开发准备
确定您已经开通了腾讯云,并且创建了一个 EMR 集群。在创建 EMR 集群的时候,需要在软件配置界面选择 spark_hadoop 组件。
Spark 安装在 EMR 云服务器的
/usr/local/service 路径下(/usr/local/service/spark)。拷贝 jar 包
需要将
spark-<version>-yarn-shuffle.jar 拷贝到集群各个节点的 /usr/local/service/hadoop/share/hadoop/yarn/lib 目录路径下。方法一:SSH 控制台操作
1. 在集群服务 > YARN 组件中,选择操作 > 角色管理,确定 NodeManager 所在节点 IP。
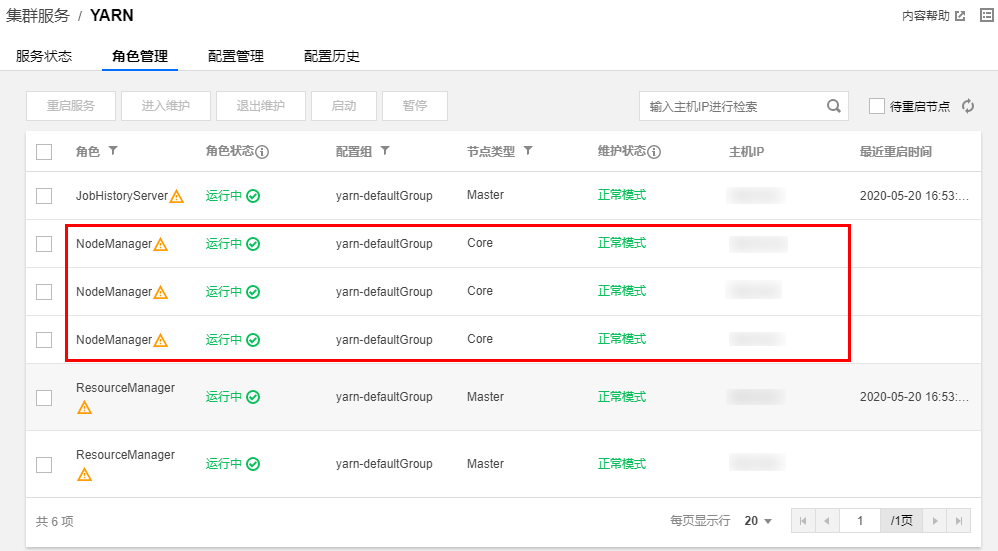
2. 依次登录每个 NodeManager 所在节点。
首先,需要登录 EMR 集群中的任意机器,最好是登录到 Master 节点。登录 EMR 的方式请参考 登录 Linux 实例,这里我们可以使用 XShell 登录 Master 节点。
使用 SSH 登录到其他 NodeManager 所在节点。指令为
ssh $user@$ip,$user 为登录的用户名,$ip 为远程节点 IP(即步骤1中确定的 IP 地址)。
验证已经成功切换。
3. 搜索 
spark-<version>-yarn-shuffle.jar 文件路径。
4. 将 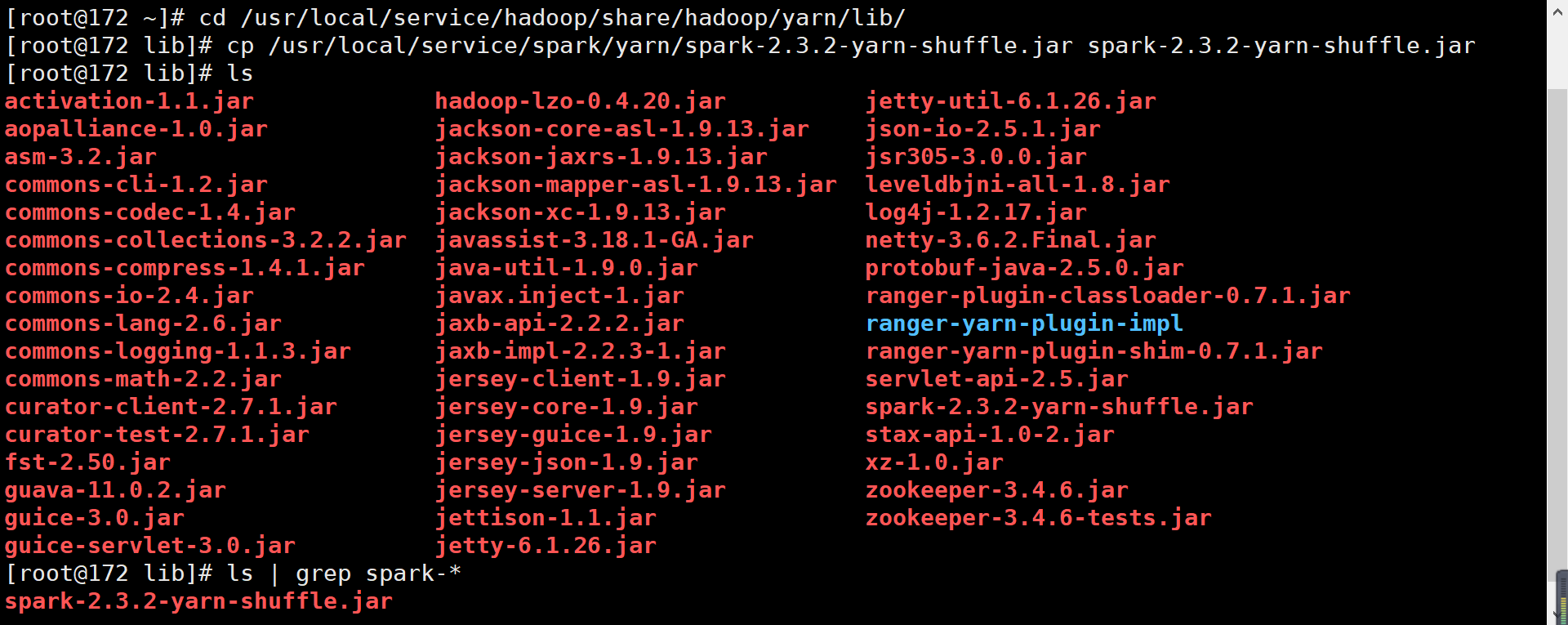
spark-<version>-yarn-shuffle.jar 拷贝到 /usr/local/service/hadoop/share/hadoop/yarn/lib 下。
5. 退出登录,并切换其余节点。

方法二:批量部署脚本
首先,需要登录 EMR 集群中的任意机器,最好是登录到 Master 节点。登录 EMR 的方式请参考 登录 Linux 实例,这里我们可以使用 XShell 登录 Master 节点。
编写如下批量传输文件的 Shell 脚本。当集群节点很多时,为了避免多次输入密码,可以使用 sshpass 工具传输。sshpass 的优势在于可以免密传输避免多次输入,但其缺点在于密码是明文容易暴露,可以使用 history 命令找到。
1. 免密,安装 sshpass。
[root@172 ~]# yum install sshpass
编写如下脚本:
#!/bin/bashnodes=(ip1 ip2 … ipn) #集群各节点 IP 列表,空格分隔len=${#nodes[@]}password=<your password>file=" spark-2.3.2-yarn-shuffle.jar "source_dir="/usr/local/service/spark/yarn"target_dir="/usr/local/service/hadoop/share/hadoop/yarn/lib"echo $lenfor node in ${nodes[*]}doecho $node;sshpass -p $password scp "$source_dir/$file"root@$node:"$target_dir";done
2. 非免密。
编写如下脚本:
#!/bin/bashnodes=(ip1 ip2 … ipn) #集群各节点 IP 列表,空格分隔len=${#nodes[@]}password=<your password>file=" spark-2.3.2-yarn-shuffle.jar "source_dir="/usr/local/service/spark/yarn"target_dir="/usr/local/service/hadoop/share/hadoop/yarn/lib"echo $lenfor node in ${nodes[*]}doecho $node;scp "$source_dir/$file" root@$node:"$target_dir";done
修改 Yarn 配置
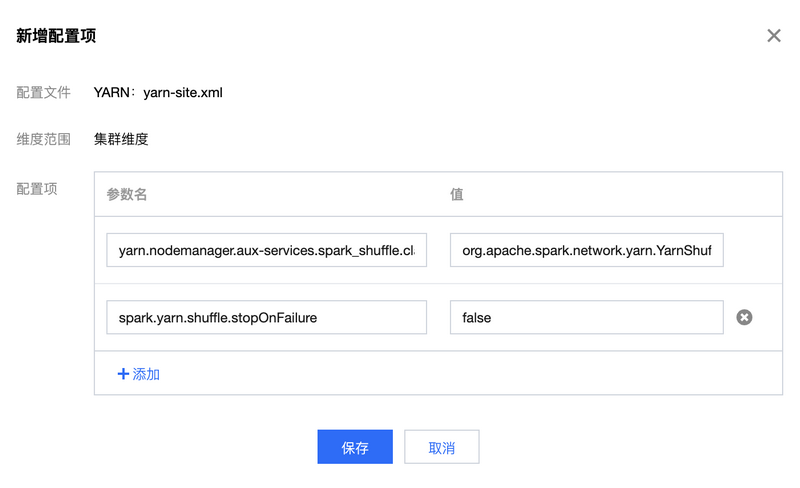
1. 在集群服务 > YARN组件中,选择操作 > 配置管理。选中配置文件 yarn-site.xml,维度范围选择“集群维度”(集群维度的配置项修改将应用到所有节点),然后单击编辑配置。
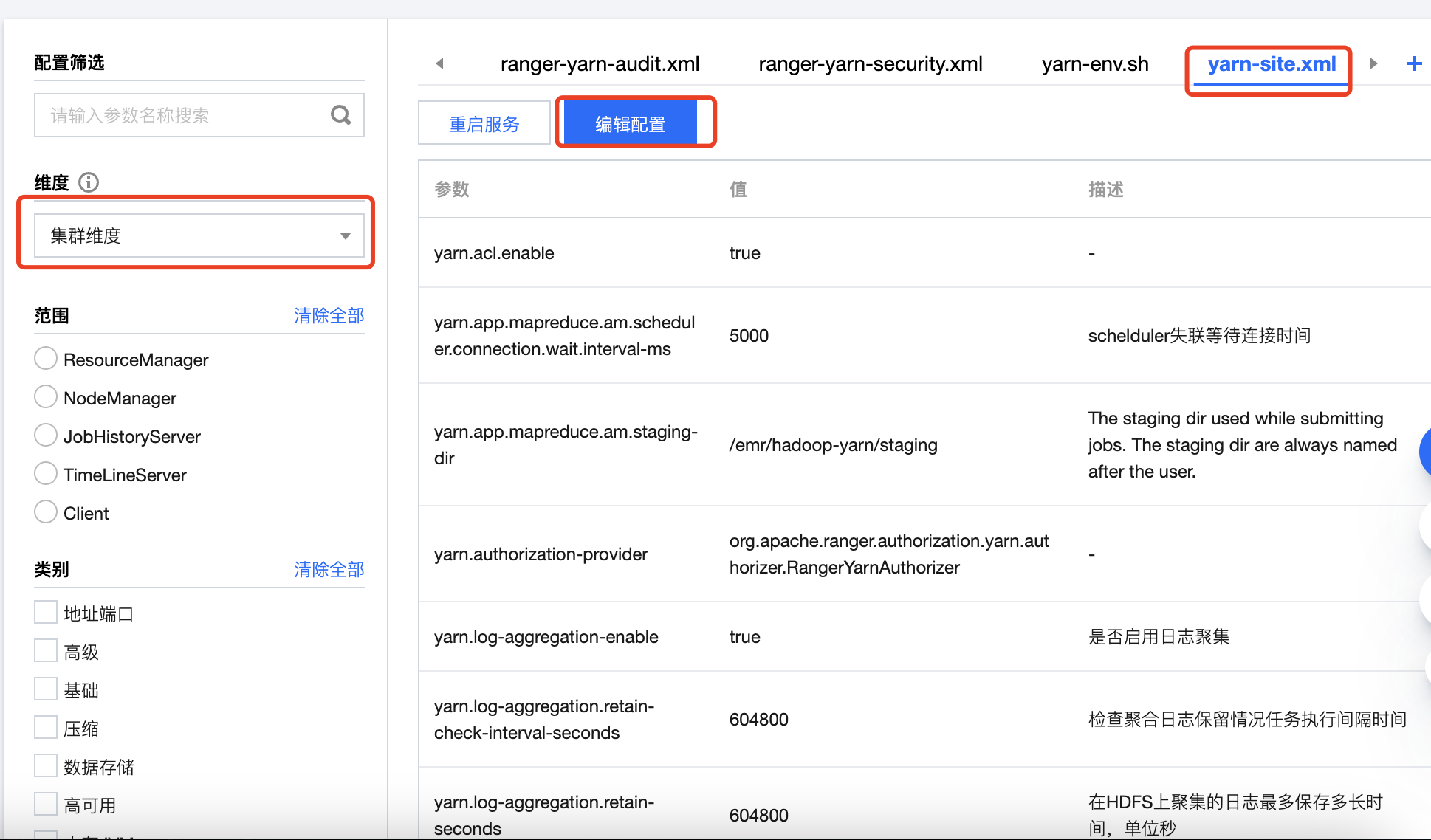
2. 修改配置项 
yarn.nodemanager.aux-services,添加 spark_shuffle。
3. 新增配置项 yarn.nodemanager.aux-services.spark_shuffle.class,该配置项的值设置为 org.apache.spark.network.yarn.YarnShuffleService。
4. 新增配置项 spark.yarn.shuffle.stopOnFailure,该配置项的值设置为 false。
5. 保存设置并下发,重启 YARN 组件使得配置生效。
修改 Spark 配置
1. 在集群服务 > SPARK组件中,选择操作 > 配置管理。
2. 选中配置文件“spark-defaults.conf”,单击编辑配置。新建配置项如下:
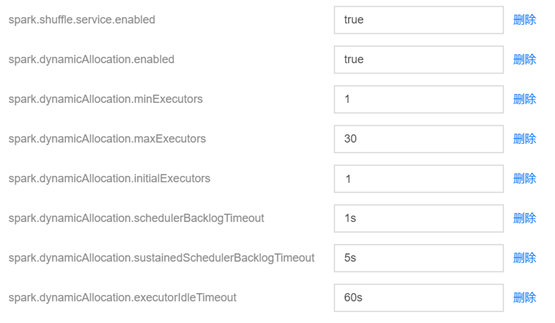
配置项 | 值 | 备注 |
spark.shuffle.service.enabled | true | 启动 shuffle 服务。 |
spark.dynamicAllocation.enabled | true | 启动动态资源分配。 |
spark.dynamicAllocation.minExecutors | 1 | 每个 Application 最小分配的 executor 数。 |
spark.dynamicAllocation.maxExecutors | 30 | 每个 Application 最大分配的 executor 数。 |
spark.dynamicAllocation.initialExecutors | 1 | 一般情况下与 spark.dynamicAllocation.minExecutors 值相同。 |
spark.dynamicAllocation.schedulerBacklogTimeout | 1s | 已有挂起的任务积压超过此持续事件,则将请求新的执行程序。 |
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout | 5s | 带处理任务队列依然存在,则此后每隔几秒再次出发,每轮请求的 executor 数目与上轮相比呈指数增长。 |
spark.dynamicAllocation.executorIdleTimeout | 60s | Application 在空闲超过几秒钟时会删除 executor。 |
3. 保存配置、下发并重启组件。
测试 Spark 资源动态调整
1. 测试环境资源配置说明
测试环境下,共两个部署 NodeManager 服务的节点,每个节点资源配置为4核 CPU、8GB内存,集群总资源为8核 CPU、16GB内存。
2. 测试任务说明
测试一:
在 EMR 控制台中,进入
/usr/local/service/spark 目录,切换 hadoop 用户,使用 spark-submit 提交一个任务,数据需存储在 hdfs 上。[root@172 ~]# cd /usr/local/service/spark/[root@172 spark]# su hadoop[hadoop@172 spark]$ hadoop fs -put ./README.md /[hadoop@172 spark]$ spark-submit --class org.apache.spark.examples.JavaWordCount --master yarn --num-executors 10 --driver-memory 4g --executor-memory 4g --executor-cores 2 ./examples/jars/spark-examples_2.11-2.3.2.jar /README.md /output
在 YARN 组件的 WebUI 界面 Application 面板中,可以观察到配置前后容器和 CPU 分配情况。

未设置资源动态调度前,CPU 最多分配个数为3。

设置资源动态调度后,CPU 最多分配个数为5。
结论:配置资源动态调度后,调度器会根据应用程序的需要动态地增加分配的资源。
测试二:
在 EMR 控制台中,进入
/usr/local/service/spark 目录,切换 hadoop 用户,使用 spark-sql 启动 SparkSQL 交互式控制台。交互式控制台被设置成占用测试集群的大部分资源,观察设置资源动态调度前后资源分配情况。[root@172 ~]# cd /usr/local/service/spark/[root@172 spark]# su hadoop[hadoop@172 spark]$ spark-sql --master yarn --num-executors 5 --driver-memory 4g --executor-memory 2g --executor-cores 1
使用 spark2.3.0 自带的计算圆周率的 example 作为测试任务,提交任务时将任务的 executor 数设置为5,driver 内存设置为4g,executor 内存设置为4g,executor 核数设置为2。
[root@172 ~]# cd /usr/local/service/spark/[root@172 spark]# su hadoop[hadoop@172 spark]$ spark-submit --class org.apache.spark.examples.SparkPi --master yarn --num-executors 5 --driver-memory 4g --executor-memory 4g --executor-cores 2 examples/jars/spark-examples_2.11-2.3.2.jar 500

只运行 SparkSQL 任务时资源占用率90.3%。

提交 SparkPi 任务后,SparkSQL 资源占用率27.8%。
结论:SparkSQL 任务虽然在提交时申请了大量资源,但并未执行任何分析任务,因此实际上有大量空闲的资源。当超过
spark.dynamicAllocation.executorIdleTimeout 设置时间时,空闲的 executor 被释放,其他任务获得资源。在本次测试中 SparkSQL 任务的集群资源占用率从90%降至28%,空闲资源分配给圆周率计算任务,自动调度有效。说明
配置项
spark.dynamicAllocation.executorIdleTimeout 的值将影响资源动态调度的快慢,测试发现资源调度用时基本与该值相等,建议您根据实际需求调整该配置项的值以获得最佳性能。


