概述
随着大数据处理规模的持续增长,传统 CPU 计算架构在性能提升上逐渐进入平台期。NVIDIA 推出的 RAPIDS Accelerator for Apache Spark 将 GPU 的并行计算能力引入 Spark 数据处理流程,通过将 SQL 算子下推到 GPU 执行,实现数倍于 CPU 的性能提升,同时将计算成本降低 30%~80%。
腾讯云弹性 MapReduce(EMR)与 NVIDIA 深度合作,在 EMR v3.7.1 版本中基于 Spark 和 Spark-RAPIDS 构建了开箱即用的 Spark-RAPIDS 产品能力,为客户提供企业级大数据及人工智能场景下的 GPU 加速处理能力。
核心优势
开箱即用:基于 EMR 最新发行版,Spark-RAPIDS 插件已做深度适配,无需手动编译或复杂部署。
YARN GPU 资源自动识别:腾讯云 EMR 对 YARN 组件进行了增强,创建 GPU 节点后 YARN 自动识别 GPU 设备并配置 yarn.resource-types,用户无需手动修改 YARN 配置文件。
云原生混合调度:支持 CPU 与 GPU 资源混合部署,实现弹性扩缩容,最大化资源利用率。
成本优化:GPU 加速带来的性能提升可显著降低计算资源投入,实现降本增效。
Spark-RAPIDS 简介
工作原理
Spark-RAPIDS 是 NVIDIA 开源的 Spark 加速插件,其核心原理如下:
1. 算子下推:将 Spark SQL 中的计算密集型算子(Join、Aggregation、Sort、Window 等)从 CPU 下推到 GPU 执行。
2. 列式处理:利用 GPU 的大规模并行架构,一次性处理大批量数据行,充分发挥 GPU 计算优势。
3. 自动回退:遇到不支持的算子时自动回退到 CPU 原生执行,保证任务正确性。
适用场景
推荐场景:
高散列度的 Join、Aggregation、Window、Sort 操作
大规模数据 ETL 处理
包含 CUDA 计算或编码计算的 UDF
数据量大、计算密集的分析型查询
需评估的场景:
小数据量任务(加速效果不明显)
I/O 密集型任务(Shuffle 或读取开销占主导)
GPU 显存不足的场景
UDF 包含大量逻辑计算(与 CPU 频繁交互)
环境准备
集群版本要求
EMR 发行版:v3.7.1
Spark 版本:v3.5.3
Spark-RAPIDS 版本:v25.12.1
GPU 节点选择
Spark-RAPIDS 对 GPU 节点的网络带宽和硬盘带宽有较高要求。建议:
配置项 | 推荐说明 |
机型 | 优先选择高网络带宽 GPU 机型(如 GNV4、PNV4、GN10X 系列) |
存储 | 增加硬盘容量或使用支持高 IOPS 的云盘类型 |
节点类型 | 可选择 Core 节点或 Task 节点配置 GPU 节点 |
集群创建
新建集群时:在硬件配置步骤中,为 Core 或 Task 节点选择 GPU 计算型实例。
GPU 节点配置:
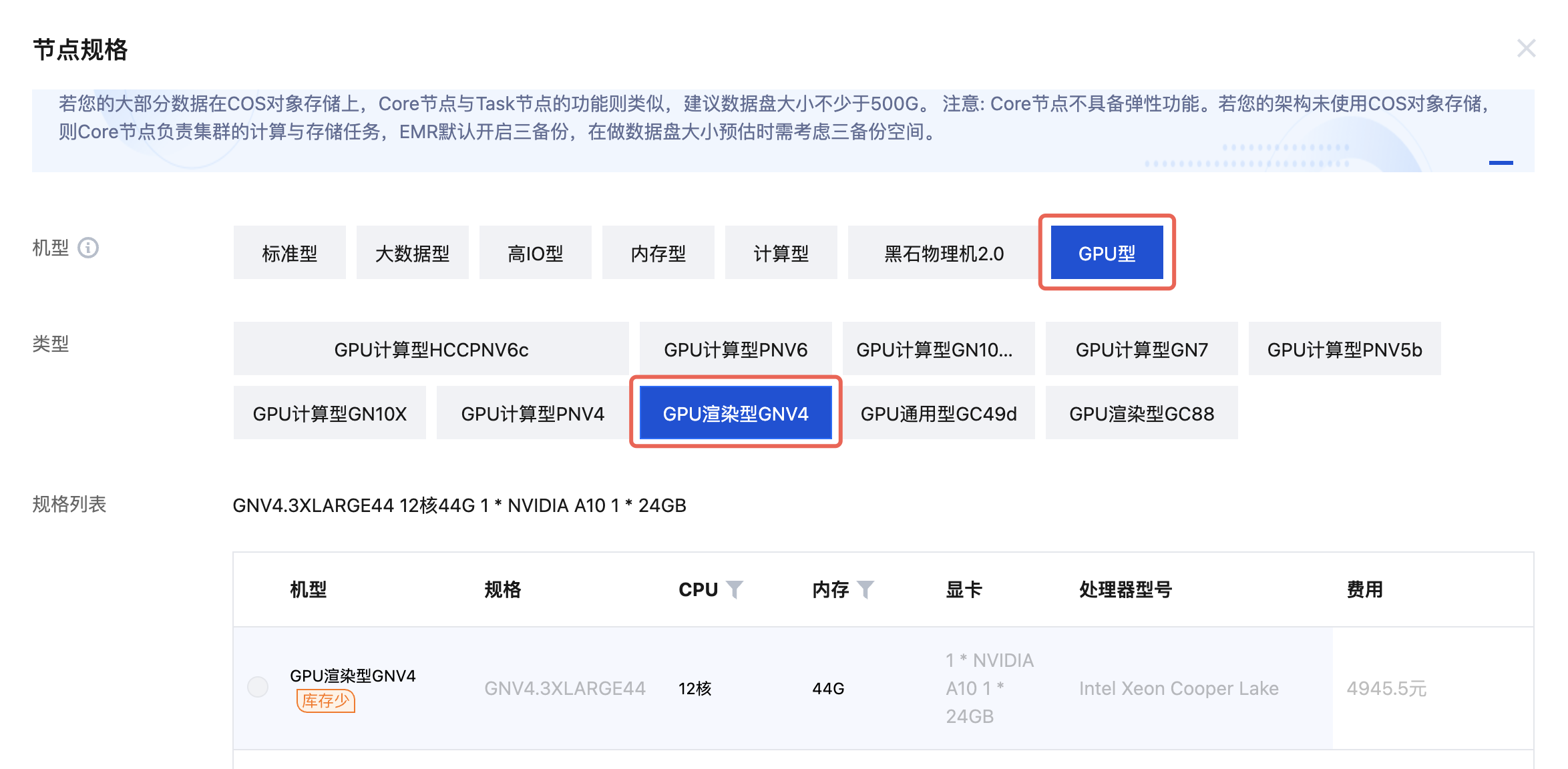
已有集群扩容:可通过 EMR 控制台的“扩容”功能,向目标节点添加 GPU 节点。
核心配置
YARN GPU 资源自动识别
腾讯云 EMR 核心能力:开启 GPU 节点后,YARN 自动识别 GPU 设备并配置 yarn.resource-types,无需用户手动修改 yarn-site.xml 或 resource-types.xml ,自动发现并注册 GPU 资源类型,NodeManager 自动将 GPU 设备纳入资源管理范畴。
用户只需在 EMR 控制台完成 GPU 节点的添加操作,YARN 资源管理器即可自动识别并调度 GPU 资源。
核心配置参数
下表列出对性能和正确性影响较大的参数,用户可按需配置:
RAPIDS 插件启用(必填)
配置项 | 推荐取值 | 说明 |
spark.plugins | com.nvidia.spark.SQLPlugin | 启用 RAPIDS SQL Plugin,将 SQL 算子下推到 GPU |
spark.kryo.registrator | com.nvidia.spark.rapids.GpuKryoRegistrator | 向 Kryo 注册 RAPIDS 序列化类 |
spark.resources.discoveryPlugin | com.nvidia.spark.ExclusiveModeGpuDiscoveryPlugin | GPU 资源发现插件,自动探测节点上可用的 GPU 设备 |
spark.driver.extraClassPath | ./rapids-4-spark_2.12-25.12.1-SNAPSHOT-cuda12.jar | 让 plugin jar 在 driver 上优先加载(避免 classloader 顺序问题);jar 文件名按实际版本替换 |
spark.executor.extraClassPath | ./rapids-4-spark_2.12-25.12.1-SNAPSHOT-cuda12.jar | 让 plugin jar 在 executor 上优先加载;jar 文件名按实际版本替换 |
spark.rapids.sql.allowMultipleJars | SAME_REVISION | 允许 classpath 上出现多份同 revision 的 RAPIDS jar(cluster 模式下常见),SAME_REVISION 为默认值 |
Executor 资源配置
配置项 | 推荐取值 | 说明 |
spark.executor.instances | 根据集群 GPU 节点数与每节点 GPU 数确定 | Executor 数量,(一个 executor 独占 1 块 GPU) |
spark.executor.cores | 20 | 每个 Executor 占用的 CPU 核数 |
spark.executor.memory | 18g | 堆内存,与 memoryOverhead 按约 1:3 分配 |
spark.executor.memoryOverhead | 54g | Off-Heap 内存 |
spark.executor.resource.gpu.amount | 1 | 每个 Executor 固定占用 1 块 GPU |
spark.executor.resource.gpu.discoveryScript | ./getGpusResources.sh | GPU 发现脚本(YARN 模式必填),需通过 --files 分发到 executor 工作目录 |
spark.task.resource.gpu.amount | 0.05 | 每个 task 占用的 GPU 资源份额,按 1 / spark.executor.cores 设置(20 cores 对应 0.05),让 cores 数即为 task 并发数;GPU 真正的并发由 concurrentGpuTasks 控制 |
spark.yarn.resourceGpuDeviceName | gpu | 告知 YARN GPU 资源名 |
- | --files /usr/local/service/spark/examples/src/main/scripts/getGpusResources.sh | 分发 GPU 发现脚本到 executor 工作目录 |
RAPIDS GPU 内存与并发
配置项 | 推荐取值 | 说明 |
spark.rapids.memory.pinnedPool.size | 10G | Pinned Memory 池大小,加速 host↔device 数据传输 |
spark.rapids.memory.host.offHeapLimit.enabled | true | 开启 RAPIDS host off-heap 总上限控制 |
spark.rapids.memory.host.offHeapLimit.size | - | host off-heap 总上限,建议略小于 memoryOverhead(例如 53g < 54g) |
spark.rapids.sql.concurrentGpuTasks | 2~4 | 同一 GPU 上同时执行的 Task 数,需根据显存调整;过大易出现 GPU OOM 或抢占抖动 |
Shuffle 相关
配置项 | 推荐取值 | 说明 |
spark.shuffle.manager | com.nvidia.spark.rapids.spark353.RapidsShuffleManager | 启用 RAPIDS Shuffle Manager,类名中间的 spark353 必须与 Spark 版本严格一致(Spark 3.3.x → spark33x,Spark 3.5.3 → spark353) |
spark.shuffle.service.enabled | false | 必须关闭外部 shuffle 服务(ESS)。RAPIDS Shuffle Manager 的内存路径与多线程优化都依赖此前提 |
spark.rapids.shuffle.multiThreaded.writer.threads | - | MULTITHREADED 模式下 shuffle 的写线程数,建议 ≈ executor.cores 或 略高于它 |
spark.rapids.shuffle.multiThreaded.reader.threads | - | MULTITHREADED 模式下 shuffle 的读线程数,建议 ≈ executor.cores 或 略高于它 |
spark.io.compression.codec | zstd | 中间数据(shuffle、广播)压缩算法,zstd 压缩比/速度最均衡,推荐 |
文件读取相关(针对云存储优化)
配置项 | 推荐取值 | 说明 |
spark.rapids.sql.format.parquet.reader.type | MULTITHREADED | 强制使用多线程 Parquet reader。云存储/对象存储(cosn/s3/oss)场景设为 MULTITHREADED 可显著提升吞吐;本地 HDFS 可保持默认 AUTO |
spark.rapids.sql.multiThreadedRead.numThreads | 100~200 | 多线程 reader 的线程池大小,经验值 = executor.cores × 2~4:I/O 等待重的对象存储可上调到 100~200;本地 HDFS 一般 40~80 就够;过大会增加上下文切换开销 |
spark.rapids.filecache.enabled | true | 开启输入文件本地缓存(仅 Parquet 生效)。热数据反复扫描场景强烈建议开启,缺省占用 spark local dirs 一半磁盘空间,可用 spark.rapids.filecache.maxBytes 限制上限 |
完整提交示例
spark-submit --master yarn --deploy-mode cluster \\--conf spark.plugins=com.nvidia.spark.SQLPlugin \\--conf spark.kryo.registrator=com.nvidia.spark.rapids.GpuKryoRegistrator \\--conf spark.resources.discoveryPlugin=com.nvidia.spark.ExclusiveModeGpuDiscoveryPlugin \\--conf spark.executor.instances=2 \\--conf spark.driver.cores=8 \\--conf spark.driver.memory=16g \\--conf spark.driver.maxResultSize=4g \\--conf spark.executor.cores=20 \\--conf spark.executor.memory=18g \\--conf spark.executor.memoryOverhead=54g \\--conf spark.sql.shuffle.partitions=200 \\--conf spark.sql.files.maxPartitionBytes=2g \\--conf spark.executor.resource.gpu.amount=1 \\--conf spark.yarn.resourceGpuDeviceName=gpu \\--conf spark.executor.resource.gpu.discoveryScript=./getGpusResources.sh \\--conf spark.task.resource.gpu.amount=0.05 \\--conf spark.rapids.sql.explain=NONE \\--conf spark.rapids.memory.pinnedPool.size=10G \\--conf spark.rapids.sql.concurrentGpuTasks=3 \\--conf spark.shuffle.manager=com.nvidia.spark.rapids.spark353.RapidsShuffleManager \\--conf spark.driver.extraClassPath=/rapids-4-spark_2.12-25.12.1-SNAPSHOT-cuda12.jar \\--conf spark.executor.extraClassPath=/rapids-4-spark_2.12-25.12.1-SNAPSHOT-cuda12.jar \\--conf spark.rapids.sql.allowMultipleJars=SAME_REVISION \\--conf spark.rapids.shuffle.multithreaded.writer.threads=30 \\--conf spark.rapids.shuffle.multithreaded.reader.threads=30 \\--conf spark.shuffle.service.enabled=false \\--conf spark.rapids.sql.multithreadedRead.numThreads=200 \\--conf spark.rapids.sql.format.parquet.reader.type=MULTITHREADED \\--conf spark.rapids.filecache.enabled=true \\--conf spark.rapids.memory.host.offHeapLimit.enabled=true \\--conf spark.rapids.memory.host.offHeapLimit.size=53g \\--conf spark.io.compression.codec=zstd \\--files /usr/local/service/spark/examples/src/main/scripts/getGpusResources.sh \\<your-application-jar> [application-arguments]
注意:
jar 文件名 rapids-4-spark_2.12-25.12.1-SNAPSHOT-cuda12.jar 请根据实际版本替换。
若需访问 Hive 元数据,可追加:
--conf spark.sql.catalogImplementation=hive --conf spark.hadoop.hive.metastore.uris=thrift://<host>:<port>验证 GPU 加速是否生效
提交任务后,可通过 Spark UI 查看执行计划:
若算子显示 Gpu 前缀(如
GpuFilter、GpuHashAggregate),表示 GPU 加速已生效在 Spark UI 的 Executors 页面,可查看各 Executor 的 GPU 资源分配情况
使用限制与注意事项
1. 算子兼容性:Spark-RAPIDS 支持大部分 SQL 算子,但不支持的算子会自动回退到 CPU 原生执行。详细信息参见 官方兼容性文档。
2. 浮点数精度:GPU 计算的浮点数结果可能与 CPU 存在微小差异,这是 GPU 并行计算的正常特性。
3. GPU 独占性:在不支持 MIG 的 GPU 卡上,一张物理卡只能由一个 Executor 独占。可通过配置 spark.rapids.sql.concurrentGpuTasks 在同一 Executor 内实现高并发。
4. 数据格式支持:目前支持 Parquet、Iceberg,Delta Lake 格式的 GPU 加速读取。
5. 混合部署场景:在混合(CPU+GPU)节点组上提交 Spark-RAPIDS 任务时,需确保任务被调度到 GPU 节点。建议通过节点标签或 YARN 队列进行隔离。
详细参考文档
NVIDIA Spark-RAPIDS 官方 Tuning Guide
NVIDIA Spark-RAPIDS 官方 Configuration
腾讯云 EMR 产品文档



