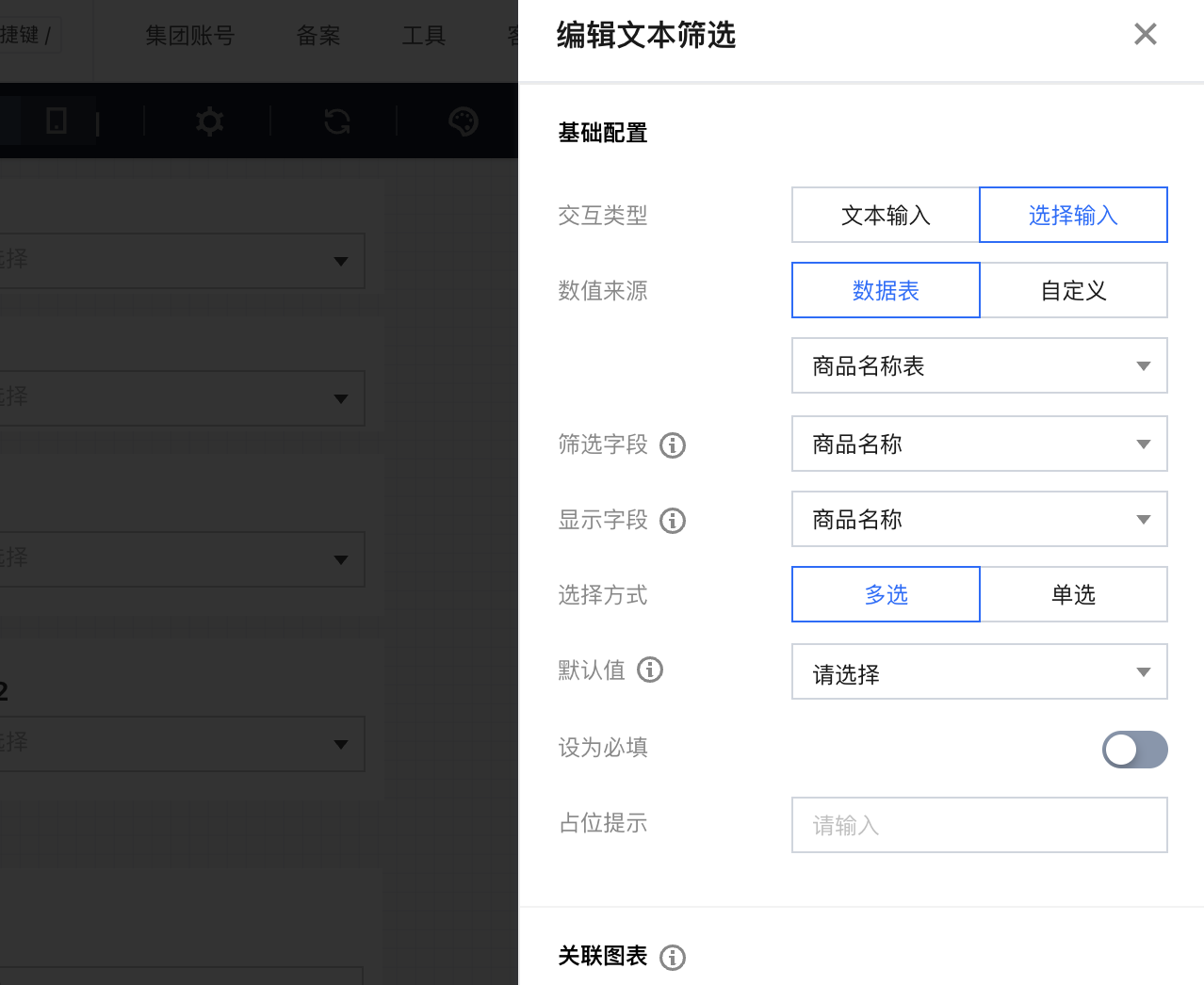
下拉筛选器列表来源于数据表时,需要从数据表里查询并聚合结果后,载入到筛选器。导致如下图,载入下拉列表时间可能过长甚至失败。
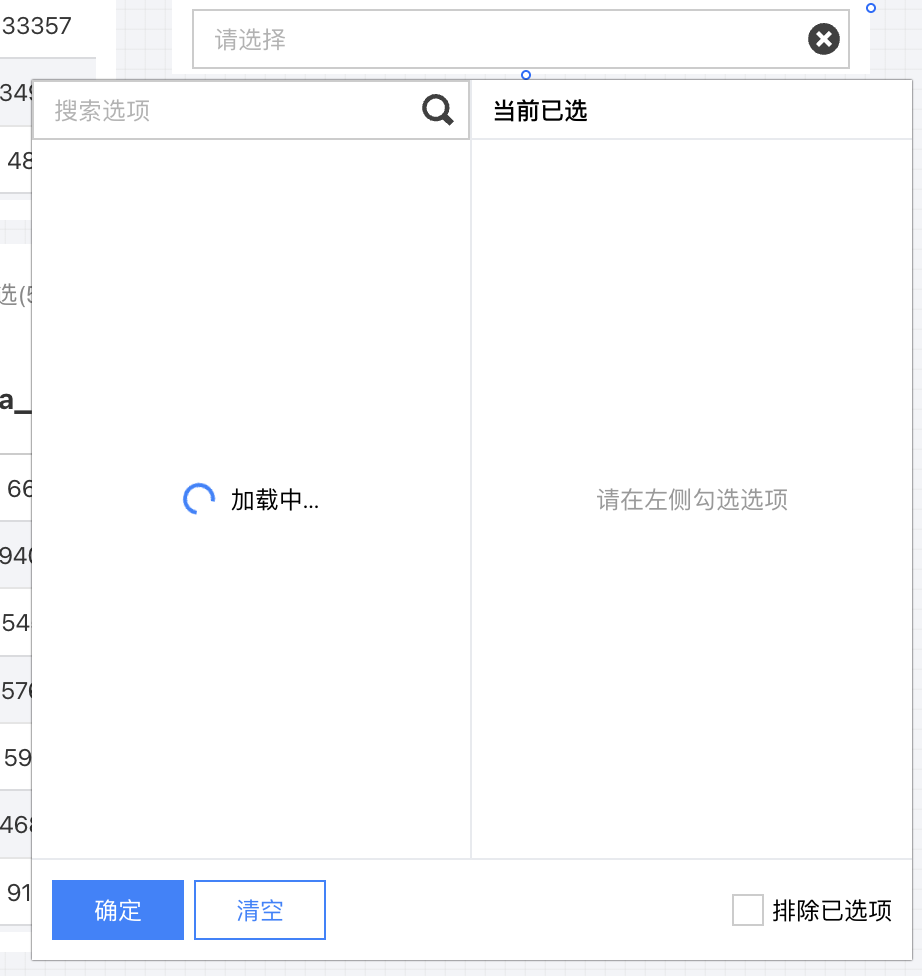
当存在以下情况时,可能引起筛选器加载缓慢:
查询数据太多:例如底表有100万行订单数据,我们需要筛选省份,则需要先查询100万数据,然后聚合出30多个省份;
结果数据太多:例如底表有100万行订单数据,我们需要筛选销售员,则每次数据库输出5万行销售员数据,传输到 BI 服务需要较长的时间。
因此,优化思路从以下角度展开:
减少服务的查询:能不去请求列表的尽量不请求,适合字段值比较固定的场景,如选择月份、省市,这种相对固定的字段;
减少数据库的查询:能不去查询数据的尽量不去查询数据库,适合字段值实时性不高的场景,如选择部门列表,这种不需要每次去数据库查;
减少数据量的查询:能不查明细的尽量不去查明细,适合字段值较多,但实时性不高的场景,如选择供应商列表,这种不需要每次查询百万级数据。
以上,可根据实际情况选择其中一种或多种进行优化。
减少服务查询:使用手工输入静态值
适用场景:列表值比较少,值比较固定,如选择省;
优劣势:
优势:不用查询,图表加载出来数据即加载完成;
劣势:非动态,如新增值需要手工维护。
操作指引:
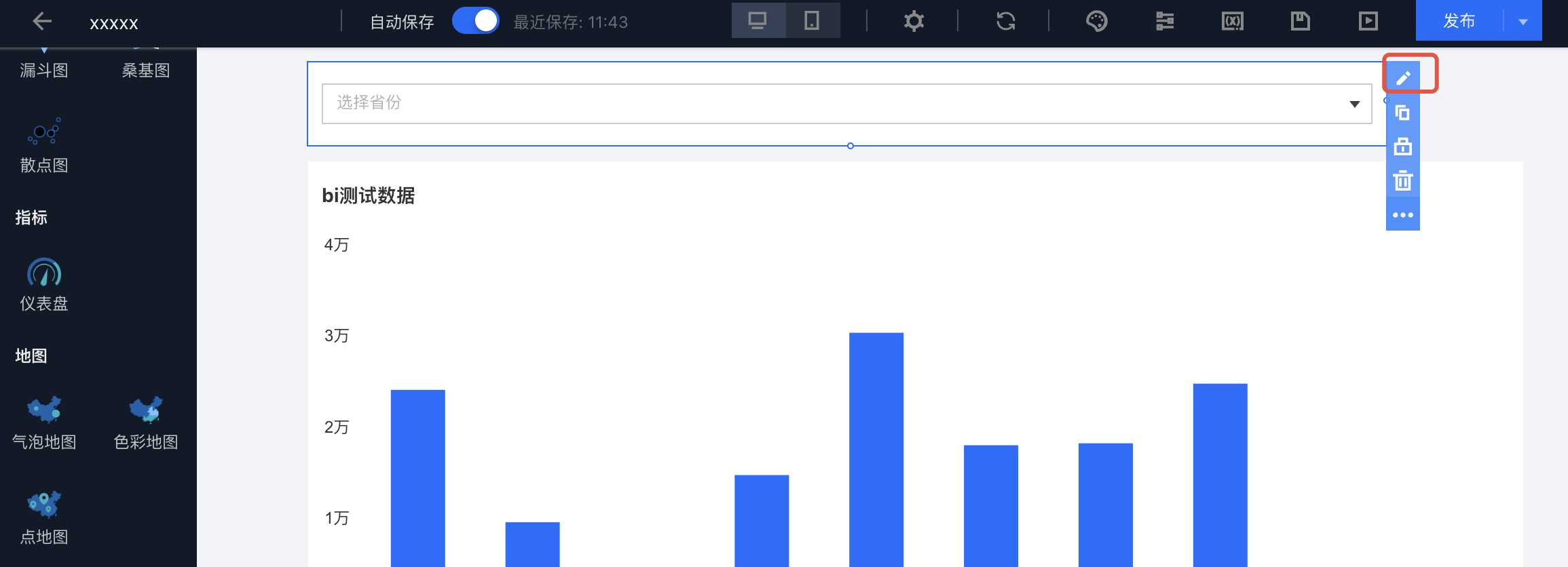
1. 进入筛选器编辑:
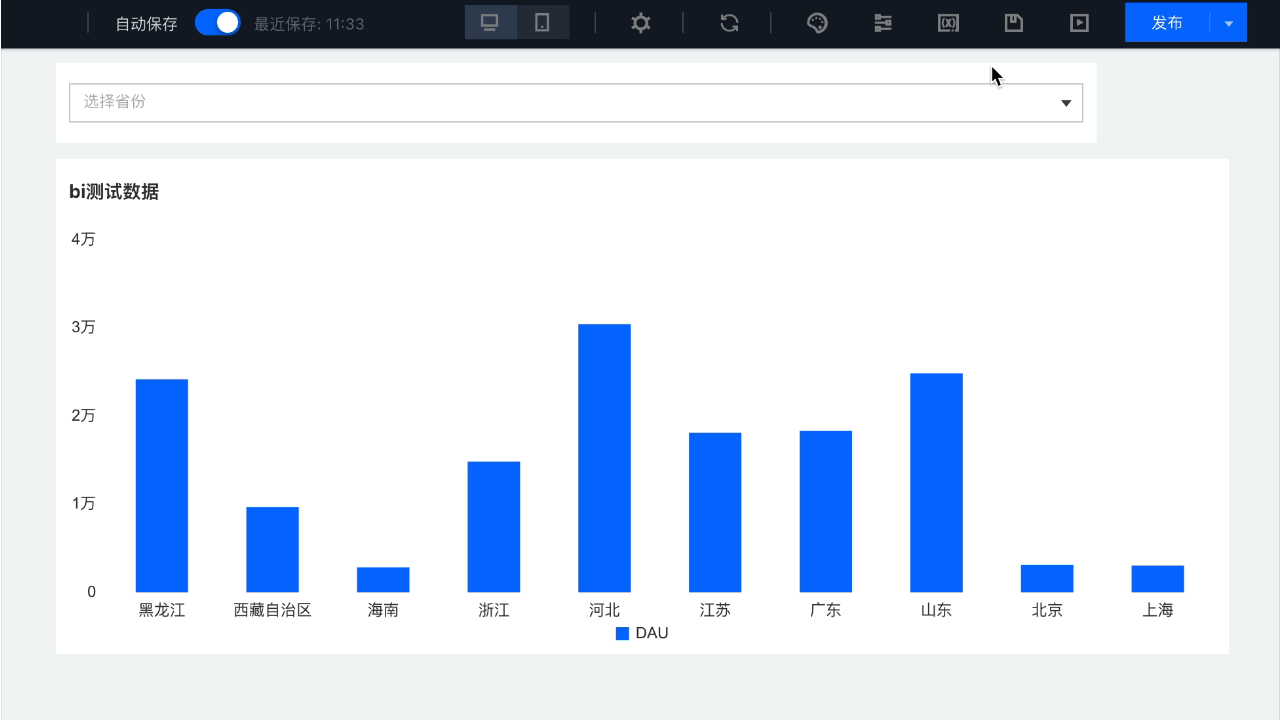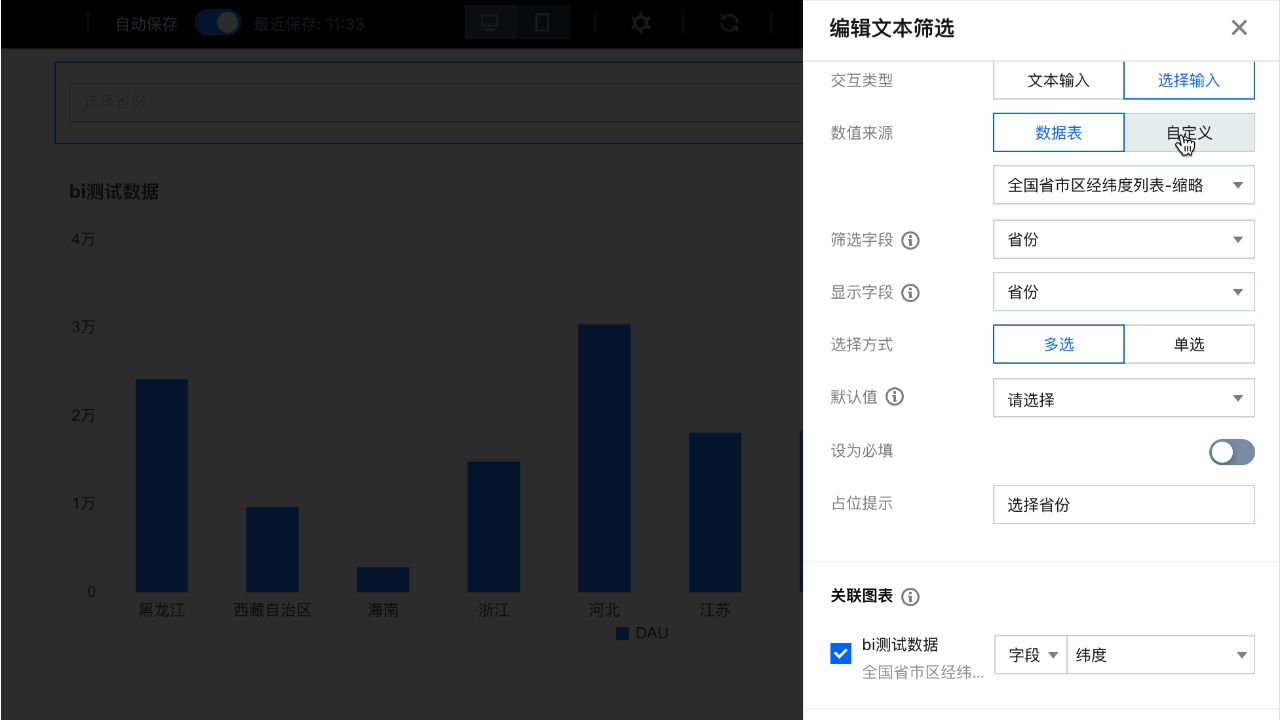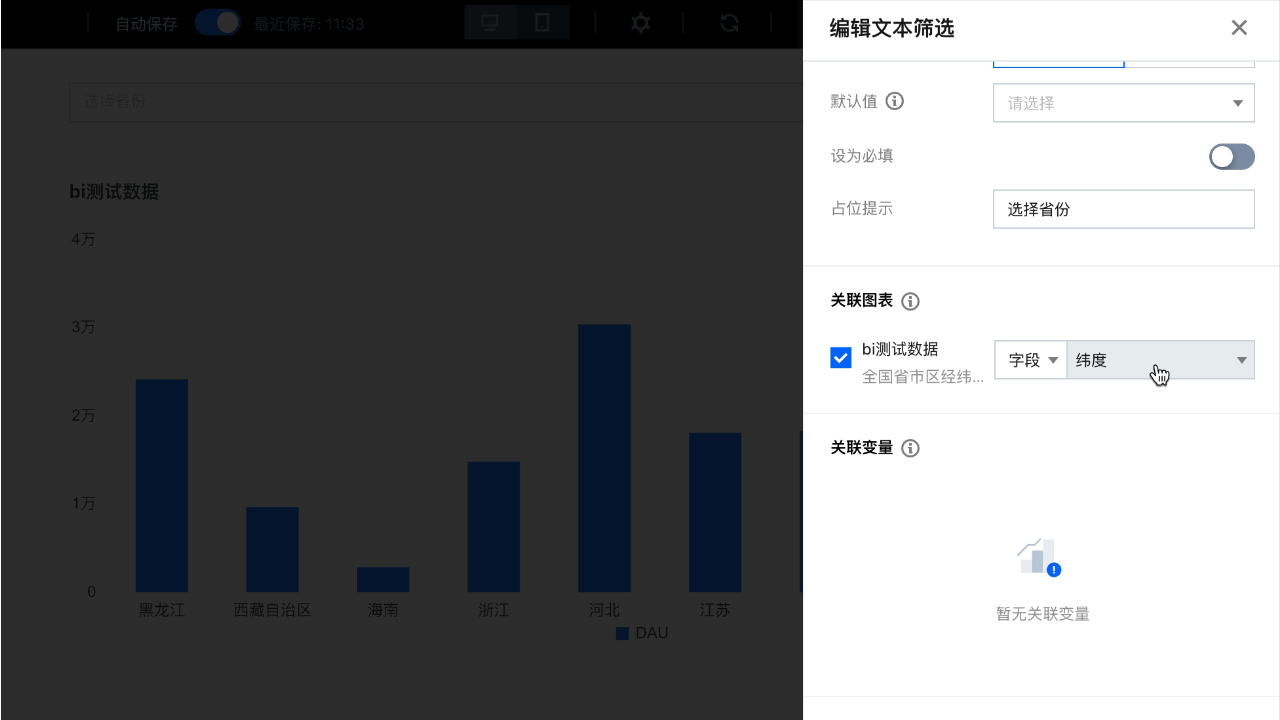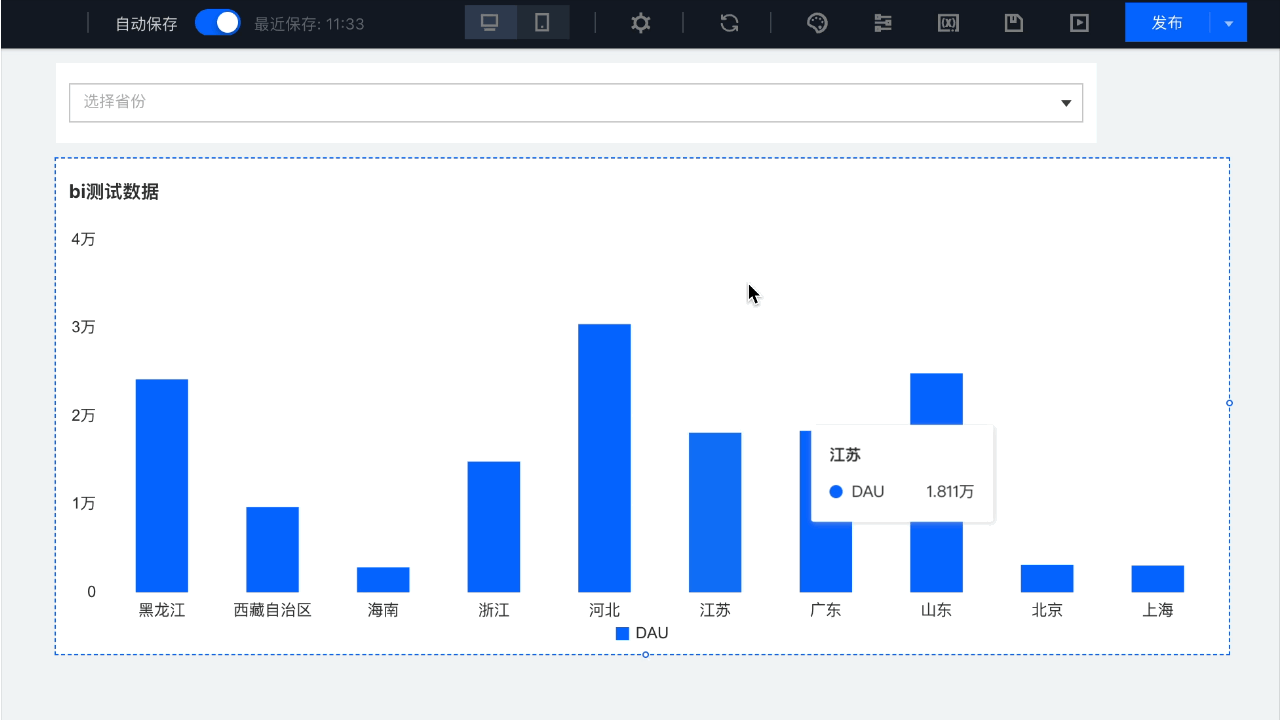
2. 设置数据来源为“自定义”:
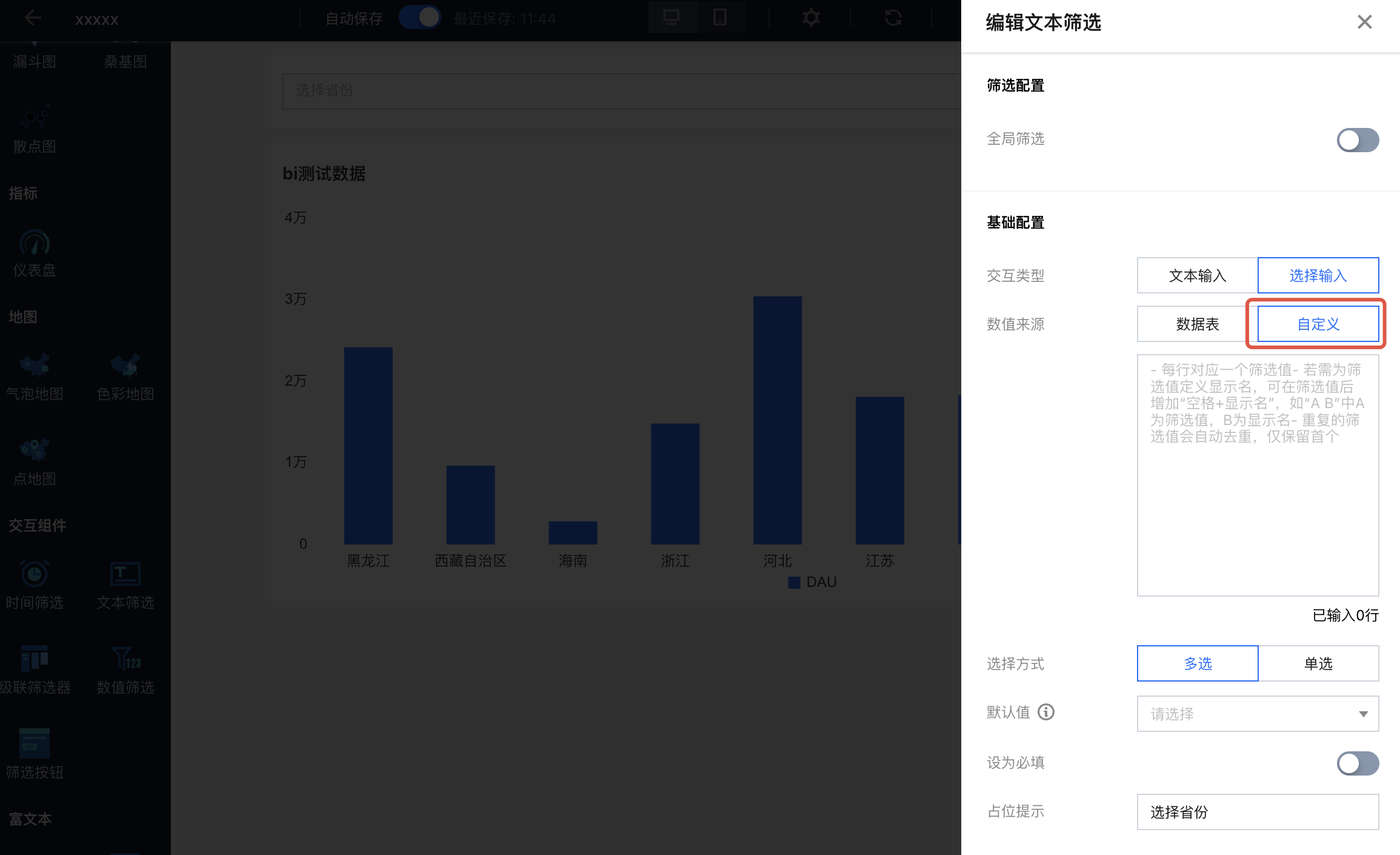
3. 设置下拉选项值:
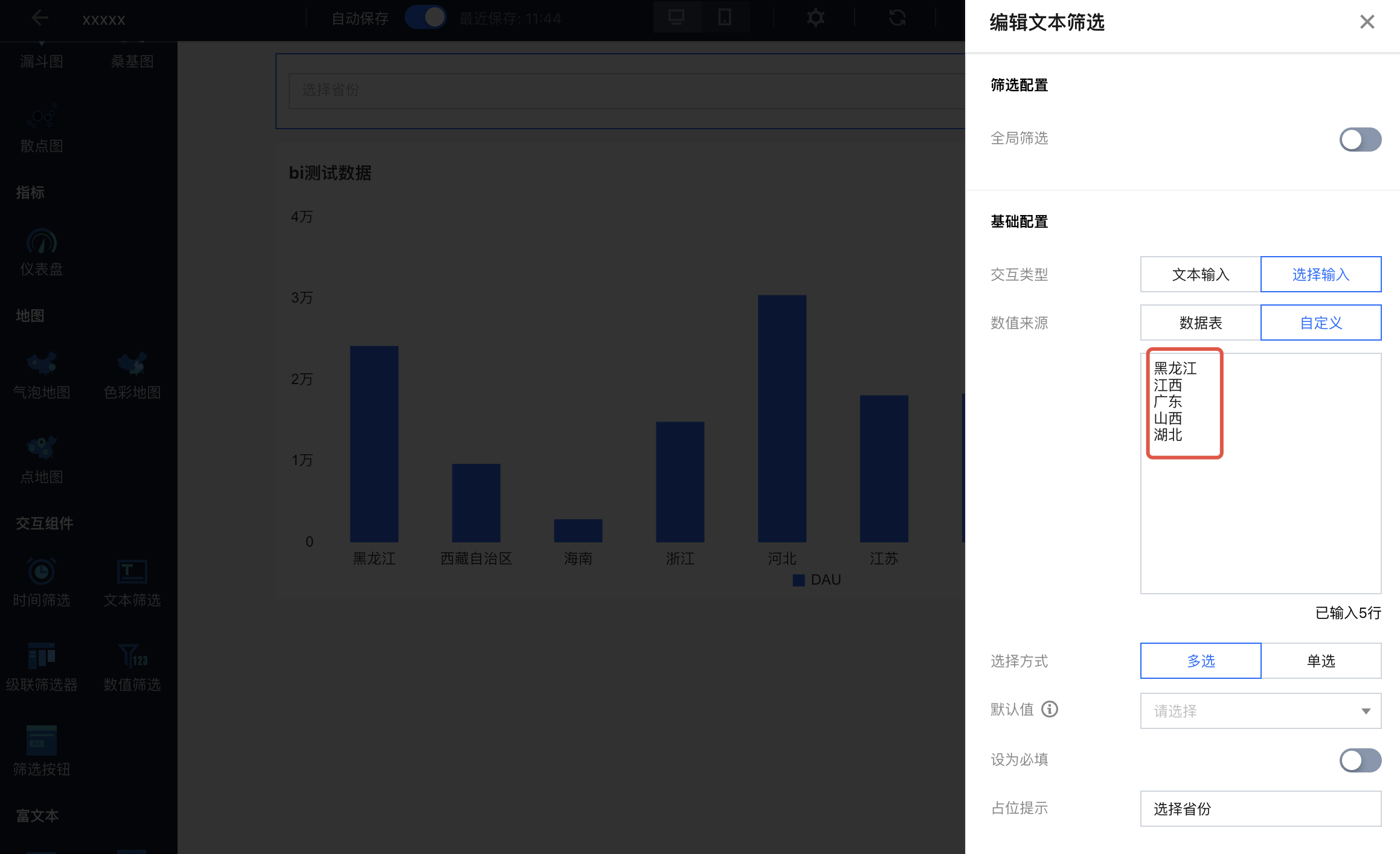
4. 保存后生效。
减少数据库的查询:使用筛选器缓存
适用场景:列表值不需要实时数据,可定期更新的,如选择供应商;
优劣势:
优势:相同查询条件,比直接查询快很多;
劣势:第一次加载依然会很慢; 如果查询条件发生变化,则会需要重建缓存导致比较慢。
操作指引:

1. 进入筛选器,在menubar里选择“缓存与刷新”:
2. 开启缓存,并设置缓存频率为 每天的 08:00(即在明早8点前,都无需发起查询)
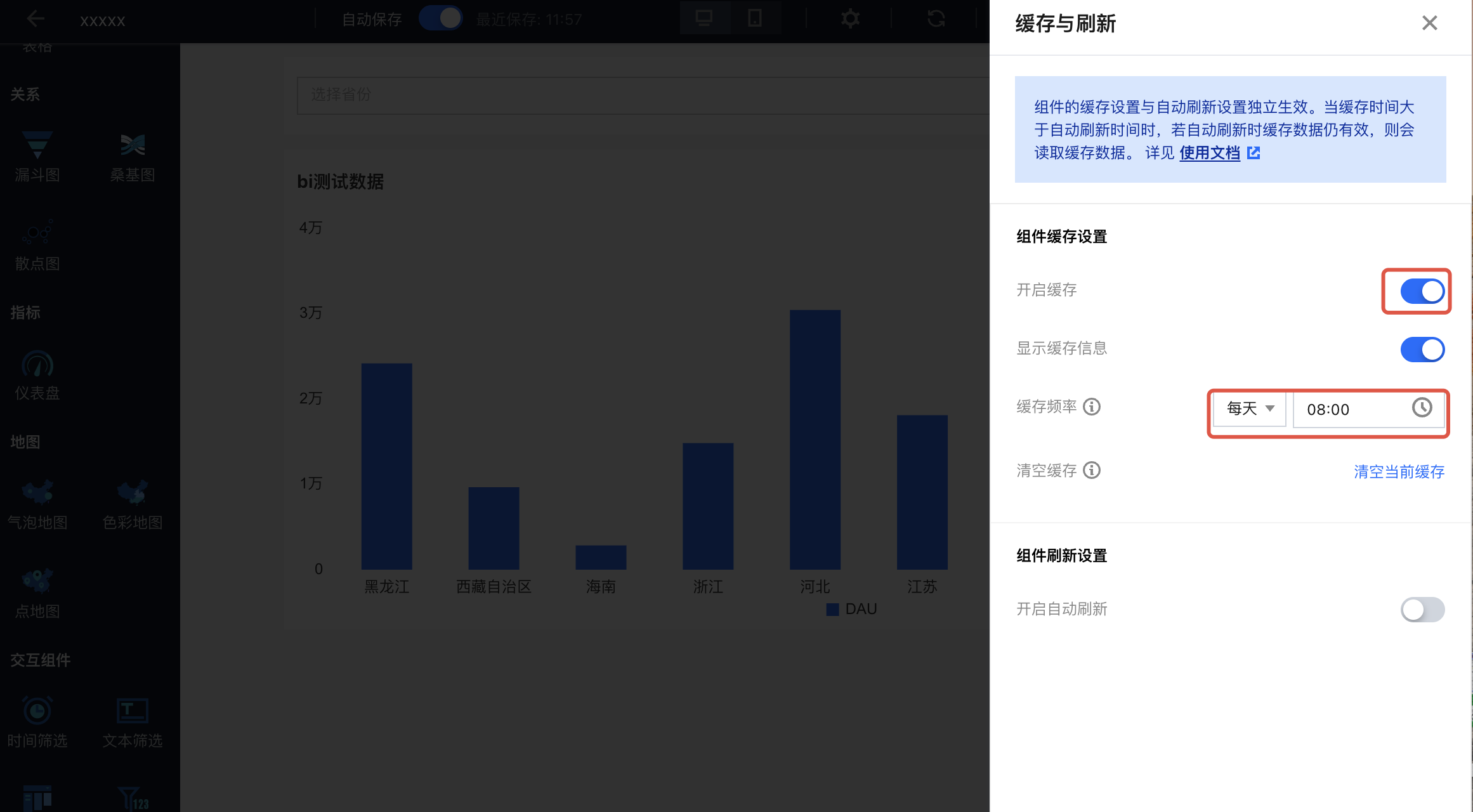
3. 保存后生效。
减少数据量的查询:定期维护维表
适用场景:列表值不需要实时数据,可定期更新的,如选择商品;
优劣势:
优势:减少数据库压力,减少明细查询时间;
劣势:需要数据工程师操作。
操作指引:
1. 在数据库中建一张实体表,如下示例代码,生成一张mysql表:
-- 创建商品维度表CREATE TABLE dim_list (id INT AUTO_INCREMENT PRIMARY KEY,product_name VARCHAR(255) NOT NULL COMMENT '商品名称',create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',UNIQUE KEY (product_name) -- 确保商品名称唯一) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品维度表';-- 初始化数据INSERT INTO dim_list (product_name)SELECT DISTINCT 商品名称FROM order_tabWHERE 商品名称 IS NOT NULLON DUPLICATE KEY UPDATE product_name = VALUES(product_name);
* 以上代码,从订单明细表 order_tab 里取出“商品名称”字段,生成商品名称的维表 dim_list。
2. 创建定时任务,定时执行数据更新:
-- 创建存储过程DELIMITER //CREATE PROCEDURE update_dim_list()BEGININSERT INTO dim_list (product_name)SELECT DISTINCT 商品名称FROM order_tabWHERE 商品名称 IS NOT NULLAND 商品名称 NOT IN (SELECT product_name FROM dim_list)ON DUPLICATE KEY UPDATE product_name = VALUES(product_name);END //DELIMITER ;-- 设置定时任务(每天8点执行)CREATE EVENT IF NOT EXISTS daily_dim_list_updateON SCHEDULE EVERY 1 DAY STARTS '2025-05-17 08:00:00'DO CALL update_dim_list();
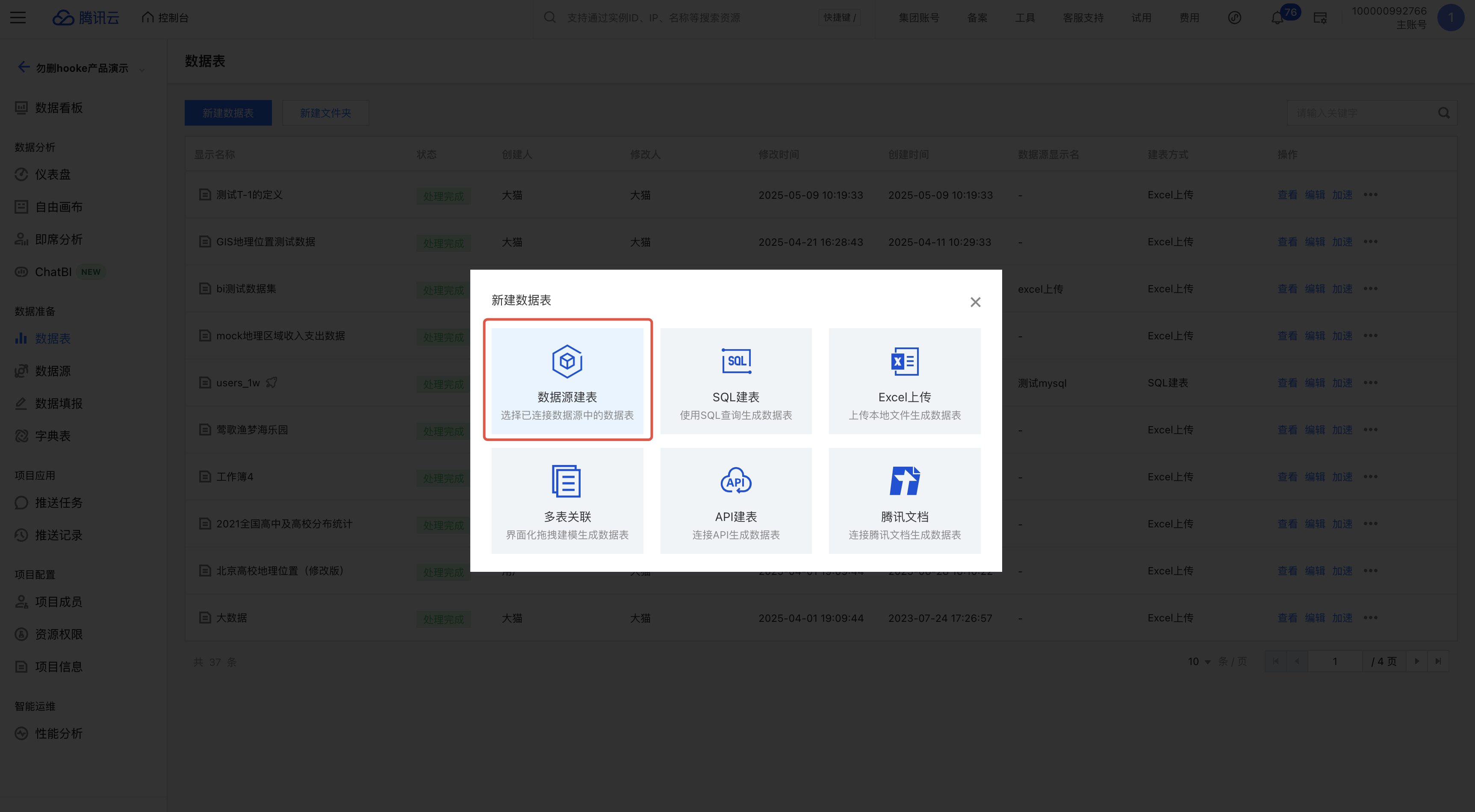
3. 在 BI 里创建数据源和数据表,连接以上已创建的 dim_list 表(以下以数据表为例):
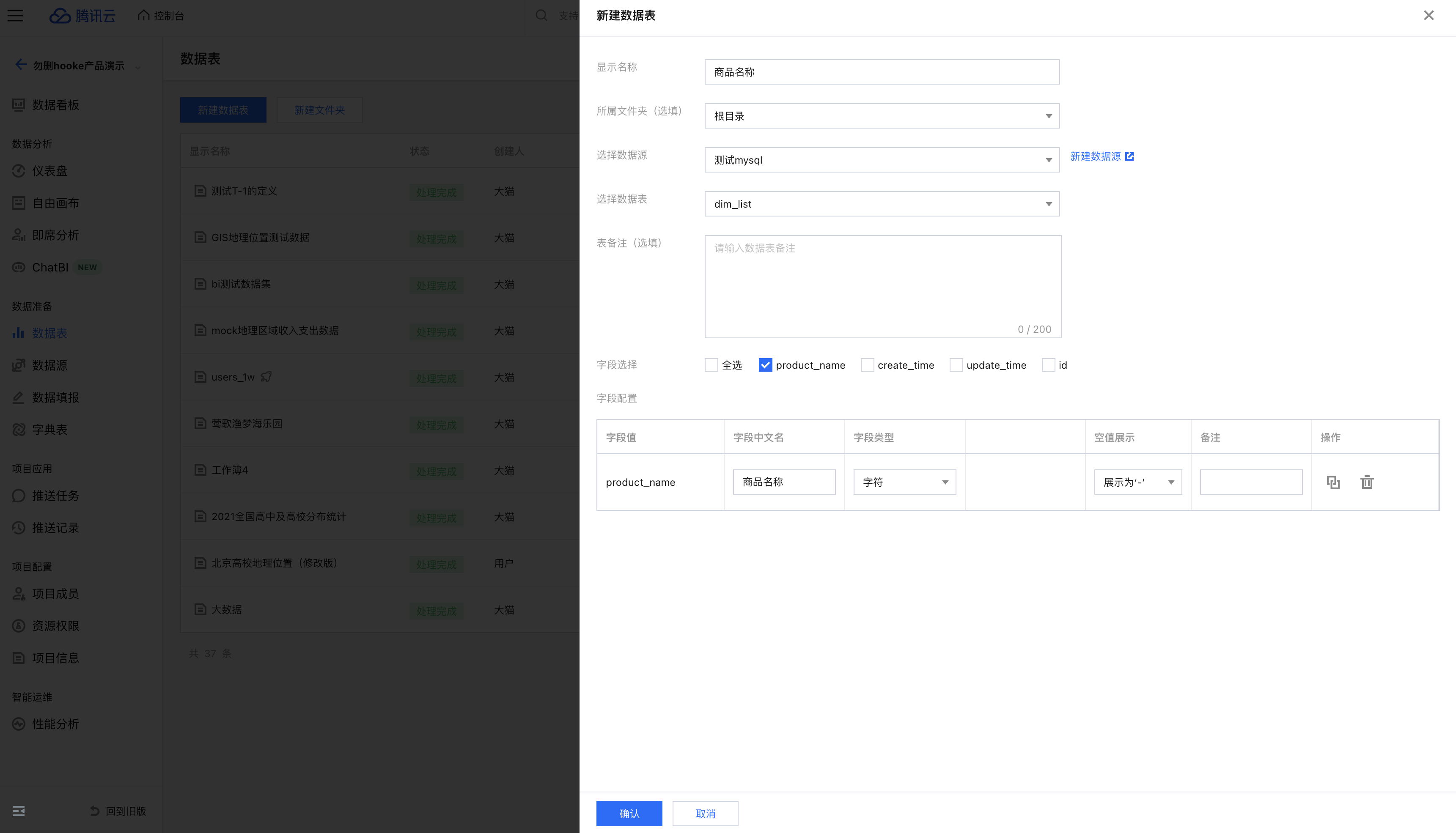
4. 筛选器关联数据表的商品名称字段: