架构说明
消息队列 CKafka 版的架构图如下所示:
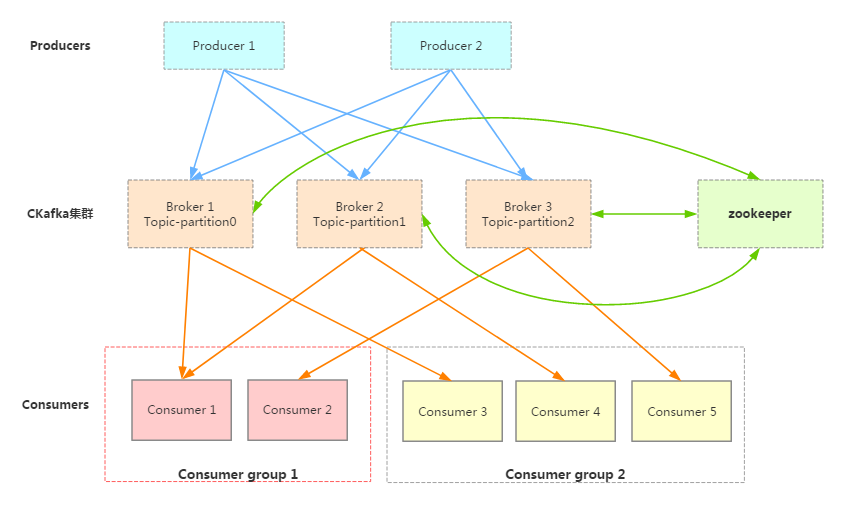
Producer
消息的生产者,生产的消息可能是网页活动产生的消息、服务日志等信息。生产者通过 push 模式将消息发布到 CKafka 的 Broker 集群。
CKafka 集群
Broker:存储消息的服务器,Broker支持水平扩展,节点数量越多,集群吞吐率越高。
Partition:分区,一个 Topic 可以有多个 Partition,每个 Partition 在物理上对应一个文件夹,用于存储该 Partition 中的消息和索引文件。Partition 可以有多个副本,提升可用性,但也会增加存储和网络开销。
Zookeeper:负责集群的配置管理、leader选举、故障容错等。
Consumer
消息消费者,Consumer 被划分为若干个 Consumer Group,消费者通过 pull 模式从 Broker 中消费消息。
架构原理说明
高吞吐
消息队列 CKafka 版中存在大量的网络数据持久化到磁盘和磁盘文件通过网络发送的过程。这一过程的性能直接影响 Kafka 的整体吞吐量,主要通过以下几点实现:
高效使用磁盘:磁盘中顺序读写数据,提高磁盘利用率。
写 message:消息写到 page cache,由异步线程刷盘。
读 message:消息直接从 page cache 转入 socket 发送出去。
当从 page cache 没有找到相应数据时,此时会产生磁盘 IO,从磁盘加载消息到 page cache,然后直接从 socket 发出去。
Broker 的零拷贝(Zero Copy)机制:使用 sendfile 系统调用,将数据直接从页缓存发送到网络上。
减少网络开销
数据压缩降低网络负载。
批处理机制:Producer 批量向 Broker 写数据、Consumer 批量从 Broker 拉数据。
数据持久化
消息队列 CKafka 版的数据持久化主要通过如下原理实现:
Topic 中 Partition 存储分布
在消息队列 CKafka 版文件存储中,同一 Topic 有多个不同 Partition,每个 Partition 在物理上对应一个文件夹,用于存储该 Partition 中的消息和索引文件。例如,创建两个 Topic,Topic1 中存在5个 Partition,Topic2 中存在10个 Partition,则整个集群上会相应生成5 + 10 = 15个文件夹。
Partition 中文件存储方式
Partition 物理上由多个 segment 组成,每个 segment 大小相等,顺序读写,快速删除过期 segment, 提高磁盘利用率。
水平扩展(Scale Out)
一个 Topic 可包含多个 Partition,分布在一个或多个 Broker 上。
一个消费者可订阅其中一个或者多个 Partition。
Producer 负责将消息均衡分配到对应的 Partition。
Partition 内消息是有序的。
消费者分组(Consumer Group)
消息队列 CKafka 版不删除已消费的消息。
任何 Consumer 必须属于一个 Group。
同一 Consumer Group 中的多个 Consumer 不同时消费同一个 Partition。
不同 Group 同时消费同一条消息,多元化(队列模式、发布订阅模式)。



