Apache Kudu 是一个分布式,可水平扩展的列式存储系统,它完善了 Hadoop 的存储层,可对快速变化数据进行快速分析。
Kudu 基本特点
高效处理类 OLAP 负载。
与 MapReduce、Spark 以及 Hadoop 生态系统中其他组件进行友好集成。
可与 Impala 集成,替代目前 Impala 常用的 HDFS + Parquet 组合。
灵活的一致性模型。
顺序写和随机写并存的场景下,仍能达到良好的性能。
高可用,使用 Raft 协议保证数据高可靠存储。
结构化数据模型。
Kudu 使用场景
适用于那些既有随机访问,也有批量数据扫描的复合场景。
高计算量的场景。
实时预测模型的应用,支持根据所有历史数据周期地更新模型。
支持数据更新,避免数据反复迁移。
支持跨地域的实时数据备份和查询。
Kudu 基本架构
Kudu 包含如下两种类型的组件:
master 主要负责管理元数据信息、监听 server,当 server 宕机后负责 tablet 的重分配。
tserver 主要负责 tablet 的存储与数据的增删改查。
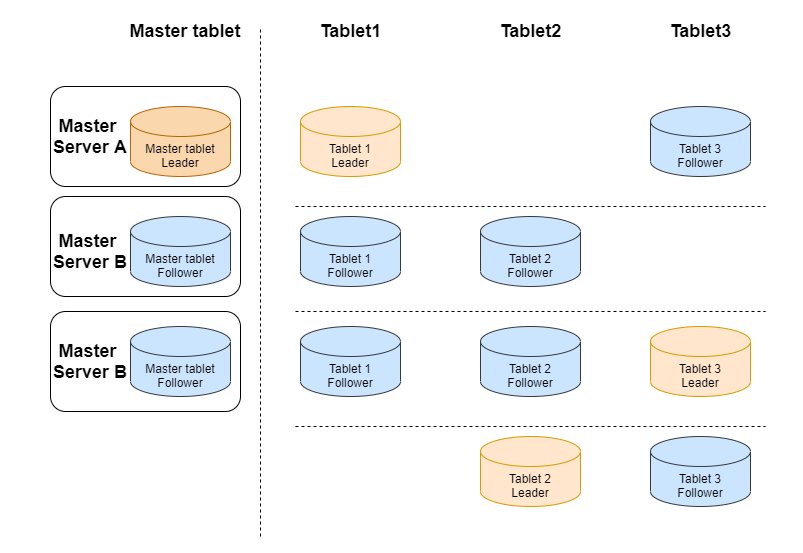
Kudu 使用
EMR-2.4.0版本以上支持了 Kudu 组件。在创建 Hadoop 集群时勾选 Kudu 组件,即会创建 Kudu 集群。默认情况下 Kudu 集群包含3个 Kudu Master 服务并开启 HA。
说明
以下 Kudumaster_ip1、Kudumaster_ip2、Kudumaster_ip3 所用到的 IP 为 KuduMaster 角色所在节点内网 IP。
Impala 与 Kudu 集成
参考 Impala 简介 内容进入到 Impala 命令行,执行以下命令新建表格:
CREATE TABLE t2(id BIGINT,name STRING,PRIMARY KEY(id))PARTITION BY HASH PARTITIONS 2 STORED AS KUDU TBLPROPERTIES ('kudu.master_addresses' = '$Kudumaster_ip1,$Kudumaster_ip2,$Kudumaster_ip3','kudu.num_tablet_replicas' = '1');
成功后返回以下提示信息:
Query: create TABLE t2 (id BIGINT,name STRING,PRIMARY KEY(id)) PARTITION BY HASH PARTITIONS 2 STORED AS KUDU TBLPROPERTIES ('kudu.master_addresses' = '$Kudumaster_ip1,$Kudumaster_ip2,$Kudumaster_ip3','kudu.num_tablet_replicas' = '1')Fetched 0 row(s) in 0.12s
输入以下命令可查看已创建表格:
usr/local/service/kudu/bin/kudu table list $Kudumaster_ip1,$Kudumaster_ip2,$Kudumaster_ip3
数据插入
在 Impala 命令行,执行以下命令向表中插入数据:
insert into t2 values(1, 'test');
基于 Impala 查询数据
在 Impala 命令行,执行以下命令查询表中数据:
[172.30.0.98:27001] > select * from t2;
可查询到表中已插入数据
其他命令
集群健康检测
[hadoop@172 root]$ /usr/local/service/kudu/bin/kudu cluster ksck 172.30.0.240,172.30.1.167,172.30.0.96,172.30.0.94,172.30.0.214
创建表
[hadoop@172 root]$ /usr/local/**service**/**kudu**/bin/kudu table create '172.30.0.240,172.30.1.167,172.30.0.96,172.30.0.94,172.30.0.214' '{"table_name":"test","schema":{"columns":[{"column_name":"id","column_type":"INT32","default_value":"1"},{"column_name":"key","column_type":"INT64","is_nullable":false,"comment":"range key"},{"column_name":"name","column_type":"STRING","is_nullable":false,"comment":"user name"}],"key_column_names":["id","key"]},"partition":{"hash_partitions":[{"columns":["id"],"num_buckets":2,"seed":100}],"range_partition":{"columns":["key"],"range_bounds":[{"upper_bound":{"bound_type":"inclusive","bound_values":["2"]}},{"lower_bound":{"bound_type":"exclusive","bound_values":["2"]},"upper_bound":{"bound_type":"inclusive","bound_values":["3"]}}]}},"extra_configs":{"configs":{"kudu.table.history_max_age_sec":"3600"}},"num_replicas":1}'
查询创建的 test 表
[hadoop@172 root]$ /usr/local/service/kudu/bin/kudu table list 172.30.0.240,172.30.1.167,172.30.0.96,172.30.0.94,172.30.0.214test
查看表结构
[hadoop@172 root]$ /usr/local/service/kudu/bin/kudu table describe 172.30.0.240,172.30.1.167,172.30.0.96,172.30.0.94,172.30.0.214 testTABLE test (id INT32 NOT NULL,key INT64 NOT NULL,name STRING NOT NULL,PRIMARY KEY (id, key))HASH (id) PARTITIONS 2 SEED 100,RANGE (key) (PARTITION VALUES < 3,PARTITION 3 <= VALUES < 4)REPLICAS 1



