Ray 是一个高性能的通用分布式计算框架,旨在帮助用户高效构建和运行大规模的并行程序。它通过简洁的编程接口,将底层复杂的资源调度与任务分发进行了高度封装,使开发者可以像编写普通 Python 脚本一样构建分布式应用。Ray 具备良好的可扩展性和灵活性,支持任务并行、Actor 并发、资源自动调度等特性,适用于 AI 模型训练、推理服务部署、超参数调优、强化学习、多 Agent 系统等多种计算密集型场景。详细的使用文档请参见 Ray 官网文档。
1. 开发准备
Ray 组件默认安装位置为
/usr/local/service,集群预安装了 Python 3.9、torch、tensorflow、scikit-learn 等库,开箱即用。2. 数据读取
2.1 通过 HDFS 读取
Ray 集群的 HDFS 只有客户端,如需 HDFS 服务,需要手动配置连接到其他集群的 HDFS 服务。
集群 HDFS 配置
以下操作需要在集群的 head、worker 节点上各自配置一遍。
HDFS 下新增 hdfs-site.xml 文件,将要访问集群的 hdfs-site.xml 文件拷贝到当前集群节点
/usr/local/service/hadoop/etc/hadoop 下。su hadoopscp -P 22 <您的用户名>@<HDFS所在集群master公网ip>:/usr/local/service/hadoop/etc/hadoop/hdfs-site.xml root@<当前集群节点ip>:/usr/local/service/hadoop/etc/hadoop/hdfs-site.xml
HDFS 下修改 core-site.xml 文件:
fs.defaultFS=hdfs://HDFS<您的HDFS Namenode>
Spark 下运行 spark-env.sh:
./spark-env.sh his_log_path=hdfs:///spark-history
下发后重启 spark HistoryServer:
$SPARK_HOME/sbin/stop-history-server.sh$SPARK_HOME/sbin/start-history-server.sh
配置完成后,即可读取 HDFS 数据。
import rayimport raydpimport osfrom pyspark.sql import SparkSessionray.init(address='auto', log_to_driver=False)spark = raydp.init_spark(app_name = "example",num_executors = 1,executor_cores = 1,executor_memory = "1GB")df = spark.read.csv("hdfs://HDFS<您的HDFS Namenode>/data/iris.csv", header=True, inferSchema=True) # 替换为您的HDFSdf.show(10)# spark.stop()
2.2 S3
仅在 head 节点下载 S3数据。
import rayif __name__ == "__main__":ray.init(address="auto")if ray.util.get_node_ip_address() == "172.00.0.00": # 替换为您的 Head 节点 内网IPds = ray.data.read_parquet("s3://anonymous@ray-example-data/iris.parquet")print("S3 数据 Schema:", ds.dtypes)ray.shutdown()
2.3 NFS
import rayray.init(address="auto")ds = ray.data.read_parquet("/mnt/cluster_storage/iris.parquet")print(ds.schema())
2.4 本地读取
需保证每个节点都存在数据副本。
import rayds = ray.data.read_parquet("local:///tmp/iris.parquet")print(ds.schema())
2.5 读写 COS
结合 Ray 和 PyArrow 实现对 COS 中文件的读写操作。通过远程 Ray 任务,并行写入多个 Parquet 文件并验证其可读取性。该方法适用于将中间结果缓存到对象存储或构建分布式数据处理链路。
import rayimport pandas as pdimport pyarrow.fs as pa_fsimport ioimport os# 初始化 Ray,并设置 Hadoop 相关环境变量def init_ray():classPath = os.popen("$HADOOP_HOME/bin/hadoop classpath --glob").read()os.environ["CLASSPATH"] = classPathos.environ["RAY_LOG_LEVEL"] = "debug"os.environ["RAY_BACKEND_LOG_LEVEL"] = "debug"os.environ["HADOOP_HDFS_HOME"] = "/usr/local/service/hadoop"runtime_env = {"env_vars": {"CLASSPATH": classPath,"RAY_LOG_LEVEL": "debug","RAY_BACKEND_LOG_LEVEL": "debug"}}# 连接已有 Ray 集群ray.init(address='auto', runtime_env=runtime_env, log_to_driver=False)# 定义 COS 路径COS_NAMENODE_URI = "cosn://<您的COS Namenode名称>"COS_TASK_FILE_PATH_PREFIX = f"{COS_NAMENODE_URI}/ray_data/ray_test/task_files/file_"# 初始化 Ray 集群连接init_ray()# 生成一个模拟的 Pandas DataFramedef create_sample_dataframe(num_rows=100, file_index=0):return pd.DataFrame({'id': range(num_rows),'value': [f'data_{file_index}_{i}' for i in range(num_rows)],'timestamp': pd.Timestamp.now()})# 写入任务:将 DataFrame 写入 COS 的指定路径,格式为 Parquet@ray.remotedef write_parquet_task(cos_uri, cos_path, df):try:fs = pa_fs.HadoopFileSystem.from_uri(cos_uri)parquet_buffer = io.BytesIO()df.to_parquet(parquet_buffer, index=False)with fs.open_output_stream(cos_path) as f:f.write(parquet_buffer.getvalue())return True, cos_path, f"Wrote Parquet with {len(df)} rows"except Exception as e:return False, cos_path, str(e)# 读取任务:从 COS 读取 Parquet 文件并转换为 Ray Dataset@ray.remotedef read_parquet_task(cos_uri, cos_path):try:fs = pa_fs.HadoopFileSystem.from_uri(cos_uri)with fs.open_input_stream(cos_path) as f:content = f.read()df = pd.read_parquet(io.BytesIO(content), engine='pyarrow')dataset = ray.data.from_pandas(df)return True, cos_path, datasetexcept Exception as e:return False, cos_path, str(e)# 执行写入和读取任务try:write_tasks = []num_task_files = 5# 并行写入多个文件到 COSfor i in range(num_task_files):task_file_path = f"{COS_TASK_FILE_PATH_PREFIX}{i}.parquet"sample_df = create_sample_dataframe(20, i)write_tasks.append(write_parquet_task.remote(COS_NAMENODE_URI, task_file_path, sample_df))write_results = ray.get(write_tasks)successful_writes = []# 打印写入结果for success, path, msg in write_results:if success:successful_writes.append(path)print(f"Write Result: {path} - {'Success' if success else 'Failed'}: {msg}")# 成功写入后并行读取if successful_writes:read_tasks = []for path in successful_writes:read_tasks.append(read_parquet_task.remote(COS_NAMENODE_URI, path))read_results = ray.get(read_tasks)datasets = []for success, path, data in read_results:if success:datasets.append(data)data.show() # 展示读取的 Ray Datasetelse:print(f"Read Failed for {path}: {data}")except Exception as e:print(f"\\nERROR during Ray Tasks : {e}")finally:ray.shutdown()
写入过程:通过
write_parquet_task,使用 PyArrow 的 HadoopFileSystem 连接 COS,写入本地 DataFrame 为 Parquet 文件。读取过程:通过
read_parquet_task 读取 COS 中的 Parquet 文件,并转换为 Ray Dataset,以供后续分布式计算处理。并行处理:使用 Ray 的
@remote 装饰器并发执行任务,大幅提高数据处理效率。3. 任务训练
为满足不同业务场景的需求,Ray 提供了多种内置组件:
Ray Core:提供任务与 Actor 编程模型,支持细粒度并行计算。
Ray Tune:支持大规模超参数搜索与自动化实验管理。
Ray Train:提供统一的分布式训练接口,兼容主流深度学习框架。
Ray Serve:用于构建高可用、低延迟的在线推理服务。
RLlib:支持多种主流强化学习算法和大规模训练。
使用 Ray 分布式训练 FashionMNIST 模型
使用 PyTorch 定义并训练一个简单的神经网络模型。
利用 Ray Train 将训练任务分布式运行在多个 worker 上。
支持 CPU/GPU 环境,易于扩展和迁移。
准备数据集和模型结构
import torchimport torch.nn as nnfrom torch.utils.data import DataLoaderfrom torchvision import datasetsfrom torchvision.transforms import ToTensor# 下载并返回 FashionMNIST 数据集def get_dataset():return datasets.FashionMNIST(root="/tmp/data",train=True,download=True,transform=ToTensor(),)# 定义神经网络模型结构class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28 * 28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10),)def forward(self, inputs):inputs = self.flatten(inputs)logits = self.linear_relu_stack(inputs)return logits
定义单机版训练函数
可用于本地测试。
def train_func():num_epochs = 3batch_size = 64dataset = get_dataset()dataloader = DataLoader(dataset, batch_size=batch_size)model = NeuralNetwork()criterion = nn.CrossEntropyLoss()optimizer = torch.optim.SGD(model.parameters(), lr=0.01)for epoch in range(num_epochs):for inputs, labels in dataloader:optimizer.zero_grad()pred = model(inputs)loss = criterion(pred, labels)loss.backward()optimizer.step()print(f"epoch: {epoch}, loss: {loss.item()}")
执行方式:
train_func()
编写分布式训练函数
我们使用
ray.train.torch.prepare_model 和 prepare_data_loader 方法对模型和数据进行封装。这些工具可以自动:将模型包裹为 DistributedDataParallel。
为 DataLoader 添加分布式采样器。
在多 GPU/多节点环境中自动设置设备与通信。
import ray.train.torchdef train_func_distributed():num_epochs = 3batch_size = 64dataset = get_dataset()dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)dataloader = ray.train.torch.prepare_data_loader(dataloader)model = NeuralNetwork()model = ray.train.torch.prepare_model(model)criterion = nn.CrossEntropyLoss()optimizer = torch.optim.SGD(model.parameters(), lr=0.01)for epoch in range(num_epochs):# 多 worker 时需设置 epoch 以同步采样器if ray.train.get_context().get_world_size() > 1:dataloader.sampler.set_epoch(epoch)for inputs, labels in dataloader:optimizer.zero_grad()pred = model(inputs)loss = criterion(pred, labels)loss.backward()optimizer.step()print(f"epoch: {epoch}, loss: {loss.item()}")
启动 Ray 分布式训练器
我们使用
TorchTrainer 对训练函数进行调度管理,并通过 ScalingConfig 控制 worker 数量和是否使用 GPU。from ray.train.torch import TorchTrainerfrom ray.train import ScalingConfig# 设置为 True 可启用 GPUuse_gpu = Falsetrainer = TorchTrainer(train_func_distributed,scaling_config=ScalingConfig(num_workers=4, # 使用 4 个分布式 workeruse_gpu=use_gpu))results = trainer.fit()
说明:
prepare_model() 会自动将模型移动到当前设备。prepare_data_loader() 自动加上 DistributedSampler。如果使用 GPU,请确保环境中已经配置好 CUDA 和可用 GPU 资源,并设置
use_gpu=True。训练日志默认只由主进程打印,如需记录所有日志可在 Ray Dashboard 或 Ray 目录下的日志文件中查看。
4. 任务管理
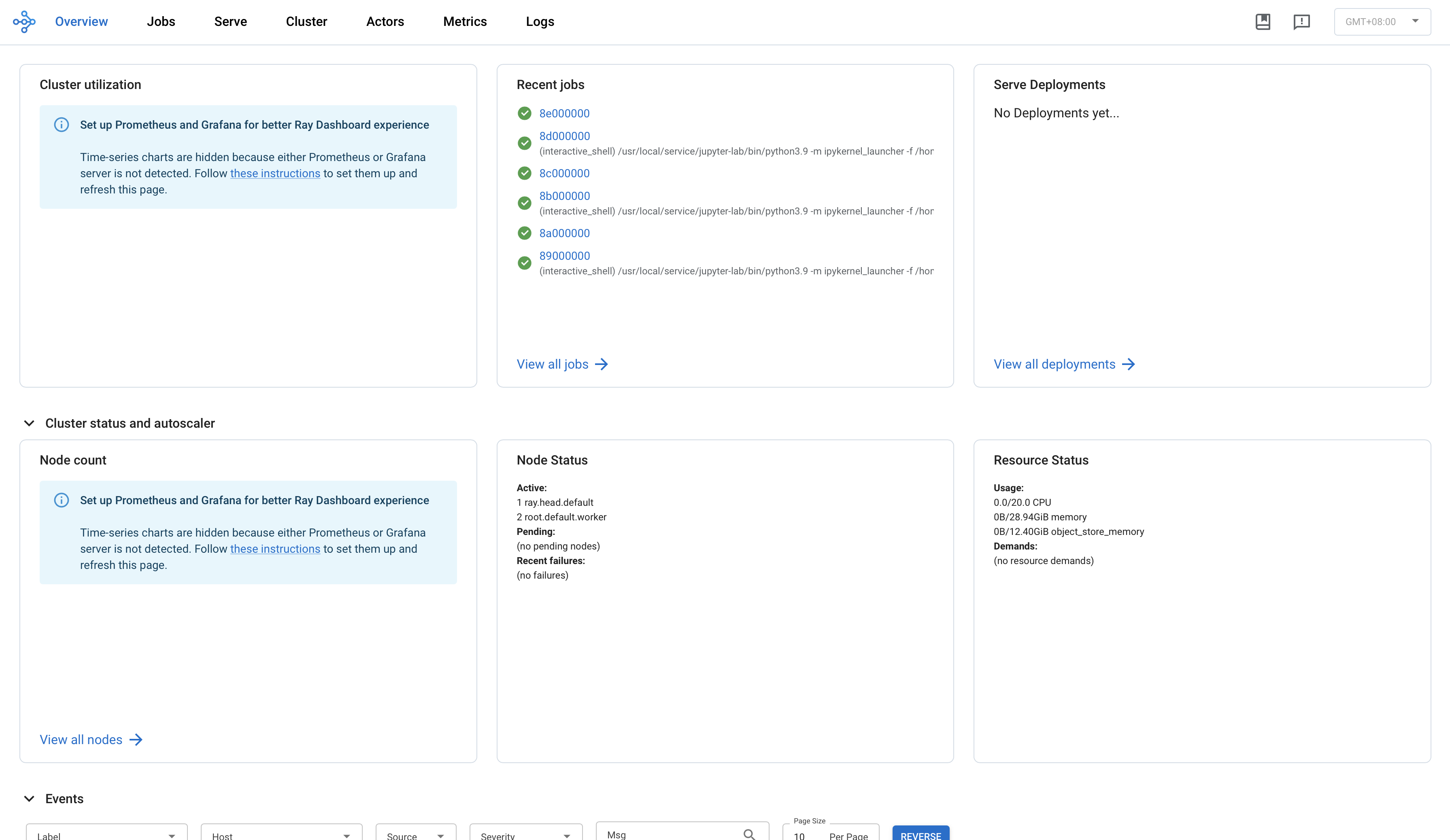
Ray Dashboard
Ray Dashboard 提供一个用于实时展示系统指标、节点级资源监控、作业分析以及任务可视化的界面,旨在帮助用户了解 Ray 应用的运行性能,并识别潜在问题。
在集群服务页单击 Ray 组件 WebUI 即可进入 Ray Dashboard(需安全组开启8265端口)。
Job 页
在 Jobs 视图中,您可以监控在 Ray 集群中运行的所有作业(job)。Ray 作业是指通过 Ray API 提交的计算任务。官方建议使用 Ray Job API 将作业提交至集群,同时也支持在 Head 节点上直接运行 Python 脚本的方式来交互式执行 Ray 作业。
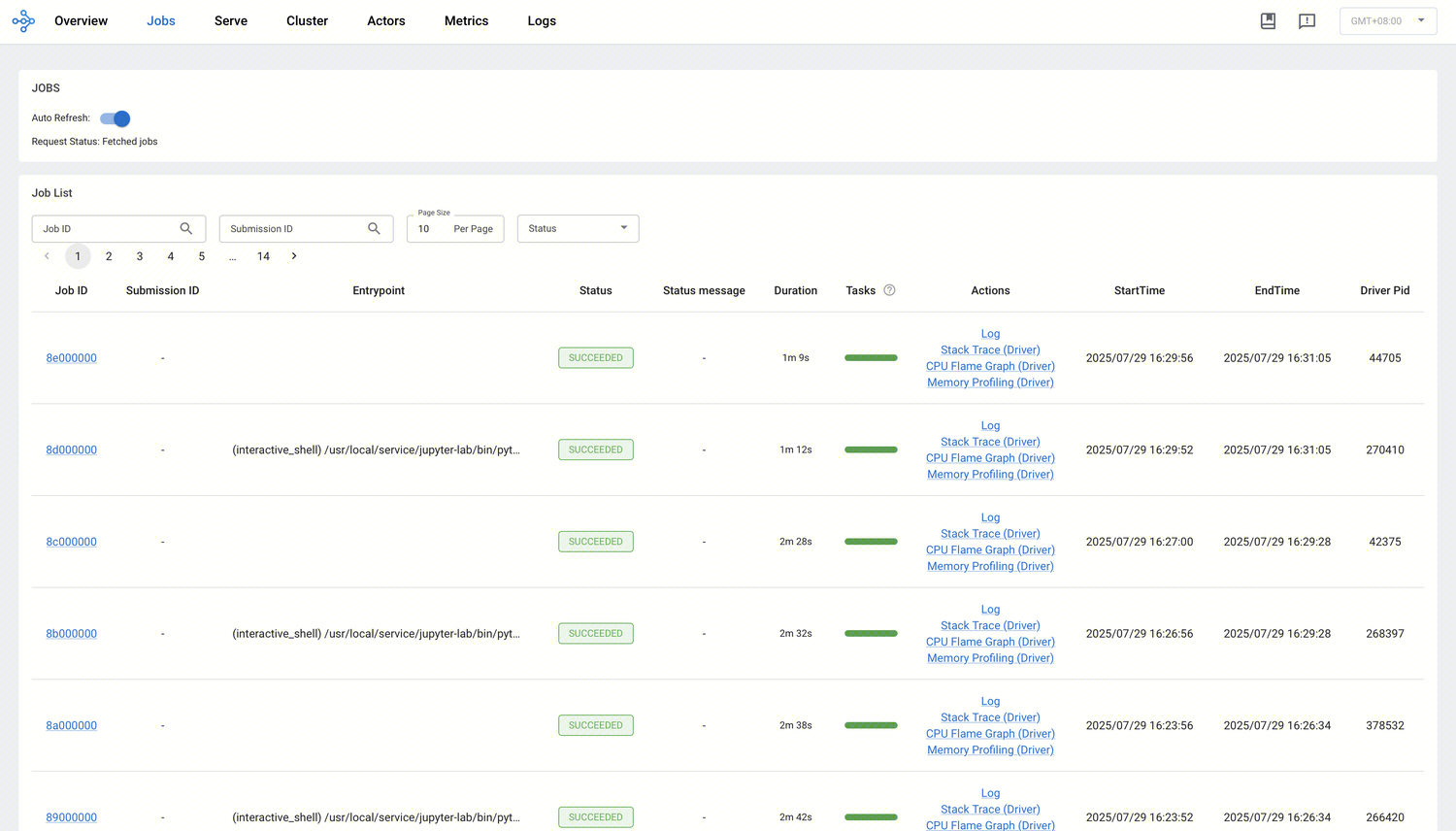
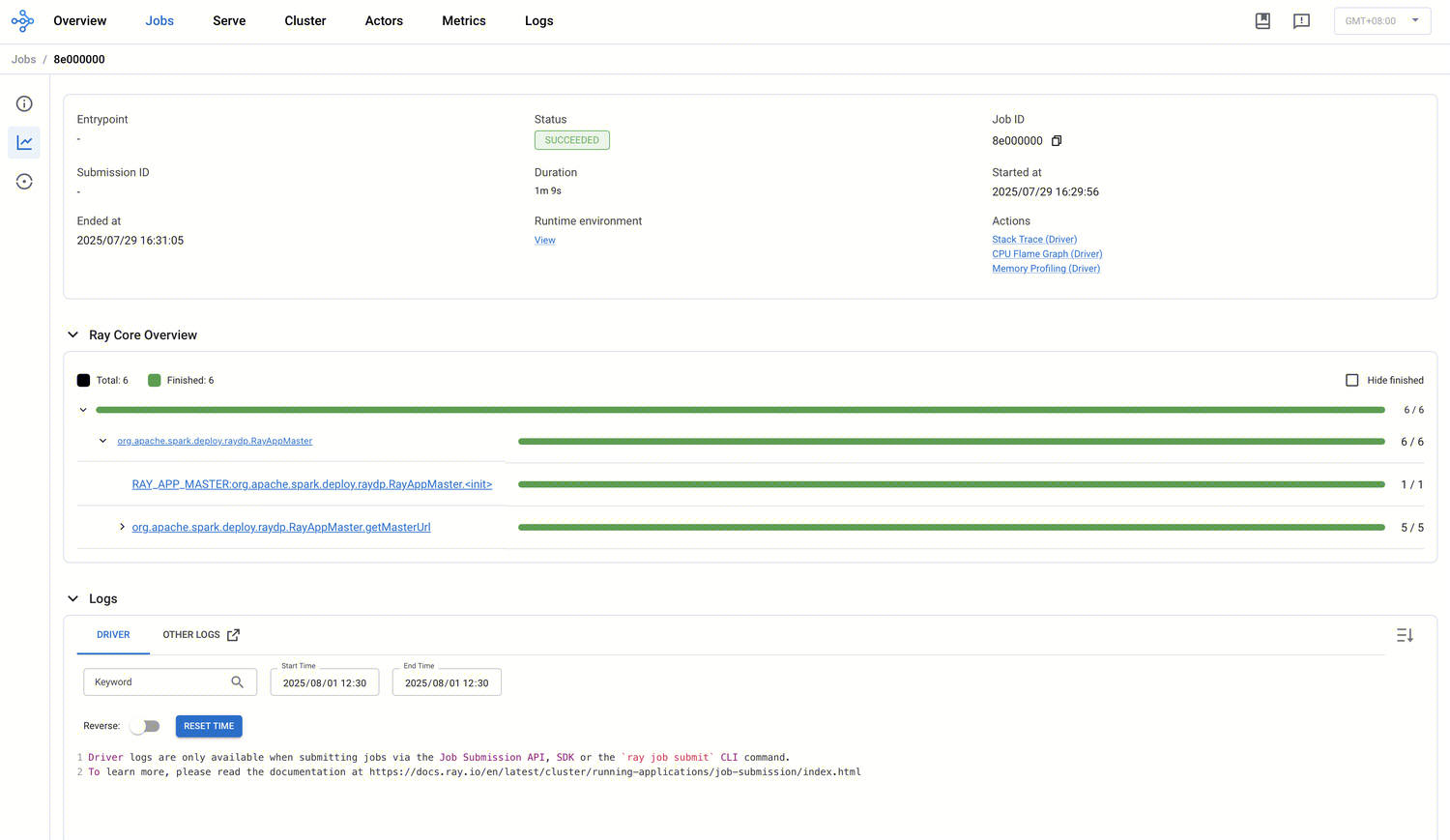
该视图会列出所有活跃、已完成及失败的作业,单击每个作业的 ID,可查看该作业的详细执行信息.包括:
作业状态总览与基本信息:显示每个作业的 ID、Entry point、提交/结束时间、持续时长和状态。
Ray Core 概览:以树形结构展示 Job 中所有 Task 和 Actor 的状态分布,任务按名称分组,并展示子任务层级;Actor 也按类名分组,并展示嵌套 Actor 与 Actor 内部调用的方法等细节。
日志查看与筛选:可以查看 Driver 日志及其他日志,例如 Head 节点日志。支持关键词搜索与时间窗口筛选,有助于调试与问题定位。
Task Timeline:显示不同 Worker 在不同节点上调度、执行、序列化、反序列化等事件的执行时间线,精准分析延迟与资源使用情况。
Task、Actor、Placement Group Table 概览。
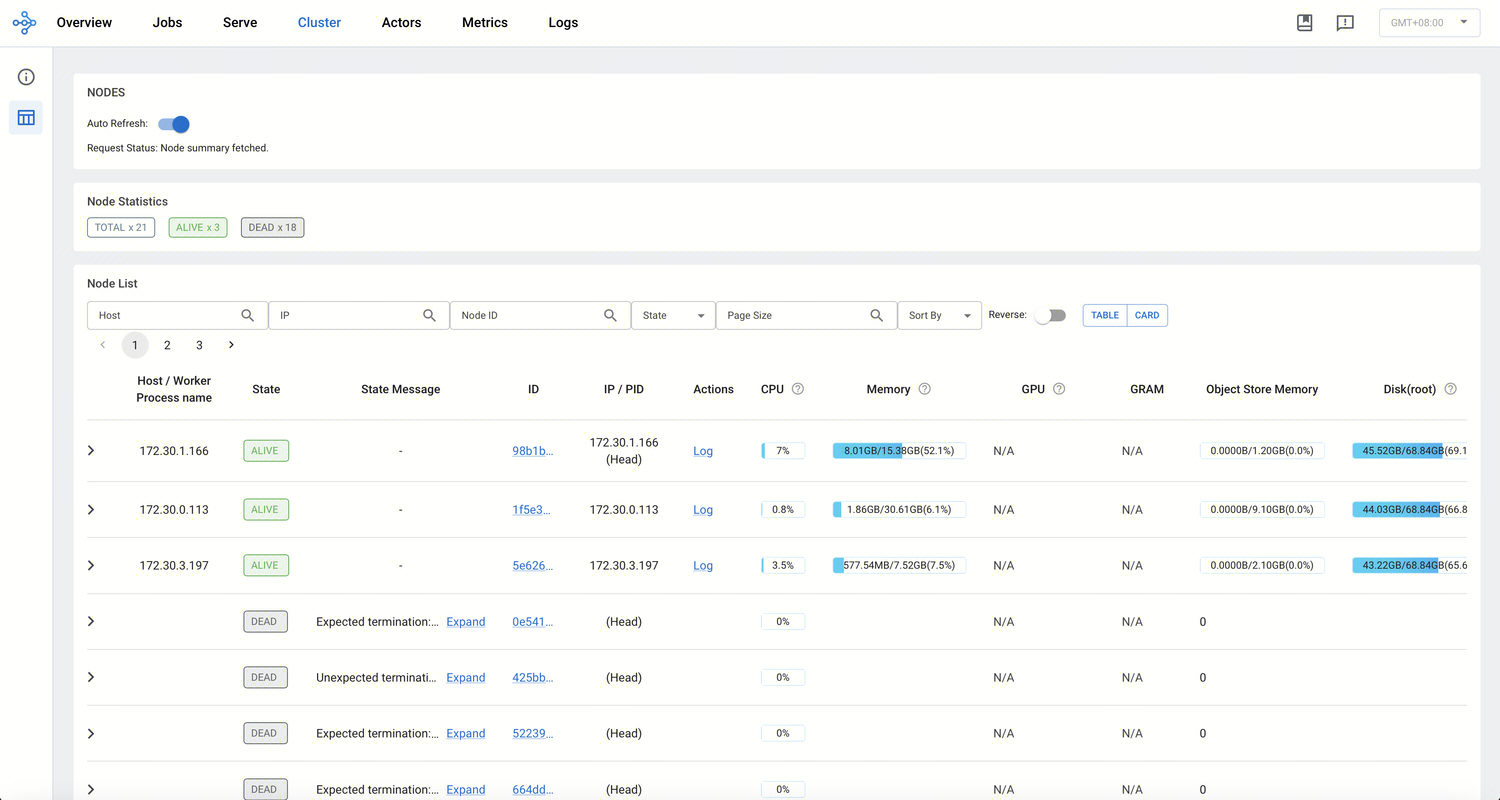
Cluster 页
Cluster 页面帮助用户全面掌握 Ray 集群的实时资源分布与各节点状态,并可深入查看节点或 Worker 日志,快速定位性能瓶颈或异常节点。
节点与 Worker 层级关系:Cluster 视图以树状结构展示整个集群中各节点及所属进程的关系。您可以单击每个节点前的展开按键,查看节点下的 Worker 列表,还可以清楚看到 GPU/CPU 是否分配给特定任务或 Actor。
节点状态统计:展示总节点数量、处于 ALIVE 与 DEAD 的节点数。
实时资源监控:显示每个节点的 CPU、内存、磁盘、网络利用率,还有 GPU 或 GRAM 使用情况等硬件资源状态。
日志与错误排查:在 Cluster 页面,您可以单击节点或 Worker 的 Log 操作项,查看该进程对应的日志,有助于定位资源耗用异常或单节点故障情景。
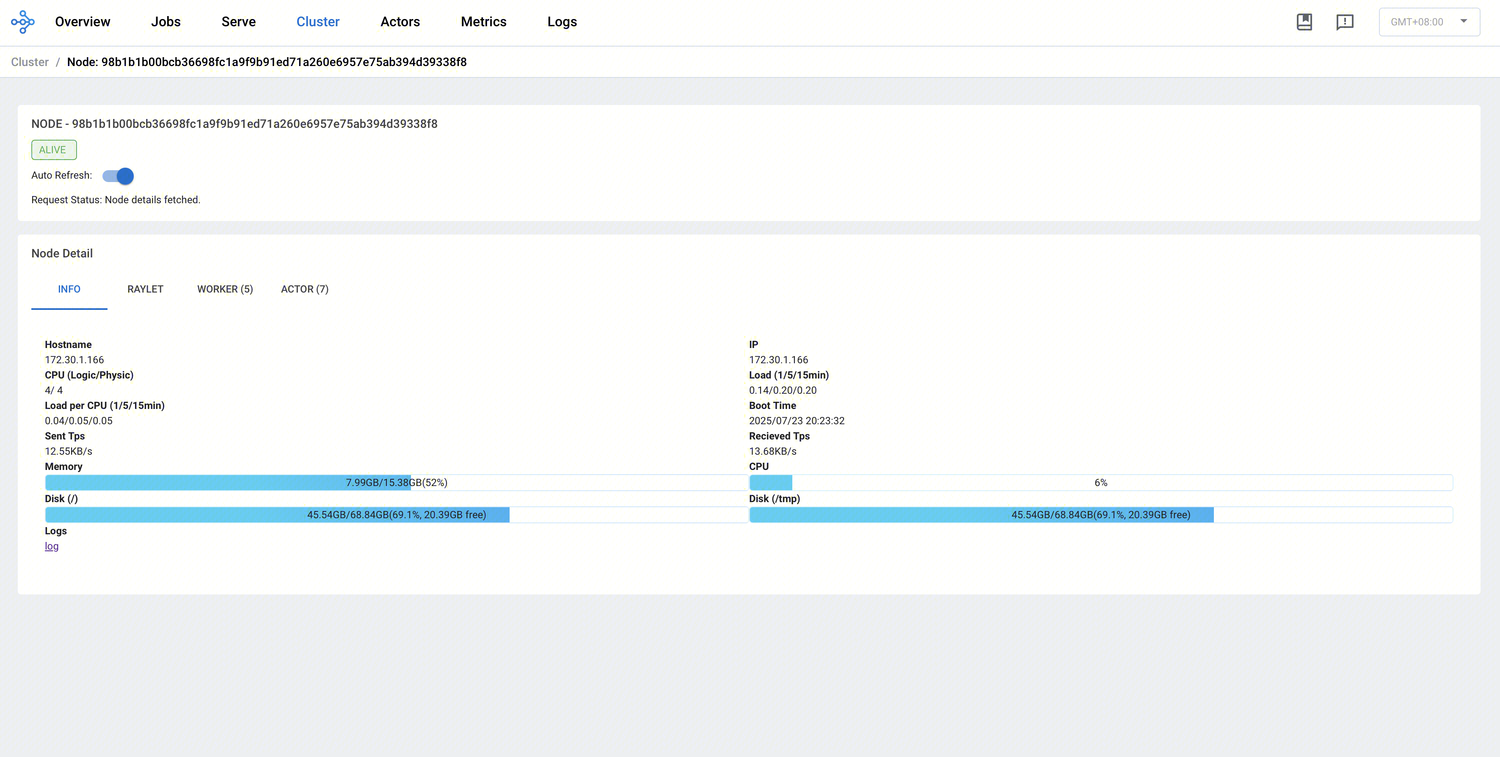
单击节点 ID 可进入该节点的详情页面。
Actor 页
在 Actor 页面可以查看所有创建过的 Actor 的信息,以及某个 Actor 的日志、创建该 Actor 的作业 ID 等信息。
系统最多保存 100,000 个已销毁(dead)的 Actor 信息。可通过设置环境变量
RAY_maximum_gcs_destroyed_actor_cached_count 来修改该限制。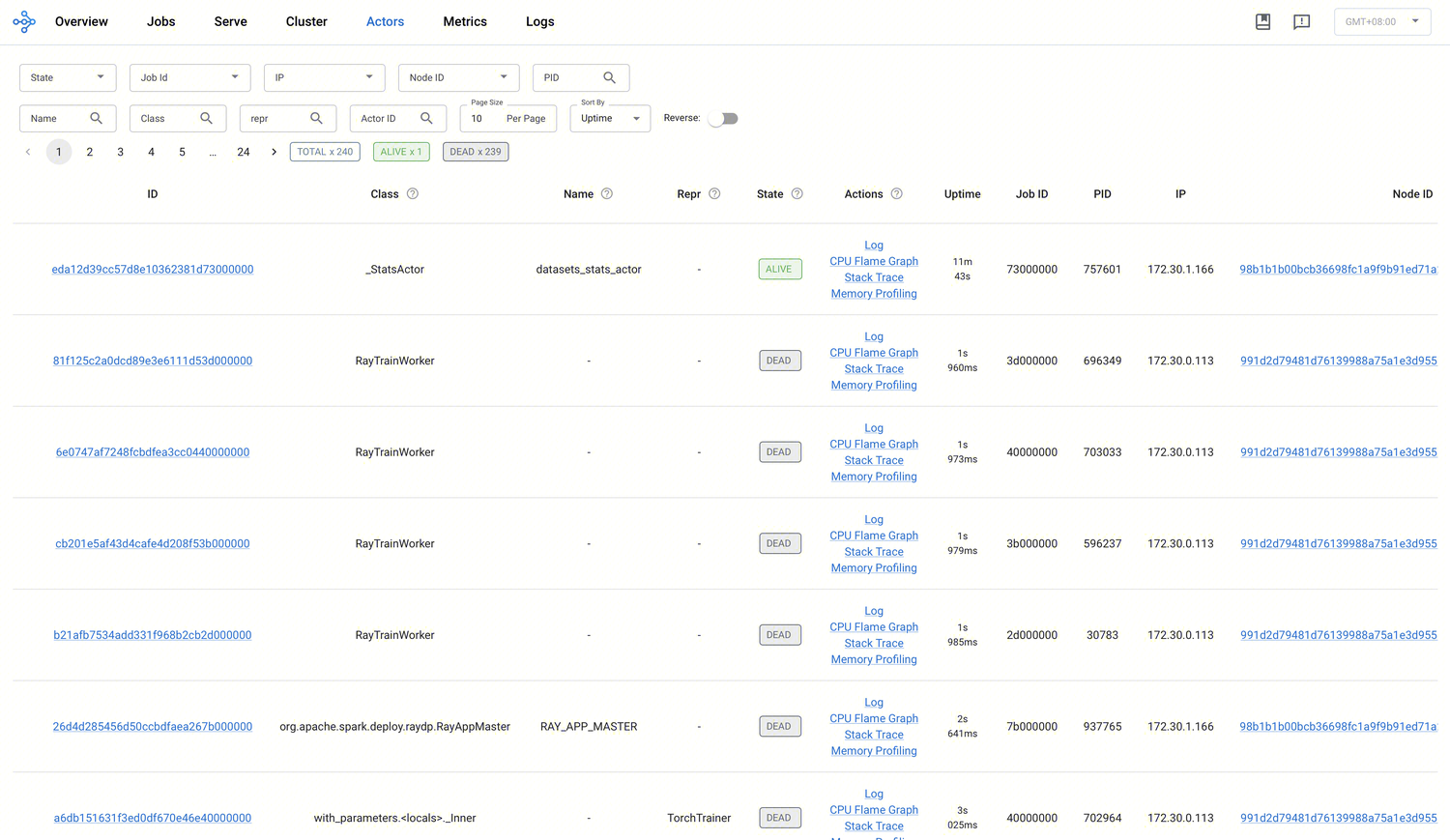
Actor 详情页
单击某个 Actor 的 ID 即可进入详情页。
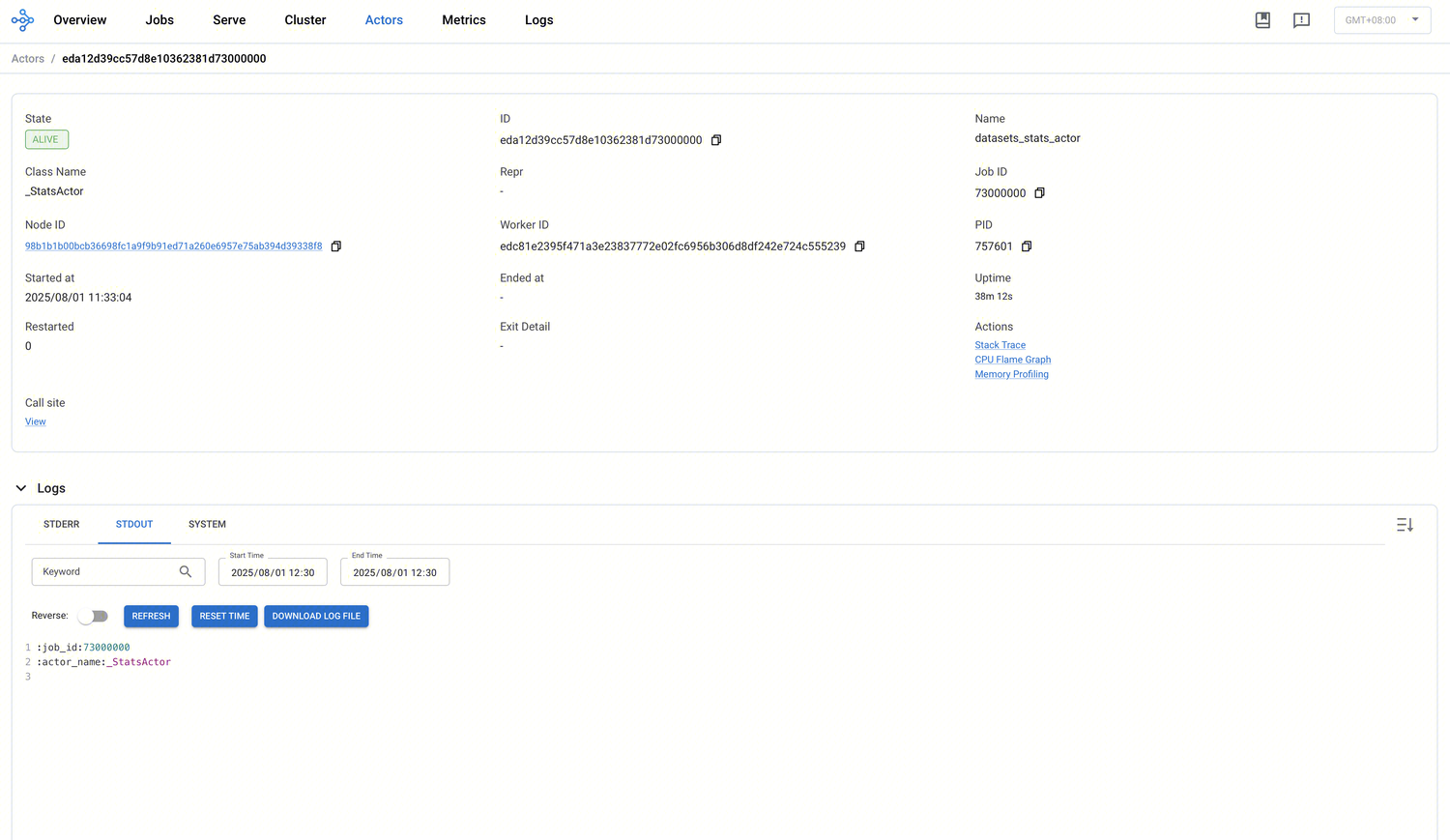
Logs 页
Logs 视图会列出集群中所有节点的 Ray 日志,并按节点与日志文件名称进行组织。
此外,Logs 视图提供搜索功能,支持快速定位特定的日志信息。