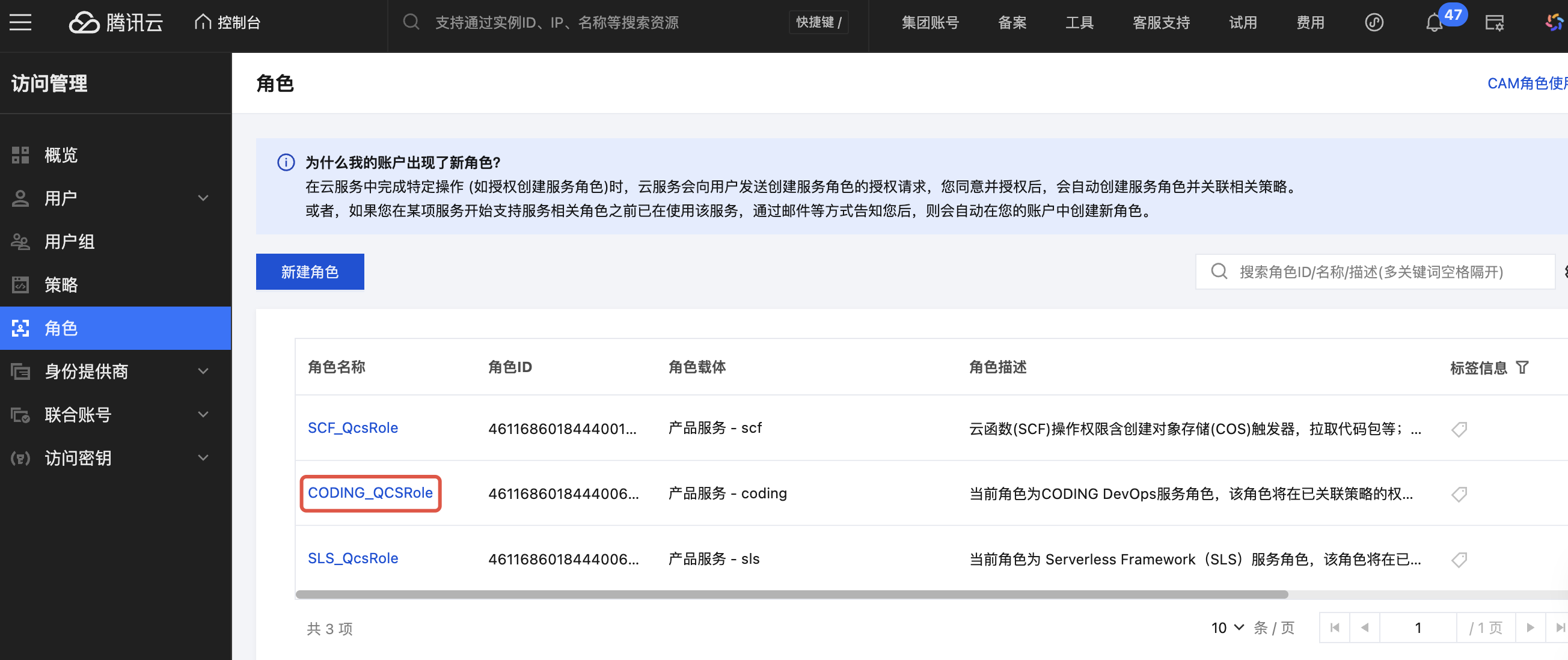
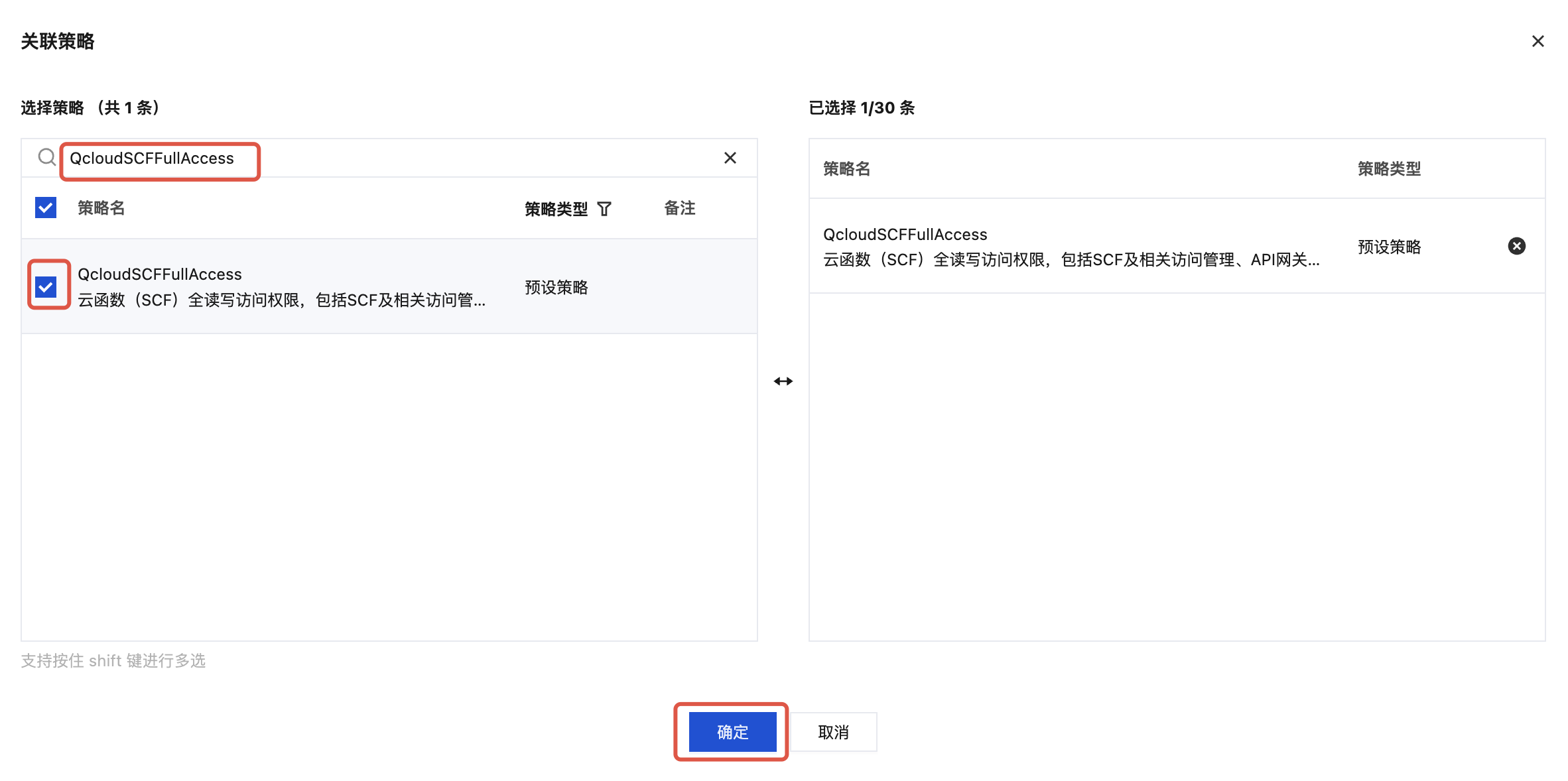
1.3 单击关联策略,搜索并选择策略 “QcloudSCFFullAccess”。
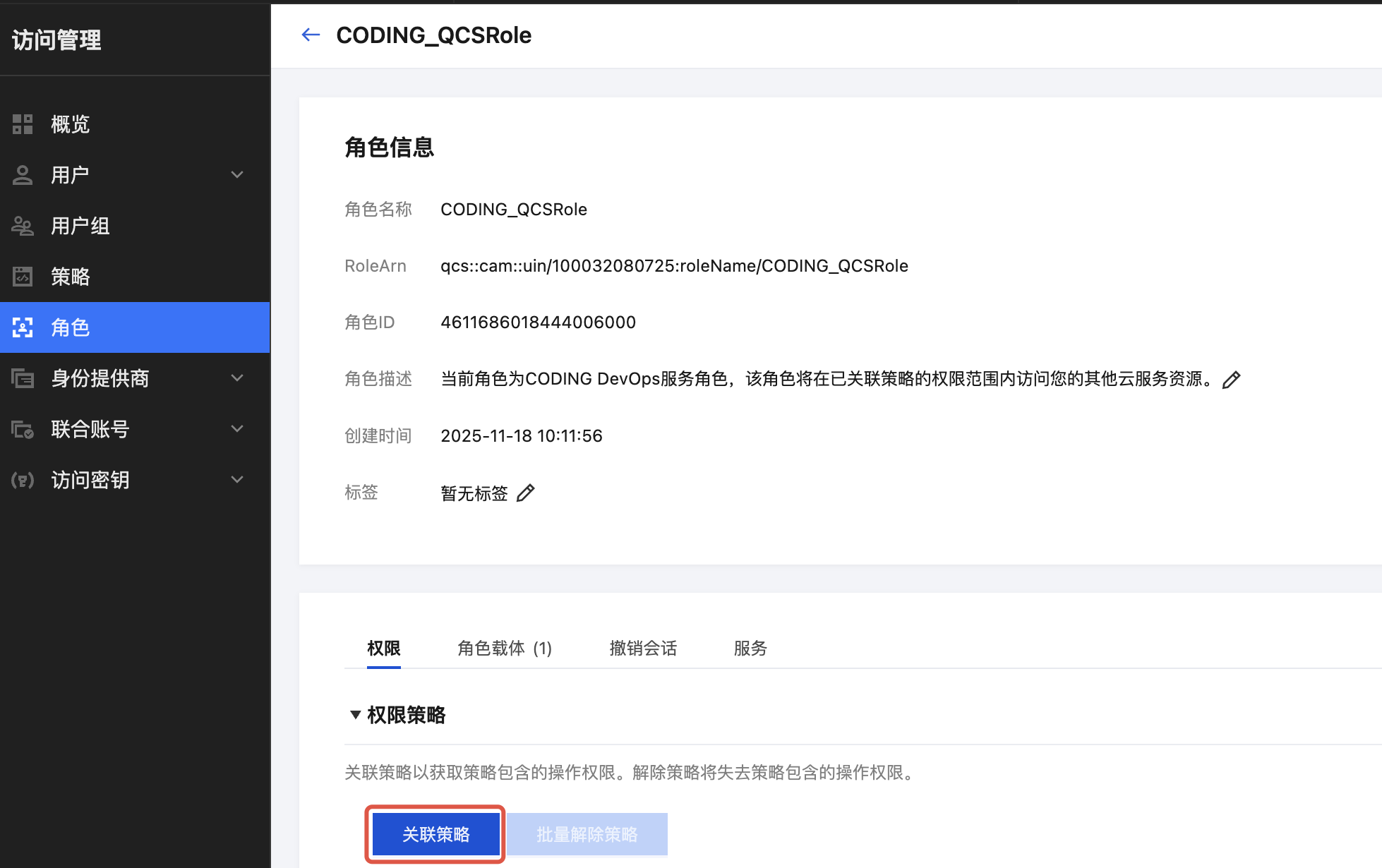
1.4 单击确定完成策略绑定。
容器镜像准备
如果您通过容器镜像部署,您需要先准备好 WebServer 类型的容器镜像,并上传到容器镜像仓库。
1.1 镜像要求:需要搭建 HTTP Server,监听 0.0.0.0:9000 或 *:9000。HTTP Server 需在30秒内启动完毕。如未完成,则可能会导致健康检查超时,出现以下错误:
The request timed out in 30000ms.Please confirm your http server have enabled listening on port 9000.
如果您希望通过代码方式部署应用,可以参考 自定义创建 Web 函数,并配置 基于会话并发模式。
操作步骤
步骤一:创建浏览器沙箱应用
1. 登录 Serverless 控制台,单击左侧导航栏的 Agent。
2. 在 Serverless AI 运行时页面上的沙箱工具区域,单击创建应用,进入应用创建流程。
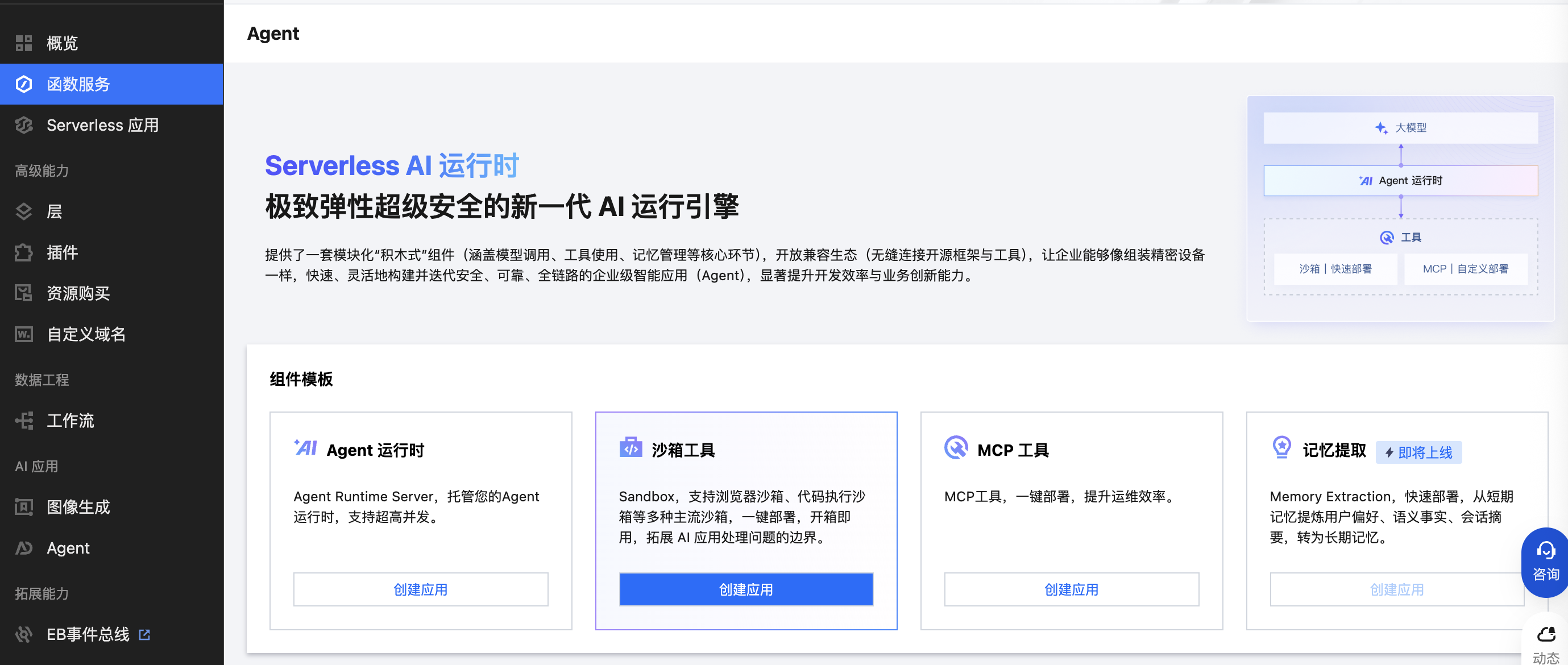
3. 在基础配置版块:
3.1 填入应用名称:应用的唯一标识,不可重复,创建后不可修改。
3.2 选择地域:资源必须归属于某个地域。
4. 在环境配置版块:
4.1 选择内存:设置资源类型对应的规格,当前仅支持 CPU 不同内存配置,详情请参见 函数算力支持。
4.2 添加环境变量,在配置中定义的环境变量可在函数运行时从环境中获取到。详情请参见 环境变量。

5. 在网络配置版块,配置函数网络访问权限:
公网访问:默认未启用,如果需要访问公网资源,则需要启用。
私有网络:启用后,应用可以访问同一个私有网络下的资源。

6. 在日志配置版块:启用日志投递,可将函数运行日志实时投递到指定位置。详情请参见 日志投递配置。

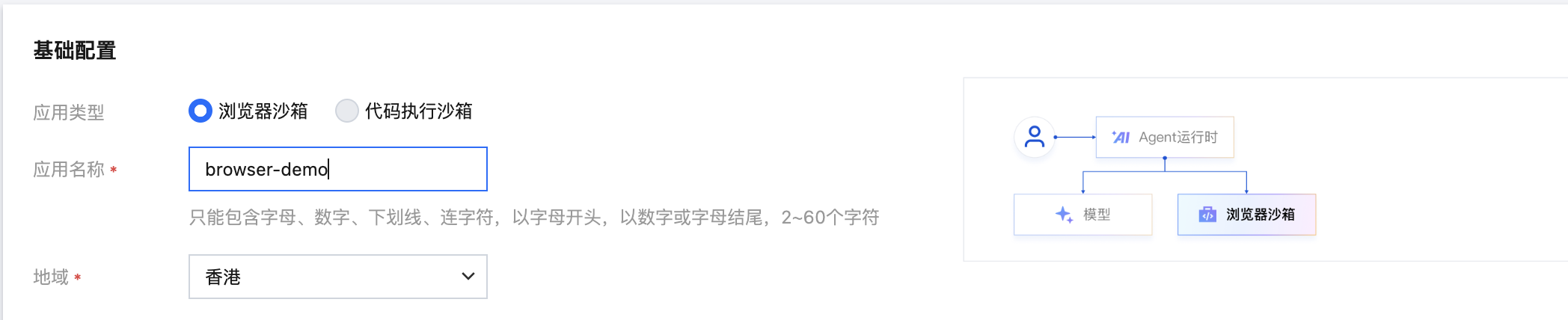
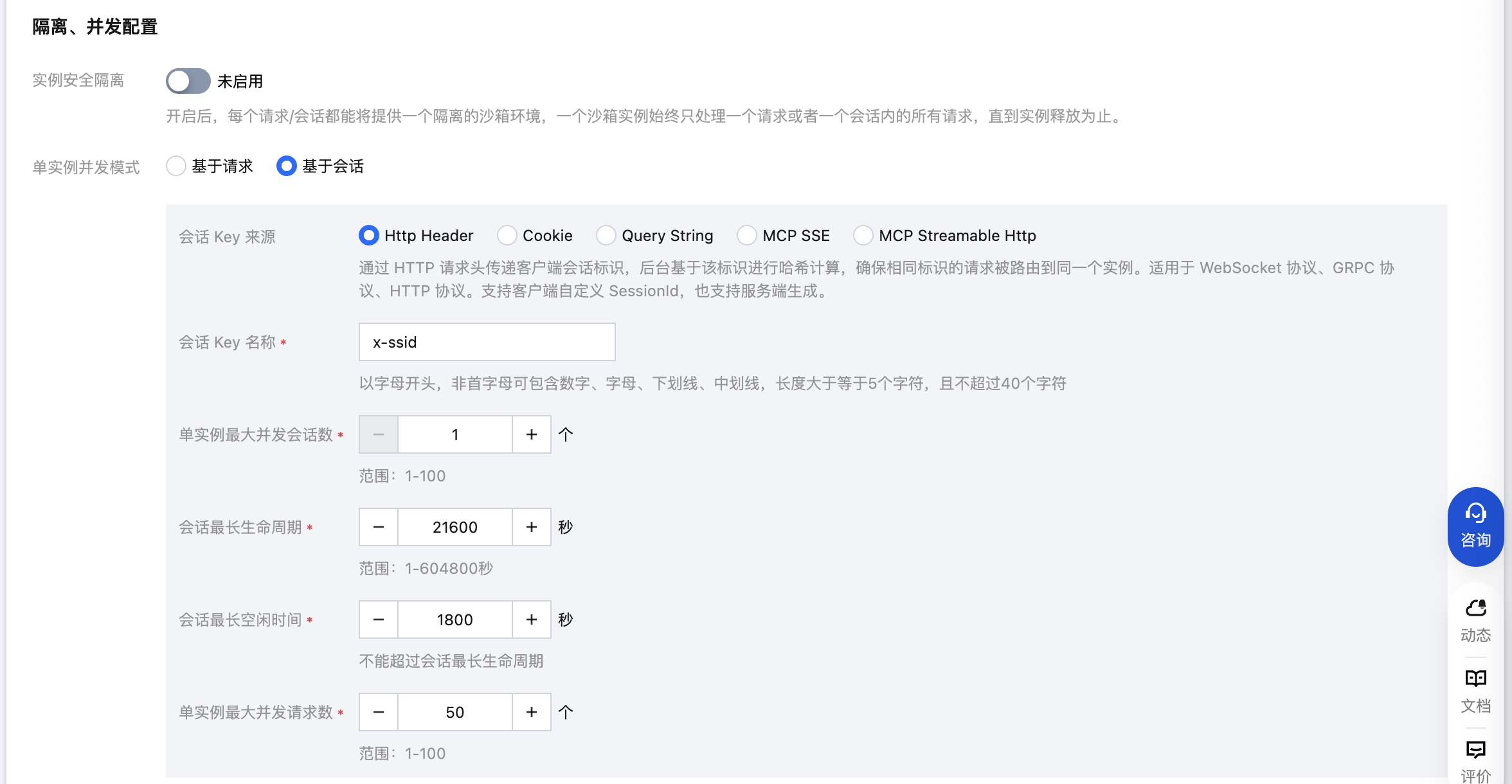
7. 在隔离、并发配置版块:配置实例安全隔离和单实例并发模式。
7.1 实例安全隔离:
如果启用,保证一个沙箱独占一个实例,沙箱销毁时,实例也销毁。
如果不启用,多个沙箱可能共享一个实例。
7.2 配置基于会话单实例并发模式,该配置主要用于标记客户端请求以哪种方式携带沙箱 ID、配置沙箱生命周期、底层实例支持的沙箱并发数和请求,其中本应用中“会话”的配置对应的是“沙箱”的配置。具体配置项说明如下:
配置项 | 说明 | 示例 |
会话 Key 来源 | 标记客户端请求以哪种方式携带沙箱 ID,系统根据此标记来决定要调度到某个沙箱上。可选项:Http Header、Cookie、Query String,三选一。不同选项支持场景说明如下: Http Header 通过 HTTP 请求头传递客户端会话标识,后台确保相同标识的请求被路由到同一个沙箱。适用于 WebSocket 协议、gRPC 协议、HTTP 协议。支持客户端自定义沙箱 ID,也支持服务端生成。 Cookie 将携带相同 Cookie 信息的请求路由到同一个沙箱。支持客户端生成沙箱 ID,也支持服务端生成。 Query String 将携带相同 Query String 信息的请求路由到同一个沙箱,需要客户端生成沙箱 ID。 | Http Header |
会话 Key 名称 | 1. Key 用途及命名规则 用途:沙箱的唯一标识名称。 命名要求:必须以字母开头;非首字母可包含数字、字母、下划线(_)、中划线(-);长度限制5-40 个字符(含边界值)。 2. Key 对应 Value(沙箱 ID )生成逻辑及字符要求: 生成逻辑: 来源为 Http Header、Cookie:支持客户端在首次调用时自主生成 Value;若客户端未生成,系统将自动生成。 来源为 QueryString:首次 Value 需由客户端生成。 字符要求: 含数字、字母、下划线(_)、中划线(-)长度限制128个字节。 | sandbox-id |
会话最长生命周期 | 从沙箱创建、使用到最终销毁的全过程,单位秒。超过生命周期后,服务端将自动销毁沙箱。最长可设置7天,默认21600秒。 | 21600秒 |
会话最长空闲时间 | 用户在一段时间内没有进行任何操作,导致沙箱进入空闲状态,单位秒。最长不得超过会话最长生命周期,默认1800秒。超过最长空闲(Idle)时间后,服务端将按照“会话空闲超时处理策略”处理沙箱。 | 1800秒 |
会话空闲超时处理策略 | 如果您开启了“实例安全隔离”,会话空闲超时处理策略可选自动销毁或者自动暂停。 如果您没有开启“实例安全隔离”,会话空闲超时处理策略默认自动销毁。 | 自动销毁 |
单实例最大并发会话数 | 单实例在同一时间内支持的最大沙箱数,默认值为20,最大支持100。 | 20 |
单实例最大并发请求数 | 单实例在同一时间内支持的最大请求数,默认为10,最大支持100。 | 10 |
8. 单击提交,启动应用的部署。
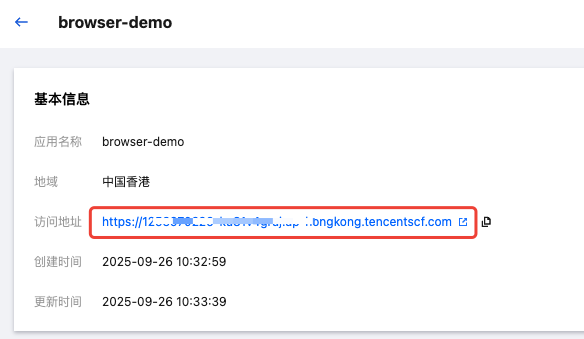
9. 应用部署完成后,在应用详情页面,可以获得访问地址。如果想从公网访问,建议您配置 自定义域名。
步骤二:生成浏览器沙箱实例
1. 应用部署完成后,在应用详情页面,可以获得应用访问地址。
2. 在客户端指定沙箱 ID,生成浏览器沙箱实例:
from steel import Steeldef create_browser_sandbox():# 用您的浏览器沙箱应用 URL 替换 {$URL}sandbox_url = "{$应用URL}"# 客户端生成沙箱 IDsandbox_id = "sandbox-id-123456"# 通过指定沙箱 ID x-ssid 生成沙箱client = Steel(base_url = sandbox_url)session = client.sessions.create(extra_headers={'sandbox-id': sandbox_id})ws_url = session.websocketUrlprint(f"✅ Browser Sandbox created: {sandbox_id}")print(f"🔗 WebSocket地址: {ws_url}")if __name__ == "__main__":create_browser_sandbox()
返回结果如下:
✅ 浏览器沙箱已创建: sandbox-id-123456🔗 WebSocket地址: ws://******.ap-******.tencentscf.com/
使用浏览器
通过 Playwright 使用浏览器
以下完整示例演示如何在浏览器中访问腾讯云官网:
前置依赖:参考步骤一创建浏览器沙箱,该沙箱的会话配置如下(您也可以改成其他方式,代码需要对应修改):
会话 Key 来源:HTTP Header
会话 Key 名称:sandbox-id
from steel import Steelfrom playwright.sync_api import sync_playwrightimport timedef playwright_demo():# 创建浏览器沙箱实例# 用您的浏览器沙箱应用 URL 替换sandbox_url = "https://******.ap-hongkong.tencentscf.com"# 客户端生成沙箱 IDsandbox_id = "sandbox-id-12345678"client = Steel(base_url = sandbox_url)session = client.sessions.create(extra_headers={'sandbox-id': sandbox_id})ws_url = session.websocketUrlprint(f"✅ 浏览器沙箱已创建: {sandbox_id}")print(f"🔗 WebSocket地址: {ws_url}")# 完成浏览器沙箱实例创建# 启动 playwrightplaywright = sync_playwright().start()browser = playwright.chromium.connect_over_cdp(ws_url, headers={'sandbox-id': sandbox_id})print("✅ 连接到浏览器")# 创建一个新的页面context = browser.contexts[0]page = context.new_page()# 访问腾讯云官网page.goto("https://cloud.tencent.com/")print(f"✅ 访问腾讯云官网:{page.url}")# 获取页面标题print(f"📄 页面标题: {page.title()}")# 关闭浏览器连接browser.close()if __name__ == "__main__":playwright_demo()
返回结果如下:
✅ 浏览器沙箱已创建: sandbox-id-12345678🔗 WebSocket地址: ws://******.ap-******.tencentscf.com/✅ 连接到浏览器✅ 访问腾讯云官网:https://cloud.tencent.com/📄 页面标题: 腾讯云 产业智变·云启未来 - 腾讯
通过 Puppeteer 使用浏览器
以下完整示例演示如何在浏览器中访问腾讯云官网:
前置依赖:参考步骤一创建浏览器沙箱,该沙箱的会话配置如下:
会话 Key 来源:Query String
会话 Key 名称:sandboxId
import asynciofrom pyppeteer import connectfrom steel._client import Steelsandbox_url = '******.ap-hongkong.tencentscf.com'sandbox_id = 'd45ea6f6-c5b2-47b5-9a42-4237d8647945'async def puppeteer_demo():# 浏览器沙箱 初始化client = Steel(base_url=f'http://{sandbox_url}', default_query={'sandboxId':sandbox_id})session = client.sessions.create(extra_query={'sandboxId': sandbox_id})cdp_url = f'{session.websocketUrl}?sandboxId={sandbox_id}'print(f"✅ 浏览器沙箱已创建: {sandbox_id}")print(f"🔗 CDP 地址: {cdp_url}")# 完成浏览器沙箱实例创建try:browser = await connect({'browserWSEndpoint': cdp_url,'defaultViewport': None})print('✅ 通过 CDP 连接到浏览器')page = await browser.newPage()await page.goto('https://cloud.tencent.com/')print(f"✅ 访问腾讯云官网:{page.url}")print(f"📄 页面标题: {await page.title()}")await browser.close()except Exception as error:print('Error:', str(error))if __name__ == "__main__":asyncio.run(puppeteer_demo())
返回结果如下:
✅ 浏览器沙箱已创建: d45ea6f6-c5b2-47b5-9a42-4237d8647945🔗 CDP 地址: ws://******.ap-hongkong.tencentscf.com/?sandboxId=d45ea6f6-c5b2-47b5-9a42-4237d8647945✅ 通过 CDP 连接到浏览器✅ 访问腾讯云官网:https://cloud.tencent.com/📄 页面标题: 腾讯云 产业智变·云启未来 - 腾讯
在 browser-use agent 集成浏览器沙箱工具
以下完整示例演示如何在 browser-use agent 集成浏览器沙箱,查询天气信息:
前置依赖:参考步骤一创建浏览器沙箱,该沙箱的会话配置如下:
会话 Key 来源:Query String
会话 Key 名称:sandboxId
from browser_use import Agent, BrowserSessionfrom browser_use.llm import ChatDeepSeekfrom steel._client import Steelfrom dotenv import load_dotenvimport asyncioimport os# 读取 DEEPSEEK_API_KEY 配置load_dotenv()# 浏览器沙箱配置sandbox_url = '******.ap-hongkong.tencentscf.com'sandbox_id = 'd43ea6f6-c5b2-47b5-9a42-4237d8647945'cdp_url = f'ws://{sandbox_url}?sandboxId={sandbox_id}'# 模型服务配置deepseek_api_key = os.getenv('DEEPSEEK_API_KEY')async def main():# 模型服务 初始化llm = ChatDeepSeek(base_url='https://api.deepseek.com/v1',model='deepseek-chat',api_key=deepseek_api_key,)# 浏览器沙箱 初始化client = Steel(base_url=f'http://{sandbox_url}', default_query={'sandboxId':sandbox_id})session = client.sessions.create(session_id=sandbox_id)browser_session = BrowserSession(cdp_url=cdp_url)# 任务task = "打开百度,查询深圳天气"# Agent 初始化agent = Agent(task=task,llm=llm,browser_session=browser_session)# 执行任务await agent.run()if __name__ == "__main__":asyncio.run(main())
返回结果如下:
INFO [service] Using anonymized telemetry, see https://docs.browser-use.com/development/telemetry.WARNING [Agent] ⚠️ DeepSeek models do not support use_vision=True yet. Setting use_vision=False for now...INFO [Agent] 🎯 Task: 打开百度,查询深圳天气INFO [Agent] 📦 Newer version available: 0.9.0 (current: 0.8.1). Upgrade with: uv add browser-use@0.9.0INFO [Agent] Starting a browser-use agent with version 0.8.1, with provider=deepseek and model=deepseek-chatINFO [Agent]INFO [Agent] 📍 Step 1:INFO [Agent] ❔ Eval: No previous action to evaluate - this is the first step.INFO [Agent] 🧠 Memory: Starting fresh browser session. Need to navigate to Baidu and search for Shenzhen weather information.INFO [Agent] 🎯 Next goal: Navigate to Baidu's homepage to begin the search process.INFO [Agent] ▶️ navigate: url: https://www.baidu.com, new_tab: FalseINFO [tools] 🔗 Navigated to https://www.baidu.comINFO [Agent]INFO [Agent] 📍 Step 2:INFO [Agent] 👍 Eval: Successfully navigated to Baidu's homepage as the first step.INFO [Agent] 🧠 Memory: Currently on Baidu homepage, ready to search for Shenzhen weather information.INFO [Agent] 🎯 Next goal: Input '深圳天气' into the search box and click search to get weather information.INFO [Agent] ▶️ [1/2] input: index: 16, text: 深圳天气, clear: TrueINFO [BrowserSession] ⌨️ Typed "深圳天气" into element with index 16INFO [Agent] ▶️ [2/2] click: index: 41INFO [tools] 🖱️ Clicked elementINFO [Agent]INFO [Agent] 📍 Step 3:INFO [Agent] 👍 Eval: Successfully searched for Shenzhen weather on Baidu and obtained comprehensive weather information.INFO [Agent] 🧠 Memory: Successfully completed the user request by navigating to Baidu, searching for '深圳天气', and retrieving detailed weather information including current conditions (19-24°C, cloudy), wind conditions, air quality, and extended forecasts.INFO [Agent] 🎯 Next goal: Present the weather information to the user and complete the task.INFO [Agent] ▶️ done: text: 已成功在百度查询深圳天气信息:**当前天气状况(14:35更新)**- 地点:深圳- 天气:多云- 温度:19~24°C- 风力:东北风3级- 空气质量:38 优**今日预报**- 当前温度:19°C- 天气状况:多云- 体感温度:24°C(人体感觉较为舒适)- 湿度:56..., success: True, files_to_display: []INFO [Agent]📄 Final Result:已成功在百度查询深圳天气信息:**当前天气状况(14:35更新)**- 地点:深圳- 天气:多云- 温度:19~24°C- 风力:东北风3级- 空气质量:38 优**今日预报**- 当前温度:19°C- 天气状况:多云- 体感温度:24°C(人体感觉较为舒适)- 湿度:56%- 紫外线指数:偏弱- 降水量:0.0毫米**生活气象指数**- 穿衣:外套类(舒适)- 感冒:少发(无需特别防护)- 洗车:较适宜(未来一天无雨)- 化妆:控油(露质面霜打底)**日出日落时间**- 日出:06:24- 日落:17:52已成功完成在百度查询深圳天气的任务。INFO [Agent] ✅ Task completed successfully
社区完整 API 说明
如果通过 SDK 调用,需要先安装 steel-sdk ,支持 Node 和 Python:
Node:使用时需要将访问地址 baseURL 替换为应用的 URL。SDK 使用详见 Node SDK 指引。
Python:使用时需要将访问地址 base_url 替换为应用的 URL。SDK 使用详见 Python SDK 指引。



