随着业务的增长和数据流量的增加,CKafka 在生产者和消费者以极高的速度生产/消费大量数据或产生请求时,可能会导致 Broker 上资源的过度消耗,造成网络 IO 饱和等问题。为了避免这种情况对全量业务产生影响,CKafka 设计了一套完善的限流方案,对节点进行自我保护,避免因为资源消耗过高而影响全量业务。
限流能力概述
CKafka 当前支持以下限流能力:
限流类型 | 说明 |
集群级限流 | 根据实例购买的峰值带宽,对实例整体生产和消费流量进行保护。该能力由系统自动生效,无需用户手动配置。 |
Topic 级限流 | 支持为指定 Topic 配置生产或消费流量上限,避免单个 Topic 流量过高影响实例内其他业务。 |
用户/客户端级限流 | 支持按用户名、Client ID 或用户名 + Client ID 配置限流规则,控制指定接入方的流量占用,避免单个用户或客户端占用过多实例资源。 |
限流方案概述
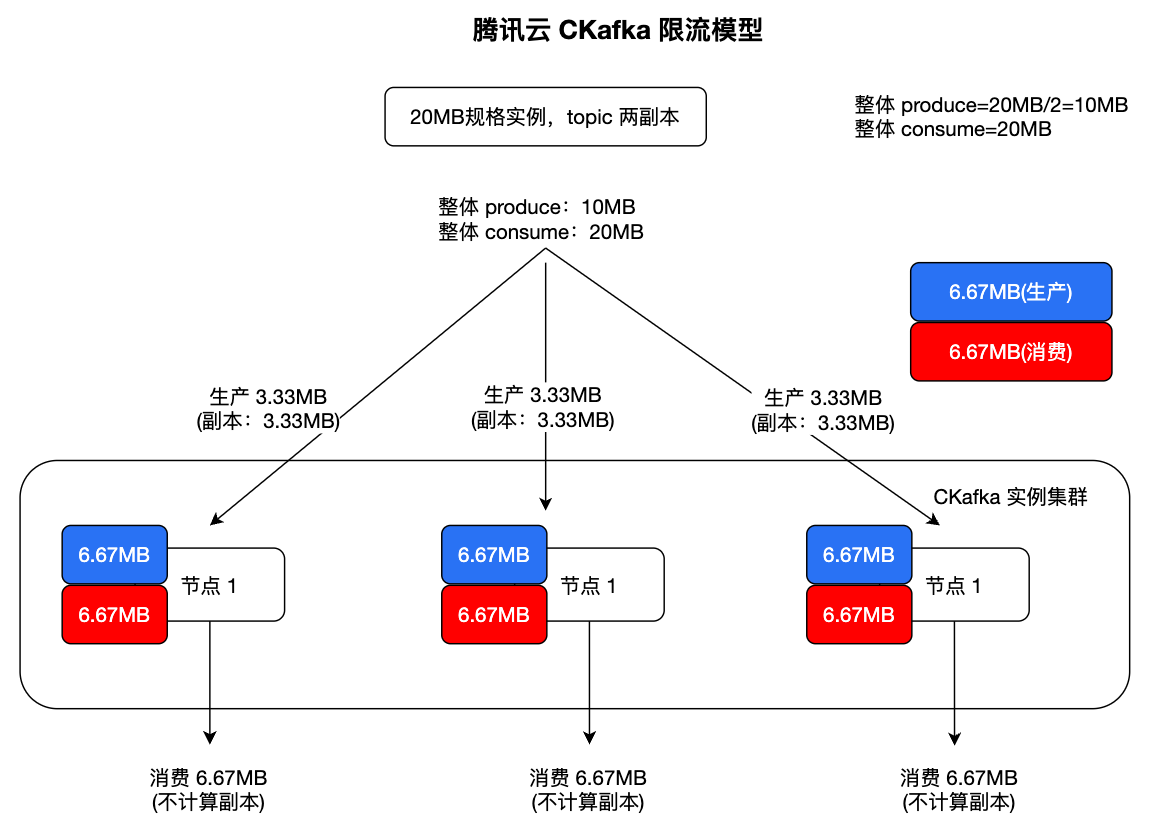
以购买带宽为 20 MB/s、Topic 副本数为 2、实例部署 3 个 Broker 节点为例:
生产流量:生产流量需要计算副本同步流量,因此业务侧可用生产带宽约为 20 MB/s ÷ 2 = 10 MB/s。
消费流量:消费流量通常只从 Leader 副本读取,不计算副本同步流量,因此整体消费带宽约为 20 MB/s。
节点流量:针对客户使用场景和需求,CKafka 至少为 3 节点部署。此时,限流额度会分配到各 Broker 节点。例如 3 个 Broker 节点时,每个节点约承载 6.67 MB/s 的生产(含副本,实际生产约3.33 MB/s)和消费限流额度。
带宽计算说明:
生产和消费的带宽计算方式不同。生产消息时,数据需要写入 Leader 副本,并同步到其他副本,副本同步会占用写入带宽;消费消息时,客户端通常只从 Leader 副本拉取数据,不涉及副本同步流量。因此,生产和消费的带宽限额计算方式如下:
生产最大带宽 = 购买带宽 ÷ 副本数
消费最大带宽 = 购买带宽
由于限流在 Broker 节点维度执行,如果 Topic 分区数较少,或流量集中在少数分区上,可能导致某个 Broker 节点提前触发限流。建议您将分区数设置为 Broker 节点数的整数倍(2-3倍或以上),使流量尽量均匀分布。
目前 CKafka 提供三种层级的限流能力,限流能力分别如下:
集群级限流
集群级限流基于实例购买的峰值带宽自动生效,无需手动配置。当实例整体生产或消费流量持续超过购买规格时,系统会自动触发限流保护,避免资源被持续打满。如果您购买的是专业版实例,可以开启弹性带宽,应对短时突发流量,降低因限流导致业务抖动的风险。
以购买带宽为 20 MB/s、3 个 Broker 节点的实例为例:
写入限流按副本同步后的总流量计算,实例整体写入流量上限约为 20 MB/s,即最多压测到的写流量(计算副本)为 20MB/s 附近。由于限流额度会分配到各 Broker 节点,单节点写入限流额度约为 6.67 MB/s。如果 Topic 为 2 副本,单分区写入时需要同时计算副本同步流量,业务侧单分区可写入流量约为 3.33 MB/s。
消费限流不计算副本同步流量,实例整体消费流量上限约为 20 MB/s,即最多压测到的消费流量(不计算副本)为 20MB/s 附近。在 3 个 Broker 节点均衡承载时,单节点消费限流额度约为 6.67 MB/s。
Topic 级限流
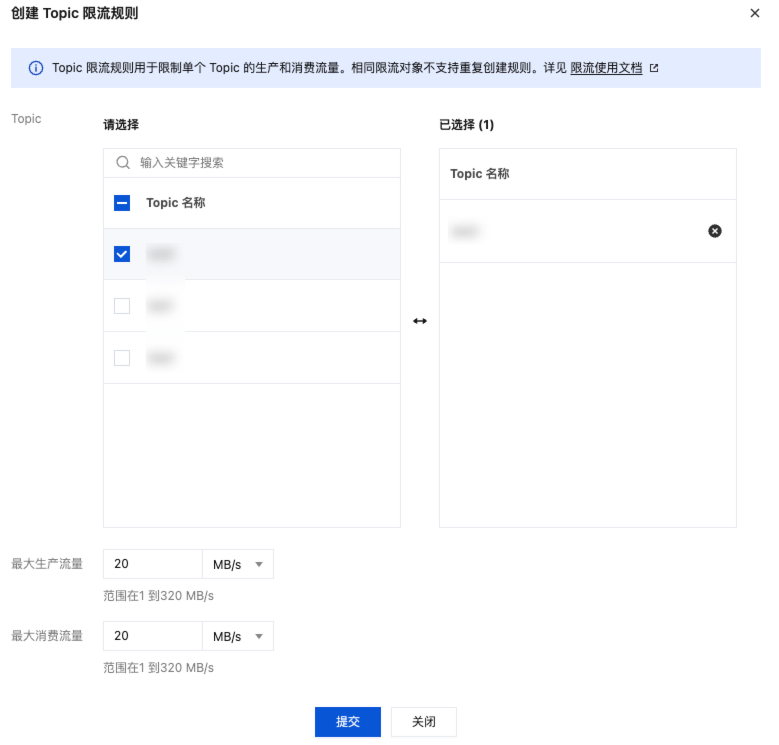
Topic 级限流用于控制指定 Topic 的生产或消费流量。例如您可以为 Topic:test (2 副本)配置:生产限流 20 MB/s(已计算副本),消费限流 20MB/s (不计算副本)。实际限流在 Broker 节点维度执行,分区分布不均时,可能出现实际限流值低于配置值的情况。
用户/客户端限流
用户/客户端级限流用于控制指定用户名或 Client ID 的流量占用,适合多业务、多客户端共用同一实例的场景。支持以下配置方式:
配置方式 | 说明 |
按用户名限流 | 该用户名下所有 Client ID 的流量之和超过阈值时触发限流。 |
按 Client ID 限流 | 该 Client ID 下所有用户的流量之和超过阈值时触发限流。 |
按用户名 + Client ID 限流 | 指定用户名和 Client ID 的流量超过阈值时触发限流。 |
通过用户/客户端级限流,可以避免单个接入方占用过多实例带宽,影响其他业务正常生产或消费。
限流机制说明
CKafka 采用软限流机制。即当流量超过限流阈值时,CKafka 通常不会直接向客户端返回错误,而是通过延迟回包的方式降低客户端请求速度,使流量逐步回落,避免突发流量直接造成业务报错。
硬限流和软限流
限流方式 | 说明 | 客户端表现 |
硬限流 | 流量超过阈值后,服务端直接拒绝请求并返回错误。 | 客户端需要感知错误,并根据业务逻辑进行重试或降级处理。 |
软限流 | 流量超过阈值后,服务端不直接拒绝请求,而是增加请求响应时间。 | 客户端请求变慢,整体发送或拉取速度下降,但通常不会直接收到错误。 |
例如,某服务限制调用频率为 100 次/秒,正常请求耗时为 10 ms:
如果采用硬限流,当客户端请求超过 100 次/秒 时,超出的请求会直接返回错误。
如果采用软限流,当客户端请求略高于阈值时,请求耗时可能从 10 ms 增加到 20 ms;当请求量继续升高时,请求耗时可能进一步增加到 50 ms 或更高。
对于 Kafka 这类高吞吐消息场景,软限流可以在流量突增时平滑降低客户端请求速度,减少因短时流量波动导致的报错和业务抖动。
延时回包限流原理
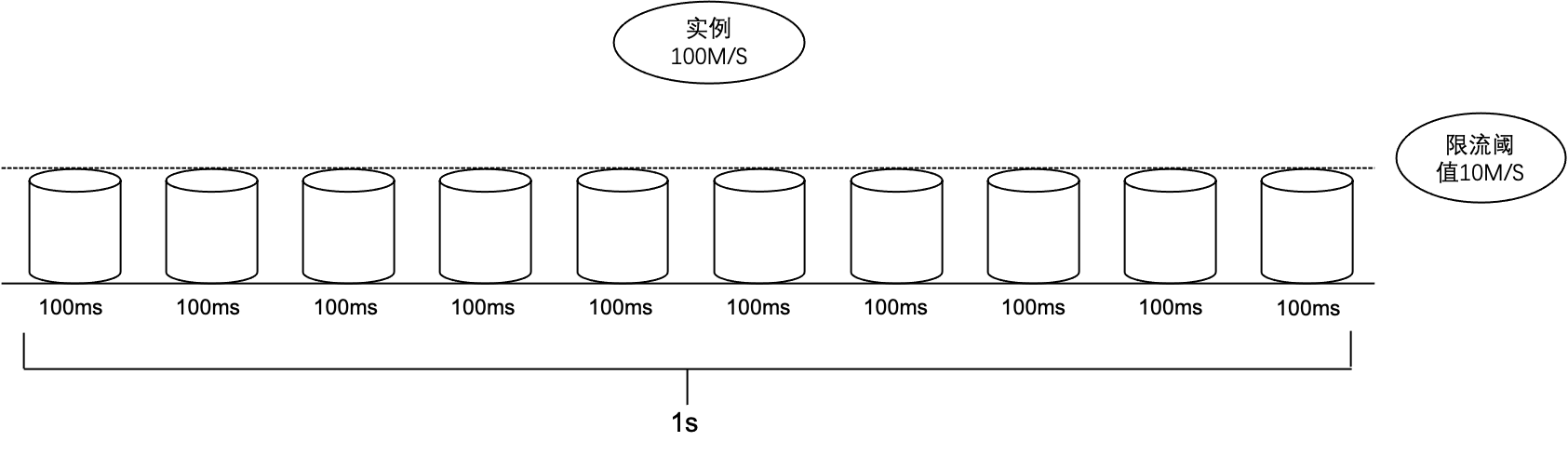
CKafka 底层限流机制基于令牌桶原理实现。系统会将 1 秒划分为多个更小的时间窗口,并为每个时间窗口分配对应的流量额度。
限流策略会把每秒(1000ms)均分为若干个时间桶。例如分为10个时间桶,每个桶的时间则为100ms。每个时间桶的限流阈值就是总实例规格速度的1/10。如果某个时间窗口内的请求流量超过该窗口的额度,系统会根据超限程度增加请求的回包延迟,使客户端发送或拉取速度逐步下降,从而在一段时间内达到限流保护效果。
限流实践教程
分区规划建议
CKafka 实例采用多 Broker 节点部署,实例带宽会分配到各 Broker 节点。如果 Topic 分区数较少,或分区流量分布不均,可能导致部分 Broker 节点提前触发限流,即使实例整体流量未达到规格上限。
为提高实例带宽利用率,建议您注意以下几点:
将 Topic 分区数设置为 Broker 节点数的整数倍,Ckafka 会尽可能使每个节点上的分区均匀分布。例如,实例包含 3 个 Broker 节点时,建议 Topic 分区数设置为 6、9、12 等。
流量尽可能均衡,避免大量流量集中写入少数分区。默认情况下 CKafka 的客户端会尽可能按照分区均衡流量发送到服务端,特殊场景例如指定消息的 key 会使写入流量不均衡,请关注 Key 是否导致分区流量倾斜,避免局部热点问题带来的局部限流问题。
高吞吐业务建议预留一定带宽余量,降低突发流量触发限流的概率。
如何判断是否发生限流
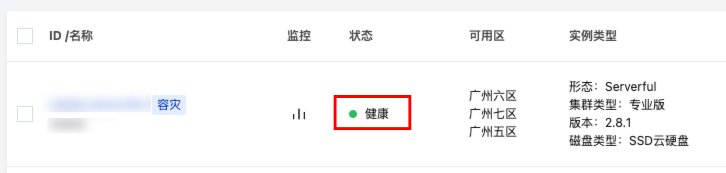
1. 实例列表页面,每个集群都有对应的健康度展示。当健康度显示为“告警”字样时,可以将鼠标移至其上查看弹出的详细数据。
2. 用户可以打开监控数据查看流量的最大值,如果 (流量的最大值 × 副本数) > 购买时的峰值带宽,则表明至少发生过一次限流。可通过配置限流告警得知是否发生限流。告警规则等配置步骤请参考配置告警策略。
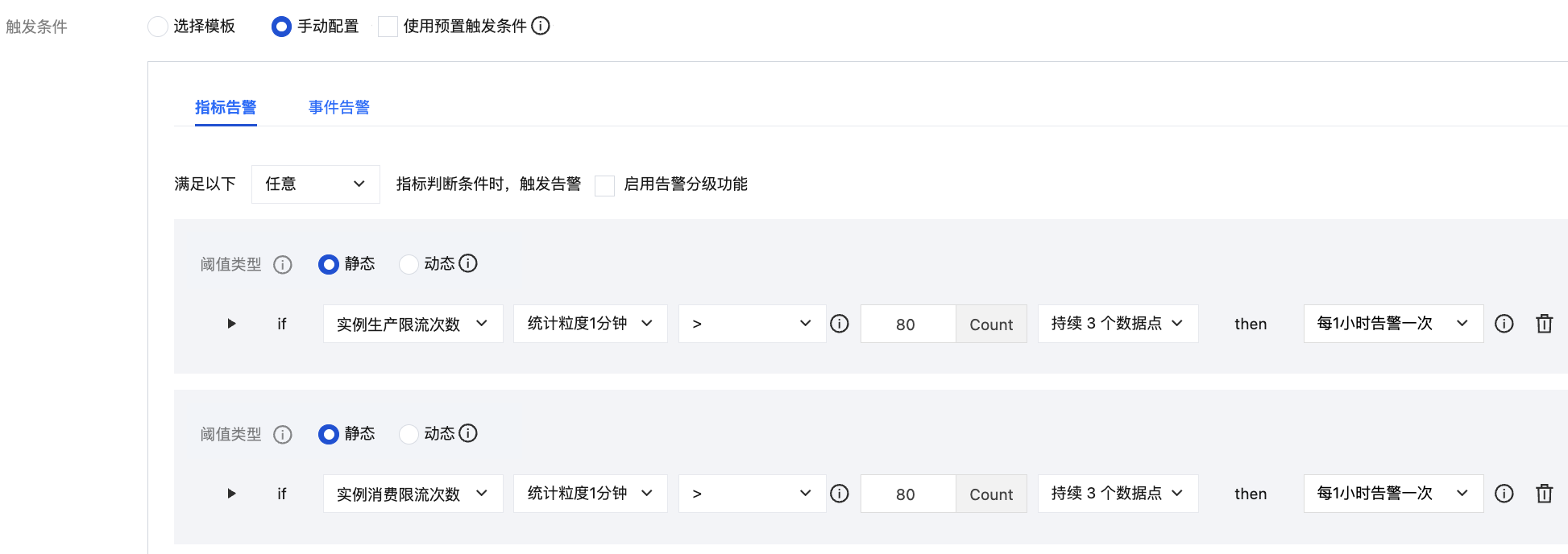
3. 在 CKafka 控制台的监控 > 限流监控页面查看监控,当限流次数大于0,证明发生过限流。具体步骤请参考查看监控数据。
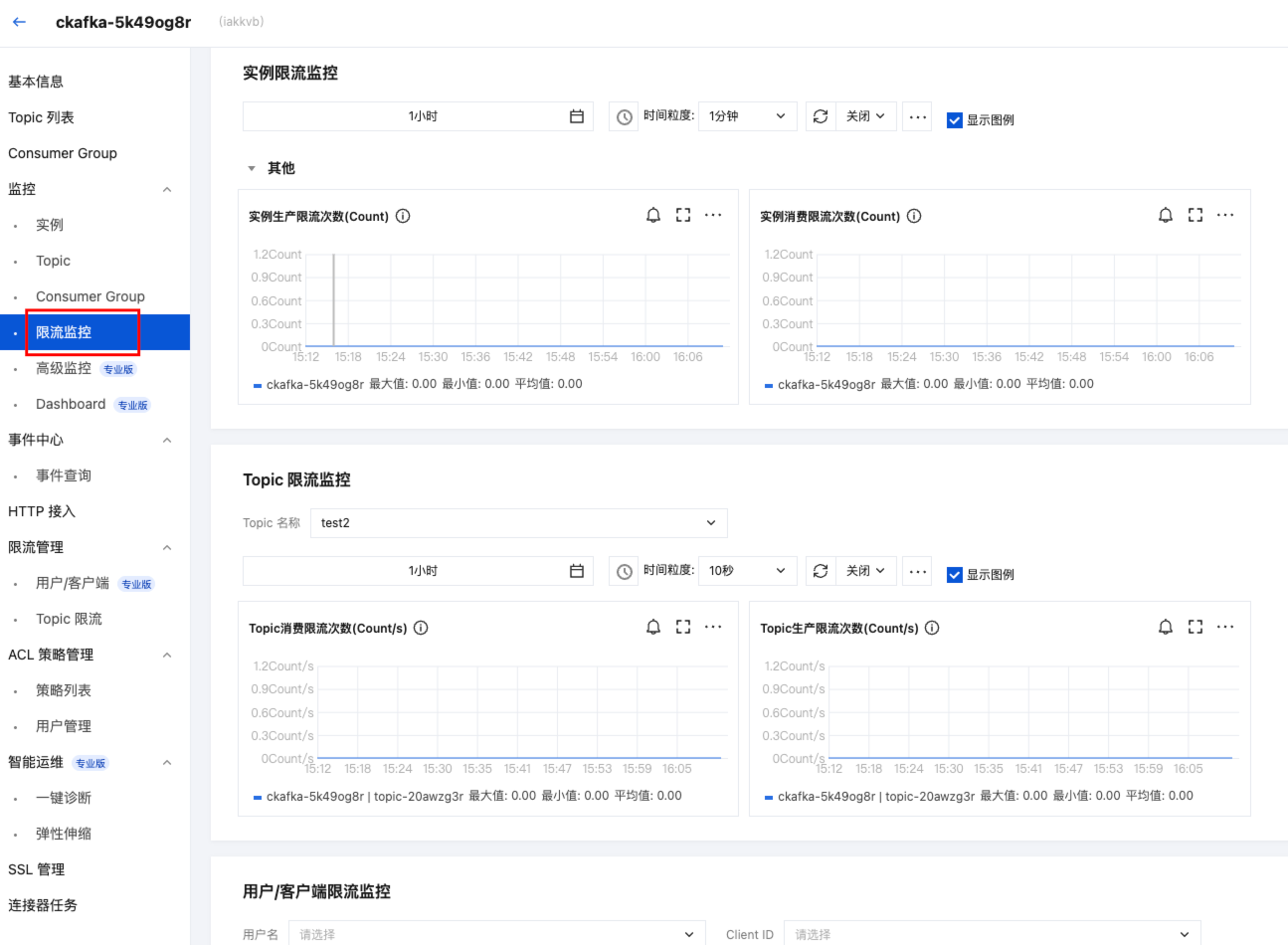
实例限流次数与延时回包监控说明
CKafka 的实例限流次数为各 Broker 节点限流次数之和。该指标不代表所有 Broker 节点都触发了限流,也不等同于实例整体写入或消费能力不足。
当出现限流,但实例整体流量低于规格值时,可能是部分 Broker 节点出现局部限流。您可以在专业版高级监控中查看各节点的限流次数,判断是否存在单节点热点。当遇到这类问题,建议您尽可能调整分区数到节点的倍数,提高整体实例的带宽利用率。
目前 CKafka 采用延迟回包策略进行软限流。发生限流后,建议重点关注专业版高级监控中的延时回包时间。如果延时回包时间持续升高,可能会影响客户端生产或消费延迟。
限流观察与处理建议
当实例出现限流次数时,建议结合以下情况判断:
场景 | 说明 | 处理建议 |
偶发限流 | 通常由瞬时流量突增、请求量抖动或局部分区热点引起。由于生产流量需要计算副本同步流量,副本数越多,生产侧可用带宽越低。同时,限流在 Broker 节点维度执行,限流判断粒度通常细于控制台监控展示粒度,因此即使分钟级监控中整体流量未超过规格,也可能在秒级或更短时间窗口内触发短暂限流。 | 可先观察业务是否受影响,并关注限流是否持续出现。若业务对响应时间敏感,建议预留约 30% 的带宽余量,并在专业版高级监控中查看节点级限流指标,确认是否存在单节点热点。 |
局部限流 | 实例整体流量低于规格,但部分 Broker 节点触发限流,通常与分区数不足、分区分布不均或消息 Key 导致流量倾斜有关。 | 建议在高级监控中查看各 Broker 节点的限流次数和流量情况,确认是否存在单节点流量过高。可通过增加分区数、执行分区均衡或优化消息 Key 分布,使流量尽量均匀分布到各 Broker 节点。 |
持续限流 | 实例持续出现限流次数,且生产或消费流量长期接近规格。 | 评估是否需要升配实例、开启弹性带宽,或调整生产消费流量。 |
规则限流 | 由 Topic 级或用户/客户端级限流规则触发。 | 检查对应限流规则是否配置过低,并根据业务需要调整阈值。 |
异常限流 | 每个 Broker 节点都持续出现限流,但实例整体流量明显低于规格,并已排除 Topic 级和用户/客户端级限流规则影响。 |
常见问题
Q1:为什么实际限流值会小于配置的阈值?
限流最终在 Broker 节点维度执行。限流所配置的限额实际会被下发到每台 Broker(单机限流),因此实例维度的限流会按照限流配置值/Broker 数量下发,Topic 限流值也会按照限流配置值/Broker 数量下发。
Q2:为什么监控生产/消费低于实例规格时会触发限流?
如上文所述,因为限流是以 ms 为单位的,控制台监控平台数据是按每秒采集,分钟维度聚合(最大值或者平均值)。控制台监控展示的是聚合后的数据,而限流判断发生在更细粒度的时间窗口内。如果某个短时间窗口内流量突增,Broker 可能已经触发限流;但从分钟级监控看,平均流量仍可能低于实例规格。因此,监控流量低于规格时,也可能出现限流次数。
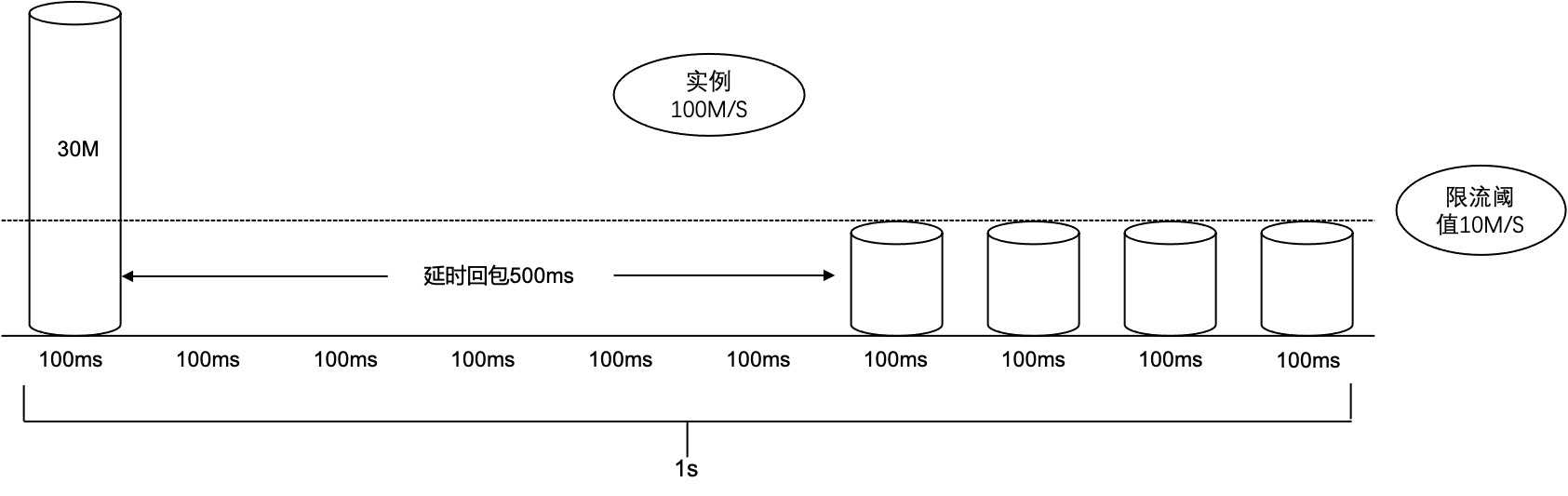
按令牌桶原理可知,单个桶不会强制限制流量。如果实例 A 的带宽规格为 100MB/s,那么每个 100ms 的时间桶的限流阈值为 100MB/10 = 10MB/桶,假设实例 A 的生产流量在某秒的第一个 100ms 时间桶达到了 30MB (时间桶限流阈值的3倍)。那么这时会触发 Broker 限流策略增加延时回包时间,假设原先正常 TCP 返回时间是 100ms,超限后可能会增加 500ms 才返回。最终这秒的流量 :30MB × 1 + 0MB × 5 + 10MB × 4 = 70MB,即这秒内的流量速度为 70MB/s 小于实例规格 100MB/s。
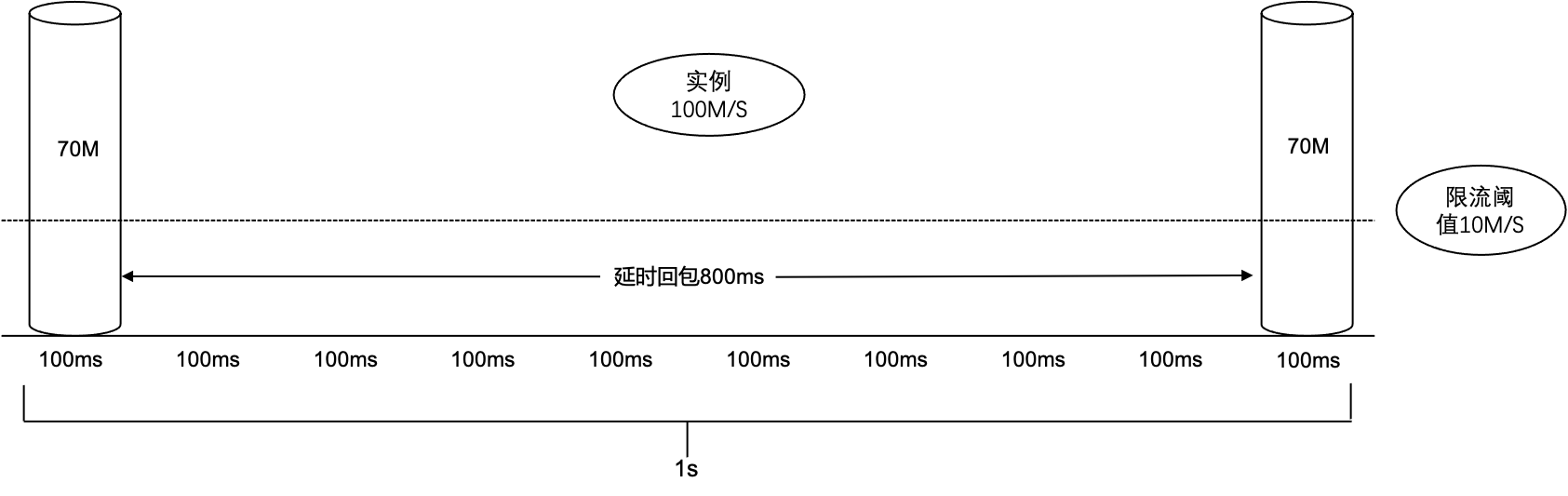
Q3:为什么生产/消费峰值流量会高于实例规格?
CKafka 使用延迟回包方式进行软限流。流量超过阈值后,系统会增加请求回包延迟,使客户端发送或拉取速度逐步下降。由于监控统计粒度和限流执行粒度不同,控制台可能看到某些时间点的生产或消费峰值高于实例规格。这不代表限流未生效。
再次假设实例 A 的带宽规格为 100MB/s,那么每个 100ms 的时间桶的限流阈值为 10MB,假设实例 A 的生产流量在某秒的第一个 100ms 时间桶达到了 70MB(时间桶限流阈值的7倍)。那么这时会触发 Broker 限流策略增加延时回包时间,假设原先正常 TCP 返回时间是 100ms,超限后可能会增加 800ms 延时才返回,在第 900ms 回包后客户端立刻又在第10个时间桶打入了 70MB 流量。最终这秒的流量 (70MB × 1 + 0MB × 8 + 70MB × 1) = 140MB,即这秒内的流量速度为 140MB/s 大于实例规格 100MB/s。
Q4:限流次数为什么会突然增多?
限流次数是以 TCP 请求统计的,如果实例 A 在某秒第一个时间桶流量打超了,那么超限后这个时间桶的剩余时间内所有的 TCP 请求都会被限制并统计限流次数。因此,当瞬时流量突增、请求数较多或分区热点明显时,限流次数可能快速增加。



