本次提交的任务为 wordcount 任务即统计单词个数,提前需要在集群中上传需要统计的文件。
Hadoop 等相关软件路径在
/usr/local/service/ 下。相关日志路径在
/data/emr 下。1. 开发准备
由于任务中需要访问腾讯云对象存储 COS,所以需要在 COS 中先 创建存储桶(Bucket)。
确认您已经开通了腾讯云,并且创建了一个 EMR 集群。在创建 EMR 集群时在基础配置页面勾选了开启 COS,并在下方填写自己的 SecretId 和 SecretKey。SecretId 和 SecretKey 可以在 API 密钥管理界面 查看。如果还没有密钥,请单击新建密钥建立一个新的密钥。
2. 登录 EMR 服务器
在做相关操作前需要登录到 EMR 集群中的任意一个机器,建议登录到 Master 节点。EMR 是建立在 Linux 操作系统的腾讯云服务器 CVM 上的,所以在命令行模式下使用 EMR 需要登录 CVM 服务器。
创建 EMR 集群后,在控制台中选择弹性 MapReduce。在集群资源 > 资源管理中单击 Master 节点,选择 Master 节点的资源 ID,即可进入云服务器控制台并且找到 EMR 对应的云服务器。
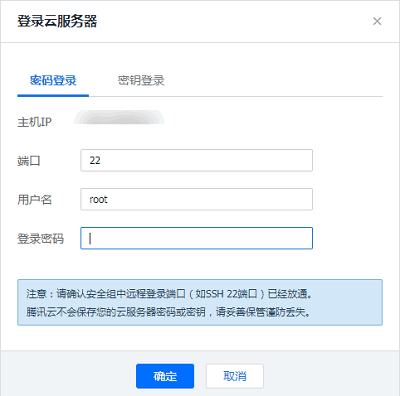
登录 CVM 的方法可参见 登录 Linux 实例。这里我们可以选择使用 WebShell 登录。单击对应云服务器右侧的登录,进入登录界面,用户名默认为 root,密码为创建 EMR 时用户自己输入的密码。
[root@172 ~]# su hadoop[hadoop@172 root]$ cd /usr/local/service/hadoop[hadoop@172 hadoop]$
3. 数据准备
您需要准备统计的文本文件。分为两种方式:数据存储在 HDFS 集群和数据存储在 COS。
首先要把本地的数据上传到云服务器。可以使用 scp 或者 sftp 服务来把本地文件上传到 EMR 集群的云服务器中。在本地命令行使用:
scp $localfile root@公网IP地址:$remotefolder
其中,$localfile 是您的本地文件的路径加名称;root 为 CVM 服务器用户名;公网 IP 地址可以在 EMR 控制台的节点信息中或者在云服务器控制台查看;$remotefolder 是您要存放文件的 CVM 服务器路径。
上传成功后,在 EMR 集群命令行中即可查看对应文件夹下是否有相应文件。
[hadoop@172 hadoop]$ ls –l
数据存放在 HDFS
将数据上传到腾讯云服务器之后,可以把数据拷贝到 HDFS 集群。这里使用
/usr/local/service/hadoop 目录下的 README.txt 文本文件作为说明。通过如下指令把文件拷贝到 Hadoop 集群:[hadoop@172 hadoop]$ hadoop fs -put README.txt /user/hadoop/
拷贝完成后使用如下指令查看拷贝好的文件:
[hadoop@172 hadoop]$ hadoop fs -ls /user/hadoop输出:-rw-r--r-- 3 hadoop supergroup 1366 2018-06-28 11:39 /user/hadoop/README.txt
如果 Hadoop下面没有
/user/hadoop 文件夹,用户可以自己创建,指令如下:[hadoop@172 hadoop]$ hadoop fs -mkdir /user/hadoop
数据存放在 COS
数据存放在 COS 中有两种方式:在本地通过 COS 的控制台上传和在 EMR 集群通过 Hadoop 命令上传。
在本地通过 COS 控制台直接上传,如果数据文件已经在 COS 可以通过如下命令查看:
[hadoop@10 hadoop]$ hadoop fs -ls cosn://$bucketname/README.txt-rw-rw-rw- 1 hadoop hadoop 1366 2017-03-15 19:09 cosn://$bucketname /README.txt
其中 $bucketname 替换成您的储存桶的名字和路径。
在 EMR 集群通过 Hadoop 命令上传,指令如下:
[hadoop@10 hadoop]$ hadoop fs -put README.txt cosn://$bucketname/[hadoop@10 hadoop]$ bin/hadoop fs -ls cosn://$bucketname/README.txt-rw-rw-rw- 1 hadoop hadoop 1366 2017-03-15 19:09 cosn://$bucketname/README.txt
4. 通过 MapReduce 提交任务
本次提交的任务是 Hadoop 集群自带的例程 wordcount,wordcount 已被压缩为 jar 包上传到了创建好的 Hadoop 中,用户可以直接调来使用。
示例使用 hadoop 3.2.2 版本,其他版本示例代码中需使用对应版本的 hadoop-mapreduce-examples 包, 可以在 hadoop 目录下./share/hadoop/mapreduce/路径中查看实际存在的版本。
统计 HDFS 中的文本文件
进入
/usr/local/service/hadoop 目录,和数据准备中一样。通过如下命令来提交任务:[hadoop@10 hadoop]$ bin/yarn jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount/user/hadoop/README.txt /user/hadoop/output
注意
以上整个命令为一条完整的指令,
/user/hadoop/README.txt 为输入的待处理文件,/user/hadoop/output 为输出文件夹,在提交命令之前要保证 output 文件夹尚未创建,否则提交会出错。执行完成后,通过如下命令查看执行输出文件:
[hadoop@10 hadoop]$ bin/hadoop fs -ls /user/hadoop/outputFound 2 items-rw-r--r-- 3 hadoop supergroup 0 2017-03-15 19:52 /user/hadoop/output/_SUCCESS-rw-r--r-- 3 hadoop supergroup 1306 2017-03-15 19:52 /user/hadoop/output/part-r-00000
通过如下指令查看 part-r-00000 中的统计结果:
[hadoop@10 hadoop]$ bin/hadoop fs -cat /user/hadoop/output/part-r-00000(BIS), 1(ECCN) 1(TSU) 1(see 15D002.C.1, 1740.13) 1<http://www.wassenaar.org/> 1……
统计 COS 中的文本文件
进入
/usr/local/service/hadoop 目录,通过如下命令来提交任务:[hadoop@10 hadoop]$ bin/yarn jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcountcosn://$bucketname/README.txt /user/hadoop/output
命令的输入文件改为了
cosn:// $bucketname /README.txt,即处理 COS 中的文件,其中 $bucketname 为您的存储桶的名字加路径。依然输出到 HDFS 集群中,也可以选择输出到 COS 中。查看输出的方法和上文一样。查看任务日志
#查看任务状态bin/mapred job -status jobid#查看任务日志yarn logs -applicationId id



